Python开发基础-Day31 Event对象、队列和多进程基础
Event对象
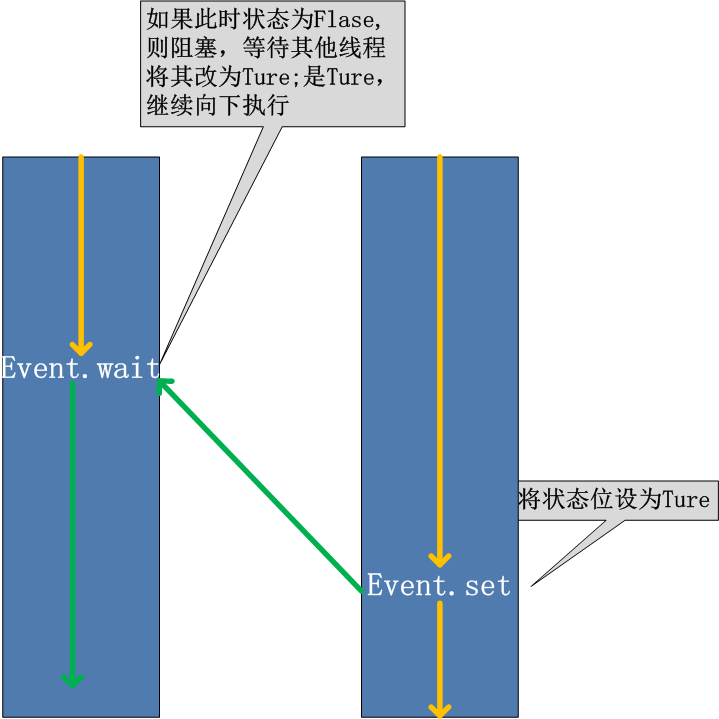
用于线程间通信,即程序中的其一个线程需要通过判断某个线程的状态来确定自己下一步的操作,就用到了event对象
event对象默认为假(Flase),即遇到event对象在等待就阻塞线程的执行。
示例1:主线程和子线程间通信,代码模拟连接服务器
import threading
import time
event=threading.Event() def foo():
print('wait server...')
event.wait() #括号里可以带数字执行,数字表示等待的秒数,不带数字表示一直阻塞状态
print('connect to server') t=threading.Thread(target=foo,args=()) #子线程执行foo函数
t.start()
time.sleep(3)
print('start server successful')
time.sleep(3)
event.set() #默认为False,set一次表示True,所以子线程里的foo函数解除阻塞状态继续执行
示例2:子线程与子线程间通信
import threading
import time
event=threading.Event() def foo():
print('wait server...')
event.wait() #括号里可以带数字执行,数字表示等待的秒数,不带数字表示一直阻塞状态
print('connect to server')
def start():
time.sleep(3)
print('start server successful')
time.sleep(3)
event.set() #默认为False,set一次表示True,所以子线程里的foo函数解除阻塞状态继续执行
t=threading.Thread(target=foo,args=()) #子线程执行foo函数
t.start()
t2=threading.Thread(target=start,args=()) #子线程执行start函数
t2.start()
示例3: 多线程阻塞
import threading
import time event=threading.Event()
def foo():
while not event.is_set(): #返回event的状态值,同isSet
print("wait server...")
event.wait(2) #等待2秒,如果状态为False,打印一次提示继续等待
print("connect to server") for i in range(5): #5个子线程同时等待
t=threading.Thread(target=foo,args=())
t.start() print("start server successful")
time.sleep(10)
event.set() # 设置标志位为True,event.clear()是回复event的状态值为False
queue队列
队列是一只数据结构,数据存放方式类似于列表,但是取数据的方式不同于列表。
队列的数据有三种方式:
1、先进先出(FIFO),即哪个数据先存入,取数据的时候先取哪个数据,同生活中的排队买东西
2、先进后出(LIFO),同栈,即哪个数据最后存入的,取数据的时候先取,同生活中手枪的弹夹,子弹最后放入的先打出
3、优先级队列,即存入数据时候加入一个优先级,取数据的时候优先级最高的取出

代码实现
先进先出:put存入和get取出
import queue
import threading
import time
q=queue.Queue(5) #加数字限制队列的长度,最多能够存入5个数据,有取出才能继续存入
def put():
for i in range(100): #顺序存入数字0到99
q.put(i)
time.sleep(1) #延迟存入数字,当队列中没有数据的时候,get函数取数据的时候会阻塞,直到有数据存入后才从阻塞状态释放取出新数据
def get():
for i in range(100): #从第一个数字0开始取,直到99
print(q.get()) t1=threading.Thread(target=put,args=())
t1.start()
t2=threading.Thread(target=get,args=())
t2.start()
先进先出:join阻塞和task_done信号
import queue
import threading
import time
q=queue.Queue(5) #加数字限制长度
def put():
for i in range(100):
q.put(i)
q.join() #阻塞进程,直到所有任务完成,取多少次数据task_done多少次才行,否则最后的ok无法打印
print('ok') def get():
for i in range(100):
print(q.get())
q.task_done() #必须每取走一个数据,发一个信号给join
# q.task_done() #放在这没用,因为join实际上是一个计数器,put了多少个数据,
#计数器就是多少,每task_done一次,计数器减1,直到为0才继续执行 t1=threading.Thread(target=put,args=())
t1.start()
t2=threading.Thread(target=get,args=())
t2.start()
先进后出:
import queue
import threading
import time q=queue.LifoQueue()
def put():
for i in range(100):
q.put(i)
q.join()
print('ok') def get():
for i in range(100):
print(q.get())
q.task_done() t1=threading.Thread(target=put,args=())
t1.start()
t2=threading.Thread(target=get,args=())
t2.start()
按优先级:不管是数字、字母、列表、元组等(字典、集合没测),使用优先级存数据取数据,队列中的数据必须是同一类型,都是按照实际数据的ascii码表的顺序进行优先级匹配,汉字是按照unicode表(亲测)
列表
import queue
q=queue.PriorityQueue()
q.put([1,'aaa'])
q.put([1,'ace'])
q.put([4,333])
q.put([3,'afd'])
q.put([5,'4asdg'])
#1是级别最高的,
while not q.empty():#不为空时候执行
print(q.get())
元组
import queue
q=queue.PriorityQueue()
q.put((1,'aaa'))
q.put((1,'ace'))
q.put((4,333))
q.put((3,'afd'))
q.put((5,'4asdg'))
while not q.empty():#不为空时候执行
print(q.get())
汉字
import queue
q=queue.PriorityQueue()
q.put('我')
q.put('你')
q.put('他')
q.put('她')
q.put('ta')
while not q.empty():
print(q.get())
生产者与消费者模型
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
这就像,在餐厅,厨师做好菜,不需要直接和客户交流,而是交给前台,而客户去饭菜也不需要不找厨师,直接去前台领取即可,这也是一个结耦的过程。
import time,random
import queue,threading q = queue.Queue() def Producer(name):
count = 0
while count <10:
print("making........")
time.sleep(random.randrange(3))
q.put(count)
print('Producer %s has produced %s baozi..' %(name, count))
count +=1
#q.task_done()
#q.join()
print("ok......")
def Consumer(name):
count = 0
while count <10:
time.sleep(random.randrange(4))
if not q.empty():
data = q.get()
#q.task_done()
#q.join()
print(data)
print('\033[32;1mConsumer %s has eat %s baozi...\033[0m' %(name, data))
else:
print("-----no baozi anymore----")
count +=1 p1 = threading.Thread(target=Producer, args=('A',))
c1 = threading.Thread(target=Consumer, args=('B',))
# c2 = threading.Thread(target=Consumer, args=('C',))
# c3 = threading.Thread(target=Consumer, args=('D',))
p1.start()
c1.start()
# c2.start()
# c3.start()
多进程基础
由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程
多进程优点:可以利用多核、实现并行运算
多进程缺点:切换开销太大、进程间通信困难
multiprocessing模块
multiprocessing包是Python中的多进程管理包。与threading.Thread类似,它可以利用multiprocessing.Process对象来创建一个进程。该进程可以运行在Python程序内部编写的函数。该Process对象与Thread对象的用法相同,也有start(), run(), join()的方法。此外multiprocessing包中也有Lock/Event/Semaphore/Condition类 (这些对象可以像多线程那样,通过参数传递给各个进程),用以同步进程,其用法与threading包中的同名类一致。所以,multiprocessing的很大一部份与threading使用同一套API,只不过换到了多进程的环境。
计算密集型串行计算:计算结果大概25秒左右
import time def foo(n): #计算0到1亿的和
ret=0
for i in range(n):
ret+=i
print(ret) def bar(n): #计算1到10万的乘积
ret=1
for i in range(1,n):
ret*=i
print(ret)
if __name__ == '__main__':
s=time.time()
foo(100000000)
bar(100000)
print(time.time()-s)
计算密集型多进程计算:计算结果13秒左右
import multiprocessing
import time def foo(n):
ret=0
for i in range(n):
ret+=i
print(ret) def bar(n):
ret=1
for i in range(1,n):
ret*=i
print(ret) if __name__ == '__main__':
s=time.time()
p1 = multiprocessing.Process(target=foo,args=(100000000,)) #创建子进程,target: 要执行的方法;name: 进程名(可选);args/kwargs: 要传入方法的参数。
p1.start() #同样调用的是类的run方法
p2 = multiprocessing.Process(target=bar,args=(100000,) ) #创建子进程
p2.start()
p1.join()
p2.join()
print(time.time()-s)
继承类用法
from multiprocessing import Process
import time class MyProcess(Process):
def __init__(self):
super(MyProcess, self).__init__()
# self.name = name def run(self):
print ('hello', self.name,time.ctime())
time.sleep(1) if __name__ == '__main__':
p_list=[]
for i in range(3):
p = MyProcess()
p.start()
p_list.append(p) for p in p_list:
p.join() print('end')
方法示例
from multiprocessing import Process
import os
import time def info(name):
print("name:",name)
print('parent process:', os.getppid()) #获取父进程的id号
print('process id:', os.getpid()) #获取当前进程pid
print("------------------")
time.sleep(5)
if __name__ == '__main__':
info('main process') #第一次获取的是ide工具的进程和该代码文件的进程
p1 = Process(target=info, args=('alvin',)) #该代码文件的进程和p1的进程
p1.start()
p1.join()
对象实例的方法
实例方法:
is_alive():返回进程是否在运行。
join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数)。
start():进程准备就绪,等待CPU调度
run():strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法。
terminate():不管任务是否完成,立即停止工作进程
属性:
daemon:和线程的setDeamon功能一样
name:进程名字。
pid:进程号。
Python开发基础-Day31 Event对象、队列和多进程基础的更多相关文章
- python Event对象、队列和多进程基础
Event对象 用于线程间通信,即程序中的其一个线程需要通过判断某个线程的状态来确定自己下一步的操作,就用到了event对象 event对象默认为假(Flase),即遇到event对象在等待就阻塞线程 ...
- python基础之Event对象、队列和多进程基础
Event对象 用于线程间通信,即程序中的其一个线程需要通过判断某个线程的状态来确定自己下一步的操作,就用到了event对象 event对象默认为假(Flase),即遇到event对象在等待就阻塞线程 ...
- Python开发【第5节】【函数基础】
1.函数 函数的本质就是功能的封装. 函数的作用 提升代码的重复利用率,避免重复开发相同代码 提高程序开发效率 便于程序维护 2.函数定义 def 函数名(参数): """ ...
- python开发concurent.furtrue模块:concurent.furtrue的多进程与多线程&协程
一,concurent.furtrue进程池和线程池 1.1 concurent.furtrue 开启进程,多进程&线程,多线程 # concurrent.futures创建并行的任务 # 进 ...
- python学习笔记——创建事件对象Event
1 Event对象的基本概述 用 multiprocessing.Event 实现线程间通信,使用multiprocessing.Event可以使一个线程等待其他线程的通知,我们把这个Event传递到 ...
- Python多线程的threading Event
Python threading模块提供Event对象用于线程间通信.它提供了一组.拆除.等待用于线程间通信的其他方法. event它是沟通中最简单的一个过程之中,一个线程产生一个信号,号.Pytho ...
- Python进阶(3)_进程与线程中的lock(线程中互斥锁、递归锁、信号量、Event对象、队列queue)
1.同步锁 (Lock) 当全局资源(counter)被抢占的情况,问题产生的原因就是没有控制多个线程对同一资源的访问,对数据造成破坏,使得线程运行的结果不可预期.这种现象称为“线程不安全”.在开发过 ...
- Python开发基础-Day19继承组合应用、对象序列化和反序列化,选课系统综合示例
继承+组合应用示例 class Date: #定义时间类,包含姓名.年.月.日,用于返回生日 def __init__(self,name,year,mon,day): self.name = nam ...
- Event对象、队列、multiprocessing模块
一.Event对象 线程的一个关键特性是每个线程都是独立运行且状态不可预测.如果程序中的其他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就 会变得非常棘手.为了解决这些问题, ...
随机推荐
- 2017 ACM Arabella Collegiate Programming Contest(solved 11/13)
省选考前单挑做点ACM练练细节还是很不错的嘛- 福利:http://codeforces.com/gym/101350 先来放上惨不忍睹的virtual participate成绩(中间跑去食堂吃饭于 ...
- 可编辑表格(Editable Table)
需求分析 1.单击table的每个cell后,给cell加上一个尺寸相当的input; 2.input后把value传给cell的innerHTML; 3.失焦后删除input. HTML <! ...
- Windows下搭建网络代理
场景:有些场景下会出现局域网内的某些网段可能由于安全限制,不能访问外网,此时可以通过安装一些工具来实现借助局域网内某些能够上外网的电脑来实现网络代理的功能.以下工具均是使用于Window环境. 服务端 ...
- Try finally的一个实验和为什么避免重载 finalize()方法--例子
public class TryFinallTest { public TryFinallTest(){ } public void runSomething(String str){ System. ...
- 高性能优秀的服务框架-dubbo介绍
先来了解一下这些年架构的变化,下面的故事是我编的.... "传统架构":很多年前,刚学完JavaWeb开发的我凭借一人之力就开发了一个网站,网站 所有的功能和应用都集中在一起,方便 ...
- perl6 一个猜测密码的注入
use HTTP::UserAgent; my $ua = HTTP::UserAgent.new; my $r = HTTP::Request.new; my $c = HTTP::Cookies. ...
- 【Python学习】csv库
csv(Comma-Separated Values, 逗号分割值)是存储表格数据的常用文件格式. 它每一行都用一个换行符分隔,列与列之间用逗号分隔. 本地文件 Python的csv库可以非常简单地修 ...
- ubuntu新机安装工具
ubuntu新机安装工具:1,sudo apt-get install ssh vim2, 设置root密码,以备不时之需: 执行:sudo passwd root 然后输入当前三次密码,第一次是当前 ...
- 64_t4
texlive-hardwrap-svn21396.0.2-33.fc26.2.noarch.rpm 24-May-2017 15:41 35930 texlive-harmony-doc-svn15 ...
- eWebEditor复制粘贴图片时过滤域名
1.找到form.js 路径:plugins/frame/scripts/form.js 这个方法: 2.替换这个方法 /** * 处理参数 */ Form.prototype.processReqP ...