Python3.x:代理ip刷评分
Python3.x:代理ip刷评分
声明:仅供为学习材料,不允许用作商业用途;
一,功能:
针对某网站对企业自动刷评分;
二,步骤:
1,获取代理ip(代理ip地址:http://www.xicidaili.com/nn);
2,模拟浏览器打开评分页面;
3,模拟评分事件,并传递参数;
参数获取:根据浏览器的开发者工具,跟踪评分事件;对应的“Network”可以看到相关的表头信息,其中的From Data就是参数信息;
表头信息:POST方式
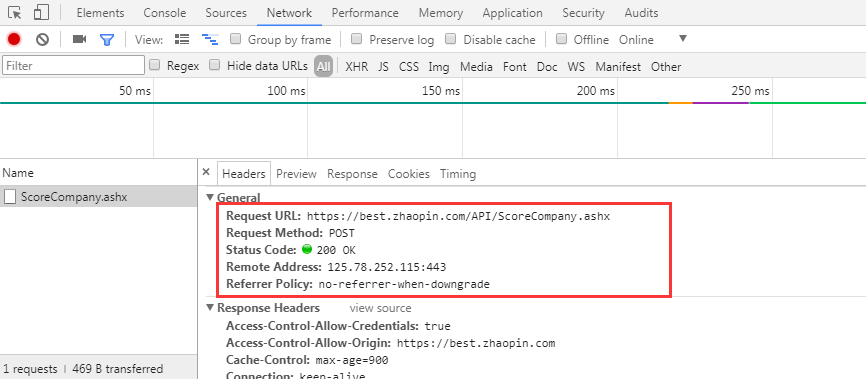
参数信息:

三、代码:
# python3
# 功能:对https://best.zhaopin.com/中的某企业刷评分
import re
import random
import sys
import time
import datetime
import threading
from random import choice
import requests
import bs4 # 设置user-agent列表,每次请求时,可在此列表中随机挑选一个user-agnet
user_agent = [
"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:17.0; Baiduspider-ads) Gecko/17.0 Firefox/17.0",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9b4) Gecko/2008030317 Firefox/3.0b4",
"Mozilla/5.0 (Windows; U; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; BIDUBrowser 7.6)",
"Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.3; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0",
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.99 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.3; Win64; x64; Trident/7.0; Touch; LCJB; rv:11.0) like Gecko",
] # 国内高匿代理IP,返回某页面的所有ip
def get_ip_list(page=1):
#获取代理IP(取当前页的ip列表,每页100条ip)
url = "http://www.xicidaili.com/nn/"+page
headers = { "Accept":"text/html,application/xhtml+xml,application/xml;",
"Accept-Encoding":"gzip, deflate, sdch",
"Accept-Language":"zh-CN,zh;q=0.8,en;q=0.6",
"Referer":"http://www.xicidaili.com",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.90 Safari/537.36"
}
r = requests.get(url,headers=headers)
soup = bs4.BeautifulSoup(r.text, 'html.parser')
data = soup.table.find_all("td")
# 匹配规则需要用浏览器的开发者工具进行查看
# 匹配IP:<td>61.135.217.7</td>
ip_compile= re.compile(r'<td>(\d+\.\d+\.\d+\.\d+)</td>')
# 匹配端口:<td>80</td>
port_compile = re.compile(r'<td>(\d+)</td>')
# 获取所有IP,返回的是数组[]
ip = re.findall(ip_compile,str(data))
# 获取所有端口:返回的是数组[]
port = re.findall(port_compile,str(data))
# 组合IP+端口,如:61.135.217.7:80
return [":".join(i) for i in zip(ip,port)] # 打开页面,执行评分行为
def do_dz(code=0,ips=[]):
#点赞,如果代理IP不可用造成刷评分失败,则会自动换一个代理IP后继续刷评分
try:
# 随机选取一个ip
ip = choice(ips)
except:
return False
else:
proxies = {
"http":ip,
}
headers_ = {
"Accept":"*/*",
"Accept-Encoding":"gzip, deflate, sdch",
"Accept-Language":"zh-CN,zh;q=0.8,en;q=0.6",
"Referer":"https://best.zhaopin.com/",
"User-Agent":choice(user_agent),
}
# 用浏览器的开发者工具跟踪评分事件传输的参数值
datas = {'bestid': 6030, 'score': '5,5,5,5,5,5','source': 'best'}
try:
# 评分请求url
url_dz = "https://best.zhaopin.com/API/ScoreCompany.ashx"
# 执行评分行为(发送请求)
r_dz = requests.post(url_dz,headers=headers_,data=datas,proxies=proxies)
except requests.exceptions.ConnectionError:
print("Connection Error")
if not ips:
print("not ip")
sys.exit()
# 删除不可用的代理IP
if ip in ips:
ips.remove(ip)
# 重新请求URL
get_url(code,ips)
else:
# 获取当前时间
date = datetime.datetime.now().strftime('%H:%M:%S')
print(u"第%s次 [%s] [%s]:评分%s (剩余可用代理IP数:%s)" % (code,date,ip,r_dz.text,len(ips))) if __name__ == '__main__':
ips = []
# python3把xrange()与rang()e整合为一个range()
for i in range(5000):
# 每隔1000次重新获取一次最新的代理IP
if i % 1000 == 0:
ips.extend(get_ip_list(""))
# 启用线程,隔2秒产生一个线程
t1 = threading.Thread(target=do_dz,args=(i,ips))
t1.start()
# time.sleep的最小单位是毫秒
time.sleep(2)
四、效果:
执行前:

执行后:

作者:整合侠
链接:http://www.cnblogs.com/lizm166/p/8242249.html
来源:博客园
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Python3.x:代理ip刷评分的更多相关文章
- Python3.x:代理ip刷点赞
Python3.x:代理ip刷点赞 声明:仅供为学习材料,不允许用作商业用途: 一,功能: 针对某网站对企业自动刷点赞: 网站:https://best.zhaopin.com/ 二,步骤: 1,获取 ...
- 使用不同代理IP刷票的脚本---requests
投票功能限制刷票是通过限制单个IP的投票次数实现的,所以写了个脚本用于测试此功能. #-*- coding=utf-8 -*- ''' 功能:此脚本用于用不同的IP刷票 作者:Elle 最后修改日期: ...
- python代理池的构建1——代理IP类的构建,以及配置文件、日志文件、requests请求头
一.整体结构 二.代理IP类的构建(domain.py文件) ''' 实现_ init_ 方法, 负责初始化,包含如下字段: ip: 代理的IP地址 port:代理IP的端口号 protocol: 代 ...
- 【python3】如何建立爬虫代理ip池
一.为什么需要建立爬虫代理ip池 在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制的,在某段时间内,当某个ip的访问量达到一定的阀值时,该ip会被拉黑.在一段时间内被禁止访问. 这种时候,可 ...
- Python3网络爬虫(四):使用User Agent和代理IP隐藏身份《转》
https://blog.csdn.net/c406495762/article/details/60137956 运行平台:Windows Python版本:Python3.x IDE:Sublim ...
- Python3网络爬虫(3):使用User Agent和代理IP隐藏身份
Python版本: python3 IDE: pycharm2017.3.3 一.为何要设置User Agent 有一些网站不喜欢被爬虫访问,所以会检测对象,如果是爬虫程序,他就会不让你访问,通过设置 ...
- Python3.x:免费代理ip的批量获取并入库
Python3.x:免费代理ip的批量获取并入库 一.简介 网络爬虫的世界,向来都是一场精彩的攻防战.现在许多网站的反爬虫机制在不断的完善,其中最令人头疼的,莫过于直接封锁你的ip.但是道高一尺魔高一 ...
- Python3.x:获取代理ip以及使用
Python3.x:获取代理ip以及使用 python爬虫浏览器伪装 #导入urllib.request模块 import urllib.request #设置请求头 headers=("U ...
- scrapy怎么设置带有密码的代理ip base64.encodestring不能用 python3.5,base64库里面的encodestring()被换成了什么?
自己写爬虫时买的代理ip有密码,在网上查了都是下面这种: 1.在Scrapy工程下新建"middlewares.py": import base64 # Start your mi ...
随机推荐
- 移动端ios中click点击失效
原因: Safari应该有某种机制用来节约资源,就是如果元素摸起来不像可以点的,就不给他响应事件. 所以,需要在点击的元素上加上{cursor:pointer},就解决了.当然还有别的方法,检点来说就 ...
- python虚拟机运行原理
近期为了面试想要了解下python的运行原理方面的东西,奈何关于python没有找到一本类似于深入理解Java虚拟机方面的书籍,找到了一本<python源码剖析>电子书,但是觉得相对来说最 ...
- js数组和字符串去重复几种方法
js数组去重复几种方法 第一种:也是最笨的吧. Array.prototype.unique1 = function () { var r = new Array(); label:for(var i ...
- sql中字段名中包含特殊字符的查询方法
sql中字段名章包含特殊字符的查询方法:例如包含"",student表中字段为:id“学号”.name"姓名". 解决办法:用英文下的 "`" ...
- datasnap 关于lifecycle的问题
首先DSServerClass的lifecycle属性有Invocation.Server.Session三种模式: 简单叙述一下三点区别: server:datasnap只初始化一个TDSServe ...
- Safe Or Unsafe--hdu2527(哈夫曼树求WPL)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=2527 用优先队列模拟 #include<iostream> #include<std ...
- 获取当前文件夹以及子文件夹下所有文件C++
void getFiles( string path,vector<string>& files) { //文件句柄 ; //文件信息 struct _finddata_t fil ...
- Linux 下线程的理解
2017-04-03 最近深入研究了下Linux线程的问题,发现自己之前一直有些许误解,特记之…… 关于Linux下的线程,各种介绍Linux的书籍都没有深入去解释的,或许真的如书上所述,Linux本 ...
- Mybatis框架学习总结-Mybatis框架搭建和使用
Mybatis介绍 Mybatis是一个支持普通SQL查询,存储过程,和高级映射的优秀持久层框架.Mybatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.Mybatis可以使 ...
- 配置stun服务器实现穿墙
Turn服务器的配置流程 Webrtc是基于P2P的,在两个客户端建立连接之前需要服务器建立连接,这时两台设备一般都处于一个或者多个NAT中,那么两台设备建立连接就需要穿墙技术. 这时就用到了turn ...