机器学习笔记—EM 算法
EM 算法所面对的问题跟之前的不一样,要复杂一些。
EM 算法所用的概率模型,既含有观测变量,又含有隐变量。如果概率模型的变量都是观测变量,那么给定数据,可以直接用极大似然估计法,或贝叶斯估计法来估计模型参数,但是,当模型含有隐变量时,情况就复杂一些,相当于一个双层的概率模型,要估计出两层的模型参数,就需要换种方法求解。EM 算法是通过迭代的方法求解。
监督学习是由训练数据 {(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))} 学习条件概率分布 P(Y|X) 或决策函数 Y=f(X) 作为模型,用于分类、回归等任务,这时训练数据中的每个样本点由输入和输出组成。但有时训练数据只有输入没有对应的输出 {(x(1),•),(x(2),•),...,(x(m),•)},从这样的数据学习模型称为非监督学习问题。EM 算法可用于生成模型的非监督学习,生成模型由联合概率分布 P(X,Y) 表示,可以认为非监督学习训练数据是联合概率分布产生的数据。X 为观测数据,Y 为未观测数据。
我们先不管上一篇文章介绍的高斯混合模型,先来看通用的 EM 算法。
假设有训练集 {x(1),x(2),...,x(m)},我们要寻找模型 p(x,z) 的参数来拟合这些数据,数据的似然估计为:
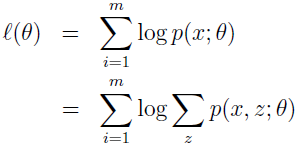
要直接使用极大似然估计来求 θ 是很难的,因为 z(i) 是隐随机变量,如果 z(i) 不是隐变量,而是可以观察到的,那使用极大似然估计就简单多了。
在这种情况下,EM 算法给出了一种高效的极大似然估计方法,直接最大化 L(θ) 很难,我们的策略是不断地构建 L 的下界(E-step),然后优化下界(M-step)。
对于每个 i,使 Qi 为 z 上的分布(∑zQi(z)=1,Qi(z)≥0),那么

最后一步的推导是用了 Jensen 不等式定理和 f(x)=log(x) 是凹函数的事实。
现在,对于一些 Qi 的分布,上式给出了 L(θ) 的下界,Qi 有很多种选择,该选择哪个呢?如果已经有 θ 的猜测值,那么自然会想到让下界贴近 θ 值,也就是使不等式在 θ 处等号成立。根据 Jensen 不等式,如果要使 E[f(X)]=f(EX) 成立,应使 X 为常数。即
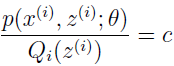
也就是
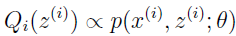
因为 ∑zQi(z(i))=1,所以可使
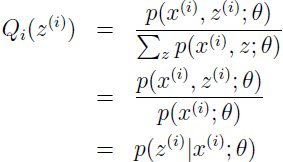
所以,就简单地把 Qi 设为给定 x(i) 和 θ 后 z(i) 的后验分布即可。
现在,有了 Q 的这个选择,就得到了 L 的下界,这是 E-step。在 M-step,对参数 θ 作极大似然估计。重复执行这两步,就是 EM 算法:
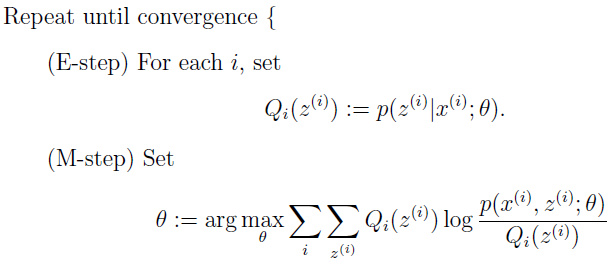
我们怎么知道算法是不是收敛呢?假设 θ(t) 和 θ(t+1) 是 EM 算法连续迭代的两个参数, 我们现在证明 L(θ(t))≤L(θ(t+1)),以证明 EM 单调改进 log 似然。证明的关键就在于 Qi 的选择,不失一般性,我们从 EM 迭代的 θ(t) 开始,Qi(t)(z(i)) :=p(z(i))p(x(i);θ(t)),我们知道这使得 Jensen 不等式变恒等。

参数 θ(t+1) 由最大化上式右边所得。

第一个不等式来自一个事实:

第二个不等式是因为 θ(t+1) 等于
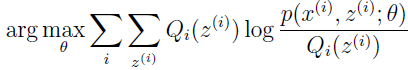
最后一个等式是因为 Qi 的选择使得 Jenson 不等式在 θ(t) 处等式成立。
所以 EM 使似然单调收敛,EM 算法一直运行知道收敛,收敛测试就是看两次结果的差是不是小于一个设置的容忍值,如果 EM 改进很慢就说明收敛了。
如果我们定义:
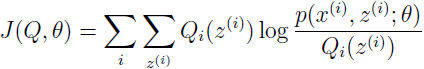
从之前的推导我们知道 L(θ)≥J(Q,θ),EM 算法可以看作是 J 的坐标上升法,在 E-step,以 Q 为参数最大化,在 M-step,以 θ 为参数最大化。
有了通用 EM 算法的定义,我们再来看下高斯混合模型中 Φ,µ 和 ∑ 的参数拟合。高斯混合模型应用广泛,在许多情况下,EM 算法是学习高斯混合模型的有效方法。简单起见,在 M-step 我们只推导 Φ 和 μi 的参数更新,有兴趣的可以推导下 ∑i。
假设有训练集 {x(1),x(2),...,x(m)},要把数据建模成一个联合分布 p(x(i),z(i))=p(x(i)|z(i))p(z(i)),其中 z(i)~Multinomial(Φ),x(i)|z(i)=j~N(µj,∑j),k 表示 z(i) 的可取值个数。数据 x(i) 是这样生成的:先从 {1,...,k} 中随机选择一个 z(i),再从 z(i) 所关联的高斯分布中生成 x(i)。这就是高斯混合模型,其中 z(i) 是隐变量,也就是未观测变量,正是这个变量使得问题变得复杂。
这个模型的参数是 Φ,μ 和 ∑,我们的任务就是估计出这些参数。
E-step 很简单,根据上面的推导,我们只需要计算
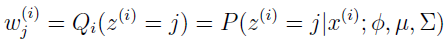
这里 Qi(z(i)=j) 表示 z(i) 在分布 Qi 下取值 j 的概率。使用贝叶斯规则来计算 z(i) 的后验概率。
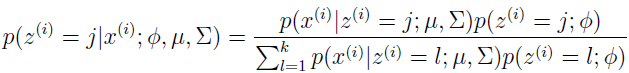
这里 p(x(i)|z(i)=j;μ,∑) 是均值为 μj,方差为 ∑j 的高斯分布在 x(i) 处的密度,p(z(i)=j;Φ) 由 Φj 给出。
下一步,在 M-step,我们需要最大化以 Φ,μ 和 ∑ 为参数的:
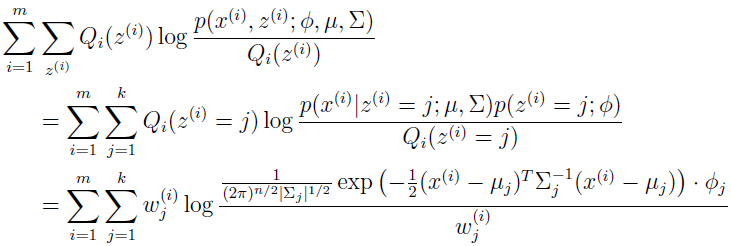
先来推导以 μl 为参数的最大化,有
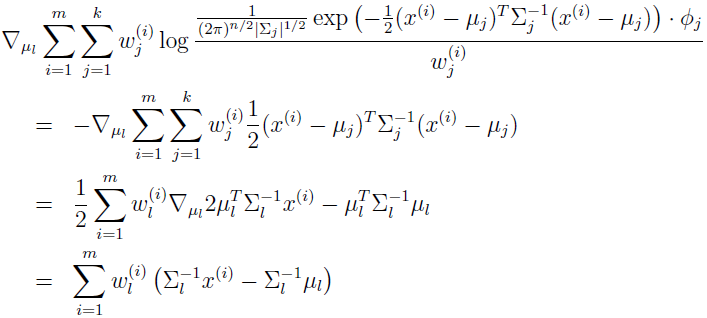
设为 0,就得到 μl 的更新规则。
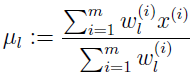
跟上一篇文章结果一样。
再来推导 M-step 中 Φj 的更新规则,经过观察,发现只需要最大化下式就可以了。
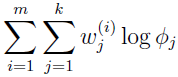
还有一个附加的约束,ΣΦj=1,因为 Φj=p(z(i)=j;Φ),为了处理这个约束,我们构建拉格朗日式子:
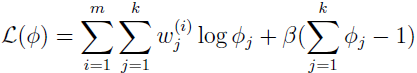
其中 β 是拉格朗日乘子。求导得:

上式设为 0,解得:

所以 Φj 正比于 Σw,由约束 ΣΦj=1,可得 -β=ΣiΣjw=m,所以

对于 Σj 的推导也很直观。
参考资料:
[1] http://cs229.stanford.edu/notes/cs229-notes8.pdf
[2] 李航,著.统计学习方法[M]. 清华大学出版社, 2012
机器学习笔记—EM 算法的更多相关文章
- 斯坦福大学机器学习,EM算法求解高斯混合模型
斯坦福大学机器学习,EM算法求解高斯混合模型.一种高斯混合模型算法的改进方法---将聚类算法与传统高斯混合模型结合起来的建模方法, 并同时提出的运用距离加权的矢量量化方法获取初始值,并采用衡量相似度的 ...
- 学习笔记——EM算法
EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计.EM算法的每次迭代由两步组成:E步,求期望(expectation):M步,求 ...
- 关于机器学习-EM算法新解
我希望自己能通俗地把它理解或者说明白,但是,EM这个问题感觉真的不太好用通俗的语言去说明白,因为它很简单,又很复杂.简单在于它的思想,简单在于其仅包含了两个步骤就能完成强大的功能,复杂在于它的数学推理 ...
- 机器学习之EM算法(五)
摘要 EM算法全称为Expectation Maximization Algorithm,既最大期望算法.它是一种迭代的算法,用于含有隐变量的概率参数模型的最大似然估计和极大后验概率估计.EM算法经常 ...
- 【机器学习】EM算法详细推导和讲解
今天不太想学习,炒个冷饭,讲讲机器学习十大算法里有名的EM算法,文章里面有些个人理解,如有错漏,还请读者不吝赐教. 众所周知,极大似然估计是一种应用很广泛的参数估计方法.例如我手头有一些东北人的身高的 ...
- 统计学习方法笔记--EM算法--三硬币例子补充
本文,意在说明<统计学习方法>第九章EM算法的三硬币例子,公式(9.5-9.6如何而来) 下面是(公式9.5-9.8)的说明, 本人水平有限,怀着分享学习的态度发表此文,欢迎大家批评,交流 ...
- 【机器学习】--EM算法从初识到应用
一.前述 Em算法是解决数学公式的一个算法,是一种无监督的学习. EM算法是一种解决存在隐含变量优化问题的有效方法.EM算法是期望极大(Expectation Maximization)算法的简称,E ...
- 机器学习五 EM 算法
目录 引言 经典示例 EM算法 GMM 推导 参考文献: 引言 Expectation maximization (EM) 算法是一种非常神奇而强大的算法. EM算法于 1977年 由Dempster ...
- 机器学习:EM算法
EM算法 各类估计 最大似然估计 Maximum Likelihood Estimation,最大似然估计,即利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值的计算过程. 直白来讲,就 ...
随机推荐
- Eclipse集成SVN
安装Subversion1.82(SVN)插件 简介 :SVN是团队开发的代码管理工具,它使我们得以进行多人在同一平台之下的团队开发. 解决问题:Eclipse下的的SVN插件安装. 学到 ...
- wordpress 自己制作子主题 child theme
使用 WordPress 的子主题(Child Themes)功能快速制作自己的主题 在了解子主题功能之前,先来看一下你在使用 WordPress 的时候是否是这样:不会自己制作主题,只好从网上下载一 ...
- my first ai application
正式下手之前,先跑个demo体验以下. 1.my first ai application https://sonnguyen.ws/first-ai-application/ https://git ...
- windows平台tensorboard的配置及使用
由于官网和其他教程里面都是以Linux为平台演示tensorboard使用的,而在Windows上与Linux上会有一些差别,因此我将学习的过程记录下来与大家分享(基于tensorflow1.2.1版 ...
- Vue组件的定义方式
1.使用template标签定义组件 <!DOCTYPE html> <html> <head> <meta charset="UTF-8" ...
- Linux系统——ACL权限控制及特殊权限
ACL权限控制 ACL(access control list),可以提供除属主.属组.其他人的rwx权限之外的细节权限设定 ACL的权限控制 (1)User 使用者 (2)Group 群组 (3)M ...
- iOS 个人所得税 app 基础解析实践
前言:2019年 新个税实施在即,全国几乎所有在职员工都会下载“个人所得税”app来使用,并且 注册使用过程需要填写身份证号等相当私密重要的个人信息. 至今,各大app平台应用下载榜首仍然“无人能出其 ...
- C#使用window API 控制打印纸张大小(转载)
windows一个特点就是设备无关性,这样就给程序控制打印机提供了很好的方法. 首先引用“泥人张”写的打印API类. using System;using System.Collections;usi ...
- Ubuntu下pycharm设定任务栏图标后打开出现问号图标
事情是这样的: ubuntu16.04,安装好pycharm后,bin下只有一个sh执行文件,想要弄成任务栏图标,所以在/usr/share/applications下新建文件pycharm.desk ...
- Tomcat源码
1.Connector Container:Engine,Host,Context,Wrapper(责任链的设计模式) Valve: Tomcat 中一个最容易发现的设计模式就是责任链模式,这 ...