Eclipse下使用Stanford CoreNLP的方法
源码下载地址:CoreNLP官网。
目前release的CoreNLP version 3.5.0版本仅支持java-1.8及以上版本,因此有时需要为Eclipse添加jdk-1.8配置,配置方法如下:
- 首先,去oracle官网下载java-1.8,下载网址为:java下载,安装完成后。
- 打开Eclipse,选择Window -> Preferences -> Java –> Installed JREs 进行配置:
点击窗体右边的“add”,然后添加一个“Standard VM”(应该是标准虚拟机的意思),然后点击“next”;在”JRE HOME”那一行点击右边的“Directory…”找到你java 的安装路径,比如“C:Program Files/Java/jdk1.8”
这样你的Eclipse就已经支持jdk-1.8了。
1. 新建java工程,注意编译环境版本选择1.8

2. 将官网下载的源码解压到工程下,并导入所需jar包
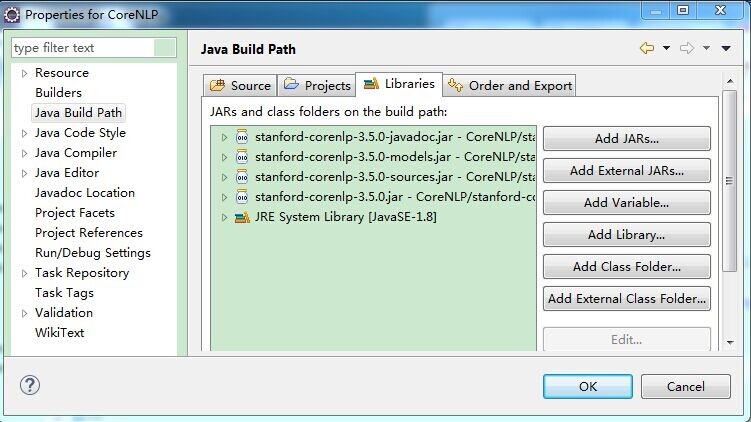
如导入stanford-corenlp-3.5.0.jar、stanford-corenlp-3.5.0-javadoc.jar、stanford-corenlp-3.5.0-models.jar、stanford-corenlp-3.5.0-sources.jar、xom.jar等
导入jar包过程为:项目右击->Properties->Java Build Path->Libraries,点击“Add JARs”,在路径中选取相应的jar包即可。
3. 新建TestCoreNLP类,代码如下
package Test; import java.util.List;
import java.util.Map;
import java.util.Properties; import edu.stanford.nlp.dcoref.CorefChain;
import edu.stanford.nlp.dcoref.CorefCoreAnnotations.CorefChainAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.LemmaAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.NamedEntityTagAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.PartOfSpeechAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.SentencesAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.TextAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.TokensAnnotation;
import edu.stanford.nlp.ling.CoreLabel;
import edu.stanford.nlp.pipeline.Annotation;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
import edu.stanford.nlp.semgraph.SemanticGraph;
import edu.stanford.nlp.semgraph.SemanticGraphCoreAnnotations.CollapsedCCProcessedDependenciesAnnotation;
import edu.stanford.nlp.sentiment.SentimentCoreAnnotations;
import edu.stanford.nlp.trees.Tree;
import edu.stanford.nlp.trees.TreeCoreAnnotations.TreeAnnotation;
import edu.stanford.nlp.util.CoreMap; public class TestCoreNLP {
public static void main(String[] args) {
// creates a StanfordCoreNLP object, with POS tagging, lemmatization, NER, parsing, and coreference resolution
Properties props = new Properties();
props.put("annotators", "tokenize, ssplit, pos, lemma, ner, parse, dcoref");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props); // read some text in the text variable
String text = "Add your text here:Beijing sings Lenovo"; // create an empty Annotation just with the given text
Annotation document = new Annotation(text); // run all Annotators on this text
pipeline.annotate(document); // these are all the sentences in this document
// a CoreMap is essentially a Map that uses class objects as keys and has values with custom types
List<CoreMap> sentences = document.get(SentencesAnnotation.class); System.out.println("word\tpos\tlemma\tner");
for(CoreMap sentence: sentences) {
// traversing the words in the current sentence
// a CoreLabel is a CoreMap with additional token-specific methods
for (CoreLabel token: sentence.get(TokensAnnotation.class)) {
// this is the text of the token
String word = token.get(TextAnnotation.class);
// this is the POS tag of the token
String pos = token.get(PartOfSpeechAnnotation.class);
// this is the NER label of the token
String ne = token.get(NamedEntityTagAnnotation.class);
String lemma = token.get(LemmaAnnotation.class); System.out.println(word+"\t"+pos+"\t"+lemma+"\t"+ne);
}
// this is the parse tree of the current sentence
Tree tree = sentence.get(TreeAnnotation.class); // this is the Stanford dependency graph of the current sentence
SemanticGraph dependencies = sentence.get(CollapsedCCProcessedDependenciesAnnotation.class);
}
// This is the coreference link graph
// Each chain stores a set of mentions that link to each other,
// along with a method for getting the most representative mention
// Both sentence and token offsets start at 1!
Map<Integer, CorefChain> graph = document.get(CorefChainAnnotation.class);
}
}
PS:该代码的思想是将text字符串交给Stanford CoreNLP处理,StanfordCoreNLP的各个组件(annotator)按“tokenize(分词), ssplit(断句), pos(词性标注), lemma(词元化), ner(命名实体识别), parse(语法分析), dcoref(同义词分辨)”顺序进行处理。
处理完后List<CoreMap> sentences = document.get(SentencesAnnotation.class);中包含了所有分析结果,遍历即可获知结果。
这里简单的将单词、词性、词元、是否实体打印出来。其余的用法参见官网(如sentiment、parse、relation等)。
4. 执行结果:

Eclipse下使用Stanford CoreNLP的方法的更多相关文章
- eclipse下添加viplugin插件的方法
http://www.viplugin.com/ 在eclipse根目录下建立文件:viplugin2.lic,然后在里面添加以下字符串: nd4UFjUMBADcUSeSW8ocLKoGP3lpbW ...
- eclipse下修改项目名导致tomcat内发布名不一致的解决方法 .
eclipse下修改项目名导致tomcat内发布名不一致的解决方法 . ------------------------------------------------------- 解决方案: 直接 ...
- eclipse下java中凝视字体太小和xml中中文字体太小问题解决方法
我们在win7下进行android应用开发.须要搭建对应的开发环境.如今普遍基本上都是eclipse+adt+sdk,在本人搭建完环境后,发现eclipse下.java中的凝视和xml中的中文字体变得 ...
- eclipse下使用cygwin的方法(Windows下用eclipse玩gcc/g++和gdb)
明天就回国了,今晚回国前写写如何配置eclipse和CDT.这个配置方法网上讨论不是很多,可能用的人少,毕竟Windows上写C++程序多数喜欢VS,即使写的是Linux程序,很多人仍然会用VS(说只 ...
- eclipse下Android工程名称的修改方法
eclipse下Android工程名称的修改方法 对于已经建立的工程,如果发现原来的工程名不合适,此时若想彻底更改工程名,需要三个步骤: 1.更改工程名 选中工程名,右键-->Refactor- ...
- stanford corenlp的TokensRegex
最近做一些音乐类.读物类的自然语言理解,就调研使用了下Stanford corenlp,记录下来. 功能 Stanford Corenlp是一套自然语言分析工具集包括: POS(part of spe ...
- Stanford CoreNLP 3.6.0 中文指代消解模块调用失败的解决方案
当前中文指代消解领域比较活跃的研究者是Chen和Vincent Ng,这两个人近两年在AAAI2014, 2015发了一些相关的文章,研究领域跨越零指代.代词指代.名词指代等,方法也不是很复杂,集中于 ...
- stanford corenlp自定义切词类
stanford corenlp的中文切词有时不尽如意,那我们就需要实现一个自定义切词类,来完全满足我们的私人定制(加各种词典干预).上篇文章<IKAnalyzer>介绍了IKAnalyz ...
- Eclipse下配置javaweb项目快速部署到tomcat
用惯了VS,再用Eclipse,完全有一种从自动挡到手动挡的感觉啊. 很多同学在Eclipse下开发web项目,每一次修改代码,看效果的时候都有右键项目->Run as -> Run on ...
随机推荐
- ActiveMQ笔记之安装(Linux)
1. 基本概念 MQ(MessageQueue),消息队列,是一个消息接收和转发的容器. Apache ActiveMQ是一个JMS Provider实现. 2. 安装 从官网下载安装包: wget ...
- ThinkPHP自定义错误页面、成功页面及异常页面
为什么会选择 ThinkPHP 呢?首先,作为一款国产PHP框架,文档肯定比国外那些框架要丰富的多,而且容易看懂:其次,ThinkPHP已经发展了七八年的时间了,相对来说已经比较成熟了:当然,最重要的 ...
- 宋牧春: Linux设备树文件结构与解析深度分析(2) 【转】
转自:https://mp.weixin.qq.com/s/WPZSElF3OQPMGqdoldm07A 作者简介 宋牧春,linux内核爱好者,喜欢阅读各种开源代码(uboot.linux.ucos ...
- 使用linux下的C操作SQLLITE
from: http://baike.so.com/doc/1529694.html 由于Linux下侧重使用命令,没有win的操作容易上手,所以在测试C操作SQLITE时会比较容易出现错误,给大家做 ...
- kernel随机生成MAC地址的接口
/** * eth_random_addr - Generate software assigned random Ethernet address * @addr: Pointer to a si ...
- linux和windows共享文件,通过samba
SAMBA共享1.安装samba:可以先检查下是否已经安装:rpm -qa | grep samba,没有的话自己安装下,这里介绍下基于RPM包的一种在线安装模式yumyum是一种快速安装模式,它会自 ...
- PHP 不让标准浏览器(firfox,chrome等)走浏览器的缓存页面
或在HTML页面里加: <META HTTP-EQUIV="Cache-Control" CONTENT="no-cache,no-store, must-reva ...
- 21.Merge Two Sorted Lists---《剑指offer》面试17
题目链接:https://leetcode.com/problems/merge-two-sorted-lists/description/ 题目大意: 给出两个升序链表,将它们归并成一个链表,若有重 ...
- IO的学习与使用
一.IO的学习方法:IO中包含了很多的类,推荐的学习方式是:“举一反三,掌握一种,以此类推”. 二.I/O操作的目标: 输入:从数据源(在数据源和程序之间建立的一个数据流淌的“管道”)中读取数据(文件 ...
- csu 1549: Navigition Problem(几何,模拟)
1549: Navigition Problem Time Limit: 1 Sec Memory Limit: 256 MBSubmit: 305 Solved: 90[Submit][Stat ...