Storm中并行度原来是这样计算的(1.0.1版本)
==思考问题1==
向集群提交一个拓扑的时候,Storm是如何计算Task数以及Executor数的?
具体有多少个worker,多少个executor,每个executor负责多少个task?
==思考问题2:==
构建拓扑的时候,有3个地方会影响并行度,这3个地方之间有什么关系?
builder.setSpout("spout", new RandomSentenceSpout(), 5); //parallelism-hint
builder.setSpout("spout", new RandomSentenceSpout(), 5).setNumTask(1);
builder.setSpout("spout", new RandomSentenceSpout(), 5).setMaxTaskParallelism(1);
==3个参数的信息==
1、parallelism-hint:
构建拓扑时,可以通过setSpout或setBolt的函数参数中指定。为初始executor数。
如:builder.setSpout("spout", new RandomSentenceSpout(), );
2、 TOPOLOGY-TASKS:
构建拓扑时,通过Spout/Bolt的setNumTasks()方法来指定。为component的task数(Spout或Bolt)。
如:builder.setSpout("spout", new RandomSentenceSpout(), 5).setNumTask(1);
3、TOPOLOGY-MAX-TASK-PARALLELISM:
构建拓扑时,通过Spout/Bolt的setMaxTaskParallelism()方法来指定。为component的最大并行度。通常用于测试,在本地模式时使用。
如:builder.setSpout("spout", new RandomSentenceSpout(), 5).setMaxTaskParallelism(1);
==结论1:Executor数是多少?==
对应topology代码中, 为每个component指定的parallelism-hint数(通过setBolt和setSpout的参数)
==结论2:Task数是多少?==
版本号:apache-storm-1.0.1
代码路径:org/apache/storm/daemon/nimbus.clj
这里有一个函数非常重要,看了之后上面的3个关系多少会清晰很多。
该函数返回计算之后的真实的Task数。
(defn- component-parallelism [storm-conf component]
(let [storm-conf (merge storm-conf (component-conf component))
num-tasks (or (storm-conf TOPOLOGY-TASKS) (num-start-executors component))
max-parallelism (storm-conf TOPOLOGY-MAX-TASK-PARALLELISM)
]
(if max-parallelism
(min max-parallelism num-tasks)
num-tasks)))
这个代码是用clojure语言编写的,没有用过的人估计会非常蛋疼,
为了方便理解,用伪代码(方便理解)翻译之后,大概思路是这个样子的:
num-tasks = (TOPOLOGY-TASKS != null ? TOPOLOGY-TASKS : parallelism-hint);
max-parallelism = TOPOLOGY-MAX-TASK-PARALLELISM; if (max-parallelism != null) {
//取两者较小
return min(num-tasks, max-parallelism);
} else {
return num-tasks;
}
如果将3个参数进行排列组合之后,获得结果如下:

简单理解来说:
1、暂时不考虑TOPOLOGY-MAX-TASK-PARALLELIS。(测试用的玩意儿,弄出来影响思路)
2、TOPOLOGY-TASKS优先于parallelism-hint。
==Executor与Task是如何匹配的?==
下面的代码是分配的代码
(defn- compute-executors [nimbus storm-id]
(let [conf (:conf nimbus)
blob-store (:blob-store nimbus)
storm-base (.storm-base (:storm-cluster-state nimbus) storm-id nil)
component->executors (:component->executors storm-base)
storm-conf (read-storm-conf-as-nimbus storm-id blob-store)
topology (read-storm-topology-as-nimbus storm-id blob-store)
task->component (storm-task-info topology storm-conf)]
(->> (storm-task-info topology storm-conf)
reverse-map
(map-val sort)
(join-maps component->executors)
(map-val (partial apply partition-fixed))
(mapcat second)
(map to-executor-id)
)))
理解这个代码之前,我们首先把注意力放在storm-task-info这个函数上,看看它都干了些什么。
代码位置:org/apache/storm/daemon/common.clj
(defn storm-task-info
"Returns map from task -> component id"
[^StormTopology user-topology storm-conf]
(->> (system-topology! storm-conf user-topology)
all-components
(map-val (comp #(get % TOPOLOGY-TASKS) component-conf))
(sort-by first)
(mapcat (fn [[c num-tasks]] (repeat num-tasks c)))
(map (fn [id comp] [id comp]) (iterate (comp int inc) (int 1)))
(into {})
))
来看看广大网友的解读版。参考博客:https://www.cnblogs.com/ierbar0604/p/4386480.html

这个函数, 首先读出所有components ,对每个component, 读出TOPOLOGY-TASKS(已经过标准化之后的TASK数,具体参照前面的内容),
最后用递增序列产生taskid, 并最终生成component和task的对应关系。
(如果不设置TOPOLOGY-TASKS,task数等于executor数,后面分配就很容易,否则就涉及task分配问题)
storm-task-info函数的输出,是这个样子的:
{1 "boltA", 2 "boltA", 3 "boltA", 4 "boltA", 5 "boltB", 6 "boltB"}
然后,我们把注意力返回到compute-executors函数(调用storm-task-info函数的调用处)。
还是用上面博客中,网友解读的版本来帮助我们理解。(注意:需要对照源码,确认当前版本代码是否有变化)
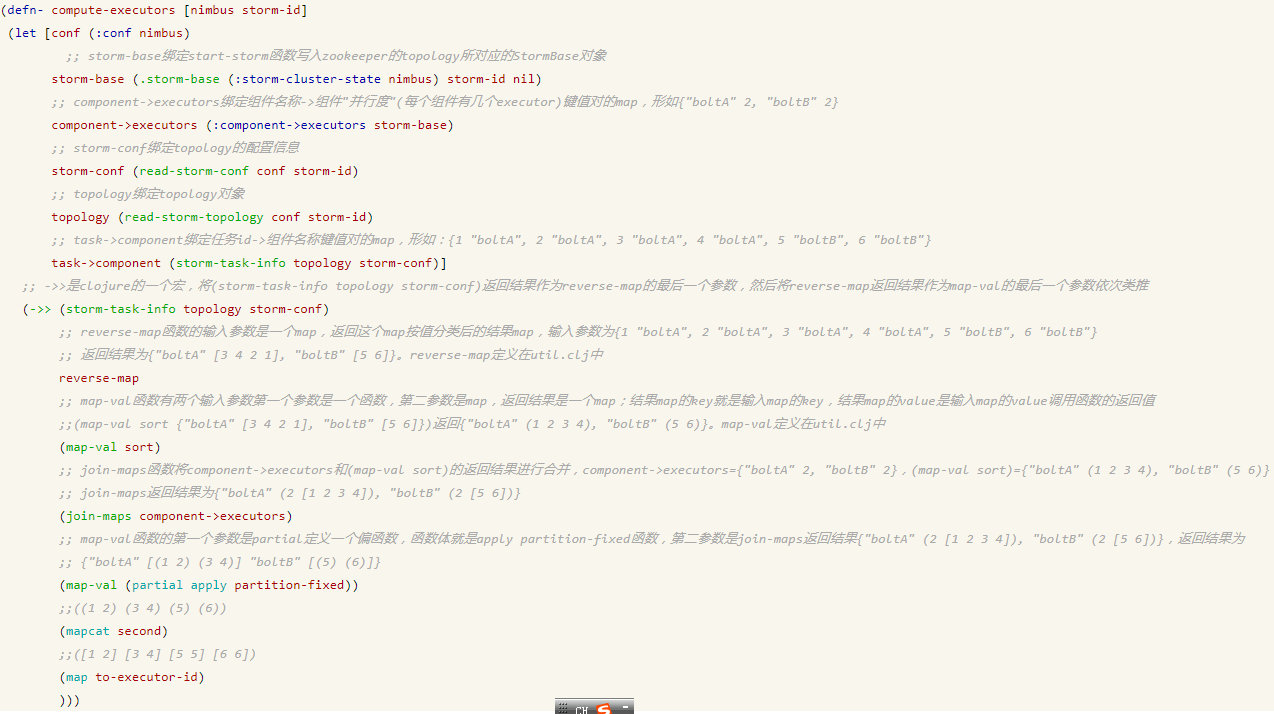
==我的笔记==

最后,从程序与StormUI界面对比来看看并行度的分配结果。
(拓扑程序)

(UI界面)
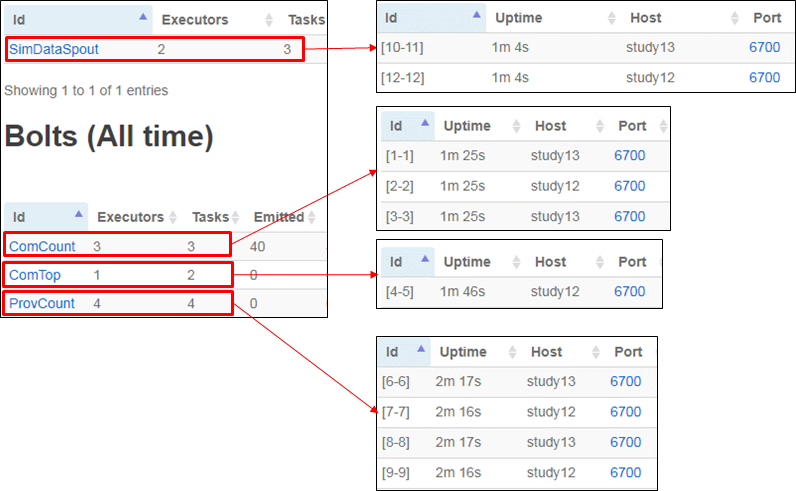
==简单总结==
1、有3个地方可以影响Task数,根据3个参数的结果决定Task数。
2、executor数 = 所有组件的parallelism-hint总数。
3、task数在生命周期内不变,executor数可能改变。
==rebalance命令==
storm运行过程中,而已使用rebalance命令动态调整拓扑的worker数及并发度。
命令模板:storm rebalance topology-name [-w wait-time-secs] [-n new-num-workers] [-e component=parallelism]* (*表示可以设置多个)
## 重新配置拓扑 "mytopology",使得该拓扑拥有 5 个 worker processes,
## 另外,配置名为 "blue-spout" 的 spout 使用 3 个 executor,
## 配置名为 "yellow-bolt" 的 bolt 使用 10 个 executor。 $ storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=1
-w:标记覆盖Storm在禁用与关闭期间等待的时间长度。
==其他疑问==
1、网上总是能看到,“不推荐使用setNumTasks”的方式来提高并发度。至于原因确实是一直没有搞明白。
答:如果只单纯的使用setNumTasks,不调整parallelism-hint,会造成多个Task运行在1个executor的结果。并不一定能够提高性能。
2、如果task数比executor数多,是否会有闲置executor?(需要用代码验证)
答:不会有闲置executor。
-------------
参考博客:
https://www.cnblogs.com/ierbar0604/p/4386480.html
http://lib.csdn.net/article/60/42875
Storm中并行度原来是这样计算的(1.0.1版本)的更多相关文章
- 《storm实战-构建大数据实时计算读书笔记》
自己的思考: 1.接收任务到任务的分发和协调 nimbus.supervisor.zookeeper 2.高容错性 各个组件都是无状态的,状态 ...
- Storm-6 Storm的并行度、Grouping策略以及消息可靠处理机制简介
概念: 配置并行度 动态的改变并行度 流分组策略----Stream Grouping 消息的可靠处理机制 概念: Workers (JVMs): 在一个节点上可以运行一个或多个独立的JVM 进程.一 ...
- 【Storm篇】--Storm中的同步服务DRPC
一.前述 Drpc(分布式远程过程调用)是一种同步服务实现的机制,在Storm中客户端提交数据请求之后,立刻取得计算结果并返回给客户端.同时充分利用Storm的计算能力实现高密度的并行实时计算. 二. ...
- storm中worker、executor、task之间的关系
这里做一些补充: worker是一个进程,由supervisor启动,并只负责处理一个topology,所以不会同时处理多个topology. executor是一个线程,由worker启动,是运行t ...
- Storm的并行度、Grouping策略以及消息可靠处理机制简介
转自:https://my.oschina.net/zc741520/blog/409949 概念: Workers (JVMs): 在一个节点上可以运行一个或多个独立的JVM 进程.一个Topolo ...
- Storm概念学习系列之并行度与如何提高storm的并行度
不多说,直接上干货! 对于storm来说,并行度的概念非常重要!大家一定要好好理解和消化. storm的并行度,可以简单的理解为多线程. 如何提高storm的并行度? storm程序主要由spout和 ...
- storm中的topology-worker-executor-task
调度角色 调度方法 自定义调度 1 调度角色 任务角色结构 上图是JStorm中一个topology对应的任务执行结构,其中worker是进程,executor对应于线程,task对应着spout ...
- Storm中遇到的日志多次重写问题(一)
业务描述: 统计从kafka spout中读取的数据条数,以及写入redis的数据的条数,写入hdfs的数据条数,写入kafaka的数据条数.并且每过5秒将数据按照json文件的形式写入日志.其中保存 ...
- Storm中Spout使用注意事项小结
Storm中Spout用于读取并向计算拓扑中发送数据源,最近在调试一个topology时遇到了系统qps低,处理速度达不到要求的问题,经过排查后发现是由于对Spout的使用模式不当导致的多线程同步等待 ...
随机推荐
- xss 攻击 sql 注入
XSS测试 "/><script>alert(document.cookie)</script><!-- <script>alert(docu ...
- java代码。。。圆的面积好搞人。。。不是一般的搞人。。。欢迎指点指点
package com.ll; public class Class3 { private String name; private int age; private int ...
- 斗地主AI
斗地主AI设计 一.牌型 1 火箭:大小王在一起的牌型,即双王牌,此牌型最大,什么牌型都可以打. 2 炸弹:相同点数的四张牌在一起的牌型,比如四条A.除火箭外,它可以打 ...
- Easyui combotree 获取自定义ID属性方法
1.设置属性 <input id="cc" class="easyui-combotree" data-options="url:'tree_d ...
- JAVA构造函数在超类与子类定义鲁波总结
1.子类无构造函数,超类无构造函数,创建的无参数的对象: 编译通过. class A { } class B extends A { } public class Testeeer { public ...
- 第一个Net+Mysql的例子,比想象的简单很多
1.window下安装mysql,比较简单,完全的图形化界面,不用看文档一路点击下来也ok,注意中间几个configtype选项就可以. 2.安装MySql Net的驱动程序程序,安装完后就是几个dl ...
- Java 内存机制、内存泄露
http://wenku.baidu.com/view/61f31da6284ac850ad02423e.html 自己注:hashset和hashmap不同 JDK1.6 API 中 HashSet ...
- Sqlmap用法小结
一共有七个等级0.只显示python错误以及严重的信息.1.同时显示基本信息和警告信息.(默认)2.同时显示debug信息.3.同时显示注入的payload.4.同时显示HTTP请求.5.同时显示HT ...
- centos7.3安装python3.6.5
最近在玩django,想部署个网站试试,结果发现线上默认的centos用得居然是python2.7.5,那么先升级下吧,到python3.6.5 yum安装时python2.7.5 那么编译安装吧 那 ...
- Android Studio 2.3.3 调用asp.net webService实战(拒绝忽悠)
1.路径中不能包含localhost(本来想在本机调试,就是不行,没办法发布到远程服务器) 2.必须采用异步的办法(阻塞主线程的是肯定不行了) 3.以下是全部的源代码(毫不保留) package co ...