Spark-2.4.0源码:sparkContext
在看sparkContext之前,先回顾一下Scala的语法。Scala构造函数分主构造和辅构造函数,辅构造函数是关键字def+this定义的,而类中不在方法体也不在辅构造函数中的代码就是主构造函数,实例化对象的时候主构造函数都会被执行,例:
class person(name String,age Int){
println("主构造函数被调用")
def this(name String,age Int){ //辅构造函数
this () //必须先调用主构造函数
this.name = name
this.age = age
}
def introduce(){
println("name :" + name + "-age :" + age)
}
}
val jack = new person("jack",)
jack.introduce()
运行结果:
主构造函数被调用
name :jack-age :2
切入正题,看sparkContext的主构造函数比较重要的一些代码:
try{
...
// Create the Spark execution environment (cache, map output tracker, etc)
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
...
// We need to register "HeartbeatReceiver" before "createTaskScheduler" because Executor will
// retrieve "HeartbeatReceiver" in the constructor. (SPARK-6640)
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
_taskScheduler.start()
}
首先:
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
这里是在sparkContext中创建rpcEnv,并通过 setupEndpoint 向 rpcEnv 注册一个心跳的 Endpoint。
private[spark] class HeartbeatReceiver(sc: SparkContext, clock: Clock)
extends SparkListener with ThreadSafeRpcEndpoint with Logging
这里有一个事件总线的概念:



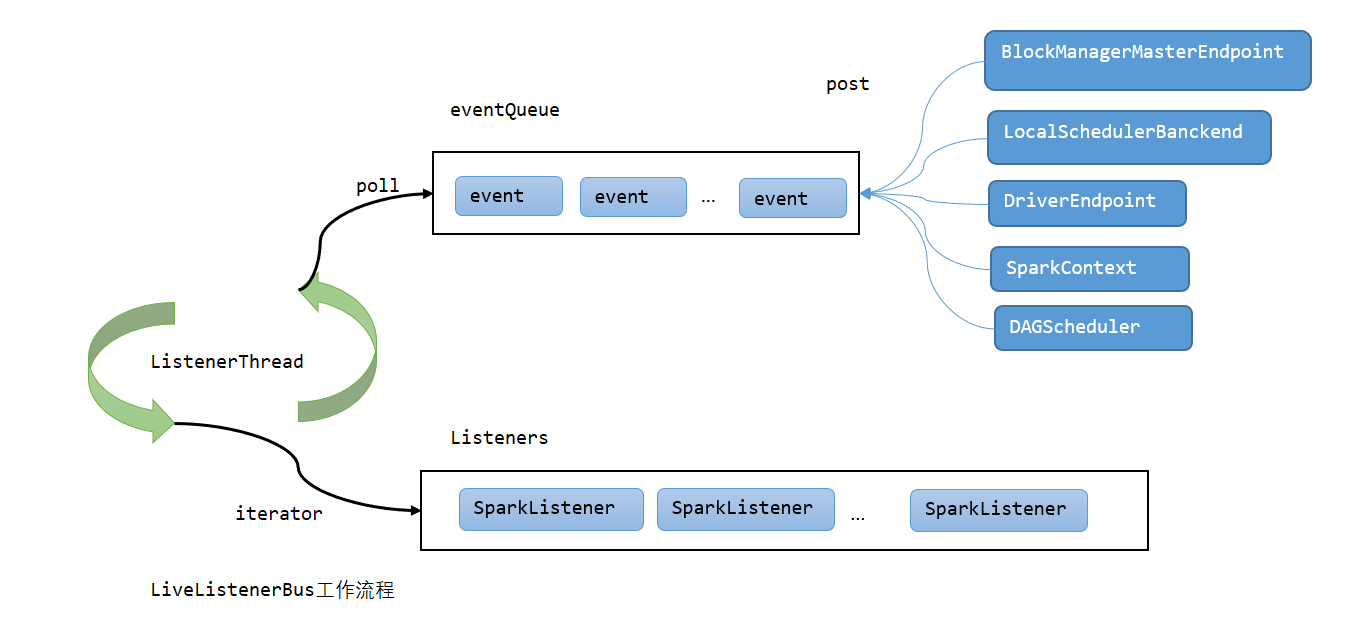
接着:
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
调的sparkContext自己的方法,创建taskScheduler,返回的是一个 (SchedulerBackend, TaskScheduler) 元组
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._ // When running locally, don't try to re-execute tasks on failure.
val MAX_LOCAL_TASK_FAILURES = master match {
//... //standalone的提交模式
case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
//调用初始化方法
scheduler.initialize(backend)
(backend, scheduler)
} //...
}
方法内部根据master参数判断不同的提交模式,创建不同的(SchedulerBackend, TaskScheduler) ,拿standalon模式举例,根据入参创建TaskSchedulerImpl和StandalonSchedulerBackend,再调用TaskSchedulerImpl的初始化方法,最后返回一个元组。
scheduler.initialize(backend),其实就是根据不同的schedulingMode创建不同的schedulableBuilder,它就是对Scheduleable tree的封装,负责对taskSet的调度。
def initialize(backend: SchedulerBackend) {
this.backend = backend
schedulableBuilder = {
schedulingMode match {
case SchedulingMode.FIFO =>
new FIFOSchedulableBuilder(rootPool)
case SchedulingMode.FAIR =>
new FairSchedulableBuilder(rootPool, conf)
case _ =>
throw new IllegalArgumentException(s"Unsupported $SCHEDULER_MODE_PROPERTY: " +
s"$schedulingMode")
}
}
schedulableBuilder.buildPools()
}
接着下面两行代码:
_dagScheduler = new DAGScheduler(this)
创建DAG有向无环图,实现类面向stage的调度机制的高层次调度层,他会为每个stage计算DAG(有向无环图),追踪RDD和stage的输出是否被物化(写入磁盘或内存),并且寻找一个最少消耗的调度机制来运行job。它会将stage作为taskSets提交到底层的TaskSchedulerImpl上来在集群运行。除了处理stage的DAG,它还负责决定运行每个task的最佳位置,基于当前的缓存状态,将最佳位置提交给底层的TaskSchedulerImpl,此外,他会处理由于每个shuffle输出文件导致的失败,在这种情况下旧的stage可能会被重新提交。一个stage内部的失败,如果不是由于shuffle文件丢失导致的失败,会被taskScheduler处理,它会多次重试每个task,还不行才会取消整个stage。
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
在上面创建好了TaskScheduler和SchedulerBackend后,告诉 HeartbeatReceiver(心跳) 的监听端。
最后:
_taskScheduler.start()
在TaskSchedulerImpl的start()方法中调的是SchedulerBackend的start()方法,所以start()方法运行的是这段:
override def start() {
super.start()
// SPARK-21159. The scheduler backend should only try to connect to the launcher when in client
// mode. In cluster mode, the code that submits the application to the Master needs to connect
// to the launcher instead.
if (sc.deployMode == "client") {
launcherBackend.connect()
}
//参数设置
val appDesc = ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
webUrl, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
这里创建了两个对象:AppliactionDescription和AppClient,AppliactionDescription顾名思义就是对Application的描述类,比如它需要的资源等;AppClient负责负责为application与spark集群通信。SchedulerBackend的start()最终调用了AppClient的start(),代码如下:
def start() {
// Just launch an rpcEndpoint; it will call back into the listener.
endpoint.set(rpcEnv.setupEndpoint("AppClient", new ClientEndpoint(rpcEnv)))
}
启动一个rpcEndPoint并回调给监听器,RPC原理可看这篇 https://www.cnblogs.com/superhedantou/p/7570692.html
最后画个大概流程图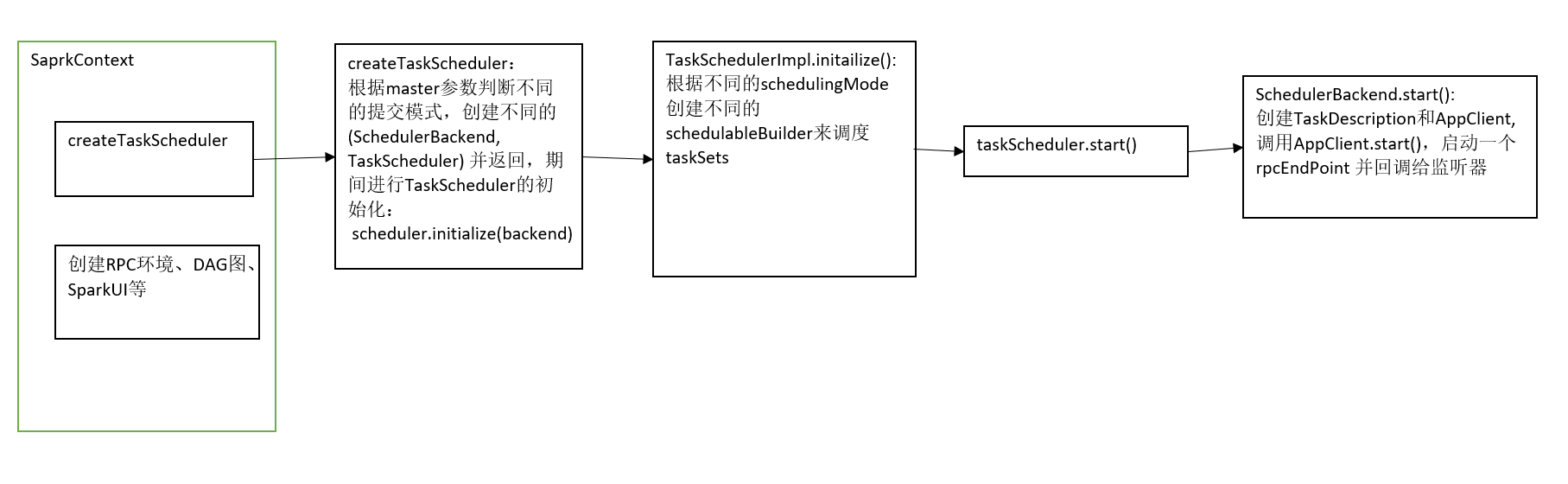
Spark-2.4.0源码:sparkContext的更多相关文章
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- 【Spark2.0源码学习】-1.概述
Spark作为当前主流的分布式计算框架,其高效性.通用性.易用性使其得到广泛的关注,本系列博客不会介绍其原理.安装与使用相关知识,将会从源码角度进行深度分析,理解其背后的设计精髓,以便后续 ...
- Scala 深入浅出实战经典 第65讲:Scala中隐式转换内幕揭秘、最佳实践及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- Scala 深入浅出实战经典 第61讲:Scala中隐式参数与隐式转换的联合使用实战详解及其在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载: 百度云盘:http://pan.baidu.com/s/1c0noOt ...
- Scala 深入浅出实战经典 第60讲:Scala中隐式参数实战详解以及在Spark中的应用源码解析
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载:百度云盘:http://pan.baidu.com/s/1c0noOt6 ...
- spark2.0源码学习
[Spark2.0源码学习]-1.概述 [Spark2.0源码学习]-2.一切从脚本说起 [Spark2.0源码学习]-3.Endpoint模型介绍 [Spark2.0源码学习]-4.Master启动 ...
- Spark1.0.0 源码编译和部署包生成
问题导读:1.如何对Spark1.0.0源码编译?2.如何生成Spark1.0的部署包?3.如何获取包资源? Spark1.0.0的源码编译和部署包生成,其本质只有两种:Maven和SBT,只不过针对 ...
- Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark.由于MapRedu ...
- Spark 2.1.1 源码编译
Spark 2.1.1 源码编译 标签(空格分隔): Spark Spark 源码编译 环境准备与起因 由于线上Spark On Yarn Spark Streaming程序在消费kafka 写入HD ...
- AFNetworking 3.0 源码解读 总结(干货)(下)
承接上一篇AFNetworking 3.0 源码解读 总结(干货)(上) 21.网络服务类型NSURLRequestNetworkServiceType 示例代码: typedef NS_ENUM(N ...
随机推荐
- 【转】Unity3D如何制作落叶效果
原文地址:http://hi.baidu.com/cupgenie/item/c23861df692f59e3b3f777a8 创建一个粒子系统 GameObject>Create other& ...
- Hibernate Validator--创建自己的约束规则
尽管Bean Validation API定义了一大堆标准的约束条件, 但是肯定还是有这些约束不能满足我们需求的时候, 在这种情况下, 你可以根据你的特定的校验需求来创建自己的约束条件. 3.1. 创 ...
- Spring MVC配置详解(3)
一.Spring MVC环境搭建:(Spring 2.5.6 + Hibernate 3.2.0) 1. jar包引入 Spring 2.5.6:spring.jar.spring-webmvc.ja ...
- AxInterop.ShockwaveFlashObjects.dll 问题
在实际项目中引用此dll加载项目启动动画(swf),但在64位上此dll并不支持,解决办法有待商讨,个人在项目中,把加载动画的部分给注释掉了,不给项目中签入,他们用的都是32位系统,我的是64位的.请 ...
- Java探索之旅(7)——对象的思考
1.知识要点 ❶不可变类:一旦创建,其内容不能改变的类称之为不可变类.满足:⑴所有数据域私有,⑵没有修改器,⑶没有访问器方法,其返回一个指向可变数据域的引用.(这样通过引用就能修改私有数据域).比如, ...
- Servlet处理流程分析
---------------siwuxie095 Tomcat 处理客户端请求的方式: Tomcat 既是一个 Servlet ...
- hibernate查询的方式和变量
1.实体查询: hql="FROM User"; List list= session.createQuery(hql).list(); for(Object obj:list){ ...
- javascript 数组中出现的次数最多的元素
javascript 数组中出现的次数最多的元素 var arr = [1,-1,2,4,5,5,6,7,5,8,6]; var maxVal = arr[0]; // 数组中的最大值 var min ...
- jQuery 选择表格(table)里的行和列及改变简单样式
本文只是介绍如何用jQuery语句对表格中行和列进行选择以及一些简单样式改变,希望它可以对jQuery表格处理的深层学习提供一些帮助jQuery对表格(table)的处理提供了相当强大的功能,比如说对 ...
- BK Componet Monitor
Apache a) 启动服务前将监听地址改成0.0.0.0 b) 确认在文件“/etc/httpd/conf.modules.d/00-base.conf“中有加载mod_status模块 c) 新建 ...