sklearn解决过拟合的例子
Learning curve 检视过拟合
sklearn.learning_curve 中的 learning curve 可以很直观的看出我们的 model 学习的进度, 对比发现有没有 overfitting 的问题. 然后我们可以对我们的 model 进行调整, 克服 overfitting 的问题.
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: https://www.youtube.com/channel/UCdyjiB5H8Pu7aDTNVXTTpcg
# Youku video tutorial: http://i.youku.com/pythontutorial """
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
"""
from __future__ import print_function
from sklearn.learning_curve import learning_curve
from sklearn.datasets import load_digits
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np digits = load_digits()
X = digits.data
y = digits.target
train_sizes, train_loss, test_loss= learning_curve(
SVC(gamma=0.01), X, y, cv=10, scoring='mean_squared_error',
train_sizes=[0.1, 0.25, 0.5, 0.75, 1])
train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1) plt.plot(train_sizes, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(train_sizes, test_loss_mean, 'o-', color="g",
label="Cross-validation") plt.xlabel("Training examples")
plt.ylabel("Loss")
plt.legend(loc="best")
plt.show()

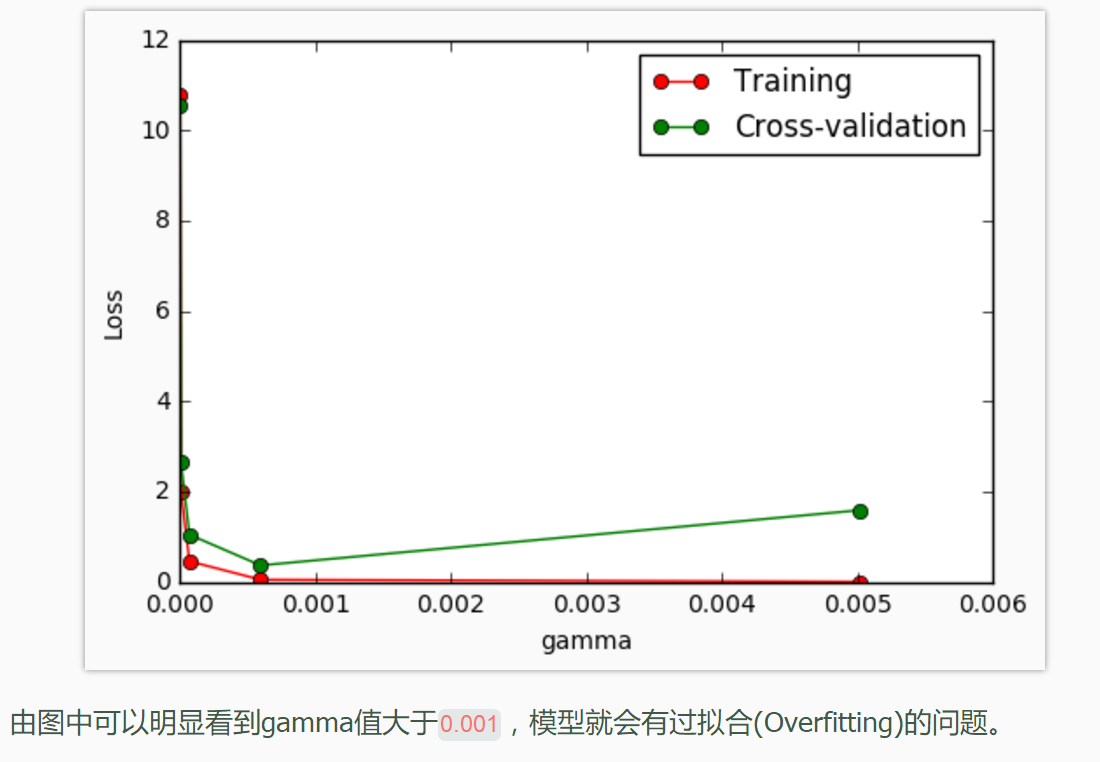
validation_curve 检视过拟合
用这一种曲线我们就能更加直观看出改变模型中的参数的时候有没有过拟合(overfitting)的问题了. 这也是可以让我们更好的选择参数的方法.
from sklearn.learning_curve import validation_curve #学习曲线模块
from sklearn.datasets import load_digits #digits数据集
from sklearn.svm import SVC #Support Vector Classifier
import matplotlib.pyplot as plt #可视化模块
import numpy as np digits = load_digits()
X = digits.data
y = digits.target
#建立参数测试集
param_range = np.logspace(-6, -2.3, 5)
#使用validation_curve快速找出参数对模型的影响
train_loss, test_loss = validation_curve(
SVC(), X, y, param_name='gamma', param_range=param_range, cv=10, scoring='mean_squared_error') train_loss_mean = -np.mean(train_loss, axis=1)
test_loss_mean = -np.mean(test_loss, axis=1) #可视化图形
plt.plot(param_range, train_loss_mean, 'o-', color="r",
label="Training")
plt.plot(param_range, test_loss_mean, 'o-', color="g",
label="Cross-validation") plt.xlabel("gamma")
plt.ylabel("Loss")
plt.legend(loc="best")
sklearn解决过拟合的例子的更多相关文章
- tensorflow学习之路---解决过拟合
''' 思路:1.调用数据集 2.定义用来实现神经元功能的函数(包括解决过拟合) 3.定义输入和输出的数据4.定义隐藏层(函数)和输出层(函数) 5.分析误差和优化数据(改变权重)6.执行神经网络 ' ...
- L1与L2正则化的对比及多角度阐述为什么正则化可以解决过拟合问题
正则化是一种回归的形式,它将系数估计(coefficient estimate)朝零的方向进行约束.调整或缩小.也就是说,正则化可以在学习过程中降低模型复杂度和不稳定程度,从而避免过拟合的危险. 一. ...
- 过拟合是什么?如何解决过拟合?l1、l2怎么解决过拟合
1. 过拟合是什么? https://www.zhihu.com/question/264909622 那个英文回答就是说h1.h2属于同一个集合,实际情况是h2比h1错误率低,你用h1来训练, ...
- drop解决过拟合的情况
用到的训练数据集:sklearn数据集 可视化工具:tensorboard,这儿记录了loss值(预测值与真实值的差值),通过loss值可以判断训练的结果与真实数据是否吻合 过拟合:训练过程中为了追求 ...
- sklearn中predict_proba的用法例子(转)
predict_proba返回的是一个n行k列的数组,第i行第j列上的数值是模型预测第i个预测样本的标签为j的概率.所以每一行的和应该等于1. 举个例子 >>> from sklea ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- 深度学习中 --- 解决过拟合问题(dropout, batchnormalization)
过拟合,在Tom M.Mitchell的<Machine Learning>中是如何定义的:给定一个假设空间H,一个假设h属于H,如果存在其他的假设h’属于H,使得在训练样例上h的错误率比 ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- sklearn解决分类问题(KNN,线性判别函数,二次判别函数,KMeans,MLE,人工神经网络)
代码:*******************加密中**************************************
随机推荐
- 2015 ETSI NFV用例指南
译者简介:忍忍鱼,曾经从SDNLAB获取了很多知识,现在努力为SDNLAB贡献自己的力量.爱学习,求进步!SDNLAB,么么哒! ETSI NFV ISG已经确定了9个潜在的NFV用例.本章节简单介绍 ...
- linux apt-get remove如何恢复
linux卸载或删除软件时,若不小心删除到关联的软件,如果想撤销删除操作需要在/var/log/apt/history.log中依次安装删除的软件,具体操作如下: $echo '#!/bin/bash ...
- RouterOS(ROS)简单限速/单IP限速脚
暂无评论 有时企业环境,或个人使用环境需要针对不同IP设置较多条不同限速,可以使用以下脚本批量处理后,再针对性的修改. *脚本说明:“2 to 254”定义要设置受限IP的起始,后面“192.168. ...
- Java IO 简记
1.File 类: l java.io.File类:文件和目录路径名的抽象表示形式,与平台无关 l File 能新建.删除.重命名文件和目录,但 File 不能访问文件内容本身.如果需要访问文件内 ...
- Cassini(卡西尼)投影
- GridView有用的小方法--2017年2月13日
原文:http://blog.csdn.net/21aspnet/article/category/285354更多:http://blog.csdn.net/21aspnet/article/cat ...
- django autocommit的一个坑,读操作的事务占用导致锁表
版权归作者所有,任何形式转载请联系作者.作者:petanne(来自豆瓣)来源:https://www.douban.com/note/580618150/ 缘由:有一个django守护进程Daemon ...
- 11g 如何添加,替换,移除,迁移 OCR ?
一: 增加 裸设备上,创建至少280MB的裸设备,权限是640,属主是root:oinstall共享文件系统 Or NFS,创建空文件,权限是640,属主是root:oinstall root用户执行 ...
- poj 2187 Beauty Contest —— 旋转卡壳
题目:http://poj.org/problem?id=2187 学习资料:https://blog.csdn.net/wang_heng199/article/details/74477738 h ...
- 最长递增子序列(LIS)
最长递增子序列(Longest Increasing Subsequence) ,我们简记为 LIS. 题:求一个一维数组arr[i]中的最长递增子序列的长度,如在序列1,-1,2,-3,4,-5,6 ...