学习笔记:Hashtable和HashMap
学了这么些天的基础知识发现自己还是个门外汗,难怪自己一直混的不怎么样。但这样的恶补不知道有没有用,是不是过段时间这些知识又忘了呢?这些知识平时的工作好像都是随拿随用的,也并不是平时一点没有关注过这些基础知识,只是用完了也就忘了。所以写笔记也是个好习惯,光看一个概念不容易记住,整理写成文那就好许多,以后查起来也方便一些。
为什么要用Hash Table?
什么是Hash Table
散列表(Hash table,也叫哈希表),是根据关键字(Key value)而直接访问在内存存储位置的数据结构。也就是说,它通过把键值通过一个函数的计算,映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
- 若关键字为
,则其值存放在
的存储位置上。由此,不需比较便可直接取得所查记录。称这个对应关系
为散列函数,按这个思想建立的表为散列表。
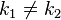 ,而
,而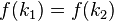 ,这种现象称为碰撞(
,这种现象称为碰撞(
散列函数能使对一个数据序列的访问过程更加迅速有效,通过散列函数,数据元素将被更快定位。
- 直接定址法:取关键字或关键字的某个线性函数值为散列地址。即
或
,其中
为常数(这种散列函数叫做自身函数)
- 数字分析法:假设关键字是以r为基的数,并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
- 平方取中法:取关键字平方后的中间几位为哈希地址。通常在选定哈希函数时不一定能知道关键字的全部情况,取其中的哪几位也不一定合适,而一个数平方后的中间几位数和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的。取的位数由表长决定。
- 折叠法:将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址。
- 随机数法:将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
- 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即
,
。不仅可以对关键字直接取模,也可在折叠法、平方取中法等运算之后取模。对p的选择很重要,一般取素数或m,若p选择不好,容易产生碰撞。
- 开放定址法:如果发生冲突就继续找下一个空的散列地址
- 单独链表法:即在发生冲突的位置直接使用链表保存冲突的数据
- 再散列:即在上次散列计算发生碰撞时,用另一个散列函数计算新的散列函数地址,直到碰撞不再发生
- 建立公共溢出区:建立基本表和溢出表,冲突的就放到溢出区
简单学习下Hash Table的机制
存储结构
/**
* The hash table data.
*/
private transient Entry[] table;
再看数据链表
/**
* Hashtable collision list.
*/
private static class Entry<K,V> implements Map.Entry<K,V> {
int hash;
K key;
V value;
Entry<K,V> next; protected Entry(int hash, K key, V value, Entry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
} protected Object clone() {
return new Entry<K,V>(hash, key, value,
(next==null ? null : (Entry<K,V>) next.clone()));
} // Map.Entry Ops public K getKey() {
return key;
} public V getValue() {
return value;
} public V setValue(V value) {
if (value == null)
throw new NullPointerException(); V oldValue = this.value;
this.value = value;
return oldValue;
} public boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o; return (key==null ? e.getKey()==null : key.equals(e.getKey())) &&
(value==null ? e.getValue()==null : value.equals(e.getValue()));
} public int hashCode() {
return hash ^ (value==null ? 0 : value.hashCode());
} public String toString() {
return key.toString()+"="+value.toString();
}
}
其实还是挺简单的,就是一个Entry数组,而Entry就是一个键值关系表,同时提供了链表的功能。
数据存取
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
Entry<K,V> e = tab[index];
tab[index] = new Entry<K,V>(hash, key, value, e);
count++;
return null;
}
- 这里看到了线程同步关键字,因为整个hashtable都是线程同步的,所以在线程里用也是木有问题的
- 注意valua是不能为null的会抛异常
- 将要存的数据以key-value的方式放进去,先通过key计算Hash值,就是数组位置
看看关键代码:
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
先得到key的hashcode,再通过除留余数法得到数组索引,简单高效就得到了存储位置。
- 然后后面的代码看看有没有相同的项目,有则替换之。最后创建一个Entry对象保存数据,如果存在碰撞Entry会自动写入链表中解决冲突。
获得数据的方法就是get:
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
计算数组下标的方法是一样的,这样的定位方式特别高效,只要计算一次就可以了,当然如果有冲突的话还要遍历链表对比hash和key再确定最终的数据项。
再看看HashMap
- key和value支持null,这种情况下总是存在数组中的第一个元素中,感觉是种特殊公共溢出区的应用
- 不是线程安全的,需要自己做线程同步
- 计算存储位置时采用了在hashcode上再次hash+indexFor的方法,使得得到的散列值更均匀
学习笔记:Hashtable和HashMap的更多相关文章
- stl源码剖析 详细学习笔记 hashtable
//---------------------------15/03/24---------------------------- //hashtable { /* 概述: sgi采用的是开链法完成h ...
- HashMap源码剖析及实现原理分析(学习笔记)
一.需求 最近开发中,总是需要使用HashMap,而为了更好的开发以及理解HashMap:因此特定重新去看HashMap的源码并写下学习笔记,以便以后查阅. 二.HashMap的学习理解 1.我们首先 ...
- 基于jdk1.8的HashMap源码学习笔记
作为一种最为常用的容器,同时也是效率比较高的容器,HashMap当之无愧.所以自己这次jdk源码学习,就从HashMap开始吧,当然水平有限,有不正确的地方,欢迎指正,促进共同学习进步,就是喜欢程序员 ...
- java集合类学习笔记之HashMap
1.简述 HashMap是java语言中非常典型的数据结构,也是我们平常用的最多的的集合类之一.它的底层是通过一个单向链表(Node<k,v>)数组(也称之为桶bucket,数组的长度也叫 ...
- HashMap源代码学习笔记
HashMap的底层主要是基于数组和链表来实现的,它之所以有相当快的查询速度主要是由于它是通过计算散列码来决定存储的位置. HashMap中主要是通过key的hashCode来计算hash值的 ...
- 《Java学习笔记(第8版)》学习指导
<Java学习笔记(第8版)>学习指导 目录 图书简况 学习指导 第一章 Java平台概论 第二章 从JDK到IDE 第三章 基础语法 第四章 认识对象 第五章 对象封装 第六章 继承与多 ...
- Redis学习笔记一:数据结构与对象
1. String(SDS) Redis使用自定义的一种字符串结构SDS来作为字符串的表示. 127.0.0.1:6379> set name liushijie OK 在如上操作中,name( ...
- 20145330第五周《Java学习笔记》
20145330第五周<Java学习笔记> 这一周又是紧张的一周. 语法与继承架构 Java中所有错误都会打包为对象可以尝试try.catch代表错误的对象后做一些处理. 使用try.ca ...
- Java学习笔记4
Java学习笔记4 1. JDK.JRE和JVM分别是什么,区别是什么? 答: ①.JDK 是整个Java的核心,包括了Java运行环境.Java工具和Java基础类库. ②.JRE(Java Run ...
- JavaSE中Map框架学习笔记
前言:最近几天都在生病,退烧之后身体虚弱.头疼.在床上躺了几天,什么事情都干不了.接下来这段时间,要好好加快进度才好. 前面用了三篇文章的篇幅学习了Collection框架的相关内容,而Map框架相对 ...
随机推荐
- android UI控件小记
1.关于text和drawableTop之类的间距 android:drawablePadding="10dp" 2.EditText属性 android:phoneNumber= ...
- 当攻击者熟读兵法,Camouflage病毒实战演示暗度陈仓之计
"明修栈道,暗度陈仓"的典故许多人都听说过,该典故出自楚汉争霸时期,刘邦意图进入关中,需要攻下关中咽喉之地--陈仓.韩信献出一计:表面上浩浩荡荡地修复通往陈仓的栈道以迷惑陈仓守将, ...
- 在nginx中配置ip直接访问的默认站点
一台机子部署多个网站,我们直接访问ip (外网内网都一样)提示无法访问或404. 因为有多个网站,我们想指定某个网站为IP访问默认的网站,如何操作呢? 解:在Listen ip:port; 这个指令行 ...
- Hadoop单机模式安装-(2)安装Ubuntu虚拟机
网络上关于如何单机模式安装Hadoop的文章很多,按照其步骤走下来多数都失败,按照其操作弯路走过了不少但终究还是把问题都解决了,所以顺便自己详细记录下完整的安装过程. 此篇主要介绍在虚拟机设置完毕后, ...
- Codeforces #380 Subordinates(贪心 构造)
从前往后扫,找到一出现次数为0的数,从后面找一个出现不为0的数转化而来.设置两指针l, r来处理. #include<cstdio> #include<iostream> #i ...
- jQuery九类选择器详解
(1)基本选择器 <body> <div id="div1ID">div1</div> <div id="div2ID" ...
- strip_tags、htmlspeciachars
strip_tags:过滤html.xml标签: htmlspecialchars:把预定义自负转化为html实体:包括<.>.'.".& sql注入:将'." ...
- python 爬虫(五)
下载媒体文件 I 使用urllib.request.urlretrieve方法可以下载文件存为指定文件 from urllib.request import urlretrieve from urll ...
- silverlight使用小计(先做记录后续整理)
1.Grid: a.通过获取指定行的高度和指定列的宽度来获取指定单元格的宽高 b.几种宽高默认值: 宽高(Width/Heigth):1* 最大宽高(MaxWidth/MaxHeigth):正无穷大 ...
- Vue - 实例
1.实例属性介绍如下图所示: 具体介绍如下: A.$parent:访问当前组件的父实例 B.$root:访问当前组件的根实例,要是没有的话,则是自己本身 C.$children:访问当前组件实例的直接 ...