Multi-modal Sentence Summarization with Modality Attention and Image Filtering 论文笔记
文章已同步更新在https://ldzhangyx.github.io/,欢迎访问评论。
五个月没写博客了,不熟悉我的人大概以为我挂了……
总之呢这段时间还是成长了很多,在加拿大实习的两个多月来,我在编码能力和眼界上都有了极大长进。当然,我也点上了烹饪技能点。
废话不多说,我们来看一篇论文,就是标题所说的使用模态注意力和图像过滤机制的多模态句子摘要。
====================
个人见解
宗成庆老师的这篇文章发表于ACL'18,同时获得了国家自然科学基金的支持。文章着眼于利用图片信息提升摘要与原文本的相关性。
原文:www.nlpr.ia.ac.cn/cip/ZongPublications/2018/2018HaoranLiIJCAI.pdf
在处理图片信息的时候,这个模型使用了VGG-19,提取特征的能力上没有什么问题。
亮点
这篇文章的思路与一般的额外信息有一些区别,同是用额外信息干涉指导文本生成,这个模型同时使用了两个attention,并提出了一种加权机制将两个attention组合起来。在我读过的另一篇文章《Diversity driven Attention Model for Query-based Abstractive Summarization》中,作者试图用query的context干涉document的context,而不直接显性参与decoder的过程。
文中计算权值的时候,充分考虑了各种可能性;在Image Attention Filter那一块,将数个特征非线性组合起来,虽然显得参数有点多,好在不无道理。
贡献了一个全新的数据集(动用了10个研究生,真有钱),脱胎于Gigawords,对这个领域做出了基础性贡献。
想法
首先,对于数据集,我认为可以选择替代的数据集,可能是我之前做过中文摘要,我很自然地就想到了LCSTS,可以用同样的方法构建数据集,但是这个很费时间精力,而且并不是什么突出的想法贡献。
其次,为什么用VGG提取特征?在这个框架里,VGG提取特征取到的效果我持保留态度。即使有了图片特征又能怎么样呢?到底是一个怎样的机制让VGG的图片特征与关键字对上的?我认为这样的attention拼凑框架思路时非常棒的,但是图片特征与文字的多模态映射我始终不明白how it works. 作为替代方法,我很自然地想到了CV里的目标检测,使用选择性搜索,SVM判断图像中的实体,再作为特征送进模型,我认为这是一个更接近直觉的做法。
再次,Image Filtering这个做法我认为需要改进为更加reasonable的做法。我们完全可以做一个key-word版本的Filter。Filter有两个版本,Image Attention Filter的系数Ia是根据图像与文本的相关性来控制图像干预的程度;而Image Context Filter的系数Tc是用来突出图像特征的。这个想法理应可以迁移到word的使用上。
最后,文中用到的小trick,texrual coverage mechanism,为了解决结巴问题,我们可以考虑其他的机制,比如将context vector做软正交化处理。
====================
摘要
本文介绍了一种多模态句子摘要任务,输入为一张图片和一对句子,输出为摘要。作者称其为MMSS任务。任务的难点在于怎么将视觉信息输入到框架里,以及怎么减小噪音。针对这两个问题,作者分别提出了两个方法:同时施加不同的注意力到文本和图片上;使用图像过滤Image Filter来降噪。
介绍主要是讲了文本摘要的历史,以及多模态方法最早应用在翻译领域,表现特别好,但是作者认为在摘要上表现得应该更好。
在解决MMSS任务的时候,作者准备使用分层注意力机制,底层分别关注图片和文本的内部,而上层对两个模态进行平衡。因为图片不能表现很多抽象内容,所以图片特征需要过滤去噪;为了解决生成句子结巴的问题,使用了coverage方法。
顺便他们做了一个数据集,真是让人肝疼的工作量。

图片展示了多模态模型的实际效果要好于文本模型。
模型
模型简图如下:
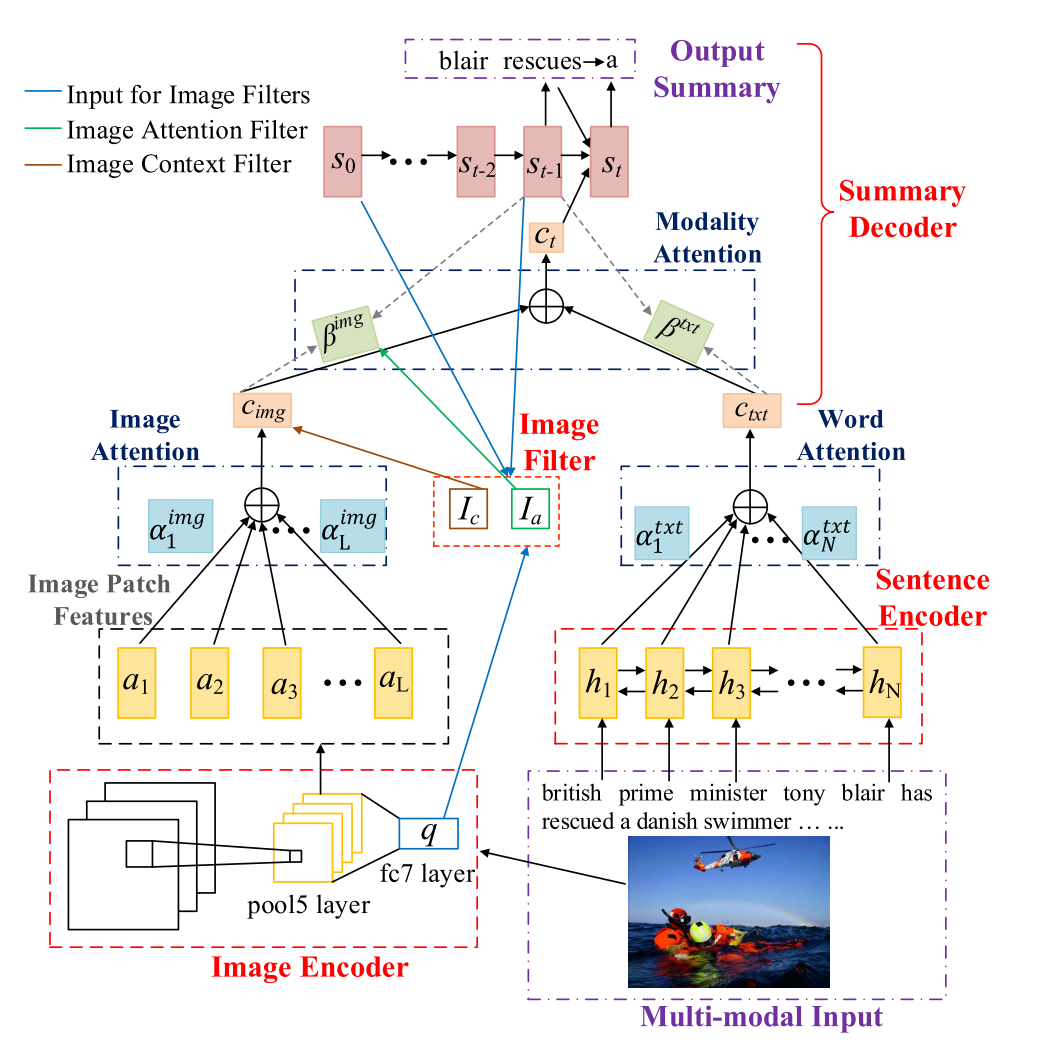
模型可见由句子编码器,图片编码器,摘要解码器和图片过滤器四个部分组成。
Encoder
句子编码器使用的是双向GRU,这个没什么好说的。
图片编码器使用了VGG19,抽取了两种特征:7x7x512的局部特征(flatten之后成为了49x512),和4096维的全局特征。其中局部特征表示为
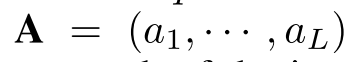
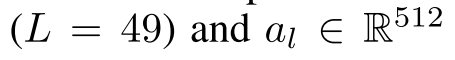
Decoder
单元使用单向的GRU:
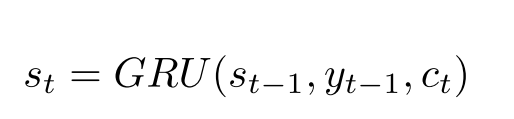
初始状态$s_0$进行了改进。
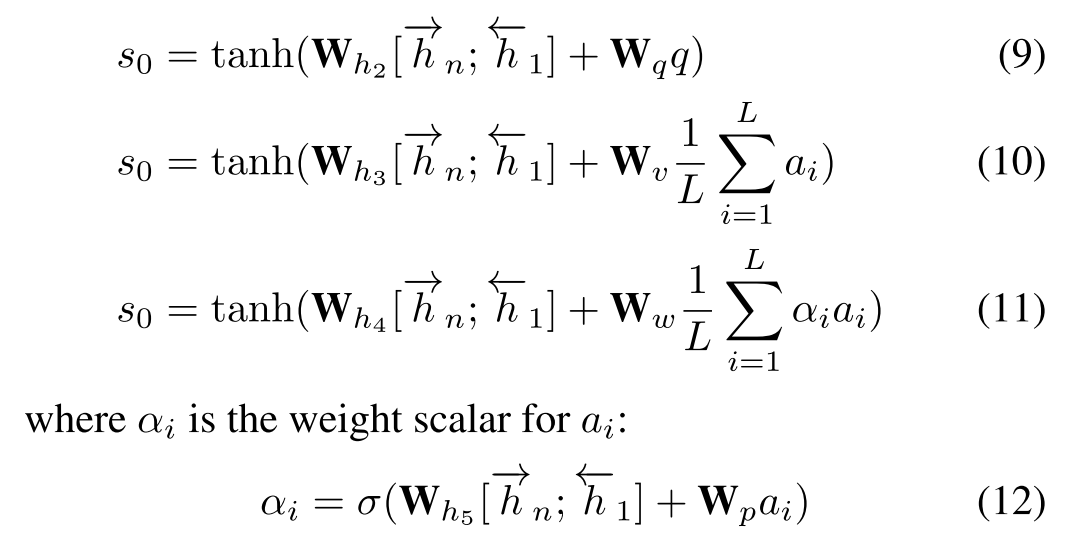
其中,q为全局特征,a为各个局部特征,如上文所说。
图像和两边的context使用下述公式进行平衡和维度统一:
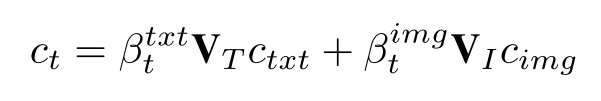
两个β都是系数:
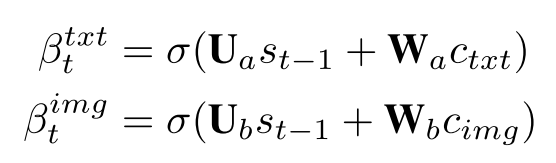
而对于context的计算与原先的attention没有两样。
对于文字attention:

但是对于图片attention有一些不同的地方在于,图片类似于文本的序列输入,所以对每个图片进行注意力加权:
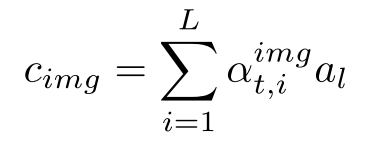

文章也提到了coverage model,但是我在这里略过。
Image Filter
文章提到了两种filter:Image Attention Filter和Image Context Filter。
Image Attention Filter的目的在于“directly applied to change the attention scale between image and text”,即根据图片相关性进行数值控制。

其中$s_0$是decoder的初始状态,q是图片全局特征,这两个参数用来表示图片相关性;$s_{t-1}$是decoder上一个time step的状态,用来表示与下一个单词的联系。
对于Image Context Vector,作者解释是脱胎于以前的思路(“Image context filter is partially inspired by gating mechanism which has gained great popularity in neural network models”),但是应用在多模态方法上仍属创新。
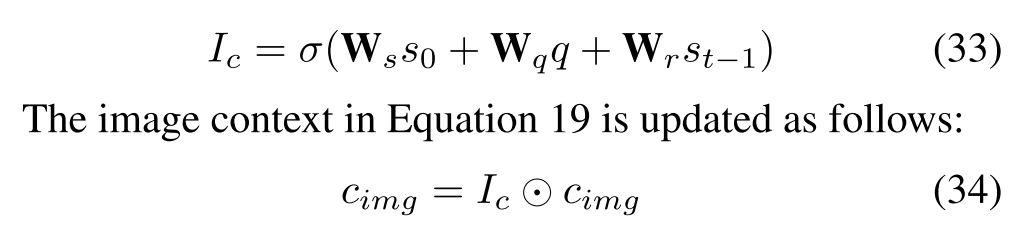
数据集
数据集的文本部分来源于Gigaword Corpus,作者使用Yahoo,以摘要为关键词搜索了top 5的图片,最后由真人选出最适合的,还做了交叉验证,最后剩下66000左右的数据。
评测结果
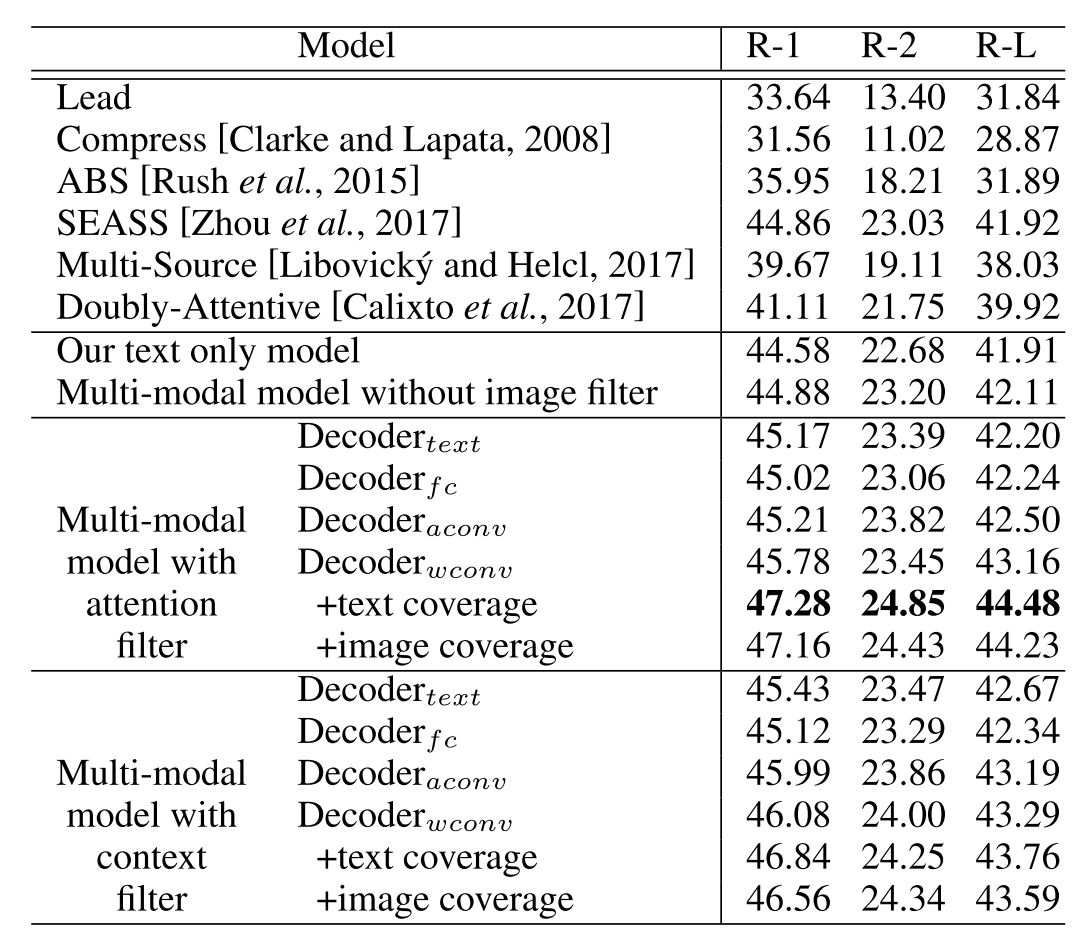
进步是显著的,但作者的很多结论还是进行了实验,然后反推进行最后的选择。这也是一个做选择的思路——都试试看就行了。
Multi-modal Sentence Summarization with Modality Attention and Image Filtering 论文笔记的更多相关文章
- facebook 摘要生成阅读笔记(一) A Neural Attention Model for Sentence Summarization
流程: 1.文本和摘要全部输入到模型中. 2.训练时,对生成摘要取前C个词,从头开始取,如果生成的摘要不足C,那么不足的地方直接补<s>. 3.训练时,最大化生成的摘要与原摘要的概率,即每 ...
- facebook 摘要生成阅读笔记(二) Abstractive Sentence Summarization with Attentive Recurrent Neural Networks
整体流程与第一篇差不多,只是在encoder和decoder加入了RNN Encoder: 1. ai=xi+li ai=词向量+词在序列中的位置信息(相当于一个权重,[M, 1]) 流程: 先是CN ...
- 论文笔记:A Structured Self-Attentive Sentence Embedding
A Structured Self-Attentive Sentence Embedding ICLR 2017 2018-08-19 14:07:29 Paper:https://arxiv.org ...
- 论文笔记之:Deep Attention Recurrent Q-Network
Deep Attention Recurrent Q-Network 5vision groups 摘要:本文将 DQN 引入了 Attention 机制,使得学习更具有方向性和指导性.(前段时间做 ...
- 论文笔记之:Multiple Object Recognition With Visual Attention
Multiple Object Recognition With Visual Attention Google DeepMind ICRL 2015 本文提出了一种基于 attention 的用 ...
- 论文笔记之:Attention For Fine-Grained Categorization
Attention For Fine-Grained Categorization Google ICLR 2015 本文说是将Ba et al. 的基于RNN 的attention model 拓展 ...
- 论文笔记之: Recurrent Models of Visual Attention
Recurrent Models of Visual Attention Google DeepMind 模拟人类看东西的方式,我们并非将目光放在整张图像上,尽管有时候会从总体上对目标进行把握,但是也 ...
- 论文笔记之:Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition
Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition Baidu ...
- 论文笔记之:Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grained Recognition
Fully Convolutional Attention Localization Networks: Efficient Attention Localization for Fine-Grain ...
随机推荐
- 1022 D进制的A+B (20 分)
输入两个非负 10 进制整数 A 和 B (≤),输出 A+B 的 D (1)进制数. 输入格式: 输入在一行中依次给出 3 个整数 A.B 和 D. 输出格式: 输出 A+B 的 D 进制数. 输入 ...
- powershell和cmd区别
Powershell是cmd的超集,换句话说,cmd能做的事情,Powershell都能做,但是Powershell还能额外做许多cmd不能做的活. 主要是系统管理功能.脚本语言和在线帮助更强大,你确 ...
- python 函数调用
##########定义函数######### 如果不主动调用函数,函数是不会执行的 def say_hello(): print 'hello1' print 'hello2' ...
- 阿里Java开发规约(1)
本文是对阿里插件中规约的详细解释一,关于插件使用,请参考这里 1. ArrayList的subList结果不可强转成ArrayList,否则会抛出ClassCastException异常. 说明:禁止 ...
- C语言标准库函数memcpy和memmove的区别以及内存重叠问题处理
①memcpy()和memmove()都是C语言中的标准库函数,定义在头文件string.h中,作用是拷贝一定长度的内存的内容,原型分别如下: void *memcpy(void *dst, cons ...
- linux查看当前用户登陆信息
@(Linux基础)[linux查看当前用户登陆信息] linux查看当前用户登陆信息 作为系统管理员,你可能经常会(在某个时候)需要查看系统中有哪些用户正在活动.有些时候,你甚至需要知道他(她)们正 ...
- idea进行断点快捷键
快捷键 功能描述 F8 单步调试,不进入函数内部 F7 单步调试,进入函数内部 Shift+F7 选择要进入的函数 Shift+F8 跳出函数 Alt+F9 运行到断点 Alt+F8 执行表达式查看结 ...
- 可视化开发_AppInventor2似乎被抛弃了
工具 blockly google,mixly,scratch,app inventor2 的分别 可视化编程,青雀,来自 白鹭 没源码 如果想二次开发呢,初版拖拽控件生成,后期维护的时候找程序员加功 ...
- 牛客网练习赛28A
题目链接:https://www.nowcoder.com/acm/contest/200/A 链接:https://www.nowcoder.com/acm/contest/200/A来源:牛客网 ...
- [转]jQuery: get table column/row index remove table column (by column number)
本文转自:http://www.xinotes.org/notes/note/1087/ <!DOCTYPE html><html><head> <title ...