基于mllib的协同过滤实战(电影推荐)
//加载需要的包 import org.apache.spark.rdd._
import org.apache.spark.mllib.recommendation.{ALS, Rating, MatrixFactorizationModel} //读取数据
val ratings = sc.textFile("D:/BaiduYunDownload/machine-learning/movielens/medium/ratings.dat").map { line =>
val fields = line.split("::")
(fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble))
}

//数据情况探索(评分数,用户数,物品数)
val numRatings = ratings.count()
val numUsers = ratings.map(_._2.user).distinct().count()
val numMovies = ratings.map(_._2.product).distinct().count()
println("Got " + numRatings + " ratings from " + numUsers + " users on " + numMovies + " movies.")
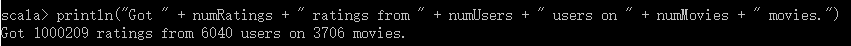
//某个人评分数据
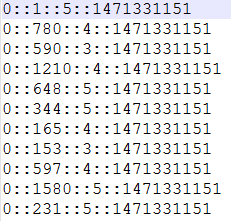
val myRatingsRDD = sc.textFile("D:/BaiduYunDownload/machine-learning/bin/personalRatings.txt").map { line =>
val fields = line.split("::")
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble)
}

//拆分训练集,校验集,测试集(ratings是(Int,Rating)格式,取values即可)
val numPartitions = 4
val training = ratings.filter(x => x._1 < 6)
.values
.union(myRatingsRDD) //加入个人评分数据
.repartition(numPartitions)
.cache()
val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8)
.values
.repartition(numPartitions)
.cache()
val test = ratings.filter(x => x._1 >= 8).values.cache()
val numTraining = training.count()
val numValidation = validation.count()
val numTest = test.count()
println("Training: " + numTraining + ", validation: " + numValidation + ", test: " + numTest)

// 校验集预测数据和实际数据之间的均方根误差
def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], n: Long): Double = {
val predictions: RDD[Rating] = model.predict(data.map(x => (x.user, x.product)))
val predictionsAndRatings = predictions.map(x => ((x.user, x.product), x.rating))
.join(data.map(x => ((x.user, x.product), x.rating)))
.values
math.sqrt(predictionsAndRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).reduce(_ + _) / n)
}
//训练不同参数下的模型,并在校验集中验证,获取最佳参数下的模型
val ranks = List(8, 12)
val lambdas = List(0.1, 10.0)
val numIters = List(10, 20)
var bestModel: Option[MatrixFactorizationModel] = None
var bestValidationRmse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestNumIter = -1
for (rank <- ranks; lambda <- lambdas; numIter <- numIters) {
val model = ALS.train(training, rank, numIter, lambda)
val validationRmse = computeRmse(model, validation, numValidation)
println("RMSE (validation) = " + validationRmse + " for the model trained with rank = "
+ rank + ", lambda = " + lambda + ", and numIter = " + numIter + ".")
if (validationRmse < bestValidationRmse) {
bestModel = Some(model)
bestValidationRmse = validationRmse
bestRank = rank
bestLambda = lambda
bestNumIter = numIter
}
}
//用最佳模型作用于测试集,并计算预测评分和实际评分之间的均方根误差
val testRmse = computeRmse(bestModel.get, test, numTest)
println("The best model was trained with rank = " + bestRank + " and lambda = " + bestLambda
+ ", and numIter = " + bestNumIter + ", and its RMSE on the test set is " + testRmse + ".")

//比较将最佳模型作用于测试集的结果:testRmse 与 仅仅用均值预测的结果进行比较,计算模型提升度。
val meanRating = training.union(validation).map(_.rating).mean
val baselineRmse = math.sqrt(test.map(x => (meanRating - x.rating) * (meanRating - x.rating)).mean)
val improvement = (baselineRmse - testRmse) / baselineRmse * 100
println("The best model improves the baseline by " + "%1.2f".format(improvement) + "%.")

//装载电影目录对照表(电影ID->电影标题)
val movies = sc.textFile("D:/BaiduYunDownload/machine-learning/movielens/medium/movies.dat").map { line =>
val fields = line.split("::")
(fields(0).toInt, fields(1))
}.collect().toMap

// 推荐前十部最感兴趣的电影,注意要剔除用户已经评分的电影
val myRatedMovieIds = myRatingsRDD.map(_.product).collect().toSet
val candidates = sc.parallelize(movies.keys.filter(!myRatedMovieIds.contains(_)).toSeq)
val recommendations = bestModel.get{
.predict(candidates.map((0, _)))
.collect()
.sortBy(-_.rating)
.take(10)}

var i = 1
println("Movies recommended for you:")
recommendations.foreach { r =>
println("%2d".format(i) + ": " + movies(r.product))
i += 1
}

基于mllib的协同过滤实战(电影推荐)的更多相关文章
- 基于用户的协同过滤的电影推荐算法(tensorflow)
数据集: https://grouplens.org/datasets/movielens/ ml-latest-small 协同过滤算法理论基础 https://blog.csdn.net/u012 ...
- 基于用户的协同过滤电影推荐user-CF python
协同过滤包括基于物品的协同过滤和基于用户的协同过滤,本文基于电影评分数据做基于用户的推荐 主要做三个部分:1.读取数据:2.构建用户与用户的相似度矩阵:3.进行推荐: 查看数据u.data 主要用到前 ...
- 基于物品的协同过滤item-CF 之电影推荐 python
推荐算法有基于协同的Collaboration Filtering:包括 user Based和item Based:基于内容 : Content Based 协同过滤包括基于物品的协同过滤和基于用户 ...
- 【推荐系统实战】:C++实现基于用户的协同过滤(UserCollaborativeFilter)
好早的时候就打算写这篇文章,可是还是參加阿里大数据竞赛的第一季三月份的时候实验就完毕了.硬生生是拖到了十一假期.自己也是醉了... 找工作不是非常顺利,希望写点东西回想一下知识.然后再攒点人品吧,仅仅 ...
- 推荐召回--基于用户的协同过滤UserCF
目录 1. 前言 2. 原理 3. 数据及相似度计算 4. 根据相似度计算结果 5. 相关问题 5.1 如何提炼用户日志数据? 5.2 用户相似度计算很耗时,有什么好的方法? 5.3 有哪些改进措施? ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- 推荐召回--基于物品的协同过滤:ItemCF
目录 1. 前言 2. 原理&计算&改进 3. 总结 1. 前言 说完基于用户的协同过滤后,趁热打铁,我们来说说基于物品的协同过滤:"看了又看","买了又 ...
- Spark MLlib之协同过滤
原文:http://blog.selfup.cn/1001.html 什么是协同过滤 协同过滤(Collaborative Filtering, 简称CF),wiki上的定义是:简单来说是利用某兴趣相 ...
- Music Recommendation System with User-based and Item-based Collaborative Filtering Technique(使用基于用户及基于物品的协同过滤技术的音乐推荐系统)【更新】
摘要: 大数据催生了互联网,电子商务,也导致了信息过载.信息过载的问题可以由推荐系统来解决.推荐系统可以提供选择新产品(电影,音乐等)的建议.这篇论文介绍了一个音乐推荐系统,它会根据用户的历史行为和口 ...
随机推荐
- 同台电脑 多Git账号同时使用
前言 有次周末忘记带公司电脑回来,恰好遇到有个问题需要修复,又不想跑公司一趟,于是研究了下如何在自己电脑上同时使用两个 git 账号 正文 1. 首先就和第一次安装 git 时一样,使用 sha算法 ...
- MVC过滤大法(过滤静态文件)
参考文章:https://prerakkaushik.wordpress.com/2014/02/12/routing-request-for-static-files-with-or-without ...
- 2、Jquery_事件
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...
- 【原创】谈谈redis的热key问题如何解决
引言 讲了几天的数据库系列的文章,大家一定看烦了,其实还没讲完...(以下省略一万字). 今天我们换换口味,来写redis方面的内容,谈谈热key问题如何解决. 其实热key问题说来也很简单,就是瞬间 ...
- Java面向对象的三大特性 继承
继承是类与类的一种关系,是“is a"关系 子类拥有父类的属性和方法,private除外 class 子类 extends 父类 方法的重写 调用方法时会优先调用子类的方法 重写时,返 ...
- 浅谈JavaScript--闭包
闭包的概念 由于在Javascript语言中,只有函数内部的子函数才能读取局部变量,因此可以把闭包简单理解成"定义在一个函数内部的函数". 变量的作用域 要理解闭包,首先必须理解J ...
- vue打包之后生成一个配置文件修改请求接口
问题描述: 在npm run build 生成dist后,url配置也被固定了,传到运行的前端服务器上后,假设某次,api服务器的ip修改了,改动只是更新下这个url,但是却需要回到前端源码,修改ur ...
- python文件名匹配
待匹配文件:#FY3D_IPMNT_GBAL_L1_20180516_0003_030KM_MS.HDF 干扰文件:#FY3D_IPMNT_GBAL_L1_20180516_0003_030KM_MS ...
- À peu près là 技术支持
À peu près là 技术支持 技术支持网址:有问题或建议请留言. 邮箱地址: metlersaiddqr@zoho.com Program design & system cons ...
- iOS无线真机调试
打开xcode,选择Window > Devices and Simulators 用数据线连接设备 选择 Connect via network