梯度下降算法(gradient descent)
简述
梯度下降法又被称为最速下降法(Steepest descend method),其理论基础是梯度的概念。梯度与方向导数的关系为:梯度的方向与取得最大方向导数值的方向一致,而梯度的模就是函数在该点的方向导数的最大值。
现在假设我们要求函数的最值,采用梯度下降法,如图所示:


梯度下降的相关概念
在详细了解梯度下降的算法之前,我们先看看相关的一些概念。
1. 步长(Learning rate):步长决定了在梯度下降迭代的过程中,每一步沿梯度负方向前进的长度。用上面下山的例子,步长就是在当前这一步所在位置沿着最陡峭最易下山的位置走的那一步的长度。
2.特征(feature):指的是样本中输入部分,比如样本(x0,y0),(x1,y1),则样本特征为x,样本输出为y。
3. 假设函数(hypothesis function):在监督学习中,为了拟合输入样本,而使用的假设函数,记为hθ(x)。比如对于样本(xi,yi)(i=1,2,...n),可以采用拟合函数如下: hθ(x) = θ0+θ1x。
4. 损失函数(loss function):为了评估模型拟合的好坏,通常用损失函数来度量拟合的程度。损失函数极小化,意味着拟合程度最好,对应的模型参数即为最优参数。在线性回归中,损失函数通常为样本输出和假设函数的差取平方。比如对于样本(xi,yi)(i=1,2,...n),采用线性回归,损失函数为:
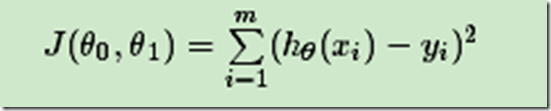
其中xi表示样本特征x的第i个元素,yi表示样本输出y的第i个元素,hθ(xi)为假设函数。
梯度下降的详细算法
梯度下降法的算法可以有代数法和矩阵法(也称向量法)两种表示,如果对矩阵分析不熟悉,则代数法更加容易理解。不过矩阵法更加的简洁,且由于使用了矩阵,实现逻辑更加的一目了然。这里先介绍代数法,后介绍矩阵法。
梯度下降法的代数方式描述
1. 先决条件: 确认优化模型的假设函数和损失函数。
同样是线性回归,对应于上面的假设函数,损失函数为:
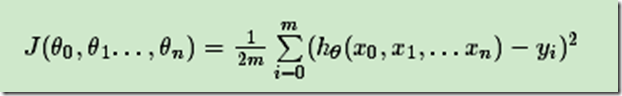
2. 算法相关参数初始化:主要是初始化θ0,θ1...,θn,算法终止距离ε以及步长α。在没有任何先验知识的时候,我喜欢将所有的θ初始化为0, 将步长初始化为1。在调优的时候再 优化。
3. 算法过程:
1)确定当前位置的损失函数的梯度,对于θi,其梯度表达式如下:
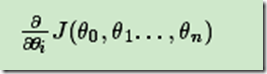
2)用步长乘以损失函数的梯度,得到当前位置下降的距离,即 。
。
3)确定是否所有的θi,梯度下降的距离都小于ε,如果小于ε则算法终止,当前所有的θi(i=0,1,...n)即为最终结果。否则进入步骤4.
4)更新所有的θ,对于θi,其更新表达式如下。更新完毕后继续转入步骤1.
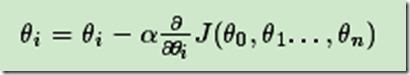
梯度下降法的矩阵方式描述
这一部分主要讲解梯度下降法的矩阵方式表述,相对于代数法,要求有一定的矩阵分析的基础知识,尤其是矩阵求导的知识。
1. 先决条件:需要确认优化模型的假设函数和损失函数。
损失函数的表达式为: ,其中YY是样本的输出向量,维度为mx1.
,其中YY是样本的输出向量,维度为mx1.
2. 算法相关参数初始化: θ向量可以初始化为默认值,或者调优后的值。算法终止距离ε,步长α。
3. 算法过程:
1)确定当前位置的损失函数的梯度,对于θ向量,其梯度表达式如下:
2)用步长乘以损失函数的梯度,得到当前位置下降的距离
3)确定θ向量里面的每个值,梯度下降的距离都小于ε,如果小于ε则算法终止,当前θ向量即为最终结果。否则进入步骤4.
4)更新θ向量,其更新表达式如下。更新完毕后继续转入步骤1.
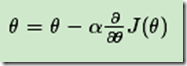
梯度下降的算法调优
在使用梯度下降时,需要进行调优。哪些地方需要调优呢?
1. 算法的步长选择。在前面的算法描述中,我提到取步长为1,但是实际上取值取决于数据样本,可以多取一些值,从大到小,分别运行算法,看看迭代效果,如果损失函数在变小,说明取值有效,否则要增大步长。前面说了。步长太大,会导致迭代过快,甚至有可能错过最优解。步长太小,迭代速度太慢,很长时间算法都不能结束。所以算法的步长需要多次运行后才能得到一个较为优的值。
2. 算法参数的初始值选择。 初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定是最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,关键损失函数的最小值,选择损失函数最小化的初值。
3.归一化。由于样本不同特征的取值范围不一样,可能导致迭代很慢,为了减少特征取值的影响,可以对特征数据归一化,也就是对于每个特征x,求出它的期望x和标准差std(x),然后转化为:
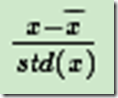
这样特征的新期望为0,新方差为1,迭代次数可以大大加快。
梯度下降法大家族(BGD,SGD,MBGD)
批量梯度下降法(Batch Gradient Descent)
批量梯度下降法,是梯度下降法最常用的形式,具体做法也就是在更新参数时使用所有的样本来进行更新
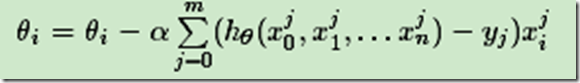
由于我们有m个样本,这里求梯度的时候就用了所有m个样本的梯度数据。
随机梯度下降法(Stochastic Gradient Descent)
随机梯度下降法,其实和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。对应的更新公式是:

随机梯度下降法,和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。自然各自的优缺点都非常突出。对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
那么,有没有一个中庸的办法能够结合两种方法的优点呢?有!这就是小批量梯度下降法。
小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,我们采用x个样子来迭代,1<x<m。一般可以取x=10,当然根据样本的数据,可以调整这个x的值。对应的更新公式是:
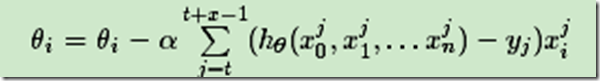
梯度下降法和其他无约束优化算法的比较
在机器学习中的无约束优化算法,除了梯度下降以外,还有前面提到的最小二乘法,此外还有牛顿法和拟牛顿法。
梯度下降法和最小二乘法相比,梯度下降法需要选择步长,而最小二乘法不需要。梯度下降法是迭代求解,最小二乘法是计算解析解。如果样本量不算很大,且存在解析解,最小二乘法比起梯度下降法要有优势,计算速度很快。但是如果样本量很大,用最小二乘法由于需要求一个超级大的逆矩阵,这时就很难或者很慢才能求解解析解了,使用迭代的梯度下降法比较有优势。
梯度下降法和牛顿法/拟牛顿法相比,两者都是迭代求解,不过梯度下降法是梯度求解,而牛顿法/拟牛顿法是用二阶的海森矩阵的逆矩阵或伪逆矩阵求解。相对而言,使用牛顿法/拟牛顿法收敛更快。但是每次迭代的时间比梯度下降法长。
参考文献:
https://www.cnblogs.com/pinard/p/5970503.html
梯度下降算法(gradient descent)的更多相关文章
- 梯度下降算法(Gradient descent)GD
1.我们之前已经定义了代价函数J,可以将代价函数J最小化的方法,梯度下降是最常用的算法,它不仅仅用在线性回归上,还被应用在机器学习的众多领域中,在后续的课程中,我们将使用梯度下降算法最小化其他函数,而 ...
- 机器学习(1)之梯度下降(gradient descent)
机器学习(1)之梯度下降(gradient descent) 题记:最近零碎的时间都在学习Andrew Ng的machine learning,因此就有了这些笔记. 梯度下降是线性回归的一种(Line ...
- 梯度下降(gradient descent)算法简介
梯度下降法是一个最优化算法,通常也称为最速下降法.最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的.最速下降法是用 ...
- 梯度下降(Gradient Descent)小结 -2017.7.20
在求解算法的模型函数时,常用到梯度下降(Gradient Descent)和最小二乘法,下面讨论梯度下降的线性模型(linear model). 1.问题引入 给定一组训练集合(training se ...
- 梯度下降(Gradient descent)
首先,我们继续上一篇文章中的例子,在这里我们增加一个特征,也即卧室数量,如下表格所示: 因为在上一篇中引入了一些符号,所以这里再次补充说明一下: x‘s:在这里是一个二维的向量,例如:x1(i)第i间 ...
- (二)深入梯度下降(Gradient Descent)算法
一直以来都以为自己对一些算法已经理解了,直到最近才发现,梯度下降都理解的不好. 1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 ...
- CS229 2.深入梯度下降(Gradient Descent)算法
1 问题的引出 对于上篇中讲到的线性回归,先化一个为一个特征θ1,θ0为偏置项,最后列出的误差函数如下图所示: 手动求解 目标是优化J(θ1),得到其最小化,下图中的×为y(i),下面给出TrainS ...
- (3)梯度下降法Gradient Descent
梯度下降法 不是一个机器学习算法 是一种基于搜索的最优化方法 作用:最小化一个损失函数 梯度上升法:最大化一个效用函数 举个栗子 直线方程:导数代表斜率 曲线方程:导数代表切线斜率 导数可以代表方向, ...
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- 梯度下降法Gradient descent(最速下降法Steepest Descent)
最陡下降法(steepest descent method)又称梯度下降法(英语:Gradient descent)是一个一阶最优化算法. 函数值下降最快的方向是什么?沿负梯度方向 d=−gk
随机推荐
- PL-SQL 包的创建和应用
PL-SQL 包的创建和应用 ①简单介绍 包是一组相关过程.函数.变量.常量和游标等PL/SQL程序设计元素的组合,它具有面向对象程序设计语言的特点.是对这些PL/SQL 程序设计元素的 ...
- autoRelease
cocos2dx采用的是引用计数的方式来管理对象的持有和释放. 所谓引用计数就是说,每个对象都会有一个属性用来记录当前被几个地方引用了.在释放内存的时候会根据这个引用计数来确定是否要用delete操作 ...
- java.lang.NoSuchMethodError: ognl.SimpleNode.isEvalChain(Lognl/OgnlContext;)Z解决方法
执行JavaEE项目时出现例如以下错误: java.lang.NoSuchMethodError: ognl.SimpleNode.isEvalChain(Lognl/OgnlContext;)Z a ...
- JavaScript Array pop(),shift()函数
pop() 删除数组的最后一个元素并返回删除的元素 shift() 删除并返回数组的第一个元素
- Asp.Mvc将生成的视图保存为字符串
public static class ViewExtensions { /// <summary> /// 在控制器内获取指定视图生成后的HTML /// </summary> ...
- 并发编程概述 委托(delegate) 事件(event) .net core 2.0 event bus 一个简单的基于内存事件总线实现 .net core 基于NPOI 的excel导出类,支持自定义导出哪些字段 基于Ace Admin 的菜单栏实现 第五节:SignalR大杂烩(与MVC融合、全局的几个配置、跨域的应用、C/S程序充当Client和Server)
并发编程概述 前言 说实话,在我软件开发的头两年几乎不考虑并发编程,请求与响应把业务逻辑尽快完成一个星期的任务能两天完成绝不拖三天(剩下时间各种浪),根本不会考虑性能问题(能接受范围内).但随着工 ...
- https 加载问题
https的网站,加载的资源要全部https,如果里面有http的资源,很多浏览器是加载不进来 要地址栏变绿,网站内部全部引用都是https的
- TMS320C6455 SRIO 实现方案
TMS320C6455 SRIO 实现方案 SRIO(Serial RapidIO)构架是一种基于高性能包交换的互连技术,主要功能是完成在一个系统内的微处理器.DSP.通信和网络处理器.系统存储器以及 ...
- python使用mysql数据库(虫师)
转自虫师 http://www.cnblogs.com/fnng/p/3565912.html 一,安装mysql 如果是windows 用户,mysql 的安装非常简单,直接下载安装文件,双击安装文 ...
- Google Code Jam 2014 Round 1 A:Problem B. Full Binary Tree
Problem A tree is a connected graph with no cycles. A rooted tree is a tree in which one special ver ...