spark-groupByKey
一般来说,在执行shuffle类的算子的时候,比如groupByKey、reduceByKey、join等。 其实算子内部都会隐式地创建几个RDD出来。那些隐式创建的RDD,主要是作为这个操作的一些中间数据的表达,以及作为stage划分的边界。 因为有些隐式生成的RDD,可能是ShuffledRDD,dependency就是ShuffleDependency,DAGScheduler的源码,就会将这个RDD作为新的stage的第一个rdd,划分出来。
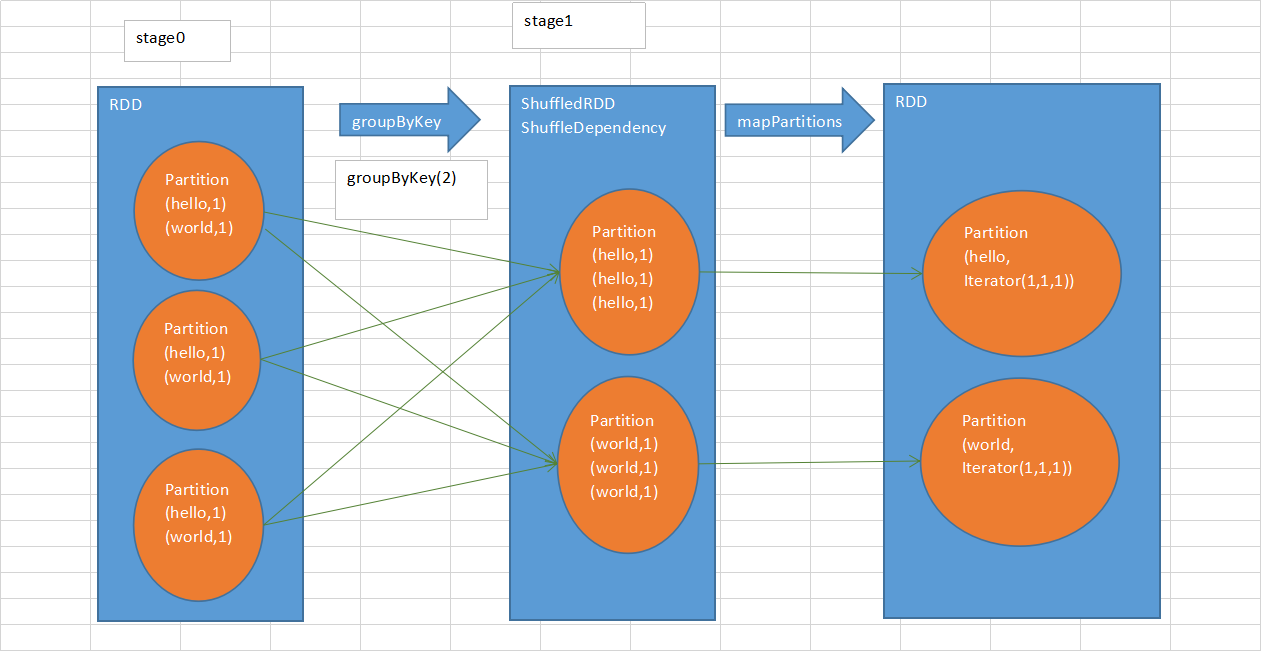
groupByKey等shuffle算子,都会创建一些隐式RDD。比如说这里,ShuffledRDD,作为一个shuffle过程中的中间数据的代表。 依赖这个ShuffledRDD创建出来一个新的stage(stage1)。ShuffledRDD会去触发shuffle read操作。从上游stage的task所在节点,拉取过来相同的key,做进一步的聚合。 对ShuffledRDD中的数据执行一个map类的操作,主要是对每个partition中的数据,都进行一个映射和聚合。这里主要是将每个key对应的数据都聚合到一个Iterator集合中。
spark-groupByKey的更多相关文章
- spark groupByKey().mapValues
>>> rdd = sc.parallelize([("bone", 231), ("bone", 21213), ("jack&q ...
- spark groupByKey 也是可以filter的
>>> v=sc.parallelize(["one", "two", "two", "three", ...
- 【Spark调优】:如果实在要shuffle,使用map侧预聚合的算子
因业务上的需要,无可避免的一些运算一定要使用shuffle操作,无法用map类的算子来替代,那么尽量使用可以map侧预聚合的算子. map侧预聚合,是指在每个节点本地对相同的key进行一次聚合操作,类 ...
- Spark程序使用groupByKey后数据存入HBase出现重复的现象
最近在一个项目中做数据的分类存储,在spark中使用groupByKey后存入HBase,发现数据出现双份( 所有记录的 rowKey 是随机 唯一的 ) .经过不断的测试,发现是spark的运行参 ...
- (九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark
groupByKey,reduceByKey,sortByKey算子 视频教程: 1.优酷 2. YouTube 1.groupByKey groupByKey是对每个key进行合并操作,但只生成一个 ...
- Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
声明: 大数据中,最重要的算子操作是:join !!! 典型的transformation和action val nums = sc.parallelize(1 to 10) //根据集合创建RDD ...
- Spark RDD/Core 编程 API入门系列之map、filter、textFile、cache、对Job输出结果进行升和降序、union、groupByKey、join、reduce、lookup(一)
1.以本地模式实战map和filter 2.以集群模式实战textFile和cache 3.对Job输出结果进行升和降序 4.union 5.groupByKey 6.join 7.reduce 8. ...
- spark中groupByKey与reducByKey
[译]避免使用GroupByKey Scala Spark 技术 by:leotse 原文:Avoid GroupByKey 译文 让我们来看两个wordcount的例子,一个使用了reduceB ...
- Spark DataFrame的groupBy vs groupByKey
在使用Spark SQL的过程中,经常会用到groupBy这个函数进行一些统计工作.但是会发现除了groupBy外,还有一个groupByKey(注意RDD也有一个groupByKey,而这里的gro ...
- spark RDD,reduceByKey vs groupByKey
Spark中有两个类似的api,分别是reduceByKey和groupByKey.这两个的功能类似,但底层实现却有些不同,那么为什么要这样设计呢?我们来从源码的角度分析一下. 先看两者的调用顺序(都 ...
随机推荐
- 剑指Offer - 九度1371 - 最小的K个数
剑指Offer - 九度1371 - 最小的K个数2013-11-23 15:45 题目描述: 输入n个整数,找出其中最小的K个数.例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是 ...
- 《Cracking the Coding Interview》——第13章:C和C++——题目6
2014-04-25 20:07 题目:为什么基类的析构函数必须声明为虚函数? 解法:不是必须,而是应该,这是种规范.对于基类中执行的一些动态资源分配,如果基类的析构函数不是虚函数,那么 派生类的析构 ...
- 《Cracking the Coding Interview》——第4章:树和图——题目8
2014-03-19 05:04 题目:给定两棵二叉树T1和T2,判断T2是否是T1的子树.子树的定义是,以T1的某个节点(可以是T1的根)作为根节点,得到的这棵树和T2一模一样. 解法:首先可以根据 ...
- 【Feasibility of Learning】林轩田机器学习基石
这一节的核心内容在于如何由hoeffding不等式 关联到机器学习的可行性. 这个PAC很形象又准确,描述了“当前的可能性大概是正确的”,即某个概率的上届. hoeffding在机器学习上的关联就是: ...
- webstrom11 vue插件配置
直接上图 1. 安装vue插件 2.添加模板 3.指定模板类型 最新的是插件 是 vue.js 创建完 Vue File 文件后 需要在 下面这里关联一下
- Python 3基础教程12-常见的错误
本文来介绍几种常见的错误,任何人在刚开始接触一个新的语言,即使照着代码抄写,也可能会犯错误,这里我们就介绍几种常见的错误,看看你是否遇到过. 1. NameError: name 'xxx' is n ...
- (原) Unreal搬山-引言(图多慎)
@author:白袍小道 扯淡:(图多) 何为搬山,这里借了剑来少年郎一句.(若有同道中人,甚是开心,开心的很) 江湖岂能没前辈) (江湖很大,足够你浪) (刺客信条 \荒野 \神秘海域 \死亡空间 ...
- ironic baremetal node rescue/unrescue mode
环境ironic-api ironic-conductor,ironicclient均升级为Queens版本 官网说明API版本为1.38才支持rescue/unrescue,所以修改下openrc文 ...
- 500 OOPS: vsftpd: refusing to run with writable anonymous root
500 OOPS: vsftpd: refusing to run with writable anonymous root 以下就是解决的三个步骤,其中第一步,是我一直没有搞明白的,也是其中的重点: ...
- PHP路径相关 dirname,realpath,__FILE__
比如:程序根目录在:E:\wamp\www 中 1. __FILE__ 当前文件的绝对路径 如果在index.php中调用 则返回 E:\wamp\www\index.php 下面再看一 ...