(九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark
groupByKey,reduceByKey,sortByKey算子
视频教程:
1、优酷
2、 YouTube
1、groupByKey
groupByKey是对每个key进行合并操作,但只生成一个sequence,groupByKey本身不能自定义操作函数。
java:
package com.bean.spark.trans; import java.util.Arrays;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext; import scala.Tuple2; public class TraGroupByKey {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("union");
System.setProperty("hadoop.home.dir", "D:/tools/spark-2.0.0-bin-hadoop2.6");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Tuple2<String, Integer>> list = Arrays.asList(new Tuple2<String, Integer>("cl1", 90),
new Tuple2<String, Integer>("cl2", 91),new Tuple2<String, Integer>("cl3", 97),
new Tuple2<String, Integer>("cl1", 96),new Tuple2<String, Integer>("cl1", 89),
new Tuple2<String, Integer>("cl3", 90),new Tuple2<String, Integer>("cl2", 60));
JavaPairRDD<String, Integer> listRDD = sc.parallelizePairs(list);
JavaPairRDD<String, Iterable<Integer>> results = listRDD.groupByKey();
System.out.println(results.collect());
sc.close();
}
}
python:
# -*- coding:utf-8 -*- from pyspark import SparkConf
from pyspark import SparkContext
import os if __name__ == '__main__':
os.environ["SPARK_HOME"] = "D:/tools/spark-2.0.0-bin-hadoop2.6"
conf = SparkConf().setMaster('local').setAppName('group')
sc = SparkContext(conf=conf)
data = [('tom',90),('jerry',97),('luck',92),('tom',78),('luck',64),('jerry',50)]
rdd = sc.parallelize(data)
print rdd.groupByKey().map(lambda x: (x[0],list(x[1]))).collect()
注意:当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对都移动,这样的后果是集群节点之间的开销很大,导致传输延时。
整个过程如下:
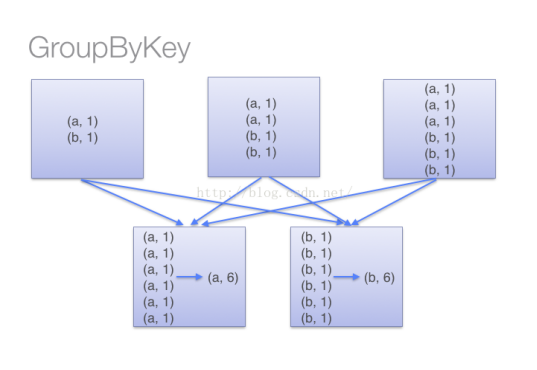
因此,在对大数据进行复杂计算时,reduceByKey优于groupByKey。
另外,如果仅仅是group处理,那么以下函数应该优先于 groupByKey :
(1)、combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)、foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。
2、reduceByKey
对数据集key相同的值,都被使用指定的reduce函数聚合到一起。
java:
package com.bean.spark.trans; import java.util.Arrays;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2; import scala.Tuple2; public class TraReduceByKey {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("reduce");
System.setProperty("hadoop.home.dir", "D:/tools/spark-2.0.0-bin-hadoop2.6");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Tuple2<String, Integer>> list = Arrays.asList(new Tuple2<String, Integer>("cl1", 90),
new Tuple2<String, Integer>("cl2", 91),new Tuple2<String, Integer>("cl3", 97),
new Tuple2<String, Integer>("cl1", 96),new Tuple2<String, Integer>("cl1", 89),
new Tuple2<String, Integer>("cl3", 90),new Tuple2<String, Integer>("cl2", 60));
JavaPairRDD<String, Integer> listRDD = sc.parallelizePairs(list);
JavaPairRDD<String, Integer> results = listRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer s1, Integer s2) throws Exception {
// TODO Auto-generated method stub
return s1 + s2;
}
});
System.out.println(results.collect());
sc.close();
}
}
python:
# -*- coding:utf-8 -*- from pyspark import SparkConf
from pyspark import SparkContext
import os
from operator import add
if __name__ == '__main__':
os.environ["SPARK_HOME"] = "D:/tools/spark-2.0.0-bin-hadoop2.6"
conf = SparkConf().setMaster('local').setAppName('reduce')
sc = SparkContext(conf=conf)
data = [('tom',90),('jerry',97),('luck',92),('tom',78),('luck',64),('jerry',50)]
rdd = sc.parallelize(data)
print rdd.reduceByKey(add).collect()
sc.close()
当采用reduceByKey时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。 注意在数据对被搬移前同一机器上同样的key是怎样被组合的。
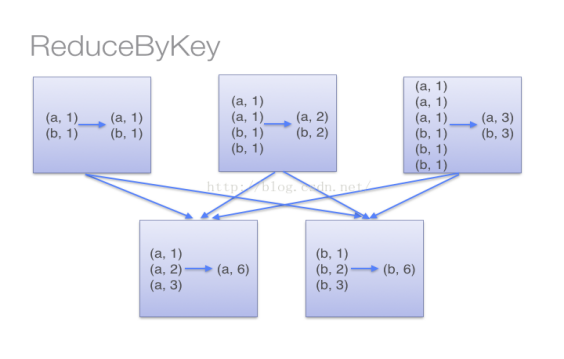
3、sortByKey
通过key进行排序。
java:
package com.bean.spark.trans; import java.util.Arrays;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext; import scala.Tuple2; public class TraSortByKey {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setMaster("local");
conf.setAppName("sort");
System.setProperty("hadoop.home.dir", "D:/tools/spark-2.0.0-bin-hadoop2.6");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Tuple2<Integer, String>> list = Arrays.asList(new Tuple2<Integer,String>(3,"Tom"),
new Tuple2<Integer,String>(2,"Jerry"),new Tuple2<Integer,String>(5,"Luck")
,new Tuple2<Integer,String>(1,"Spark"),new Tuple2<Integer,String>(4,"Storm"));
JavaPairRDD<Integer,String> rdd = sc.parallelizePairs(list);
JavaPairRDD<Integer, String> results = rdd.sortByKey(false);
System.out.println(results.collect());
sc.close()
}
}
python:
#-*- coding:utf-8 -*-
if __name__ == '__main__':
os.environ["SPARK_HOME"] = "D:/tools/spark-2.0.0-bin-hadoop2.6"
conf = SparkConf().setMaster('local').setAppName('reduce')
sc = SparkContext(conf=conf)
data = [(5,90),(1,92),(3,50)]
rdd = sc.parallelize(data)
print rdd.sortByKey(False).collect()
sc.close()
(九)groupByKey,reduceByKey,sortByKey算子-Java&Python版Spark的更多相关文章
- (八)map,filter,flatMap算子-Java&Python版Spark
map,filter,flatMap算子 视频教程: 1.优酷 2.YouTube 1.map map是将源JavaRDD的一个一个元素的传入call方法,并经过算法后一个一个的返回从而生成一个新的J ...
- (四)Spark集群搭建-Java&Python版Spark
Spark集群搭建 视频教程 1.优酷 2.YouTube 安装scala环境 下载地址http://www.scala-lang.org/download/ 上传scala-2.10.5.tgz到m ...
- (七)Transformation和action详解-Java&Python版Spark
Transformation和action详解 视频教程: 1.优酷 2.YouTube 什么是算子 算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作. 算子分类: 具体: 1.Value ...
- (一)Spark简介-Java&Python版Spark
Spark简介 视频教程: 1.优酷 2.YouTube 简介: Spark是加州大学伯克利分校AMP实验室,开发的通用内存并行计算框架.Spark在2013年6月进入Apache成为孵化项目,8个月 ...
- (二)Spark-Linux环境准备-Java&Python版Spark
Spark-Linux环境准备 视频教程: 1.优酷 2.YouTube 硬软件环境 1.虚拟机:VMware Workstation 12 2.虚拟机操作系统:RedHat5u4,单核,1G内存,2 ...
- (三)Spark-Hadoop集群搭建-Java&Python版Spark
Spark-Hadoop集群搭建 视频教程: 1.优酷 2.YouTube 配置java 启动ftp [root@master ~]# /etc/init.d/vsftpd restart 关闭 vs ...
- (六)Spark-Eclipse开发环境WordCount-Java&Python版Spark
Spark-Eclipse开发环境WordCount 视频教程: 1.优酷 2.YouTube 安装eclipse 解压eclipse-jee-mars-2-win32-x86_64.zip Java ...
- (五)什么是RDD-Java&Python版Spark
什么是RDD 视频教程: 1.优酷 2.YouTube RDD是个抽象类,全称为Resilient Distributed Datasets,是一个容错的.并行的数据结构,可以让用户显式地将数据存储到 ...
- [Python+Java双语版自动化测试(接口测试+Web+App+性能+CICD)
[Python+Java双语版自动化测试(接口测试+Web+App+性能+CICD)开学典礼](https://ke.qq.com/course/453802)**测试交流群:549376944**0 ...
随机推荐
- [React Native] State and Touch Events -- TextInput, TouchableHighLight
In React, components manage their own state. In this lesson, we'll walk through building a component ...
- Linux内核:关于中断你须要知道的
1.中断处理程序与其它内核函数真正的差别在于,中断处理程序是被内核调用来对应中断的,而它们执行于中断上下文(原子上下文)中,在该上下文中执行的代码不可堵塞. 中断就是由硬件打断操作系统. 2.异常与中 ...
- MyEclipse Hibernate Reverse Engineering 找不到项目错误
解决办法:在项目下找到.project文件,在最后的natures标签加入下面红色的一行代码. <natures> <nature>com.genuitec.ec ...
- Android_life,Intent_note
生命周期: 从出生到死亡 Activity生命周期的7个方法和3个循环 onCreate() 创建时调用onRestart() 不可见到可见时调用onStart() 用户可见时调用onResume() ...
- javascript中的内置对象
2015.12.1 javascript中的内置对象 复习: 1.js中的内置函数 alert prompt write parseInt parseFloat eval isNaN document ...
- PHP Fatal error问题处理
今天一个朋友公司网站遇到一个关于PHP的问题: PHP Fatal error: Allowed memory size of 67108864 bytes exhausted (tried to ...
- Asp.net 上传文件小叙(修改FileUpload显示文字等)
想要在asp.net网站上上传文件就得用到FileUpload,可是这个控件中“浏览”没法修改,可以使用html中<input type="file" 来解决该问题. 首先页 ...
- WinEdit7 破解方法
最近遇到了winEdit7 超过试用期的问题,找了下解决方案. 这个靠谱,通过在每次退出时自动删除注册表信息,达到无限试用的目的: https://lttt.blog.ustc.edu.cn/2012 ...
- Java获取某年某周的最后一天
package test; import java.text.SimpleDateFormat; import java.util.Calendar; /** * ClassName: LastDay ...
- cocoaPods的安装和使用之详细介绍
一,在Mac OS X上安装Ruby运行环境 步骤1------安装RVM $ curl -L https://get.rvm.io | bash -s stable 然后载入RVM环境 $ sour ...