Python 代码实现模糊查询
1、导语:
模糊匹配可以算是现代编辑器(如 Eclipse 等各种 IDE)的一个必备特性了,它所做的就是根据用户输入的部分内容,猜测用户想要的文件名,并提供一个推荐列表供用户选择。
样例如下:
Vim (Ctrl-P)
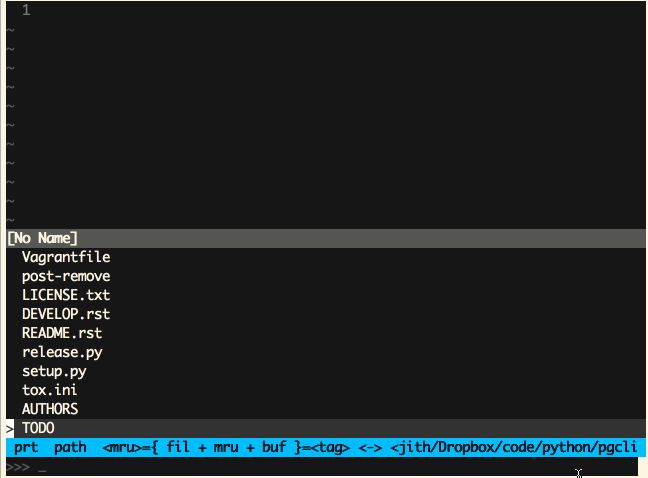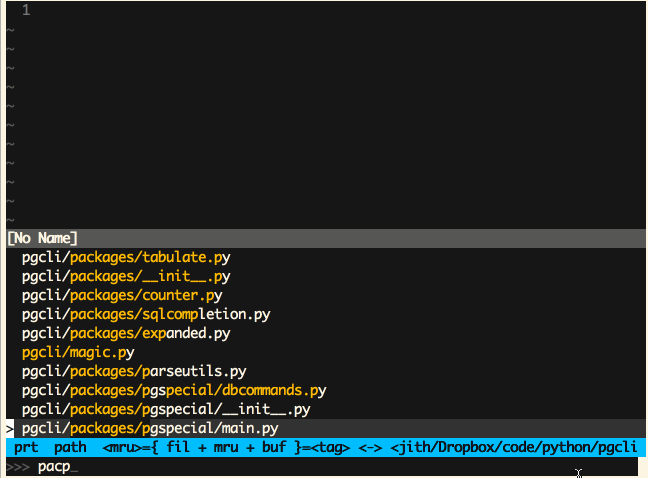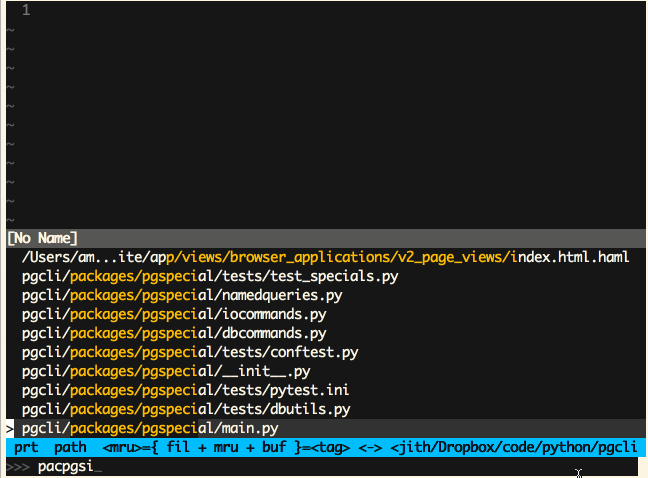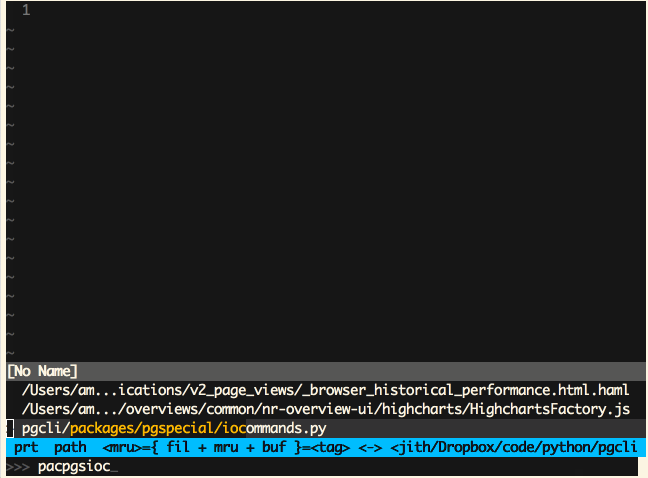
Sublime Text (Cmd-P)
‘模糊匹配’这是一个极为有用的特性,同时也非常易于实现。
2、问题分析:
我们有一堆字符串(文件名)集合,我们根据用户的输入不断进行过滤,用户的输入可能是字符串的一部分。我们就以下面的集合为例:
>>> collection = ['django_migrations.py',
'django_admin_log.py',
'main_generator.py',
'migrations.py',
'api_user.doc',
'user_group.doc',
'accounts.txt',
]当用户输入’djm‘字符串时,我们假定是匹配到’django_migrations.py’和’django_admin_log.py’,而最简单的实现方法就是使用正则表达式。
3、解决方案:
3.1 常规的正则匹配
将 "djm" 转换成 "d.*j.*m" 然后用这个正则尝试匹配集合中的每一个字符串,如果匹配到了就被列为候选。
>>> import re
>>> def fuzzyfinder(user_input, collection):
suggestions = []
pattern = '.*'.join(user_input) # Converts 'djm' to 'd.*j.*m'
regex = re.compile(pattern) # Compiles a regex.
for item in collection:
match = regex.search(item) # Checks if the current item matches the regex.
if match:
suggestions.append(item)
return suggestions
>>> print fuzzyfinder('djm', collection)
['django_migrations.py', 'django_admin_log.py']
>>> print fuzzyfinder('mig', collection)
['django_migrations.py', 'django_admin_log.py', 'main_generator.py', 'migrations.py']这里根据用户的输入我们得到了一个推荐列表,但是推荐列表中的字符串是没有进行重要性区分的。有可能出现最合适的匹配项被放到了最后的情况。
实际上,还是这个例子,当用户输入’mig‘时,最佳选项’migrations.py’就被放到了最后。
3.2 带有rank排序的匹配列表
这里我们对匹配到的结果按照匹配内容第一次出现的起始位置来进行排序。
'main_generator.py' - 0
'migrations.py' - 0
'django_migrations.py' - 7
'django_admin_log.py' - 9下面是相关代码:
>>> import re
>>> def fuzzyfinder(user_input, collection):
suggestions = []
pattern = '.*'.join(user_input) # Converts 'djm' to 'd.*j.*m'
regex = re.compile(pattern) # Compiles a regex.
for item in collection:
match = regex.search(item) # Checks if the current item matches the regex.
if match:
suggestions.append((match.start(), item))
return [x for _, x in sorted(suggestions)]
>>> print fuzzyfinder('mig', collection)
['main_generator.py', 'migrations.py', 'django_migrations.py', 'django_admin_log.py']这次我们生成了一个由二元 tuple 组成的列表,即列表中的每一个元素为一个二元tuple,而该二元tuple的第一个值为匹配到的起始位置、第二个值为对应的文件名,然后使用列表推导式按照匹配到的位置进行排序并返回文件名列表。
现在我们已经很接近最终的结果了,但还称不上完美——用户想要的是’migration.py’,但我们却把’main_generator.py’作为第一推荐。
3.3 根据匹配的紧凑程度进行排序
当用户开始输入一个字符串时,他们倾向于输入连续的字符以进行精确匹配。比如当用户输入’mig‘他们更倾向于找的是’migrations.py’或’django_migrations.py’,而不是’main_generator.py’,所以这里我们所做的改变就是查找匹配到的最紧凑的项目。
刚才提到的问题对于Python来说不算什么事,因为当我们使用正则表达式进行字符串匹配时,匹配到的字符串就已经被存放在了match.group()中了。下面假设输入为’mig’,对最初定义的’collection’的匹配结果如下:
regex = '(m.*i.*g)'
'main_generator.py' -> 'main_g'
'migrations.py' -> 'mig'
'django_migrations.py' -> 'mig'
'django_admin_log.py' -> 'min_log'这里我们将推荐列表做成了三元tuple的列表的形式,即推荐列表中的每一个元素为一个三元tuple,而该三元tuple的第一个值为匹配到的内容的长度、第二个值为匹配到的起始位置、第三个值为对应的文件名,然后按照匹配长度和起始位置进行排序并返回。
>>> import re
>>> def fuzzyfinder(user_input, collection):
suggestions = []
pattern = '.*'.join(user_input) # Converts 'djm' to 'd.*j.*m'
regex = re.compile(pattern) # Compiles a regex.
for item in collection:
match = regex.search(item) # Checks if the current item matches the regex.
if match:
suggestions.append((len(match.group()), match.start(), item))
return [x for _, _, x in sorted(suggestions)]
>>> print fuzzyfinder('mig', collection)
['migrations.py', 'django_migrations.py', 'main_generator.py', 'django_admin_log.py']针对我们的输入,这时候的匹配结果已经趋向于完美了,不过还没完。
3.4 非贪婪匹配
由 Daniel Rocco 发现了这一微妙的问题:当集合中有['api_user', 'user_group']这两个元素存在,用户输入’user‘时,预期的匹配结果(相对顺序)应该为['user_group', 'api_user'],但实际上的结果为:
>>> print fuzzyfinder('user', collection)
['api_user.doc', 'user_group.doc']上面的测试结果中:’api_user’要排在’user_group’前面。深入一点,我们发现这是因为在搜索’user’时,正则被扩展成了’u.*s.*e.*r’,考虑到’user_group’有2个’r',因此该模式匹配到了’user_gr‘而不是我们预期的’user‘。更长的匹配导致在最后的匹配rank排序时名次下降这一违反直觉的结果,不过这问题也容易解决,将正则修改为’非贪婪匹配’即可。
>>> import re
>>> def fuzzyfinder(user_input, collection):
suggestions = []
pattern = '.*?'.join(user_input) # Converts 'djm' to 'd.*?j.*?m'
regex = re.compile(pattern) # Compiles a regex.
for item in collection:
match = regex.search(item) # Checks if the current item matches the regex.
if match:
suggestions.append((len(match.group()), match.start(), item))
return [x for _, _, x in sorted(suggestions)]
>>> fuzzyfinder('user', collection)
['user_group.doc', 'api_user.doc']
>>> print fuzzyfinder('mig', collection)
['migrations.py', 'django_migrations.py', 'main_generator.py', 'django_admin_log.py']现在,fuzzyfinder已经可以(在上面的情况中)正常工作了,而我们不过只写了10行代码就实现了一个 fuzzy finder。
3.5 结论:

以上就是我在我的 pgcli 项目(一个有自动补全功能的Postgresql命令行实现)中设计实现’fuzzy matching’的过程记录。
我已经将 fuzzyfinder 提取成一个独立的Python包,你可以使用命令’pip install fuzzyfinder’在你的项目中进行安装和使用。
感谢 Micah Zoltu 和 Daniel Rocco 对算法的检查和问题修复。
如果你对这个感兴趣的话,你可以来 twitter 上找我。
4、结语:
当我第一次考虑用Python实现“fuzzy matching”的时候,我就知道一个叫做 fuzzywuzzy的优秀库,但是 fuzzywuzzy 的做法和这里的不太一样,它使用的是 “levenshtein distance”(编辑距离) 来从集合中找到最匹配的字符串。”levenshtein distance“是一个非常适合用来做自动更正拼写错误的技术,但在从部分子串匹配长文件名时表现的不太好(所以这里没有使用)。
Python 代码实现模糊查询的更多相关文章
- 10 行 Python 代码实现模糊查询/智能提示
10 行 Python 代码实现模糊查询/智能提示 1.导语: 模糊匹配可以算是现代编辑器(如 Eclipse 等各种 IDE)的一个必备特性了,它所做的就是根据用户输入的部分内容,猜测用户想要的 ...
- Python札记 -- MongoDB模糊查询
最近在使用MongoDB的时候,遇到了使用多个关键词进行模糊查询的场景.竹风使用的是mongoengine库. 查了各种资料,最后总结出比较好用的方法.先上代码,后面进行详细说明.如下: #!/usr ...
- hbase RowFilter如何根据rowkey查询以及实例实现代码 habase模糊查询【转】
RowFilter用于过滤row key Operator Description LESS 小于 LESS_OR_EQUAL 小于等于 [EQUAL 等于 NOT_EQUAL 不等于 GREATER ...
- Python——数据库like模糊查询
在Python中%是一个格式化字符,所以如果需要使用%则需要写成%%.将在Python中执行的sql语句改为:sql = "SELECT * FROM table_test WHERE va ...
- JAVA 模糊查询方法
当我们需要开发一个方法用来查询数据库的时候,往往会遇到这样一个问题:就是不知道用户到底会输入什么条件,那么怎么样处理sql语句才能让我们开发的方法不管接受到什么样的条件都可以正常工作呢?这时where ...
- java 查询路径中所有文件夹和文件的名称,支持文件名模糊查询
java 查询路径中所有文件夹和文件的名称,支持文件名模糊查询 有时候我们遇到需要查询服务器或者本机某个路径下有哪些文件?或者根据文件名称模糊搜索文件,那么就可以使用本方法:可以获取某个路径下所有文件 ...
- mongoTemplate CURD 和模糊查询(转)
此文基于Spring的MongoTemplate,介绍MongoDB比较基础常用的增删改查操作.涵盖了从集合创建.索引创建和CRUD操作到更高级的功能(如Map-Reduce和聚合)等等.不多说,直接 ...
- Mybatis-生成逆向工程后对数据库的模糊查询详解
MyBatis-使用逆向工程中方法进行模糊查询 1.应用mybatis逆向工程会大大的提高我们的开发效率,如何应用mabatis 逆向生成的代码进行模糊查询那. 2.首先看一下pojo 层中examp ...
- Python模糊查询本地文件夹去除文件后缀(7行代码)
Python模糊查询本地文件夹去除文件后缀 import os,re def fuzzy_search(path): word= input('请输入要查询的内容:') for filename in ...
随机推荐
- JS动画理论
动画(Animation) 动画意味着随着时间而变化,尤其指视觉上的变化,包括位置.形态等的变化.运动基本上表现为物体随时间,发生位置上的变化:形态基本表现为大小.颜色.透明度.形状等随时间的变化. ...
- bzoj3047: Freda的传呼机 && 2125: 最短路
Description 为了随时与rainbow快速交流,Freda制造了两部传呼机.Freda和rainbow所在的地方有N座房屋.M条双向光缆.每条光缆连接两座房屋,传呼机发出的信号只能沿着光缆传 ...
- Markdown 测试
量化派业务参考代码 测试二级标题 如果 merchant_id 是外部白条,则执行相关逻辑 if(order.getMerchantId() == Constants.BaitiaoMerchant. ...
- 转:小心,apc可能导致php-fpm罢工!
原文来自于:http://www.searchtb.com/2014/02/apc-lock-php-fpm.html 最近线上产品出现了502错误.一般出现502错误,都是php-fpm 进程处理请 ...
- optimize performance
http://www.cnblogs.com/fullhouse/archive/2012/01/05/2313105.html http://www.cnblogs.com/fullhouse/ar ...
- Emag eht htiw Em Pleh
Emag eht htiw Em Pleh This problem is a reverse case of the problem 2996. You are given the output o ...
- Visual C++ 8.0对象布局的奥秘:虚函数、多继承、虚拟继承(VC直接输出内存布局)
原文:VC8_Object_Layout_Secret.html 哈哈,从M$ Visual C++ Team的Andy Rich那里又偷学到一招:VC8的隐含编译项/d1reportSingleCl ...
- 杂题 SPOJ MOBILE2 - Mobiles
MOBILE2 - Mobiles no tags You have been asked to buy a gift for your baby brother, Ike. However, yo ...
- 【模拟】NEERC15 J Jump(2015-2016 ACM-ICPC)(Codeforces GYM 100851)
题目链接: http://codeforces.com/gym/100851 题目大意: 系统里生成一个字符串C,一开始告诉你字符串的长度N(偶数).接着你需要在n+500次内猜出这个字符串是什么. ...
- segment
1.segmentedControlStyle 设置segment的显示样式. typedef NS_ENUM(NSInteger, UISegmentedControlStyle) { UISegm ...