Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战
【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送--Spark入门实战系列》获取
1、 安装IntelliJ IDEA
IDEA 全称 IntelliJ IDEA,是java语言开发的集成环境,IntelliJ在业界被公认为最好的java开发工具之一,尤其在智能代码助手、代码自动提示、重构、J2EE支持、Ant、JUnit、CVS整合、代码审查、创新的GUI设计等方面的功能可以说是超常的。IDEA是JetBrains公司的产品,这家公司总部位于捷克共和国的首都布拉格,开发人员以严谨著称的东欧程序员为主。
IDEA每个版本提供Community和Ultimate两个版本,如下图所示,其中Community是完全免费的,而Ultimate版本可以使用30天,过这段时间后需要收费。从安装后使用对比来看,下载一个Community版本足够了。
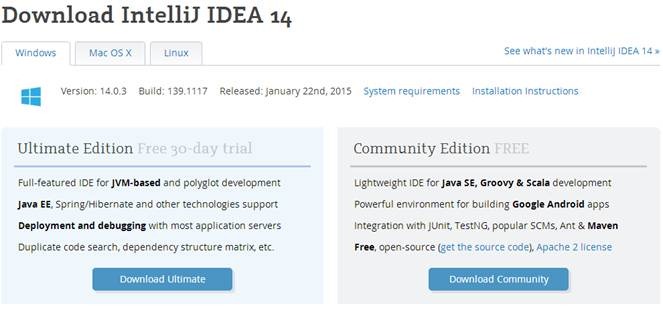
1.1 安装软件
1.1.1 下载IDEA安装文件
可以到Jetbrains官网http://www.jetbrains.com/idea/download/,选择最新的安装文件。由于以后的练习需要在Linux开发Scala应用程序,选择Linux系统IntelliJ IDEA14,如下图所示:
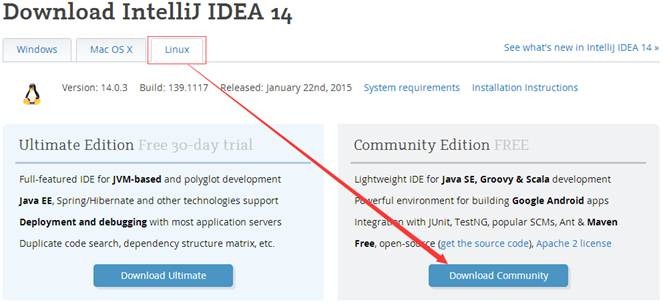
【注】在该系列配套资源的install目录下分别提供了ideaIC-14.0.2.tar.gz(社区版)和ideaIU-14.0.2.tar.gz(正式版)安装文件,对于Scala开发来说两个版本区别不大
1.1.2 解压缩并移动目录
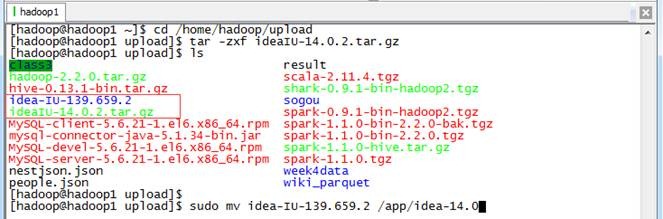
把下载的安装文件上传到目标机器,用如下命令解压缩IntelliJ IDEA安装文件,并迁移到/app目录下:
cd /home/hadoop/upload
tar -zxf ideaIU-14.0.2.tar.gz
sudo mv idea-IU-139.659.2 /app/idea-IU
1.1.3配置/etc/profile环境变量
使用如下命令打开/etc/profile文件:
sudo vi /etc/profile
确认JDK配置变量正确配置(参见第2节《Spark编译与部署》中关于基础环境搭建介绍):
export JAVA_HOME=/usr/lib/java/jdk1.7.0_55
export PATH=$PATH:$JAVA_HOME

1.2 配置Scala环境
1.2.1 启动IntelliJ IDEA
可以通过两种方式启动IntelliJ IDEA:
l 到IntelliJ IDEA安装所在目录下,进入bin目录双击idea.sh启动IntelliJ IDEA;
l 在命令行终端中,进入$IDEA_HOME/bin目录,输入./idea.sh进行启动
IDEA初始启动目录如下,IDEA默认情况下并没有安装Scala插件,需要手动进行安装,安装过程并不复杂,下面将演示如何进行安装。

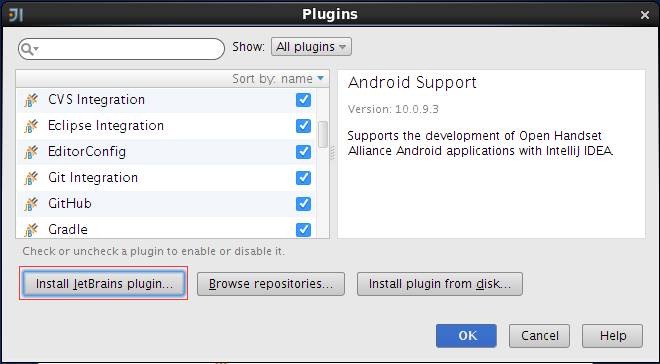
1.2.2 下载Scala插件
参见上图,在启动界面上选择“Configure-->Plugins"选项,然后弹出插件管理界面,在该界面上列出了所有安装好的插件,由于Scala插件没有安装,需要点击”Install JetBrains plugins"进行安装,如下图所示:
待安装的插件很多,可以通过查询或者字母顺序找到Scala插件,选择插件后在界面的右侧出现该插件的详细信息,点击绿色按钮"Install plugin”安装插件,如下图所示:
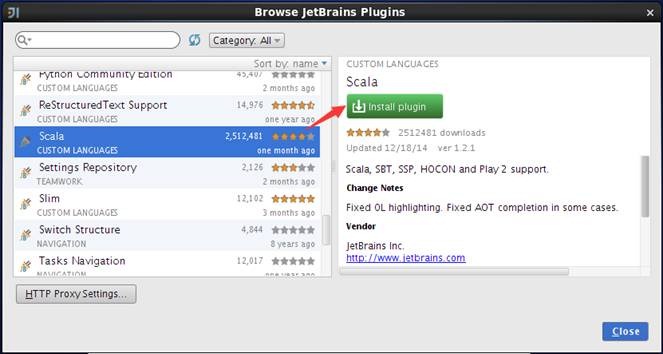
安装过程将出现安装进度界面,通过该界面了解插件安装进度,如下图所示:
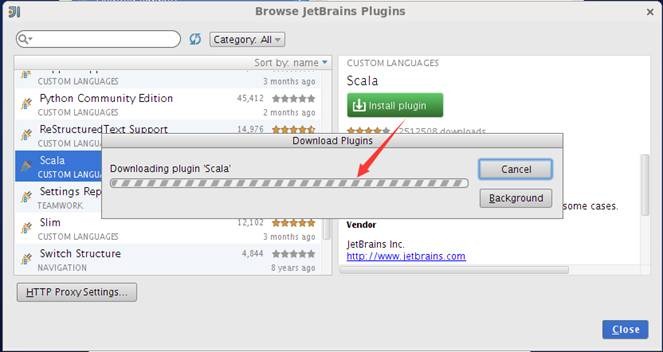
安装插件后,在启动界面中选择创建新项目,弹出的界面中将会出现"Scala"类型项目,选择后将出现提示创建的项目是仅Scala代码项目还是SBT代码项目,如下图所示:

1.2.3 设置界面主题
从IntelliJ IDEA12开始起推出了Darcula 主题的全新用户界面,该界面以黑色为主题风格得到很多开发人员的喜爱,下面我们将介绍如何进行配置。在主界面中选择File菜单,然后选择Setting子菜单,如下图所示:

在弹出的界面中选择Appearance &Behavior中Appearance,其中Theme中选择Darcula主题,如下图所示:
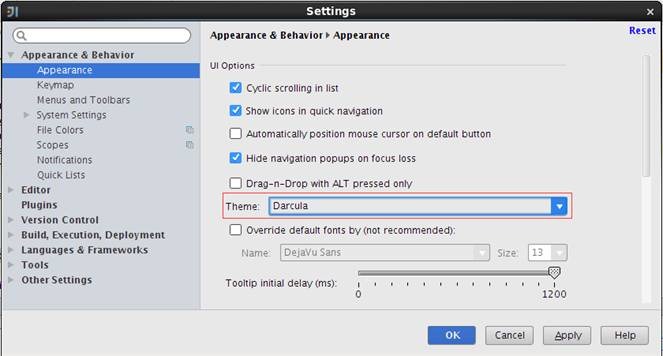
保存该主题重新进入,可以看到如下图样式的开发工具,是不是很酷!
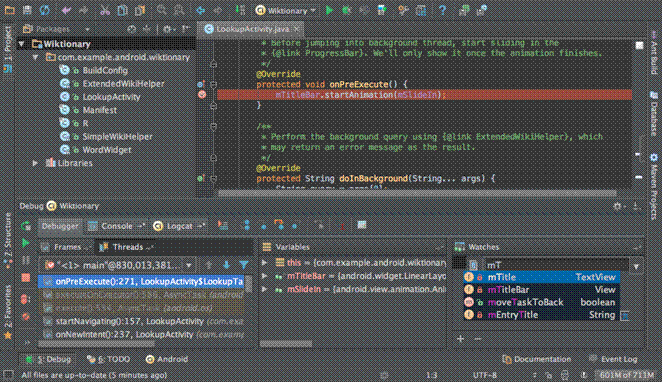
2 使用IDEA编写例子
2.1 创建项目
2.1.1 设置项目基本信息
在IDEA菜单栏选择File->New Project,出现如下界面,选择创建Scala项目:
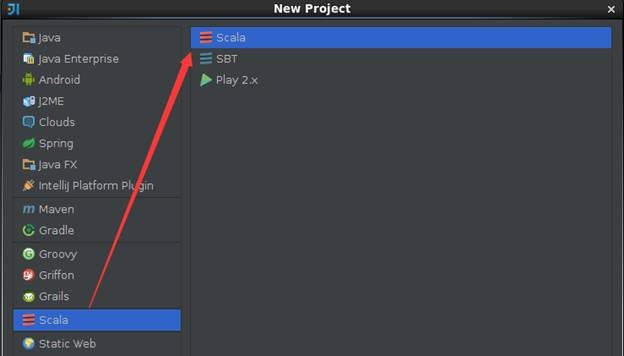
在项目的基本信息填写项目名称、项目所在位置、Project SDK和Scala SDK,在这里设置项目名称为class3,关于Scala SDK的安装参见第2节《Spark编译与部署》下Spark编译安装介绍:
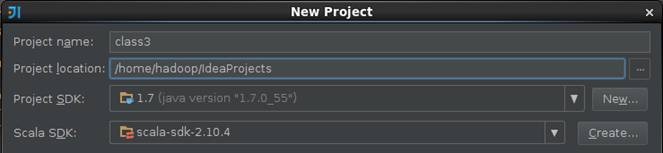
2.1.2 设置Modules
创建该项目后,可以看到现在还没有源文件,只有一个存放源文件的目录src以及存放工程其他信息的杂项。通过双击src目录或者点击菜单上的项目结构图标打开项目配置界面,如下图所示:
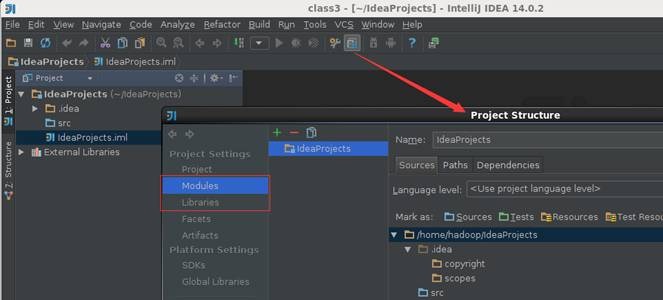
在Modules设置界面中,src点击右键选择“新加文件夹”添加src->main->scala目录:
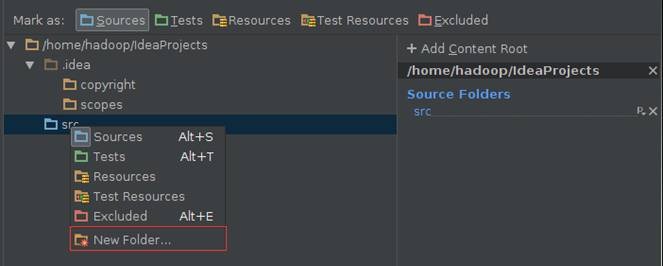
在Modules设置界面中,分别设置main->scala目录为Sources类型:
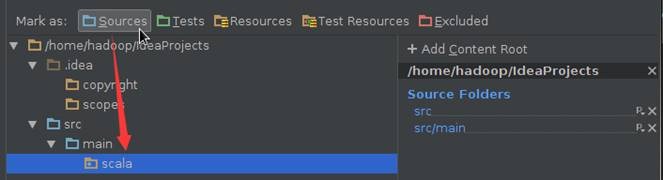
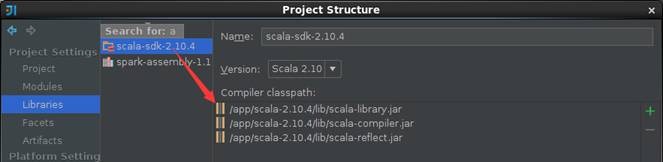
2.1.3 配置Library
选择Library目录,添加Scala SDK Library,这里选择scala-2.10.4版本
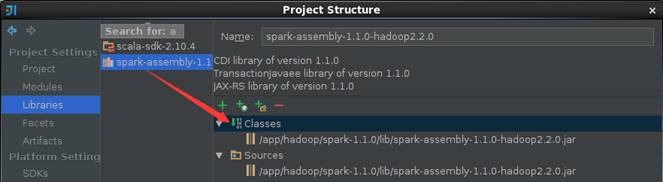
添加Java Library,这里选择的是在$SPARK_HOME/lib/spark-assembly-1.1.0-hadoop2.2.0.jar文件,添加完成的界面如下:
2.2 例子1:直接运行
《Spark编程模型(上)--概念及Shell试验》中使用Spark-Shell进行了搜狗日志的查询,在这里我们使用IDEA对Session查询次数排行榜进行重新练习,可以发现借助专业的开发工具可以方便快捷许多。
2.2.1 编写代码
在src->main->scala下创建class3包,在该包中添加SogouResult对象文件,具体代码如下:
package class3 import org.apache.spark.SparkContext._
import org.apache.spark.{SparkConf, SparkContext} object SogouResult{
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: SogouResult <file1> <file2>")
System.exit(1)
} val conf = new SparkConf().setAppName("SogouResult").setMaster("local")
val sc = new SparkContext(conf) //session查询次数排行榜
val rdd1 = sc.textFile(args(0)).map(_.split("\t")).filter(_.length==6)
val rdd2=rdd1.map(x=>(x(1),1)).reduceByKey(_+_).map(x=>(x._2,x._1)).sortByKey(false).map(x=>(x._2,x._1))
rdd2.saveAsTextFile(args(1))
sc.stop()
}
}
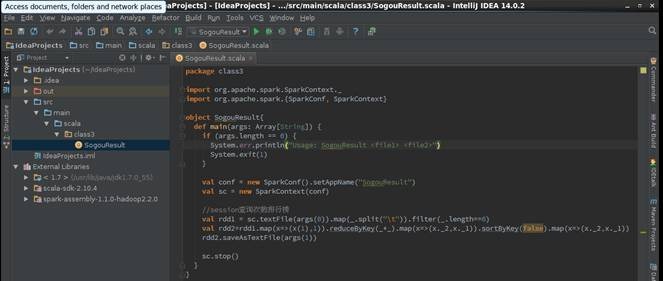
2.2.2 编译代码
代码在运行之前需要进行编译,可以点击菜单Build->Make Project或者Ctrl+F9对代码进行编译,编译结果会在Event Log进行提示,如果出现异常可以根据提示进行修改
2.2.3 运行环境配置
SogouResult首次运行或点击菜单Run->Edit Configurations打开"运行/调试 配置界面"
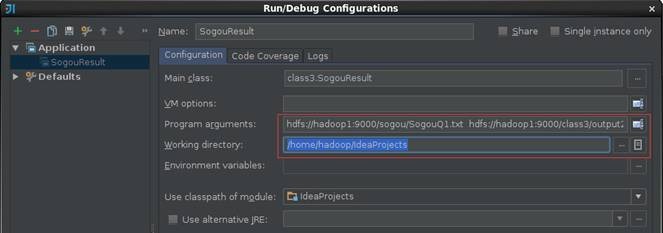
运行SogouResult时需要输入搜狗日志文件路径和输出结果路径两个参数,需要注意的是HDFS的路径参数路径需要全路径,否则运行会报错:
l 搜狗日志文件路径:使用上节上传的搜狗查询日志文件hdfs://hadoop1:9000/sogou/SogouQ1.txt
l 输出结果路径:hdfs://hadoop1:9000/class3/output2
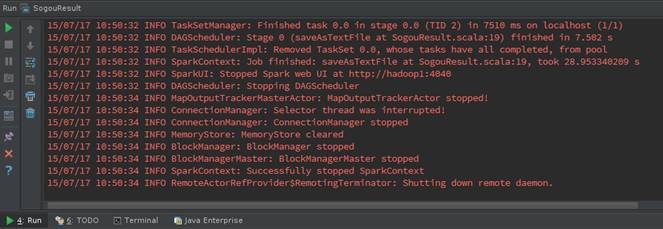
2.2.4 运行结果查看
启动Spark集群,点击菜单Run->Run或者Shift+F10运行SogouResult,在运行结果窗口可以运行情况。当然了如果需要观察程序运行的详细过程,可以加入断点,使用调试模式根据程序运行过程。
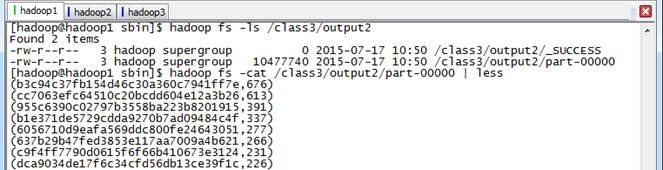
使用如下命令查看运行结果,该结果和上节运行的结果一致
hadoop fs -ls /class3/output2
hadoop fs -cat /class3/output2/part-00000 | less
2.3 例子2:打包运行
上个例子使用了IDEA直接运行结果,在该例子中将使用IDEA打包程序进行执行
2.3.1 编写代码
在class3包中添加Join对象文件,具体代码如下:
package class3 import org.apache.spark.SparkContext._
import org.apache.spark.{SparkConf, SparkContext} object Join{
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: Join <file1> <file2>")
System.exit(1)
} val conf = new SparkConf().setAppName("Join").setMaster("local")
val sc = new SparkContext(conf) val format = new java.text.SimpleDateFormat("yyyy-MM-dd")
case class Register (d: java.util.Date, uuid: String, cust_id: String, lat: Float,lng: Float)
case class Click (d: java.util.Date, uuid: String, landing_page: Int)
val reg = sc.textFile(args(0)).map(_.split("\t")).map(r => (r(1), Register(format.parse(r(0)), r(1), r(2), r(3).toFloat, r(4).toFloat)))
val clk = sc.textFile(args(1)).map(_.split("\t")).map(c => (c(1), Click(format.parse(c(0)), c(1), c(2).trim.toInt)))
reg.join(clk).take(2).foreach(println) sc.stop()
}
}
2.3.2 生成打包文件
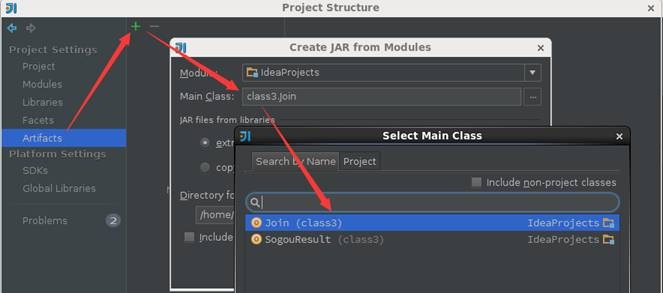
第一步 配置打包信息
在项目结构界面中选择"Artifacts",在右边操作界面选择绿色"+"号,选择添加JAR包的"From modules with dependencies"方式,出现如下界面,在该界面中选择主函数入口为Join:
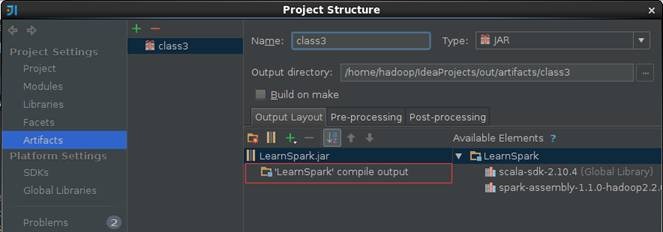
第二步 填写该JAR包名称和调整输出内容
【注意】的是默认情况下"Output Layout"会附带Scala相关的类包,由于运行环境已经有Scala相关类包,所以在这里去除这些包只保留项目的输出内容
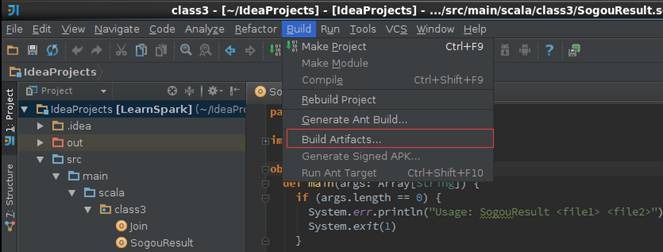
第三步 输出打包文件
点击菜单Build->Build Artifacts,弹出选择动作,选择Build或者Rebuild动作
第四步 复制打包文件到Spark根目录下
cd /home/hadoop/IdeaProjects/out/artifacts/class3
cp LearnSpark.jar /app/hadoop/spark-1.1.0/
ls /app/hadoop/spark-1.1.0/

2.3.3 运行查看结果
通过如下命令调用打包中的Join方法,运行结果如下:
cd /app/hadoop/spark-1.1.0
bin/spark-submit --master spark://hadoop1:7077 --class class3.Join --executor-memory 1g LearnSpark.jar hdfs://hadoop1:9000/class3/join/reg.tsv hdfs://hadoop1:9000/class3/join/clk.tsv
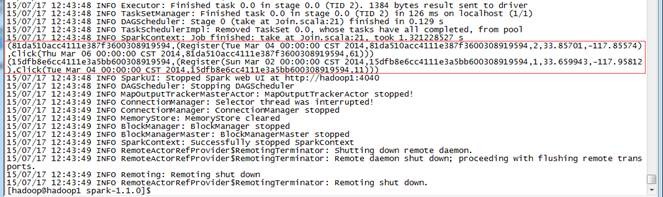
3、问题解决
3.1 出现"*** is already defined as object ***"错误
编写好SogouResult后进行编译,出现"Sogou is already as object SogouResult"的错误,

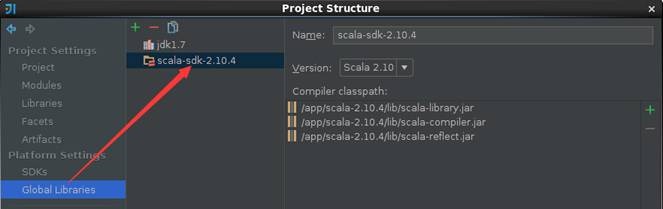
出现这个错误很可能不是程序代码的问题,很可能是使用Scala JDK版本问题,作者在使用scala-2.11.4遇到该问题,换成scala-2.10.4后重新编译该问题得到解决,需要检查两个地方配置:Libraries和Global Libraries分别修改为scala-2.10.4
Spark入门实战系列--3.Spark编程模型(下)--IDEA搭建及实战的更多相关文章
- Spark入门(七)--Spark的intersection、subtract、union和distinc
Spark的intersection intersection顾名思义,他是指交叉的.当两个RDD进行intersection后,将保留两者共有的.因此对于RDD1.intersection(RDD2 ...
- Spark入门(六)--Spark的combineByKey、sortBykey
spark的combineByKey combineByKey的特点 combineByKey的强大之处,在于提供了三个函数操作来操作一个函数.第一个函数,是对元数据处理,从而获得一个键值对.第二个函 ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--4.Spark运行架构
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 1. Spark运行架构 1.1 术语定义 lApplication:Spark Appli ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark入门实战系列--7.Spark Streaming(下)--实时流计算Spark Streaming实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .实例演示 1.1 流数据模拟器 1.1.1 流数据说明 在实例演示中模拟实际情况,需要源源 ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark入门实战系列--9.Spark图计算GraphX介绍及实例
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .GraphX介绍 1.1 GraphX应用背景 Spark GraphX是一个分布式图处理 ...
随机推荐
- MyEclipse调用Matlab打包函数
本文部分内容参考了http://www.360doc.com/content/15/1103/16/1180274_510463048.shtml 一.检查Java环境 对于已经装上JAVA环境的计算 ...
- Unity3d中Update()方法的替身
在网上看到一些资料说Unity3d的Update方法是如何如何不好,影响性能.作为一个菜鸟,之前我还觉得挺好用的,完全没用什么影响性能的问题存在.现在发现确实有很大的问题,我习惯把一大堆检测判断放在U ...
- [laravel] Laravel - composer install
#composer installLoading composer repositories with package informationUpdating dependencies (includ ...
- 使用vim在Linux下编写C语言程序
1.进入字符界面 2.创建文件夹用于存放源文件 mkdir helloworld //创建文件夹命令 cd helloworld //进入新建的文件夹,这里应该说目录比较好,win ...
- [leetcode 37]sudoku solver
1 题目: 根据给出的数独,全部填出来 2 思路: 为了做出来,我自己人工做了一遍题目给的数独.思路是看要填的数字横.竖.子是否已经有1-9的数字,有就剔除一个,最后剩下一个的话,就填上.一遍一遍的循 ...
- MySQL数据库有外键约束时使用truncate命令的办法
MySQL数据库操作中,Delete与Truncate两个命令都可以删除一个数据表中的全部数据,使用办法分别是: DELETE FROM t_question TRUNCATE TABLE t_que ...
- 高性能网站架构设计之缓存篇(4)- Redis 主从复制
Redis 的主从复制配置非常容易,但我们先来了解一下它的一些特性. redis 使用异步复制.从 redis 2.8 开始,slave 也会周期性的告诉 master 现在的数据量.可能只是个机制, ...
- 冲刺阶段 day 10
项目进展 目前我们已经完成了系部管理,教师管理,班级管理,学生管理这四大部分代码的编写及数据库的搭建与连接.就差最后专业管理这一部分了. 存在问题 其实我们从开始这个项目到现在,最大的问题还是在代码编 ...
- 由一篇文章引发的思考——多线程处理大数组
今天领导给我们发了一篇文章文章,让我们学习一下. 文章链接:TAM - Threaded Array Manipulator 这是codeproject上的一篇文章,花了一番时间阅读了一下.文章主要是 ...
- [ACM_动态规划] 找零种类
问题描述:假设某国的硬币的面值有 1.5.10.50 元四种,输入一个金额 N (正整数,N<=1000),印出符合该金额的硬币组合有多少种. 问题分析: 1.5.10 元组合出 N 元的方法数 ...