spark学习之IDEA配置spark并wordcount提交集群
这篇文章包括以下内容
(1)IDEA中scala的安装
(2)hdfs简单的使用,没有写它的部署
(3) 使用scala编写简单的wordcount,输入文件和输出文件使用参数传递
(4)IDEA打包和提交方法
一 IDEA中scala的安装
(1) 下载IEDA 装jdk
(2) 启动应用程序 选择插件(pluigin)查看scala版本,然后去对应的网站下载https://plugins.jetbrains.com/plugin/1347-scala
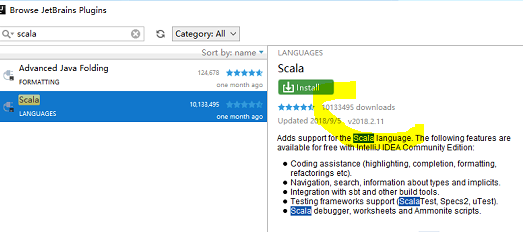
(4) 将刚才下载的scala zip文件移动到IDEA的plugin下面
(5) 回到启动页面 选择plugin

选择从磁盘安装,然后重启
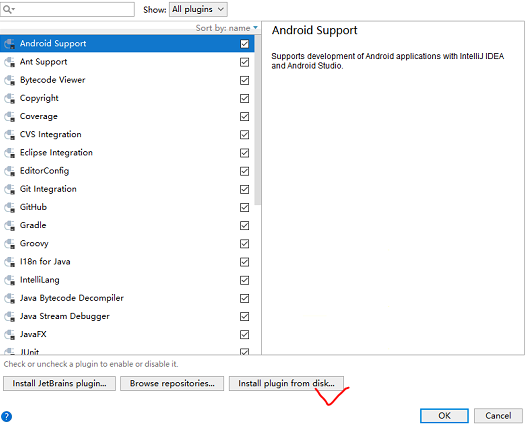
(6)新建项目 scala项目 如果没有scala sdk 那么windows下一个导入进去(注意版本一致)
二 提交wordcount并提交jar
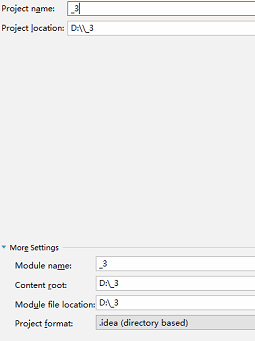
(1) 新建Maven项目
file->project->maven->next-->设置工程名称和路径(路径不要为中文)--->完成
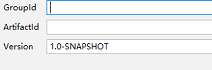
(2)将pol导入依赖,粘贴下面代码以后,需要点击右侧的maven project并刷新
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion> <groupId>com.xuebusi</groupId>
<artifactId>spark</artifactId>
<version>1.0-SNAPSHOT</version> <properties>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<encoding>UTF-</encoding> <!-- 这里对jar包版本做集中管理 -->
<scala.version>2.10.</scala.version>
<spark.version>1.6.</spark.version>
<hadoop.version>2.6.</hadoop.version>
</properties> <dependencies>
<dependency>
<!-- scala语言核心包 -->
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<!-- spark核心包 -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.</artifactId>
<version>${spark.version}</version>
</dependency> <dependency>
<!-- hadoop的客户端,用于访问HDFS -->
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies> <build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin> <plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<!-- 由于我们的程序可能有很多,所以这里可以不用指定main方法所在的类名,我们可以在提交spark程序的时候手动指定要调用那个main方法 -->
<!--
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.xuebusi.spark.WordCount</mainClass>
</transformer>
</transformers>
--> </configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
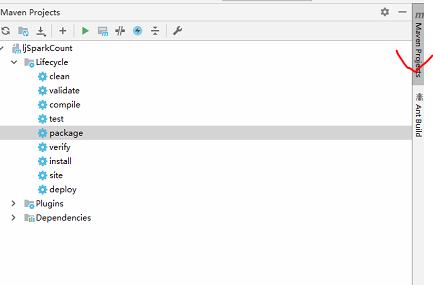
这个时候在左侧的依赖就会出现很多maven包,注意要有网络哈
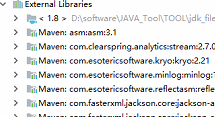
(2)修改pol部分内容如下,错误的内容会出现红色的字样哦
在pom.xml文件中还有错误提示,因为src/main/和src/test/这两个目录下面没有scala目录。
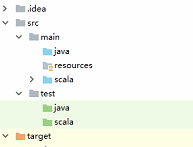
(3) 右击项目src,新建scala class,选择object
(4) 编写代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} /**
* Created by SYJ on 2017/1/23.
*/
object WordCount {
def main(args: Array[String]) {
//创建SparkConf
val conf: SparkConf = new SparkConf()
//创建SparkContext
val sc: SparkContext = new SparkContext(conf)
//从文件读取数据
val lines: RDD[String] = sc.textFile(args())
//按空格切分单词
val words: RDD[String] = lines.flatMap(_.split(" "))
//单词计数,每个单词每出现一次就计数为1
val wordAndOne: RDD[(String, Int)] = words.map((_, ))
//聚合,统计每个单词总共出现的次数
val result: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//排序,根据单词出现的次数排序
val fianlResult: RDD[(String, Int)] = result.sortBy(_._2, false)
//将统计结果保存到文件
fianlResult.saveAsTextFile(args())
//释放资源
sc.stop()
}
}
(5) 打包
将编写好的WordCount程序使用Maven插件打成jar包,打包的时候也要保证电脑能够联网,因为Maven可能会到中央仓库中下载一些依赖:
双击package

打包成功提示
(6) 在jar包上面右击 copy path找到jar在win下的路径并上传到集群
(7) 启动hdfs 因为只用到hdfs,创建一个目录 hdfs dfs -mkdir /wc 然后创建一个txt文件
/hadoop/sbin/start-dfs.sh
(8)启动集群
/spark/sbin/start-all.sh
(9) jps查看master和worker是否都起来
(10) 提交给集群 后面两个参数分别为输入输出文件
bin/spark-submit --class spark.wordCount --executor-memory 512m --total-executor-cores 2 /home/hadoop/hadoop/spark-2.3.1-bin-hadoop2.7/spark_testJar/ljSparkCount-1.0-SNAPSHOT.jar hdfs://slave104:9000/wc hdfs://slave104:9000/wc/output
(11)验证

好了,到此结束,加油骚年
spark学习之IDEA配置spark并wordcount提交集群的更多相关文章
- Spark学习笔记2(spark所需环境配置
Spark学习笔记2 配置spark所需环境 1.首先先把本地的maven的压缩包解压到本地文件夹中,安装好本地的maven客户端程序,版本没有什么要求 不需要最新版的maven客户端. 解压完成之后 ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- spark学习及环境配置
http://dblab.xmu.edu.cn/blog/spark/ 厦大数据库实验室博客 总结.分享.收获 实验室主页 首页 大数据 数据库 数据挖掘 其他 子雨大数据之Spark入门教程 林子 ...
- Spark学习(一) -- Spark安装及简介
标签(空格分隔): Spark 学习中的知识点:函数式编程.泛型编程.面向对象.并行编程. 任何工具的产生都会涉及这几个问题: 现实问题是什么? 理论模型的提出. 工程实现. 思考: 数据规模达到一台 ...
- Spark学习(四) -- Spark作业提交
标签(空格分隔): Spark 作业提交 先回顾一下WordCount的过程: sc.textFile("README.rd").flatMap(line => line.s ...
- Spark学习笔记--Linux安装Spark集群详解
本文主要讲解如何在Linux环境下安装Spark集群,安装之前我们需要Linux已经安装了JDK和Scala,因为Spark集群依赖这些.下面就如何安装Spark进行讲解说明. 一.安装环境 操作系统 ...
- Spark学习笔记6:Spark调优与调试
1.使用Sparkconf配置Spark 对Spark进行性能调优,通常就是修改Spark应用的运行时配置选项. Spark中最主要的配置机制通过SparkConf类对Spark进行配置,当创建出一个 ...
- Spark学习笔记5:Spark集群架构
Spark的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展计算能力.Spark可以在各种各样的集群管理器(Hadoop YARN , Apache Mesos , 还有Spark自带的独立 ...
- Spark学习笔记1:Spark概览
Spark是一个用来实现快速而通用的集群计算的平台. Spark项目包含多个紧密集成的组件.Spark的核心是一个对由很多计算任务组成的,运行在多个工作机器或者是一个计算集群上的应用进行调度,分发以及 ...
随机推荐
- Ecilpse绑定jdk的源码
因为近期才入职,所以电脑环境才配好,今天在写代码的时候,想查看源码,发现不能查看,所以在网上百度了一下: 下面是解决方法: 1.在Ecilpse的窗体下,点击Preferences 2.然后点击Jav ...
- Basic Socket
http://www.avajava.com/tutorials/lessons/how-do-i-make-a-socket-connection-to-a-server.html?page=1 t ...
- 2014年辛星解读css第五节
本小节我们解说css中的"盒模型".即"box model",它通经常使用于在布局的时候使用,这个"盒模型"也有人成为"框模型&q ...
- EasyDarwin接入ffmpeg实现264转图片快照功能
本文转自:http://blog.csdn.net/cai6811376/article/details/51774467 EasyDarwin一直坚持开源精神,所以我们着手把EasyDarwin中使 ...
- Red Black Tree java.util.TreeSet
https://docs.oracle.com/javase/9/docs/api/java/util/SortedMap.html public interface SortedMap<K,V ...
- ThinkPHP利用数据库字段做栏目的无限分类
一直以来对cms后台的栏目管理不太理解,尤其是子栏目顶级栏目这种关系,通过网上的搜索与自己的摸索,实现方法如下(原理是利用数据库的path字段): 1.建立简单的栏目表: CREATE TABLE ` ...
- [coci2011]友好数对 容斥
无趣的小x在玩一个很无趣的数字游戏.他要在n个数字中找他喜欢友好数对.他对友好数对的定义是:如果有两个数中包含某一个以上相同的数位(单个数字),这两个数就是友好数对.比如:123和345 就是友好数对 ...
- android studio导入项目出现的奇葩错误
1.Error:(1, 0) Cause: com/android/build/gradle/AppPlugin : Unsupported major.minor version 52.0
- android——实现多语言支持
我们知道,建好一个android 的项目后,默认的res下面 有layout.values.drawable等目录.这些都是程序默认的资源文件目录,如果要实现多语言版本的话,我们就要添加要实现语言的对 ...
- jquery特效(5)—轮播图③(鼠标悬浮停止轮播)
今天很无聊,就接着写轮播图了,需要说明一下,这次的轮播图是在上次随笔中jquery特效(3)—轮播图①(手动点击轮播)和jquery特效(4)—轮播图②(定时自动轮播)的基础上写出来的,也就是本次随笔 ...