2019腾讯广告算法大赛 Rank23
由于官方审核代码,代码将在2019年6月28号后开源
写在前面
这次腾讯的第三届广告算法大赛,是我第一次参加,取得了初赛与复赛均为23名的成绩,毕竟我只是初打比赛不久的小白。我想在此分享下我的基本解题思路。
赛题背景:
广告曝光预估如何应用在实际业务中?
腾讯的效果广告主要是展示类广告,其背后的算法引擎本质上是一个推荐框架。当新增一条广告请求时,系统会自动执行召回候选广告和排序筛选两个步骤。
召回的条件是判断广告自身的定向设置、时段设置、素材尺寸是否和当前请求的用户属性、请求时间、广告位规格相匹配。召回之后的候选广告队列会按照一定规则排序。为平衡平台收益和用户体验,排序使用的是广义的eCPM(千次曝光消耗)指标来排序,其中包括:直接与bid(广告主愿意为每次点击付出的钱)、pctr(广告的预估点击率)相关的basic_eCPM;以及和用户体验相关的quality_eCPM。所以易知,同一个广告bid越大,total_eCPM越高,排第一的可能性越高,获得曝光的机会越大。这也是竞价广告机制的特性之一。
因此,当广告的出价、定向、投放时段和素材被设定好之后,它覆盖的人群范围和实际竞争环境、自身竞争能力就能够大致确定,也就基本决定了广告的日曝光量级。假设我们的广告主投放相对稳定,没有突然出现大广告主出高价竞争,流量也无特别大的波动(比如节假日、购物节等)。这样我们就可以据此预估广告每日曝光。
这样的预估结果能够在实际场景中为广告主服务。广告主可以根据曝光预估结果提前调整出价、定向、时段等设置,结合自身的投放预期选择最适合自己的设置,而不是投放几天之后再去修改,从而减少广告主的试错时间和成本。场外Tips?
本次赛题是从实际的业务问题中做了简化,同时也尽量保留了一些业务问题的原貌。样本和特征维度需要大家从不同部分的数据文件中清洗、提炼、拼接,定义出样本和特征维度以及训练的目标Label。而上述步骤,其实也是实际工作中的一个小缩影。实际广告投放中涉及多流量频道,多广告类型,并会包含不同的计费模式、不同的出价模式(如oCPA智能出价),以及复杂的定向方式(自动定向、lookalike等)。
本次的赛题中,测试集中的广告选取了简单定向设置的传统CPC出价广告。传统CPC出价,即为广告主给每个广告一个出价bid,其代表了愿意为每次广告点击支付的费用(做gsp二阶机制里实际单次点击扣费要低于bid),对每次广告请求,广告都以这个bid去参与竞争排序,直到广告主主动修改出价。当然,CPC出价的广告会和其他不同类型(包括智能出价等)广告一同去抢曝光,所以历史曝光日志里的广告和广告静态数据里的广告不光是传统CPC出价广告。
为了降低大家的理解难度和干扰,在不影响建模的情况下,我们在提供初赛数据时有意做了删减。初赛数据可以理解为只有和测试集中同类型的广告才能得到全部的完整广告设置。
关于初赛阶段最终的评估指标,除了数值预估问题最常用的准确性指标以外,出于业务场景的实际需要,我们还加入了出价相关性的评估指标,也就是出价和预估曝光的正相关。这意味着,选手们需在满足相关性的基础上同时最大化预估的准确性,这也是此次赛题和其他CTR预估或者推荐问题最大的差异和挑战。
初赛复赛任务解释
和初赛数据相比,复赛数据有不小的改变。其中最大的变化是测试集上的 变化,线下了解到选手们对此也有不同的看法和困惑。因此,从出题者的角度 来说说这样做的考虑。 首先,就是测试集给了预估当天的日志明细(当然隐去了待预估广告的信 息), 以及预估广告实际触发的请求列表。这和初赛只给了待预估广告的定向 时段等设置是不同的,有些同学认为是 leak 特征,即用未来的数据用于未来 目标的预测。我们内部一般称之为“穿越”。
在真实业务场景中当然无法直接用未来的特征来预估,更不会用 leak 或穿 越的特征去训练模型直接应用到线上(要么无法构造真实样本要么做各种近似 后效果大打折扣)。但在特定工作场景中,使用"穿越"特征在做特征类和算法 调研上仍有用武之地。
回到我们的曝光预估问题本身, 它的核心问题有两个:一是预估广告的竞 争环境和覆盖能力;二是预估自身的竞争力以及在竞争环境中的胜出能力。更通俗一点, 一是要估计广告在未来可能会被哪些用户的请求触发,这些请求同 时触发的竞争对手水平如何; 二是要估计广告自己在这些请求中竞争里如何, 以及能胜出的比例。而在实际工作中,为提升整体的研发效率,整个曝光预估 的任务是可以按上述一分为二的并行去做的。而且二个子任务的侧重和瓶颈各 不相同,抽象而成的建模问题也是有差异的。
第一个子任务就是用广告的定向时段等设置来用预估未来的触发请求数和 曝光分数分布情况,它也可拆分两个更小的目标,一是用定向时段素材尺寸这 些来召回历史匹配的请求数据,这部分主要是业务规则的匹配,瓶颈主要在于 运行的效率和复杂业务规则的适配及可扩展问题(实际业务中的定向维度远比 初赛中使用的定向维度复杂的多,不同广告位的业务匹配逻辑也更加复杂), 二是用历史请求数据预估未来的请求数据,这更像是一个时间序列建模问题, 即用历史的变化趋势预估未来。
第二个子任务是预估广告的相对竞争水平以及基于此的胜出比例,它的前 提是触发的请求和竞价队列已知(这是第一个子任务的预估结果)。此时,我 们如果使用当天已知的触发请求和竞价队列去抽取特征建模预估当天的曝光 (即使用所谓”穿越“特征),这里得到的评估结果必然是高估的(和实际业务 效果对比),因为这实际上是基于第一个子任务预估百分百准确的前提。 但这 不妨碍基于此去做特征构建和模型算法的调研选择(基于同样假设的评估结果 横向比较)。 而经调研优选得到的最优的特征和模型,同样可以结合第一个子 任务的结果重新进行评估(相同的特征计算方式和模型从未来数据迁移到历史 数据),最终得到真实的模型整体预估效果。 综上,大家已经可以看出,初赛是完整的业务问题抽象, 而复赛数据其实 就是第二个子任务的抽象。
赛题分析:
腾讯效果广告采用的是GSP(Generalized Second-Price)竞价机制,广告的实际曝光取决于广告的流量覆盖大小和在竞争广告中的相对竞争力水平。其中广告的流量覆盖取决于广告的人群定向(匹配对应特征的用户数量)、广告素材尺寸(匹配的广告位)以及投放时段、预算等设置项。而影响广告竞争力的主要有出价、广告质量等因素(如pctr/pcvr等), 以及对用户体验的控制策略。 通常来说, 基本竞争力可以用ecpm = 1000 * cpc_bid * pctr = 1000 * cpa_bid * pctr * pcvr (cpc, cpa分别代表按点击付费模式和按转化付费模式)。综上,前者决定广告能参与竞争的次数以及竞争对象,后者决定在每次竞争中的胜出概率。二者最终决定广告每天的曝光量。
本次竞赛将提供历史n天的曝光广告的数据(特定流量上采样), 包括对应每次曝光的流量特征(用户属性和广告位等时空信息)以及曝光广告的设置和竞争力分数;测试集是新的一批广告设置(有完全新的广告id, 也有老的广告id修改了设置), 要求预估这批广告的日曝光 。(出于业务数据安全保证的考虑,所有数据均为脱敏处理后的数据。)
此次问题有两个评判标准,1 准确性相关指标 2单调性指标。 准确性指标采用SMAPE,出价单调性指标指对待预估广告 ad, 除出价 bid 外其他设置不变,任意变化 n 个 bid 取值,得到对应
的 n 个曝光预估值 ,满足单调性,为此可采用两步走,第一步预测保证单个广告的预估曝光量相同,也就是相同广告id的特征相同。第二步调整广告id预估曝光量的单调性,这里要尽量保证
预估曝光量的稳定性,由于不知道真实出价,可对bid进行排名,此外由于要求保留四位小数,单调性调整可使用基准曝光量+0.0001*出价排名。
问题建模:
由于此次比赛只提供了历史广告曝光日志,与广告静态属性以及广告操作属性,所以需要自己构造训练集与验证集。
广告操作数据处理:
由于广告的操作属性如状态取值,出价,投放时段,以及定向人群每天的值是不同的,所以可采用两种方案:第一种是直接取创建时的属性,第二种是利用请求时间以及修改创建时的时间进行匹配得到广告的操作属性,经试验, 线上差距不大
训练集与验证集生成:
初赛提取方案:以请求时间,广告id为主键,对request-id求count,就得到了某个广告某一天的曝光量。
复赛提取方案: 对竞价队列进行展开,同样以请求时间,广告id为主键,对曝光量标志位求sum,就得到了某个广告某一天的曝光量。
广告id的选取:直观来看训练集样本数量越多,但是仔细读题后发现初赛测试集预测的主要是CPC类广告,所以对于无法在广告操作数据表中匹配到的数据都可以舍弃,这样清洗下来的数据量又明显小了一大截,只剩下十几万了。 采用同样的方法训练,虽然数据量变小了,但线上成绩提高了。同时由于0曝光量数量太多,会导致模型学到很多负值,所以可过滤掉请求次数小于特定值,仍旧是0曝光的广告,留下很不容易的曝光广告。
特征工程:
初赛方案:
规则: 可采用测试集前两天的历史曝光量均值:
模型:
初赛主要围绕两方面来考虑: 一是用定向时段素材尺寸这 些来召回历史匹配的请求数据, 二是用历史请求数据预估未来的请求数据。
采用广告特征有两方面,第一个是基本静态特征如广告id,广告账户id等属性,第二个是投放时段以及定向人群。对于投放时段以及定向人群,一方面可以看做是多值特征,利用CountVectorizer进行词频统计,第二个是计算投放时 长,第二个是将定向人群特征进行拆分成用户属性,如年龄,性别,地域,婚恋状态,学历,消费能力,设备,工作状态,连接类型,行为兴趣等等。利用user_data日志文件构建字典,通过拆分后的人群属性计算各个字段人群数量。拆分后的定向人群属性同样是多值属性,仍旧采用CountVectorizer进行词频统计。 如果想要得到更精确地人群定向属性,可利用深度优先搜索暴力枚举定向人群属性完整的用户属性,不过复杂度太高。
这样就通过定向和用户匹配、广告位和素材匹配等规则估算了广告的覆盖范围
初赛A的时候大部分人模型都干不过规则,从这方面可以考虑历史曝光量相关特征。由于测试集中有完全新的广告id,所以可以考虑历史平移构造广告id、广告账户id、广告行业id、商品id、的历史曝光量,保证新旧广告的预测准确度。进一步可以考虑二阶,三阶等。初赛B的时候发现了以下规律,
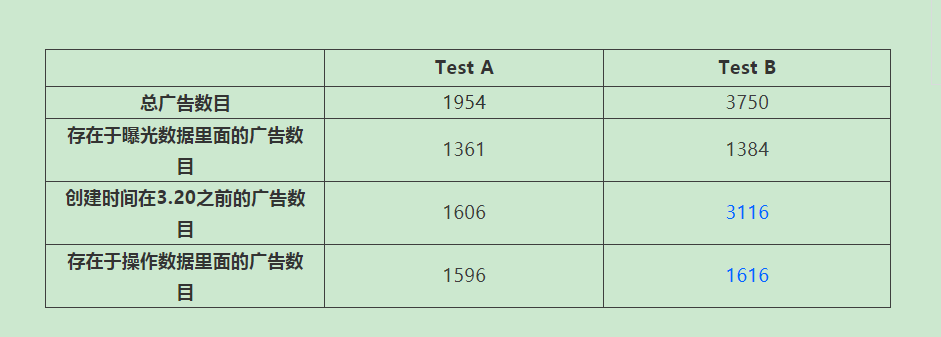
测试集a中的旧广告大多能在操作数据中找到对应数据,但是测试集b中有很多旧广告找不到对应的操作数据。基于这样的情况,出题方可能提供了一种新类型的广告,
那么可以利用创建时间,请求时间,请求时间减去创建时间作为特征。
初赛模型方案是旧广告用规则(采用前两天广告id的历史曝光量均值),新广告用模型预测。
复赛方案:
规则:采用广告id的历史获胜概率(广告id的曝光量除以广告id的请求次数)乘以测试集当天的请求次数,这里需要注意一点的是如果直接用测试集前一天的获胜概率乘以测试集当天的请求次数,效果并不好,原因是
测试集广告在前一天的广告id较少,采用历史均值是较好的方案。此外由于不同广告在不同广告位上的请求分布也是不一样的,那么通过求广告id在某一广告位的获胜概率是比较有效地,线上相比单单采取广告
id的获胜概率,规则提升了0.2,然而模型并没有提升,这可能是累积导致误差增大的缘故。
模型:
对于预测类问题来说,一般时间越接近的特征,越准确,复赛提供了测试集当天信息,那么我们就必须要充分利用。所以特征按照时间主要分为两方面,第一个是历史特征,第二个是当天特征,
当天特征主要有当天的请求次数,当天的失效率,
历史特征主要有历史曝光量,未曝光量,曝光比例,可采用五折交叉统计以及历史平移统计,广告id的pctr,quality_ecpm,total_ecpm等竞争力特征,这部分采用历史平移效果较好。
由于模型主要针对新广告,所以需要利用广告的静态属性构造上述特征。如广告账户id,广告行业id,商品id,等等二阶甚至三阶都是可以做的。
上述构造特征采用的主要手段有五折交叉,历史平移,CountVectorizer下面分别介绍。
目标编码,一切问题都可以考虑根据目标变量进行有监督的构造特征。此题也不例外,目标变量为广告日曝光值,那么我们就可以构造与目标有关的特征。然而这会存在一个问题,特别容易过拟合。
CTR比赛中历史点击率无疑是一个强特,但是往往会造成过拟合。究其原因是进行目标编码的时候没有防过拟合处理,导致数据泄露。有效的办法是采用交叉验证的方式,比如我们将将样本划分为5份,对于其中每一份数据,我们都用另外4份数据来构造。简单来说未知的数据在已知的数据里面取特征。
统计特征,一切皆可统计,类别特征可以计数统计,可以nunique统计,数值特征可以均值统计,最大最小,中位数等。官方解释把该问题抽象成一个符合正相关性的CTR预估问题,也就是说pctr越大,其曝光量就应该越大。既然广告曝光预测问题不好理解,我们可以将其转为CTR问题。这样就可以根据相关赛题,联想到很多特征。
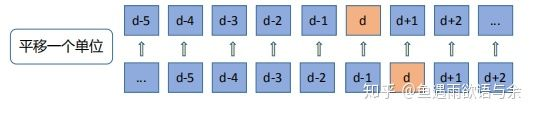
历史平移,对于这种包含时间的时序问题,测试集的具体数据是不知道的,我们可以使用前n天来曝光量,或者是pctr作为测试集的特征。如下图,d-1天的信息作为d天的特征,这种相近日期的数据相关性是非常大的。在群里也能看到很多人直接用前一天的曝光量才填充,这种规则就能得到很高的分数。
CountVectorizer是属于常见的特征数值计算类,是一个文本特征提取方法,属于词袋模型,进一步地有TF-IDF模型。对于每一个训练文本,它只考虑每种词汇在该训练文本中出现的频率。对于多值特征,最方便的展开方式就是使用CountVectorizer。
模型评估与验证:
交叉验证。这里有两个验证方案,1.由于是时序问题,为了避免数据泄露,常选择训练集最后一天进行线下验证。2.K-folds交叉验证,这个线下应该会比方案1线下好些。
模型融合:
新旧广告定义: 未在训练集中出现的广告id为历史旧广告,否则为新广告,历史旧广告采用规则,新广告采用模型
规则融合:规则一采用广告id在某个广告位的历史获胜概率乘以广告id当天在这个广告位的请求次数,规则二采用广告id在某个广告位的单次历史获胜概率乘以广告id当天在这个广告位竞争对手的个数, 采用加权融合
模型融合:模型一使用lightgbm训练,模型二使用xgboost训练,特征方面的差异主要有lightgbm使用广告id在某个广告位的历史获胜概率以及广告id当天在这个广告位的请求次数构造特征,模型二采用广告id在某个
广告位的单次历史获胜概率以及广告id当天在这个广告位竞争对手的个数构造特征, 最终采用加权融合。
参考文献:
1 https://zhuanlan.zhihu.com/p/63718151
2 https://algo.qq.com/application/home/information/info.html
3 https://mp.weixin.qq.com/s/17uvqhbnxqxD786TRseEZQ
2019腾讯广告算法大赛 Rank23的更多相关文章
- 首届全球RTB(实时竞价)广告DSP算法大赛
首届全球RTB(实时竞价)广告DSP算法大赛 竞赛指南 RTB (Real Time Bidding, 实时竞价) 是近年来计算广告领域最激动人心的进展之一. 它增加了展示广告的透明度与效率, ...
- 2018科大讯飞AI营销算法大赛全面来袭,等你来战!
AI技术已成为推动营销迭代的重要驱动力.AI营销高速发展的同时,积累了海量的广告数据和用户数据.如何有效应用这些数据,是大数据技术落地营销领域的关键,也是检测智能营销平台竞争力的标准. 讯飞AI营销云 ...
- 智慧航空AI大赛-阿里云算法大赛总结 第一赛季总结
[以前的文章]最后一公里极速配送 - 阿里云算法大赛总结 总结一下新的教训 1.由于都是NP难题,获得最优解用常规的方法非常困难,对于不是算法科班出身的人来说,首先应该到网络上寻找一下论文,是否有一些 ...
- 易观OLAP算法大赛结果揭晓,开源组黑马放大招!
100+天激烈赛程,40+国内顶级技术豪门对决,历经研发内部测试.正式环境测试和易观数据正式环境跑benchmark三大阶段.10月28日,易观OLAP算法大赛优胜名单出炉! 40+技术门派比武 易观 ...
- 2019腾讯前端技术大会资源TWeb
扫码关注公众号 回复“TWeb”即可获取“2019腾讯前端技术大会”的PPT
- AMAP-TECH算法大赛开赛!基于车载视频图像的动态路况分析
阿里巴巴高德地图AMAP-TECH算法大赛于7月8日开启初赛,赛题为「基于车载视频图像的动态路况分析」,活动邀请了业界权威专家担任评委,优秀选手不仅可以瓜分丰厚的奖金,领取荣誉证书,还有机会进入高德地 ...
- 案例 | 腾讯广告 AMS 的容器化之路
作者 张煜,15年加入腾讯并从事腾讯广告维护工作.20年开始引导腾讯广告技术团队接入公司的TKEx-teg,从业务的日常痛点并结合腾讯云原生特性来完善腾讯广告自有的容器化解决方案 项目背景 腾讯广告承 ...
- 2017易观OLAP算法大赛
大赛简介 目前互联网领域有很多公司都在做APP领域的“用户行为分析”产品,与Web时代的行为分析相类似,其目的都是帮助公司的运营.产品等部门更好地优化自家产品,比如查看日活和月活,查看渠道来源 ...
- A公司 推荐算法大赛 总结
一.介绍 ♦通过用户前四个月(04.15~08.15)的用户行为预测用户第五个月(08.15~09.15)将会购买的品牌.用户共有四种行为(type)分别是:点击(0).购买(1).购物车(2).收藏 ...
随机推荐
- powerDesignner连接数据库
http://hi.baidu.com/huntererpang/item/e65e1c48aa0ab50a6dc2f090 选用microsoft odbc for oracle 数据源名称:我喜欢 ...
- MRP routing设置释疑
Jeffer9@gmail.com 工艺是指在不同工作中心执行的作业序列 作业的详细信息 Number of cycles 在该工作中心操作几个循环 Number of ...
- Solaris文件系统管理
不同的操作系统使用不同类型的文件系统 1.文件(管理)系统:是用来对文件和目录进行管理.控制的数据结构的总称. Windows当中的文件系统: ntfs ,fat32 ,fat64 Solaris 当 ...
- python去除停用词(结巴分词下)
python 去除停用词 结巴分词 import jieba #stopwords = {}.fromkeys([ line.rstrip() for line in open('stopword. ...
- 【Sprint3冲刺之前】项目可行性研究报告
TD校园手机助手软件可行性研究报告 1.引言 在信息化时代高速发展的今天,手机成了每个人的必备物品之一.随着科技的迅猛发展,人们已经不仅仅满足于用手机发短信,打电话,因此,android手机应运而生, ...
- 【每日Scrum】第一天(4.11) TD学生助手Sprint1计划会议成果
[每日Scrum]第一天 TD学生助手Sprint1计划会议成果 ——小组成员:刘铸辉 刘静 何晓楠 谢凤娇 胡宝月 王洪叶 初次尝试敏捷开发Scrum计划流程开发项目,有什么不对的地方还希望各位大 ...
- 为公司做crm资产管理
一.实现会议室预定 二.实现调查问卷 三.项目背景初始化分析 四.简单的登陆注册 五.学生管理 六.老师管理 七.销售管理 八.客户关系管理 九.抢单管理 十.微信发消息发邮件管理 补充:数据表设计. ...
- ruby on rails模拟HTTP请求错误发生:end of file reached
在文章 Ruby On Rails中REST API使用演示样例--基于云平台+云服务打造自己的在线翻译工具 中,利用ruby的Net::HTTP发起http请求訪问IBM Bluemix上的sour ...
- JS 模板引擎 Handlebars.js 中文说明
Handlebars 为你提供了一个可以毫无挫折感的高效率书写 语义化的模板 所必需的一切. Mustache 模板和 Handlebars 是兼容的,所以你可以把Mustache模板拿来导入到Han ...
- Sass编译css/Grunt压缩文件
Sass安装(mac) $ sudo gem install sass scss编译成css文件 $ sass ui.scss ui.css CLI安装 $ npm install -g grunt- ...