吴恩达机器学习笔记(十一) —— Large Scale Machine Learning
主要内容:
一.Batch gradient descent
二.Stochastic gradient descent
三.Mini-batch gradient descent
四.Online learning
五.Map-reduce and data parallelism
一.Batch gradient descent
batch gradient descent即在损失函数对θ求偏导时,用上了所有的训练集数据(假设有m个数据,且m不太大)。这种梯度下降方法也是我们之前一直使用的。
如线性回归的batch gradient descent:
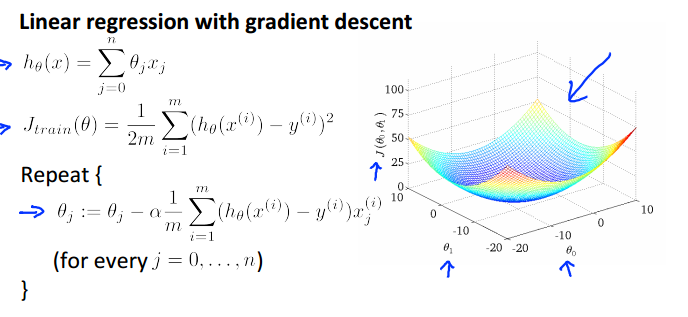
二.Stochastic gradient descent0
当数据集的规模m不太大时,利用batch gradient descent可以很好地解决问题;但是当m很大时,如 m = 100,000,000 时,如果在求偏导的时候,都利用上这100,000,000个数据,那么一次的迭代所耗的时间都是无法接受的。既然如此,就在求偏导的时候,只利用一个数据,但每一次迭代都利用上所有的数据。详情如下:
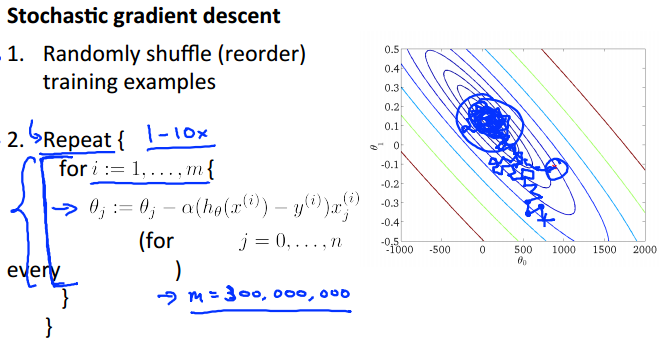
相当于把数据集抽到外面单独作为一层循环。
迭代效果:在迭代的过程中,由于求偏导时只用到了一个数据,所以很容易导致方向走偏。因而轨迹是迂回曲折的,且最终也不会收敛,而是在收敛点的附近一直徘徊。
那么,如何检测stochastic gradient descent的收敛情况?
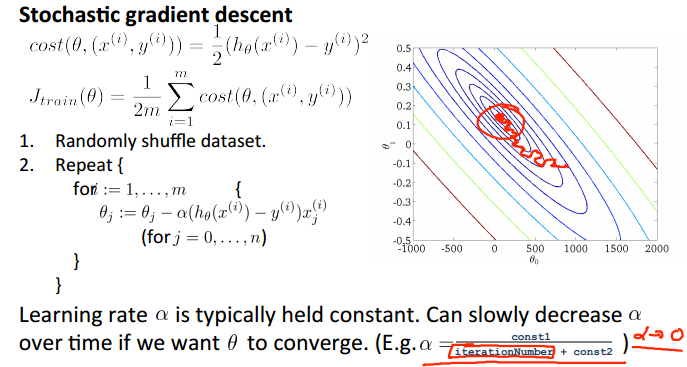
对于batch gradient descent,我么可以画出损失函数随每一次迭代的变化情况。而对于stochastic gradient descent,我们可以在经过若干次迭代之后(如1000次后),求出这若干次迭代的平均损失值,并画图进行观察收敛情况。

优化:可知stochastic gradient descent在靠近最优点的时候,依然“大踏步”地徘徊,为了更加接近最优点(提高精度),我们可以:在每一次迭代靠近最优点的时候,都降低其学习率,即步长。这样,在越靠近最优点的时候,走的步伐就越细了,自然能更加接近最优点:
三.Mini-batch gradient descent
在求损失函数对θ求偏导时,batch gradient descent用上了所有的数据,而stochastic gradient descent则只利用了一个数据。可知,这两种做法都属于极端情况:batch gradient descent的轨迹是“心无旁骛,一直往最优点靠近”,而stochastic gradient descent是“像醉汉一样跌跌撞撞地往最优点靠近,且最后一直徘徊于最优点附近”。为了平衡这两种情况,我们可以采取这种的方法:求偏导的时候,即不用上所有数据,也不只是用一个数据,而是用一个子集的数据(子集的大小为b,假设b为10)。具体如下:
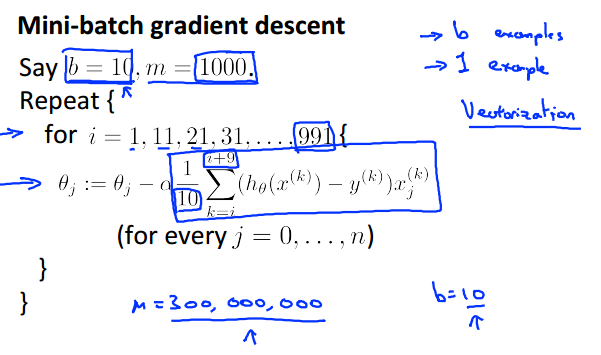
四.Online learning
很多时候,数据并不是一下子就能够收集完的,或者庞大的数据量只能慢慢地收集,如某一网站的一些链接的被点击次数等,都需要时间的积累。这时,就要用上在线学习了。
一下是两个在线学习的例子:


五.Map-reduce and data parallelism
当数据量很大时,我们可以将计算任务分配到多台计算机上(假如一台电脑有多个CPU,还可以是一台计算机上的多CPU分布式计算),然后再汇总计算结果,即所谓的分布式计算。
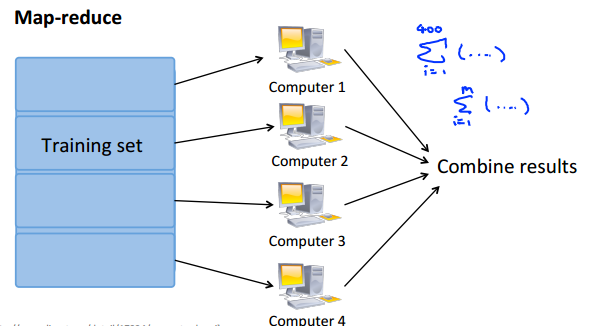
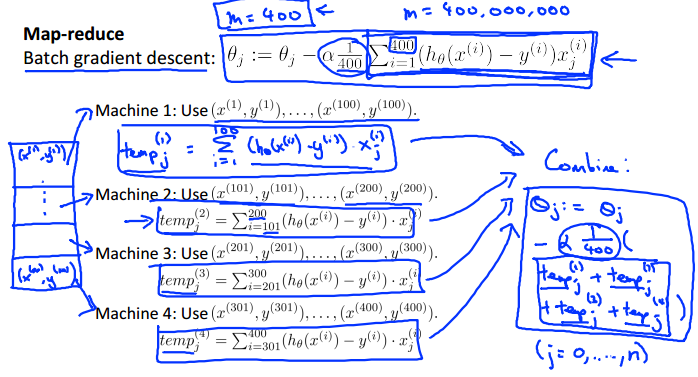
如可以将梯度下降求偏导的计算分布到赌台计算机上,然后汇总:
吴恩达机器学习笔记(十一) —— Large Scale Machine Learning的更多相关文章
- 吴恩达机器学习笔记37-学习曲线(Learning Curves)
学习曲线就是一种很好的工具,我经常使用学习曲线来判断某一个学习算法是否处于偏差.方差问题.学习曲线是学习算法的一个很好的合理检验(sanity check).学习曲线是将训练集误差和交叉验证集误差作为 ...
- Machine Learning|Andrew Ng|Coursera 吴恩达机器学习笔记
Week1: Machine Learning: A computer program is said to learn from experience E with respect to some ...
- Machine Learning|Andrew Ng|Coursera 吴恩达机器学习笔记(完结)
Week 1: Machine Learning: A computer program is said to learn from experience E with respect to some ...
- Machine Learning——吴恩达机器学习笔记(酷
[1] ML Introduction a. supervised learning & unsupervised learning 监督学习:从给定的训练数据集中学习出一个函数(模型参数), ...
- 吴恩达机器学习笔记(六) —— 支持向量机SVM
主要内容: 一.损失函数 二.决策边界 三.Kernel 四.使用SVM (有关SVM数学解释:机器学习笔记(八)震惊!支持向量机(SVM)居然是这种机) 一.损失函数 二.决策边界 对于: 当C非常 ...
- 吴恩达机器学习笔记60-大规模机器学习(Large Scale Machine Learning)
一.随机梯度下降算法 之前了解的梯度下降是指批量梯度下降:如果我们一定需要一个大规模的训练集,我们可以尝试使用随机梯度下降法(SGD)来代替批量梯度下降法. 在随机梯度下降法中,我们定义代价函数为一个 ...
- 吴恩达机器学习笔记43-SVM大边界分类背后的数学(Mathematics Behind Large Margin Classification of SVM)
假设我有两个向量,
- 吴恩达机器学习笔记42-大边界的直观理解(Large Margin Intuition)
这是我的支持向量机模型的代价函数,在左边这里我画出了关于
- [吴恩达机器学习笔记]12支持向量机3SVM大间距分类的数学解释
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.3 大间距分类背后的数学原理- Mathematic ...
随机推荐
- 关于Web项目的pom文件处理
pom文件的方式需要修改的是 <packaging>war</packaging> <profiles> <profile> <id>com ...
- x86 Android游戏开发专题篇之使用google breakpad捕捉c++崩溃(以cocos2dx为例)
近期一直都在x86设备上进行游戏开发.就c++层和Android java层倒没有什么要特别注意的(除了须要注意一下改动Application.mk指定平台外),在c++崩溃的时候,非常多时候看不到堆 ...
- 谈 API 的撰写 - 总览
背景 之前团队主要的工作就是做一套 REST API.我接手这个工作时发现那些API写的比较业余,没有考虑几个基础的HTTP/1.1 RFC(2616,7232,5988等等)的实现,于是我花了些时间 ...
- ionic 调试 "死亡白屏"
死亡白屏(White Screen of Death) 我想“死亡白屏”应该是不需要解释的,开发过ionic app的童鞋应该都有遇到过,这里解释以防读者没有听说过:“可能在浏览器中调试时一切正常,当 ...
- iOS的URLScheme
一直都有接触要设置app的url scheme,从最早的facebook開始. 当时的理解是SSO用的,当授权成功之后,facebook app或者safari能够利用给定的url scheme来回调 ...
- base64编码-----------》struts2(token)利用BigInteger产生随机数
//struts2 源码 public static final Random RANDOM= new Random(); public static String generateGUID(){ r ...
- Java中使用com.sun相关jar包出现编译错误,但是运行没有错误的解决方法和原因
[解决方法]如果你用的是Eclipse 在preference->java->complier->errors/warning->deprecated and restrict ...
- 非常酷的word技巧---删除行前的空格
今天整理一篇文章的时间遇见一个问题,非常多行前的空格严重影响美观.搞计算机的就是爱折腾.于是做了各种尝试完美解决,以下把方法发布例如以下,事实上非常easy哦! 问题例如以下情况所看到的: 解决的方法 ...
- SAS学习经验总结分享:篇一—数据的读取
第一篇:BASE SAS分为数据步的作用及生成数据集的方式 我是学经济相关专业毕业的,从事数据分析工作近一年,之前一直在用EXCEL,自认为EXCEL掌握的还不错. 今年5月份听说了SAS,便开始学习 ...
- VueJS样式绑定之内联样式v-bind:style
我们可以在 v-bind:style 直接设置样式: 直接添加样式属性 HTML <!DOCTYPE html> <html> <head> <meta ch ...