关于Flask使用Celery的实践经验分享
最近大Boss反馈Celery经常出现问题,几经实践终于把问题解决了!于是乎有了这篇博客的诞生,算是一个实践经验的分享吧!
软件版本如下:
Celery (4.1.)
Flask (0.12.)
RabbitMQ(3.6.)
librabbitmq (1.6.)
介绍
简单来说Celery是一个异步的任务队列,当我们需要将一些任务(比如一些需要长时间操作的任务)异步操作的时候,这时候Celery就可以帮到我们,另外Celery还支持定时任务(类似Crontab)。详细的介绍可以参考官网
使用RabbitMQ作为Broker
RabbitMQ是官方推荐使用的Broker,它实际是一个消息中间件,负责消息的路由分发,安装RabbitMQ如下:
# install on Ubuntu
apt-get update
apt-get install rabbitmq-server -yq
需要注意的是,线上环境我们需要创建新的账号,并将guest账号删除,操作如下:
rabbitmqctl add_user myuser mypassword # 新增用户
rabbitmqctl add_vhost myvhost # 新增vhost,以使用不同的命名空间
rabbitmqctl set_permissions -p myvhost myuser ".*" ".*" ".*" # 设置权限
rabbitmqctl delete_user guest # 安全原因,删除guest
注意:vhost是一个虚拟空间,用于区分不同类型的消息
然后,在Celery的配置中配置broker URL:
CELERY_BROKER_URL = 'amqp://myuser:mypassword@localhost:5672/myvhost'
注意:当使用amqp协议头时,如果安装有librabbitmq则使用librabbitmq,否则使用pyamqp
Celery的日志输出
在task中想要输出日志,最好的方法是通过如下方式:
from celery.utils.log import get_task_logger lg = get_task_logger(__name__) @celery.task
def log_test():
lg.debug("in log_test()")
但是仅如此会发现所有的日志最后都跑到shell窗口的stdout当中,原来必须得在启动celery的时候使用-f option来指定输出文件,如下:
celery -A main.celery worker -l debug -f log/celery/celery_task.log &
-A:指定celery实例
worker: 启动worker进程
-l:指定log level,这里指定log level为debug level
-f:指定输出的日志文件
使用Redis作为backend
当使用Redis作为存储后端的时候,我们可以通过设置DB number来使得Celery的结果存储与其它数据存储隔离开来,比如在笔者的项目中,redis还用作缓存的存储后端,因此为了区分,Celery在使用Redis的时候使用的DB number是1(默认是0),关于Redis DB number可以参考这里.
因此我们的backend设置如下:
CELERY_RESULT_BACKEND = 'redis://localhost:6379/1' # 最后的数字1代表DB number
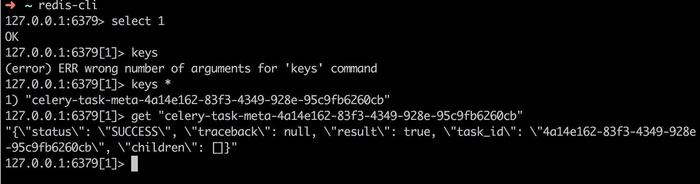
查看Celery任务的结果可以通过Redis-cli连接Redis数据库进行查看:
> redis-cli
> select # 这里选择DB , 也可以在使用redis-cli -n 1来进入指定的DB
> get key # 获取指定key对应的结果
Celery可能会遇到的坑
Celery4.x版本使用librabbitmq的问题
Celery 4.x版本在使用librabbitmq时,会出现类似这样的错误
Received and deleted unknown message. Wrong destination?!?
解决这个问题有两个方式:
- 推荐方式,更改配置项task_protocol为1。
Github上Robert Kopaczewski详细解释了这个问题,原文如下:
Apparently librabbitmq issue is related to new default protocol in celery .x. You can switch to previous protocol version by either
putting CELERY_TASK_PROTOCOL = in your settings if you're using Django or settings app.conf.task_protocol = 1 in celeryconf.py.
- 另一种方式是不使用librabbitmq, 通过pip uninstall librabbitmq, 并且更改broker配置的协议头为'pyamqp',如下,也可以解决这个问题。
BROKER_URL = 'pyamqp://guest:guest@localhost:5672/%2F'
由于librabbitmq的性能优势,我们还是推荐方式1来解决该问题。
RabbitMQ远程连接问题
如果RabbitMQ与Celery不在同一台机器上,除在Celery配置的时候要将BROKER_URL设置为正确的IP地址外,还需要将Rabbitmq的配置文件/usr/local/etc/rabbitmq/rabbitmq-env.conf中的NODE_IP_ADDRESS更改为0.0.0.0
NODE_IP_ADDRESS=0.0.0.0
Celery import问题
The message has been ignored and discarded. Did you remember to import the module containing this task?
Or maybe you're using relative imports? Please see
http://docs.celeryq.org/en/latest/internals/protocol.html
for more information. The full contents of the message body was:
'\x8e\xa7expires\xc0\xa3utc\xc3\xa4args\x91\x85\xa3tid\xb85971a43d47f84bb278f77fc2\xa3sen\xa2A1\xa2tt\xa2ar\xa2co\xc4\x00\xa1t\xa4like\xa5chord\xc0\xa9callbacks\xc0\xa8errbacks\xc0\xa7taskset\xc0\xa2id\xc4$c133dbf8-2c89-4311-b7cf-c377041058ec\xa7retries\x00\xa4task\xd9$tasks.messageTasks.send_like_message\xa5group\xc0\xa9timelimit\x92\xc0\xc0\xa3eta\xc0\xa6kwargs\x80' (239b)
Traceback (most recent call last):
File "/Users/liufeng/.pyenv/versions/2.7.13/envs/kaopu_backend/lib/python2.7/site-packages/celery/worker/consumer/consumer.py", line , in on_task_received
strategy = strategies[type_]
KeyError: u'tasks.messageTasks.send_like_message'
出现这条错误是由于我们的tasks跟celery并不是在同一个文件中,即不是同一个module,当我们通过如下命令启动task worker时,实际只加载了app module,而没有加载tasks相关的module
celery -A app.celery worker -l info
要解决这个问题,必须为celery配置文件添加import参数,如下
app.config['imports'] = ['tasks.messageTasks']Celery unregistered task问题
在开发过程中遇到了这样一个问题:
[-- ::,: ERROR/MainProcess] Received unregistered task of type u'app.tasks.messageTasks.send_follow_message'.
The message has been ignored and discarded. Did you remember to import the module containing this task?
Or maybe you're using relative imports? Please see
http://docs.celeryq.org/en/latest/internals/protocol.html
for more information. The full contents of the message body was:
'\x8e\xa7expires\xc0\xa3utc\xc3\xa4args\x91\x86\xa6sender\xa5Jenny\xa9target_id\xb859a5313847f84be534ad7d46\xabtarget_type\xa4user\xa7content\xc4\x00\xa8receiver\xb859a5313847f84be534ad7d46\xa4type\xa6follow\xa5chord\xc0\xa9callbacks\xc0\xa8errbacks\xc0\xa7taskset\xc0\xa2id\xc4$a4d40c14-1976-41a6-a753-d2a495929920\xa7retries\x00\xa4task\xd9*app.tasks.messageTasks.send_follow_message\xa5group\xc0\xa9timelimit\x92\xc0\xc0\xa3eta\xc0\xa6kwargs\x80' (312b)
Traceback (most recent call last):
File "/Users/liufeng/.pyenv/versions/2.7.13/envs/kaopu_backend/lib/python2.7/site-packages/celery/worker/consumer/consumer.py", line , in on_task_received
strategy = strategies[type_]
KeyError: u'app.tasks.messageTasks.send_follow_message'
解决这个问题,最开始是根据提示,将所有涉及到task的module全部加上from __future__ import absolute_import 之后运行之后还是不行,后来发现是由于之前启动时使用的是app module, 但是我的代码已经改成了main.py,所以重新启动了celery,最后问题解决
使用镜像迁移系统也依然需要重新添加rabbitmq的用户
问题最开始是发现无法点赞,也无法Follow用户,通过http消息发现出现502错误,于是登录到服务器检查,发现应用服务本身没有任何报错,于是又去查看Celery的日志,结果发现出现如下错误:
[-- ::,: ERROR/MainProcess] consumer: Cannot connect to amqp://celeryuser:**@loc alhost:5672/celeryvhost: Couldn't log in: a socket error occurred.
经过一番搜索发现网上的评论主要是说URL不对的情况下会出现这种情况,但是我的URL没有改过啊,那又会是什么问题呢?继续看,发现有人提到了权限问题,于是又是一番检查,发现RabbitMQ中并没有原先设置的用户(我使用的是原系统的镜像,原以为用户也是已经设置好的)
# 查看有哪些用户
rabbitmqctl list_users
然后就简单了,按照步骤创建用户,vhost,再赋予权限,删除guest,然后就终于都连好了
另外,发现从镜像复制系统后,RabbitMQ并不能正常工作,必须杀掉原先的进程,重新启动
更改task的代码后,重启Celery
需要注意的是,在更改task的代码后,必须重新启动Celery,否则代码改动无法生效,可能导致一些意外的问题
以上就是笔者使用过程中的一些坑,经验有限,如果有错漏还请指正!不要看格式啦,因为之间都是习惯写印象笔记,所以你们就将就着看吧!
关于Flask使用Celery的实践经验分享的更多相关文章
- 领域驱动设计(DDD)的实践经验分享之ORM的思考
原文:领域驱动设计(DDD)的实践经验分享之ORM的思考 最近一直对DDD(Domain Driven Design)很感兴趣,于是去网上找了一些文章来看看,发现它确实是个好东西.于是我去买了两本关于 ...
- 领域驱动设计(DDD)的实践经验分享之持久化透明
原文:领域驱动设计(DDD)的实践经验分享之持久化透明 前一篇文章中,我谈到了领域驱动设计中,关于ORM工具该如何使用的问题.谈了很多我心里的想法,大家也对我的观点做了一些回复,或多或少让我深深感觉到 ...
- 我的devops实践经验分享一二
前言 随着系统越来越大,开发人员.站点.服务器越来越多,微服务化推进,......等等原因,实现自动化的devops越来越有必要. 当然,真实的原因是,在团队组建之初就预见到了这些问题,所以从一开始就 ...
- CI Weekly #6 | 再谈 Docker / CI / CD 实践经验
CI Weekly 围绕『 软件工程效率提升』 进行一系列技术内容分享,包括国内外持续集成.持续交付,持续部署.自动化测试. DevOps 等实践教程.工具与资源,以及一些工程师文化相关的程序员 Ti ...
- Celery的实践指南
http://www.cnblogs.com/ToDoToTry/p/5453149.html Celery的实践指南 Celery的实践指南 celery原理: celery实际上是实现了一个典 ...
- Expression Blend4经验分享:自适应布局浅析
今天分享一下Blend制作自适应分辨率布局的经验,大家先看下效果图: 这是一个标准的三分天下的布局,两侧的红色区域是背景区域,是用来干吗的呢,下面简单的分析一下,大家就明白了. 1.拿到一个项目,进行 ...
- celery最佳实践
作为一个Celery使用重度用户.看到Celery Best Practices这篇文章.不由得菊花一紧. 干脆翻译出来,同一时候也会添加我们项目中celery的实战经验. 至于Celery为何物,看 ...
- 安装程序添加iis的方法经验分享
原文:安装程序添加iis的方法经验分享 网上有一些这样的方法,但我这里主要做一些对比和扩充 网上这方面的文章的岁数比较大,server 08R2和win7出来后,整理这方面的资料的文章没找到,所以这里 ...
- 以技术面试官的经验分享毕业生和初级程序员通过面试的技巧(Java后端方向)
本来想分享毕业生和初级程序员如何进大公司的经验,但后来一想,人各有志,有程序员或许想进成长型或创业型公司或其它类型的公司,所以就干脆来分享些提升技能和通过面试的技巧,技巧我讲,公司你选,两厢便利. 毕 ...
随机推荐
- phthon 基础 7.3 logging 日志模块
一. logging 的使用 日志是我们排查问题的关键利器,写好日志记录,当我们发生问题时,可以快速定位代码范围进行修改.python有给我们开发者提供好的日志模块,下面我们就来介绍一下logging ...
- python 基础 5.2 类的继承
一. 类的继承 继承,顾名思议就知道是它的意思,举个例子说明,你现在有一个现有的A类,现在需要写一个B类,但是B类是A类的特殊版,我们就可以使用继承,B类继承A类时,B类会自动获得A类的所有属性和方法 ...
- 1930: [Shoi2003]pacman 吃豆豆
1930: [Shoi2003]pacman 吃豆豆 Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 1969 Solved: 461[Submit][ ...
- C#根据Type获取默认值
简单的获取某变量类型的默认值 在c#中为我们提供了default(),但是default的参数是具体的类名, 如何根据变量类型的Type获取默认值Code如下: 1 public static obj ...
- 获取系统 SID
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/hadstj/article/details/26399533 获取系统 SID ((gwmi win ...
- Pentaho BIServer Community Edtion 6.1 使用教程 第三篇 发布和调度Kettle(Data Integration) 脚本 Job & Trans
Pentaho BIServer Community Edtion 6.1 集成了 Kettle 组件,可以运行Kettle 程序脚本.但由于Kettle没有直接发布到 BIServer-ce 服务的 ...
- LeetCode:用最少的箭引爆气球【452】
LeetCode:用最少的箭引爆气球[452] 题目描述 在二维空间中有许多球形的气球.对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标.由于它是水平的,所以y坐标并不重要,因此只要知道 ...
- Android Weekly Notes Issue #257
Android Weekly Issue #257 May 14th, 2017 Android Weekly Issue #257 本期内容包括: Gradle中关于项目的一些设置; Android ...
- BZOJ1833 数位DP
数位DP随便搞搞. #include<iostream> #include<cstdio> #include<cstdlib> #include<cstrin ...
- 《avascript 高级程序设计(第三版)》 ---第一章 Javascript简介
这一章主要是介绍了 Javascript的一些历史: 1.Javascript主要由三个部分组成:ECMAScript,DOM,BOM. ECMAScript:现在主流浏览器已经全部支持. DOM:把 ...