hadoop核心组件概述及hadoop集群的搭建
什么是hadoop?
Hadoop 是 Apache 旗下的一个用 java 语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
hadoop提供的功能:利用服务器集群,根据用户的自定义业务逻辑,对海量数据进行分布式处理。
狭义上来说hadoop 指 Apache 这款开源框架,它的核心组件有:
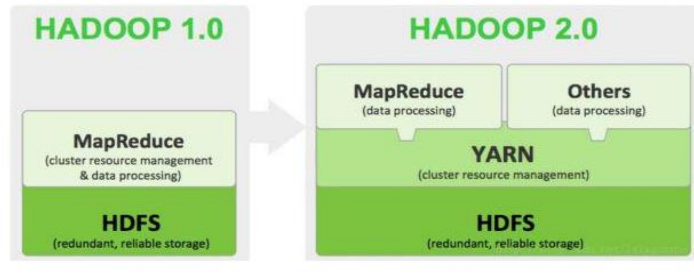
- hdfs(分布式文件系统)(负责文件读写)
- yarn(运算资源调度系统)(负责为MapReduce程序分配运算硬件资源)
- MapReduce(分布式运算编程框架)
扩展:
关于hdfs集群: hdfs集群有一个name node(名称节点),类似zookeeper的leader(领导者),namenode记录了用户上传的一些文件分别在哪些DataNode上,记录了文件的源信息(就是记录了文件的名称和实际对应的物理地址),name node有一个公共端口默认是9000,这个端口是针对客户端访问的时候的,其他的小弟(跟随者)叫data node,namenode和datanode会通过rpc进行远程通讯。
Yarn集群: yarn集群里的小弟叫做node manager,MapReduce程序发给node manager来启动,MapReduce读数据的时候去找hdfs(datanode)去读。(注:hdfs集群和yarn集群最好放在同一台机器里),yarn集群的老大主节点resource manager负责资源调度,应(最好)单独放在一台机器。
广义上来说,hadoop通常指更广泛的概念--------hadoop生态圈 。
当下的 Hadoop 已经成长为一个庞大的体系,随着生态系统的成长,新出现的项目越来越多,其中不乏一些非 Apache 主管的项目,这些项目对 HADOOP 是很好的补充或者更高层的抽象。比如:
HDFS:分布式文件系统
MAPREDUCE:分布式运算程序开发框架
HIVE:基于 HADOOP 的分布式数据仓库,提供基于 SQL 的查询数据操作
HBASE:基于 HADOOP 的分布式海量数据库
ZOOKEEPER:分布式协调服务基础组件
Mahout:基于 mapreduce/spark/flink 等分布式运算框架的机器学习算法库
Oozie:工作流调度框架
Sqoop:数据导入导出工具(比如用于 mysql 和 HDFS 之间)
Flume:日志数据采集框架
Impala:基于 Hadoop 的实时分析
hadoop特性的优点:
扩容能力(Scalable):Hadoop 是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
成本低(Economical):Hadoop 通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
高效率(Efficient):通过并发数据,Hadoop 可以在节点之间动态并行的移动数据,使得速度非常快。
可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以 Hadoop 的按位存储和处理数据的能力值得人们信赖。
hadoop集群搭建准备工作:Linux下编译hadoop
由于从Apache官方下载的hadoop 2.X.X的编译版本(binary)为32位,小概率不能适应我们的操作系统。另外,在企业中需要对hadoop源码进行修改,所以需要自己处理hadoop源文件后再进行编译。本文以Centos-6.7为例,演示编译hadoop-2.9.0。
1、hadoop-2.9.0源文件对环境的要求
Requirements:
- Unix System
- JDK 1.8+
- Maven 3.0 or later
- Findbugs 1.3.9 (if running findbugs)
- ProtocolBuffer 2.5.0
- CMake 2.6 or newer (if compiling native code), must be 3.0 or newer on Mac
- Zlib devel (if compiling native code)
- openssl devel (if compiling native hadoop-pipes and to get the best HDFS encryption performance)
- Linux FUSE (Filesystem in Userspace) version 2.6 or above (if compiling fuse_dfs)
- Internet connection for first build (to fetch all Maven and Hadoop dependencies)
- python (for releasedocs)
- bats (for shell code testing)
- Node.js / bower / Ember-cli (for YARN UI v2 building)
2、准备的资料
- 64位linux系统CentOS 6.7。
- JDK 1.8。
- maven-3.2.5。 一个项目管理综合工具, 使用标准的目录结构和默认构建生命周期
- protobuf 2.5.0 google的一种数据交换的格式,它独立于语言,独立于平台
- hadoop-2.9.0-src
- ant-1.9.7将软件编译、测试、部署等步骤联系在一起加以自动化的一个工具
3、安装环境
创建三个文件夹
#servers为软件安装路径
mkdir -p /export/servers
#software为软件压缩包存放路径
mkdir -p /export/software
#data为软件运行产生数据的存放路径
mkdir -p /export/hadoopdata
将压缩包全部上传至/export/software
yum install lrzsz
cd /export/software
rz
3.1、安装JDK
cd /export/software
tar -zxvf jdk-8u111.tar.gz -C /export/servers
cd /export/servers/
mv jdk-jdk-8u111 jdk1.8
vi /etc/profile
#键盘输入G调到文件末尾,i插入
export JAVA_HOME=/export/servers/jdk
export PATH=.:$PATH:$JAVA_HOME/bin
#ESC退出,shift+:,wq!保存
source /etc/profile
命令行敲入java -version出现如下代码表示成功
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) -Bit Server VM (build 25.111-b14, mixed mode)
[root@node0 software]#
3.2、安装maven
cd /export/software
tar -zxvf apache-maven-3.3.-bin.tar.gz -C /export/servers
cd /export/servers/
mv apache-maven-3.3. maven
vi /etc/profile
#键盘输入G调到文件末尾,i插入
export MAVEN_HOME=/export/servers/maven
export PATH=.:$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin
#ESC退出,shift+:,wq!保存
source /etc/profile
命令行敲入mvn -version出现如下代码表示成功
Apache Maven 3.3. (bb52d8502b132ec0a5a3f4c09453c07478323dc5; --11T00::+:)
Maven home: /export/servers/maven
Java version: 1.8.0_111, vendor: Oracle Corporation
Java home: /export/servers/jdk/jre
Default locale: en_US, platform encoding: UTF-
OS name: "linux", version: "2.6.32-573.el6.x86_64", arch: "amd64", family: "unix"
3.3、安装protobuf
使用yum安装需要的C和C++编译环境
yum install gcc
yum install gcc-c++
yum install make
安装protobuf
cd /export/software
tar -zxvf protobuf-2.5..tar.gz -C /export/servers
cd /export/servers/
mv protobuf-2.5. protobuf
cd /protobuf
./configure
make
make install
输入protoc --version,如果出现如下信息表示安装成功
libprotoc 2.5.
3.4、安装CMake
使用yum安装
yum install cmake
yum install openssl-devel
yum install ncurses-devel
3.5、安装ant
cd /export/software
tar -zxvf apache-ant-1.9.-bin.tar.gz -C /export/servers
cd /export/servers/
mv apache-ant-1.9. ant
vi /etc/profile
export ANT_HOME=/export/servers/ant
export PATH=.:$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$ANT_HOME/bin
source /etc/profile
输入ant -version,如果出现如下信息表示安装成功
Apache Ant(TM) version 1.9. compiled on April
3.6、编译hadoop
cd /export/software
tar -zxvf hadoop-2.9.-src.tar.gz -C /export/servers
cd /export/servers/hadoop-2.9.-src
hadoop-2.9.0-src目录
输入如下命令进行编译hadoop-2.9.0
mvn package -Pdist,native -DskipTests -Dtar
或者
mvn package -DskipTests -Pdist,native
经过漫长的等待,显示如下信息,编译完成

进入hadoop-dist查看编译好的hadoop-2.9.0
注:maven仓库用的是国外的镜像,小概率会出现抽风,修改为aliyun镜像
vi /export/servers/maven/conf/setting.xml
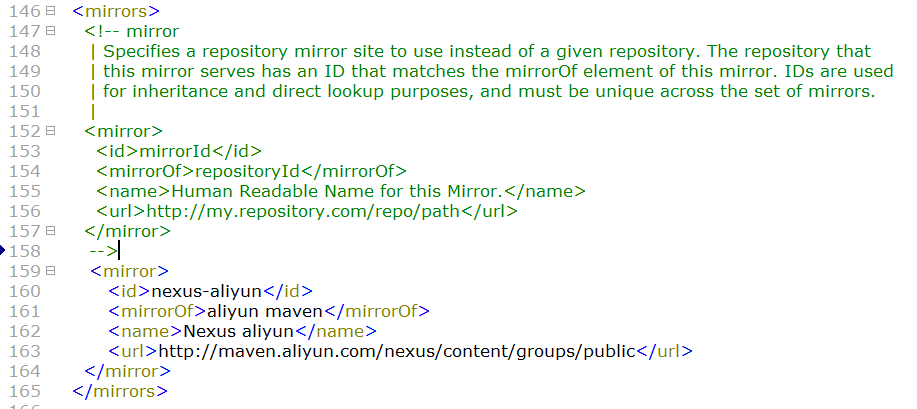
maven编译hadoop过程中可能会出现[ERROR]TEST...,这个是源码中间存在某些test文件,而maven仓库找不到相应的包。
解决:1、使用国外的maven仓库。2、修改源码,将test包下的文件删除,同时删除响应pom.xml中的依赖
终于终于完成了hadoop 的编译!接下来我们继续!
通常我们所说的hadoop集群包含 2个集群:HDFS 集群和 YARN 集群,两者逻辑上分离,但物理上常在一起。
HDFS 集群负责海量数据的存储,集群中的角色主要有:NameNode、DataNode、SecondaryNameNode
YARN 集群负责海量数据运算时的资源调度,集群中的角色主要有:ResourceManager、NodeManager
那 mapreduce 是什么呢?它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在 HDFS 集群上,并且受到 YARN 集群的资源调度管理。
Hadoop 部署方式分三种,Standalone mode (独立模式)、Pseudo-Distributedmode(伪分布式模式)、Cluster mode(群集模式),其中前两种都是在单机部署。
独立模式又称为单机模式,仅 1 个机器运行 1 个 java 进程,主要用于调试。
伪分布模式也是在 1 个机器上运行 HDFS 的 NameNode 和 DataNode、YARN 的ResourceManger 和 NodeManager,但分别启动单独的 java 进程,主要用于调试。
集群模式主要用于生产环境部署。会使用 N 台主机组成一个 Hadoop 集群。这种部署模式下,主节点和从节点会分开部署在不同的机器上。
这里我们以 3 节点为例进行搭建,角色分配如下:
mini4 NameNode DataNode ResourceManager
mini5 DataNode NodeManager SecondaryNameNode
mini6 DataNode NodeManager
分别启动mini4、mini5、mini6,同步集群各机器的时间:
#手动同步集群各机器时间
date -s "2017-03-03 03:03:03"
yum install ntpdate
#网络同步时间
ntpdate cn.pool.ntp.org
配置 IP 、主机名 映射
vi /etc/hosts
192.168.75.14 mini4
192.168.75.15 mini5
192.168.75.16 mini6
配置 ssh免密登录
#生成 ssh 免登陆密钥
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成 id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登陆的目标机器上
ssh-copy-id mini4
ssh-copy-id mini5
ssh-copy-id mini6
关闭防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
hadoop 安装 包目录结构说明:
bin:Hadoop 最基本的管理脚本和使用脚本的目录,这些脚本是 sbin 目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用 Hadoop。
etc:Hadoop 配置文件所在的目录,包括 core-site,xml、hdfs-site.xml、mapred-site.xml 等从 Hadoop1.0 继承而来的配置文件和 yarn-site.xml 等Hadoop2.0 新增的配置文件。
include:对外提供的编程库头文件(具体动态库和静态库在 lib 目录中),这些头文件均是用 C++定义的,通常用于 C++程序访问 HDFS 或者编写 MapReduce程序。
lib:该目录包含了 Hadoop 对外提供的编程动态库和静态库,与 include 目录中的头文件结合使用。
libexec:各个服务对用的 shell 配置文件所在的目录,可用于配置日志输出、启动参数(比如 JVM 参数)等基本信息。
sbin:Hadoop 管理脚本所在的目录,主要包含 HDFS 和 YARN 中各类服务的启动/关闭脚本。
share:Hadoop 各个模块编译后的 jar 包所在的目录。
hadoop配置文件修改
Hadoop 安装主要就是配置文件的修改,一般在主节点进行修改,完毕后 scp下发给其他各个从节点机器。
第一个:hadoop-env.sh
文件中设置的是 Hadoop 运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了 JAVA_HOME,它也是不认识的,因为 Hadoop 即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
vi hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8

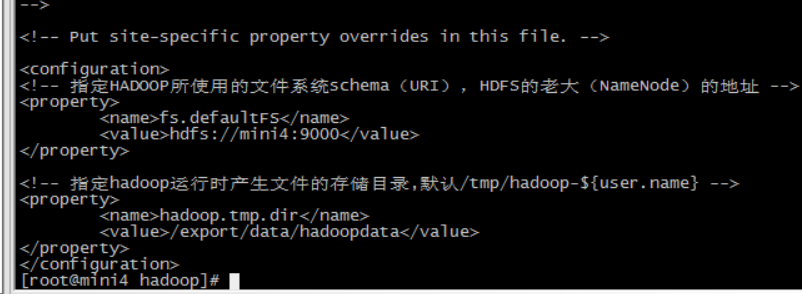
第二个:core-site.xml
hadoop 的核心配置文件,有默认的配置项 core-default.xml。core-default.xml 与 core-site.xml 的功能是一样的,如果在 core-site.xml 里没有配置的属性,则会自动会获取 core-default.xml 里的相同属性的值。
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mini4:9000</value>
</property> <!-- 指定hadoop运行时产生文件的存储目录,默认/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoopdata</value>
</property>
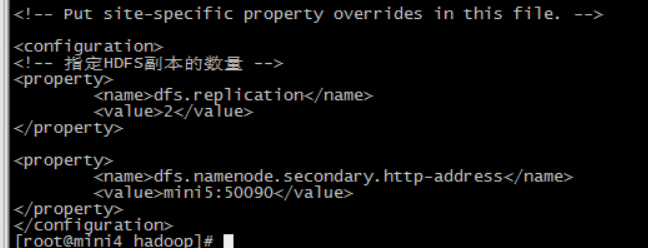
第三个:hdfs-site.xml
HDFS 的核心配置文件,有默认的配置项 hdfs-default.xml。hdfs-default.xml 与 hdfs-site.xml 的功能是一样的,如果在 hdfs-site.xml 里没有配置的属性,则会自动会获取 hdfs-default.xml 里的相同属性的值。
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value></value>
</property> <property>
<name>dfs.namenode.secondary.http-address</name>
<value>mini5:</value>
</property>
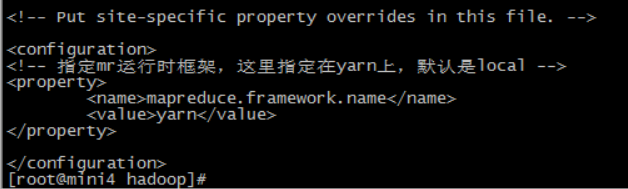
第四个:mapred-site.xml
MapReduce 的核心配置文件,有默认的配置项 mapred-default.xml。mapred-default.xml 与 mapred-site.xml 的功能是一样的,如果在 mapred-site.xml 里没有配置的属性,则会自动会获取 mapred-default.xml 里的相同属性的值。
<!-- 指定mr运行时框架,这里指定在yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
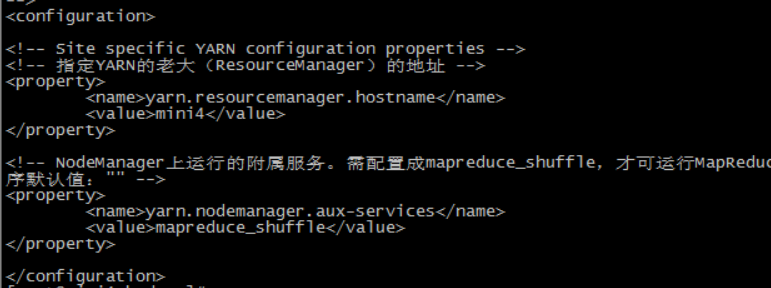
第五个:yarn-site.xml
YARN 的核心配置文件,有默认的配置项 yarn-default.xml。yarn-default.xml 与 yarn-site.xml 的功能是一样的,如果在 yarn-site.xml 里没有配置的属性,则会自动会获取 yarn-default.xml 里的相同属性的值。
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>mini4</value>
</property> <!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:"" -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
第六个:slaves文件,里面写上从节点所在的主机名字
vi slaves
mini4
mini5
mini6
将hadoop添加到环境变量
vi /etc/proflie
export JAVA_HOME=/export/servers/jdk1.
export HADOOP_HOME=/export/servers/hadoop-2.7.
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile
格式化namenode(本质是对namenode进行初始化)
hdfs namenode -format (hadoop namenode -format)
启动hadoop
先启动HDFS
sbin/start-dfs.sh
再启动YARN
sbin/start-yarn.sh
验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode (secondarynamenode)
28066 NodeManager
27803 ResourceManager
27512 DataNode
http://192.168.75.14:50070 (HDFS管理界面)
http://192.168.75.14:8088 (MR管理界面)
hadoop核心组件概述及hadoop集群的搭建的更多相关文章
- (六)hadoop系列之__hadoop分布式集群环境搭建
配置hadoop(master,slave1,slave2) 说明: NameNode: master DataNode: slave1,slave2 ------------------------ ...
- Spark 1.6.1分布式集群环境搭建
一.软件准备 scala-2.11.8.tgz spark-1.6.1-bin-hadoop2.6.tgz 二.Scala 安装 1.master 机器 (1)下载 scala-2.11.8.tgz, ...
- Hadoop |集群的搭建
Hadoop组成 HDFS(Hadoop Distributed File System)架构概述 NameNode目录--主刀医生(nn): DataNode(dn)数据: Secondary N ...
- zookeeper集群的搭建以及hadoop ha的相关配置
1.环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 master作为active主机,data1作为standby备用机,三台机器均作为数据节点,yarn资源 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- 在Hadoop集群上,搭建HBase集群
(1)下载Hbase包,并解压:这里下载的是0.98.4版本,对应的hadoop-1.2.1集群 (2)覆盖相关的包:在这个版本里,Hbase刚好和Hadoop集群完美配合,不需要进行覆盖. 不过这里 ...
随机推荐
- The bytes/str dichotomy in Python 3 [transport]
reference and transporting from: http://eli.thegreenplace.net/2012/01/30/the-bytesstr-dichotomy-in-p ...
- DM设备的创建与管理
DM(Device Mapper)即设备映射(逻辑设备). MD和DM是Linux内核上2种工作机制(实现逻辑设备)不同的模块. Physical Volume(PV): 物理卷 底层 ...
- hibernate log4j2输出sql带参数
网上有很多是输出sql ,参数以?的形式,后面输出参数binding的log,还要自己拼接特别麻烦:这里整理下输出原生sql的方法.组件是log4jdbc 1: 修改pom.xml,确定有下面的配置, ...
- Javascript 执行上下文 context&scope
执行上下文(Execution context) 执行上下文可以认为是 代码的执行环境. 1 当代码被载入的时候,js解释器 创建一个 全局的执行上下文. 2 当执行函数时,会创建一个 函数的执行上下 ...
- Linux软件相关记录
Pidgin+lw-web的聊天记录的文件对应的目录为.purple/logs/webqq/你的QQ号码/,进入之后有选择的删除. mkdir -p 递归创建目录:pwd 显示当前目录:cd .. 回 ...
- Linux下安装JDK及相关配置
1.官网下载JDK:选择Linux压缩包进行下载 https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-213 ...
- 从零开始的全栈工程师——js篇2.2
条件语句 补充: var a=“hello world” a这个变量是字符串了 对于里面每一个字母来说 他是字节 里面有11个字节 字节总数用length表示 如下: 根据上面的内容咱们又发现了一个运 ...
- 关闭VAX的拼写检查_解决中文红色警告问题
菜单VAssistX->Visual Assistant X Options->Advanced->Underlines下 取消“Underline spelling errors ...
- LeetCode Reverse Words in a String 将串中的字翻转
class Solution { public: void reverseWords(string &s) { string end="",tem="" ...
- linux 命令——39 grep (转)
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来.grep全称是Global Regular Expression Print,表示全局正则表达 ...