Day6 Python常用的模块
一、logging模块
一、日志级别
critical=50
error=40
waring=30
info=20
debug=10
notset=0
二、默认的日志级别是waring(30),默认的输出目标是终端
logging输出的目标有两种:1、终端;2、文件
高于warning的日志级别才会打印
import logging
logging.debug('debug')
logging.info('info')
logging.warning('warn')
logging.error('error')
logging.critical('critical')
三、为logging模块指定全局配置,针对所有的logger有效,控制打印到文件中
1、可在logging.basicConfig()函数中,通过具体参数更改logging模块默认行为。可用的参数
filename:用指定的文件名创建FiledHandler(后边会具体讲解handler的概念),这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件,默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
2、format参数可能用到的格式化串
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
3、范例
import logging
logging.basicConfig(
filename='access.log',
# filemode='w', #默认是a模式
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10,
) logging.debug('debug')
logging.info('info')
logging.warning('warn123')
logging.error('error')
logging.critical('critical')
将日志写入到文件中
4、存在的问题
1:既往终端打印,又往文件中打印
2:控制输出到不同的目标(终端+文件)的日志,有各自的配置信息
四、logging模块的Formatter,Handler,Logger,Filter对象
1、原理图
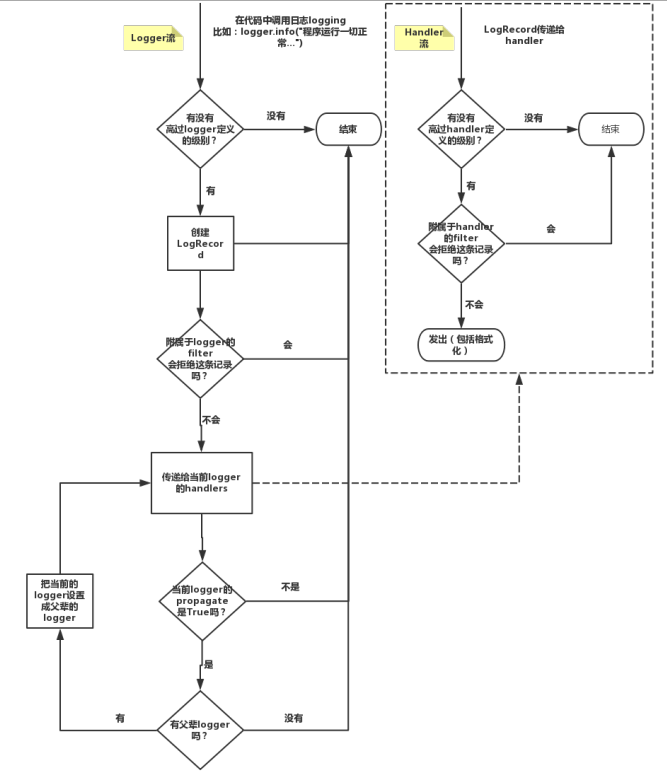
2、简介logging模块的对象
logger:产生日志的对象
Filter:过滤日志的对象
Handler:接收日志然后控制打印到不同的地方,FileHandler用来打印到文件中,StreamHandler用来打印到终端
Formatter对象:可以定制不同的日志格式对象,然后绑定给不同的Handler对象使用,以此来控制不同的Handler的日志格式
3、应用举例
import logging #一:Logger对象:负责产生日志信息
logger=logging.getLogger('root') #二:Filter对象:略 #三:Handler对象:负责接收Logger对象传来的日志内容,控制打印到终端or文件
h1=logging.FileHandler('t1.log')
h2=logging.FileHandler('t2.log')
h3=logging.StreamHandler() #四:formmater对象
#给文件
formatter1=logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
) #给终端
formatter2=logging.Formatter(
'%(asctime)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
) #五:为handler对象绑定日志格式,设置日志级别
#给文件:绑定到Filehandler对象
h1.setFormatter(formatter1)
h2.setFormatter(formatter1)
#给终端:绑定到Streamhandler对象
h3.setFormatter(formatter2) #设置日志级别
h1.setLevel(30)
h2.setLevel(30)
h3.setLevel(30) #六:把h1,h2,h3都add给logger,这样logger对象才能把自己的日志交给他们三负责输出
logger.addHandler(h1)
logger.addHandler(h2)
logger.addHandler(h3)
logger.setLevel(20) #括号的数字一定要<=Hanlder对象的数字 #七:测试
# logger.debug('debug')
# logger.info('info')
# logger.warning('warn123') #30
# logger.error('error')
# logger.critical('critical')
举例
五、Logger与Handler的级别
强调:如果想要日志成功打印
日志内容的级别 >= Logger对象的日志级别 >= Handler对象的日志级别
Logger is also the first to filter the message based on a level — if you set the logger to INFO, and all handlers to DEBUG, you still won't receive DEBUG messages on handlers — they'll be rejected by the logger itself. If you set logger to DEBUG, but all handlers to INFO, you won't receive any DEBUG messages either — because while the logger says "ok, process this", the handlers reject it (DEBUG < INFO). #验证
import logging form=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',) ch=logging.StreamHandler() ch.setFormatter(form)
# ch.setLevel(10)
ch.setLevel(20) l1=logging.getLogger('root')
# l1.setLevel(20)
l1.setLevel(10)
l1.addHandler(ch) l1.debug('l1 debug') 重要,重要,重要!!!
六、日志的继承
import logging
logger1=logging.getLogger('a')
logger2=logging.getLogger('a.b')
logger3=logging.getLogger('a.b.c')
h3=logging.StreamHandler()
formatter2=logging.Formatter(
'%(asctime)s - %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
h3.setFormatter(formatter2)
h3.setLevel(10)
logger1.addHandler(h3)
logger1.setLevel(10)
logger2.addHandler(h3)
logger2.setLevel(10)
logger3.addHandler(h3)
logger3.setLevel(10)
# logger1.debug('logger1 debug')
# logger2.debug('logger2 debug')
logger3.debug('logger2 debug')
'''
结果
2017-10-23 22:05:04 PM - logger2 debug
2017-10-23 22:05:04 PM - logger2 debug
2017-10-23 22:05:04 PM - logger2 debug
'''
七、应用
1、logging的配置范例
"""
logging配置
""" import os
import logging.config # 定义三种日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' # 定义日志输出格式 结束 logfile_dir = os.path.dirname(os.path.abspath(__file__)) # log文件的目录 logfile_name = 'all2.log' # log文件名 # 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir) # log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name) # log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
},
},
} def load_my_logging_cfg():
logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置
logger = logging.getLogger(__name__) # 生成一个log实例
logger.info('It works!') # 记录该文件的运行状态 if __name__ == '__main__':
load_my_logging_cfg()
logging配置文件
"""
MyLogging Test
""" import time
import logging
import my_logging # 导入自定义的logging配置 logger = logging.getLogger(__name__) # 生成logger实例 def demo():
logger.debug("start range... time:{}".format(time.time()))
logger.info("中文测试开始。。。")
for i in range(10):
logger.debug("i:{}".format(i))
time.sleep(0.2)
else:
logger.debug("over range... time:{}".format(time.time()))
logger.info("中文测试结束。。。") if __name__ == "__main__":
my_logging.load_my_logging_cfg() # 在你程序文件的入口加载自定义logging配置
demo()
使用
#1、有了上述方式我们的好处是:所有与logging模块有关的配置都写到字典中就可以了,更加清晰,方便管理 #2、我们需要解决的问题是:
1、从字典加载配置:logging.config.dictConfig(settings.LOGGING_DIC) 2、拿到logger对象来产生日志
logger对象都是配置到字典的loggers 键对应的子字典中的
按照我们对logging模块的理解,要想获取某个东西都是通过名字,也就是key来获取的
于是我们要获取不同的logger对象就是
logger=logging.getLogger('loggers子字典的key名') 但问题是:如果我们想要不同logger名的logger对象都共用一段配置,那么肯定不能在loggers子字典中定义n个key
'loggers': {
'l1': {
'handlers': ['default', 'console'], #
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
},
'l2: {
'handlers': ['default', 'console' ],
'level': 'DEBUG',
'propagate': False, # 向上(更高level的logger)传递
},
'l3': {
'handlers': ['default', 'console'], #
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, } #我们的解决方式是,定义一个空的key
'loggers': {
'': {
'handlers': ['default', 'console'],
'level': 'DEBUG',
'propagate': True,
}, } 这样我们再取logger对象时
logging.getLogger(__name__),不同的文件__name__不同,这保证了打印日志时标识信息不同,但是拿着该名字去loggers里找key名时却发现找不到,于是默认使用key=''的配置
!!!关于如何拿到logger对象的详细解释!!!
2、django的日志配置
#logging_config.py
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'
'[%(levelname)s][%(message)s]'
},
'simple': {
'format': '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
},
'collect': {
'format': '%(message)s'
}
},
'filters': {
'require_debug_true': {
'()': 'django.utils.log.RequireDebugTrue',
},
},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'filters': ['require_debug_true'],
'class': 'logging.StreamHandler',
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_info.log"), # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 3,
'formatter': 'standard',
'encoding': 'utf-8',
},
#打印到文件的日志:收集错误及以上的日志
'error': {
'level': 'ERROR',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_err.log"), # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'formatter': 'standard',
'encoding': 'utf-8',
},
#打印到文件的日志
'collect': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件,自动切
'filename': os.path.join(BASE_LOG_DIR, "xxx_collect.log"),
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'formatter': 'collect',
'encoding': "utf-8"
}
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console', 'error'],
'level': 'DEBUG',
'propagate': True,
},
#logging.getLogger('collect')拿到的logger配置
'collect': {
'handlers': ['console', 'collect'],
'level': 'INFO',
}
},
} # -----------
# 用法:拿到俩个logger logger = logging.getLogger(__name__) #线上正常的日志
collect_logger = logging.getLogger("collect") #领导说,需要为领导们单独定制领导们看的日志
二、re模块
一、正则表达式基础
1、什么是正则表达式
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
2、正则表达式简介
正则表达式元素可以归为三大类。
1.字符:字符可以代表一个单独的字符,或者一个字符集合构成的字符串。
2.限定符:允许你在模式中决定字符或者字符串出现的频率。
3.定位符:允许你决定模式是否是一个独立的单词,或者出现的位置必须在句子的开头还是结尾。
正则表达式代表的模式一般由四种不同类型的字符构成。
1.文字字符:像”abc”确切地匹配”abc“字符串
2.转义字符:一些特殊的字符例如反斜杠,中括号,小括号在正则表达式中居于特殊的意义,所以如果要专门识别这些特殊字符需要转义字符反斜杠。就像”\[abc\]“可以识 别”[abc]“。
3.预定义字符:这类字符类似占位符可以识别某一类字符。例如”\d”可以识别0-9的数字。
4.自定义通配符:包含在中括号中的通配符。例如”[a-d]“识别a,b,c,d之间的任意字符,如果要排除这些字符,可以使用”[^a-d]“。
| 元素 | 描述 |
| . | 匹配除了换行符意外的任意字符 |
| [^abc] | 匹配除了包含在中括号的任意字符 |
| [^a-z] | 匹配除了包含在中括号指定区间字符的任意字符 |
| [abc] | 匹配括号中指定的任意一个字符 |
| [a-z] | 匹配括号中指定的任意区间中的任意一个字符 |
| \a | 响铃字符(ASCII 7) |
| \c or \C | 匹配ASCII 中的控制字符,例如Ctrl+C |
| \d | 匹配任意数字,等同于[0-9] |
| \D | 匹配数字以外的字符 |
| \e | Esc (ASCII 9) |
| \f | 换页符(ASCII 15) |
| \n | 换行符 |
| \r | 回车符 |
| \s | 匹配任意空白字符(\t,\n,\r,\f) |
| \S | 匹配白空格(\t,\n,\r,\f)以外的字符 |
| \t | 制表符 |
| \uFFFF | 匹配Unicode字符的十六进制代码FFFF。例如,欧元符号的代码20AC |
| \v | 匹配纵向制表符(ASCII 11) |
| \w | 匹配字母,数字和下划线 |
| \W | 匹配字符,数字和下划线以外的字符 |
| \xnn | 匹配特殊字符,nn代表十六进制的ASCII 码 |
| .* | 匹配任意数量的字符(包括0个字符) |
限定符
上面表格中列出的每个通配符,可以代表一个确定的字符。使用限定符,可以精确地确定字符的出现频率。例如”\d{1,3}”代表一个数字字符出现1到3次。
| 元素 | 描述 |
| * | 匹配一个元素0次或者多次(最大限度地匹配) |
| *? | 匹配前面的元素零次或者多次(最小限度地匹配) |
| .* | 匹配任意个数的任意字符(包括0个字符) |
| ? | 匹配上一个元素0次或者1次(最大限度地匹配) |
| ?? | 匹配上一个元素0次或者1次(最小限度地匹配) |
| {n,} | 匹配上一个元素至少n次 |
| {n,m} | 匹配上一个元素n至m次 |
| {n} | 匹配上一个元素n次 |
| + | 匹配上一个元素一次或者多次 |
- *? 重复任意次,但尽可能少重复
- +? 重复1次或更多次,但尽可能少重复
- ?? 重复0次或1次,但尽可能少重复
- {n,m}? 重复n到m次,但尽可能少重复
- {n,}? 重复n次以上,但尽可能少重复
- | 表示 or
"colour" -match "colou?r" "color" -match "colou?r" 均返回true
此处的字符“?”并不代表任何字符,因为怕你可能会联想到简单模式匹配里面的“?”。正则表达式中的“?”,只是一个限定符,它代表的是指定字符或者子表达式出现的频率。具体到上面的例子,“u?”就确保了字符“u”在模式中不是必需的。常用的其它限定符,还有“*”(出现0次后者多次)和“+”(至少出现一次)
类似IP地址的模式通过正则表达式来描述比简单的通配符字符会更加精确。通常会使用字符和量词结合,来指定某个具体的字符应当出现,以及出现的频率:
| 元素 | 描述 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \A | 匹配字符串开始(包含多行文本) |
| \b | 匹配单词的边界 |
| \B | 匹配不在单词的边界 |
| \Z | 匹配字符串的结尾(包含多行文本) |
| \z | 匹配字符串结束 |
二、使用实践
1、re.findall('\w','hello_ | egon 123')
import re
# # 元字符
# #\w 匹配数字、字母和下划线字符
print(re.findall('\w','hello_ | egon 123'))
# #\W 匹配数字、字母和下划线以外的字符
print(re.findall('\W','hello_ | egon 123'))
# \s 匹配任意空字符
print(re.findall('\s','hello_ | egon 123 \n \t'))
# \S 匹配任意非空字符
print(re.findall('\S','hello_ | egon 123 \n \t'))
#\d匹配数字
print(re.findall('\d','hello_ | egon 123 \n \t'))
# \D匹配非数字
print(re.findall('\D','hello_ | egon 123 \n \t'))
# 匹配某个字符
print(re.findall('h','hello_ | egon 123 \n \t'))
# 匹配以he开头的
print(re.findall('^he','hello_ | egonh 123 \n \t'))
print(re.findall('\Ahe','hello_ | egonh 123 \n \t'))
# 匹配以123结尾的
print(re.findall('123\Z','hello_ | egonh o123 \n \t123'))
print(re.findall('123$','hello_ | egonh 0123 \n \t123'))
# 匹配制表符
print(re.findall('\n','hello_ | egonh 0123 \n \t123'))
print(re.findall('\t','hello_ | egonh 0123 \n \t123')) # . [] [^]
# .任意一个字符
print(re.findall('a.c','a a1c a*c a2c abc a c aaaaac aacc')) # [] 中括号内可以多个字符,匹配内部的任意一个字符
print(re.findall('[1 2\n3]','a a12c a*c a2c abc a c aaaaac aacc'))
print(re.findall('a[0-9][0-9]c','a a12c a*c a2c abc a c aaaaac aacc'))
# 没有a-Z匹配所有字符,Python中只能写成a-zA-Z
print(re.findall('a[a-zA-Z]c','a a12c a*c a2c abc a c aaaaac aacc'))
# 匹配+-*/ 时,-只能放到开头或结尾,不然需要转义(最好都加上转义符)
print(re.findall('a[-+*/]c','a+c a12c a*c a2c abc a c a-c a/c aaaaac aacc'))
print(re.findall('a[+*/-]c','a+c a12c a*c a2c abc a c a-c a/c aaaaac aacc'))
print(re.findall('a[\+\-\*\/]c','a+c a12c a*c a2c abc a c a-c a/c aaaaac aacc'))
# []匹配非中括号内的字符,取反
print(re.findall('a[^\+\-\*\/]c','a+c a12c a*c a2c abc a c a-c a/c aaaaac aacc')) # \转义符号,取消特殊符号的意思
# 先交给Python解释器处理一下,处理掉\的特殊函数\c本书就是特殊字符,\表示转义符需要先转义一个
print(re.findall('a\\\c','a\c abc'))
# 或者使用原生字符串:r,只需考虑正则表达式书写语法,不用考虑其他的因素
print(re.findall(r'a\\c','a\c abc')) # ? * + {} 表示左边的字符有多少 贪婪匹配
# ? 左边的一个字符有0个或1个 ##a必须存在,b也0个或者1个
print(re.findall('ab?','a ab abb abbb abbbbb aaa bbbb')) # * 左边的一个字符有0个或者无穷个
print(re.findall('ab*','a ab abb abbb abbbbb aaa bbbb')) # + 左边的一个字符有1个或者无穷个
print(re.findall('ab+','a ab abb abbb abbbbb aaa bbbb')) # {} 左边的一个字符有n-m次
print(re.findall('ab{3,5}','a ab abb abbb abbbbb aaa bbbb')) # .* .*?
# .* 任意字符任意次,贪婪匹配
print(re.findall('a.*c','ahhh121ca345cc'))
# .*? 任意字符任意次,非贪婪匹配(使用场景更多)
print(re.findall('a.*?c','ahhh121ca345cc')) # |或者
print(re.findall('company|companies','Too many companies have gone bankrupt, and the next one is my company')) # ()分组
# 不分组
print(re.findall('ab+','ababababab123'))
print(re.findall('ab+123','ababababab123'))
# 分组
print(re.findall('(ab)','ababababab123')) ##只输出组内的内容
print(re.findall('(a)b','ababababab123')) ##只输出组内的内容
print(re.findall('(ab)+','ababababab123')) #一直匹配,组内只会输出最后匹配的内容 print(re.findall('(ab)+123','ababababab123'))#只输出组内的内容
print(re.findall('(?:ab)+123','ababababab123')) #输出所有匹配的内容
print(re.findall('(ab)+(123)','ababababab123')) #一直匹配,组内只会显示最后匹配的内容 print(re.findall('compan(?:y|ies)','Too many companies have gone bankrupt, and the next one is my company'))
2、re模块的其他用法
# findall寻找所有的内容
print(re.findall('ab', 'ababababab123'))
# search 找所有的内容,找成功一次,就截止
print(re.search('ab','ababababab123')) ##输出搜索的过程
print(re.search('ab','ababababab123').group()) ##只输出结果
print(re.search('ab','asasasasasab123'))
# match #只匹配开头,有则输出结果,没有返回None
print(re.search('ab','123ab456'))
print(re.match('ab','123ab456')) ##等价于print(re.search('^ab','123ab456')) # split切分
print(re.split('b','abcde'))
print(re.split('[ab]','abcde')) # sub替换,可以指定替换的次数
print(re.sub('alex','SB','alex make love alex alex alex',1))
#打印出替换的次数
print(re.subn('alex','SB','alex make love alex alex alex'))
# 前后内容替换位置:分组替换即可
print(re.sub('(\w+)( .* )(\w+)',r'\3\2\1','alex make love')) # compile 编译,一次写,使用多次
obj=re.compile('\d{2}')
print(obj.search('abc123eee').group())
print(obj.findall('abc123eee'))
三、Python正则表达式中re.S的作用
在Python的正则表达式中,有一个参数为re.S。它表示“.”(不包含外侧双引号,下同)的作用扩展到整个字符串,包括“\n”。看如下代码:
import re
a = '''asdfhellopass:
123
worldaf
'''
b = re.findall('hello(.*?)world',a)
c = re.findall('hello(.*?)world',a,re.S)
print 'b is ' , b
print 'c is ' , c
运行结果如下:
b is []
c is ['pass:\n\t123\n\t']
正则表达式中,“.”的作用是匹配除“\n”以外的任何字符,也就是说,它是在一行中进行匹配。这里的“行”是以“\n”进行区分的。a字符串有每行的末尾有一个“\n”,不过它不可见。
如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
三、time与datetime模块
一、time模块
1、表示时间的三种方式
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String)
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
# 时间戳
print(time.time())
# 结果:1508582452.6290684 # 格式化的时间字符串
print(time.strftime('%Y-%m-%d %X'))
# 结果:2017-10-21 18:41:16 # 结构化的时间
# 本地时区时间
print(time.localtime())
# 结果:time.struct_time(tm_year=2017, tm_mon=10, tm_mday=21, tm_hour=18, tm_min=41, tm_sec=56, tm_wday=5, tm_yday=294, tm_isdst=0)
print(time.localtime().tm_mon)
# 结果:10 # UTC时间 和中国时区时间差八个小时print(time.gmtime())
#结果:time.struct_time(tm_year=2017, tm_mon=10, tm_mday=21, tm_hour=10, tm_min=23, tm_sec=3, tm_wday=5, tm_yday=294, tm_isdst=0)
%a Locale’s abbreviated weekday name.
%A Locale’s full weekday name.
%b Locale’s abbreviated month name.
%B Locale’s full month name.
%c Locale’s appropriate date and time representation.
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23].
%I Hour (12-hour clock) as a decimal number [01,12].
%j Day of the year as a decimal number [001,366].
%m Month as a decimal number [01,12].
%M Minute as a decimal number [00,59].
%p Locale’s equivalent of either AM or PM. (1)
%S Second as a decimal number [00,61]. (2)
%U Week number of the year (Sunday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Sunday are considered to be in week 0. (3)
%w Weekday as a decimal number [0(Sunday),6].
%W Week number of the year (Monday as the first day of the week) as a decimal number [00,53]. All days in a new year preceding the first Monday are considered to be in week 0. (3)
%x Locale’s appropriate date representation.
%X Locale’s appropriate time representation.
%y Year without century as a decimal number [00,99].
%Y Year with century as a decimal number.
%z Time zone offset indicating a positive or negative time difference from UTC/GMT of the form +HHMM or -HHMM, where H represents decimal hour digits and M represents decimal minute digits [-23:59, +23:59].
%Z Time zone name (no characters if no time zone exists).
%% A literal '%' character.
格式化字符串的时间格式
2、三种格式的时间转换
计算机认识的时间只能是'时间戳'格式,而程序员可处理的或者说人类能看懂的时间有: '格式化的时间字符串','结构化的时间'

# 时间戳转换为本地时间或UTC时间
print(time.localtime(112131121))
print(time.gmtime(112131121)) # 本地时间或UTC时间转换为时间戳
print(time.mktime(time.localtime()))
print(time.mktime(time.gmtime())) # 本地时间或UTC时间转换成格式化时间
print(time.strftime('%T',time.localtime()))
print(time.strftime('%T',time.gmtime())) # 格式化时间转换成结构化时间
print(time.strptime('2017-10-21','%Y-%m-%d'))
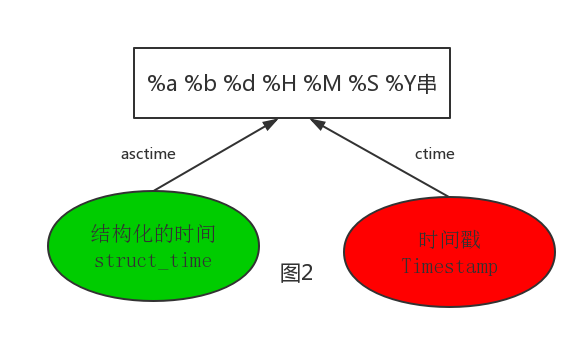
# asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。
# 如果没有参数,将会将time.localtime()作为参数传入。
print(time.asctime())#Sat Oct 21 19:09:29 2017
print(time.asctime(time.gmtime())) ##Sat Oct 21 11:12:43 2017 ,默认是localtime
# ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为
# None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
print(time.ctime()) # Sat Oct 21 19:09:29 2017
print(time.ctime(time.time())) #Sat Oct 21 19:09:29 2017
print(time.ctime(1000000000)) #Sun Sep 9 09:46:40 2001
二、dateime模块
import datetime print(datetime.datetime.now()) #返回 2017-10-21 19:14:30.416479
print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
print(datetime.datetime.now() )
print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 c_time = datetime.datetime.now()
print(c_time.replace(minute=3,hour=2)) #时间替换
四、random模块
一、random的常用操作
import random
#大于0且小于1的小数
print(random.random())
# 大于等于2且小于等于4的整数
print(random.randint(2,4))
# 大于等于2且小于4的整数
print(random.randrange(2,4))
# 在一定范围内生成随机字符
print(random.choice([1,8,100,['a','b']]))
# 列表元素任意n个组合
print(random.sample([1,8,100,['a','b'],'egon'],3))
# 大于1小于9的小数
print(random.uniform(1,9))
打乱原来的顺序,相当于洗牌
item=[1,3,5,7,9]
random.shuffle(item)
print(item)
二、实践:生成随机验证码
def make_code(n):
'''
生成10位随机验证码,元素包括大小写字母和数字
:param n:生成验证码的位数
:return: 返回验证吗
'''
res=''
for i in range(n):
s1=str(random.randint(0,9))
s2=chr(random.randint(65,122))
res +=random.choice([s1,s2])
return res
print(make_code(10))
五、os模块
os模块是与操作系统交互的一个接口
一、os模块的基本使用
1、使用os模块管理文件和目录
import os
print(os.getcwd()) #获取当前的工作目录
print(os.chdir("dirname")) #改变当前脚本的工作目录。需要加绝对路径
print(os.curdir) #返回当前目录: .
print(os.pardir) #返回当前目录的父目录字符串名: ..
print(os.makedirs('www/html/',777)) #创建多级目录,并指定权限:多层目录有一个不存在,则创建;多层目录都存在,则报错
print(os.removedirs('www/html/')) #递归删除空目录
print(os.mkdir('www',755)) #创建单级目录,并指定权限,没有创建,有的话报错
print(os.rmdir('www')) #删除单级空目录,若非空目录则报错
print(os.listdir('www')) #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
print(os.remove()) #删除一个文件
print(os.rename('www','os')) #重命名一个文件/目录
print(os.stat("./os模块.py")) #获取文件/目录信息
管理文件和目录
2、Windows和Linux的标识符
os.sep #输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep #输出当前平台使用的行终止符,win下为"\r\n",Linux下为"\n"
os.pathsep #输出用于分割文件路径的字符串 win下为;,Linux下为:
print([os.sep,os.linesep,os.pathsep])
Windows和Linux的标识符
3、直接运行系统命令和获取环境变量
print(os.system('dir .')) #运行shell命令,直接显示,达不到目录的结果 ##tasklist Windows查看单前的进程
print(os.environ) #获取系统环境变量
直接运行系统命令和获取环境变量
4、构建路径
print(os.path.join('C:\\','a','b','D:\\','d.txt')) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
print(os.path.abspath('os模块')) #返回path的规范化的绝对路径
print(os.path.expanduser('~')) #展开用户的HOME目录,如~、~username;
print(os.path.expanduser('~\\test.txt')) #路径拼接
构建路径
5、拆分路径:获取自己需要的路径中信息
print(os.path.split(os.path.abspath('os模块'))) #将path分隔成目录和文件名二元组返回
print(os.path.dirname(os.path.abspath('os模块'))) #返回path的目录,其实就是os.path.split(path)的第一个元素
print(os.path.basename(os.path.abspath('os模块'))) #返回path的目录,其实就是os.path.split(path)的第二个元素
print(os.path.splitext(os.path.abspath('os模块'))) #返回一个除去文件扩展名的部分和扩展名的二元组 。
拆分路径
6、判断文件类型
print(os.path.exists('os/html')) #若path存在,返回True;不存在,返回False
print(os.path.isabs('os/html')) #若path是绝对路径,返回True;否则,返回False
print(os.path.isfile('os模块.py')) #若path是一个存在的文件,返回True,否则,返回False
print(os.path.isdir('os')) #若path是一个存在的目录,但会True;否则,返回False
print(os.path.islink('os')) #参数path所指向的路径存在,并且是一个链接;
print(os.path.ismount('os')) #参数path所指向的路径存在,并且是一个挂载点。
判断文件类型
7、判断文件属性
os.path模块也包含了若干函数用来获取文件的属性,包括文件的创建时间 、修改时间、文件的大小等
print(os.path.getatime('os模块.py')) #返回path所指向的文件或者目录的最后存取时间
print(os.path.getmtime('os模块.py')) #返回path所指向的文件或者目录的最后修改时间
print(os.path.getctime('os模块.py')) #获取文件的创建时间
print(os.path.getsize('os模块.py')) #返回path的大小
判断文件属性
二、规划化路径
在Linux和mac平台上,该函数会原样返回path,在windows平台上会将路径中所有字符转换成小写,并将所有斜杠转换为反斜杠
print(os.path.normcase('c:/windows\\System32\\'))
##../和/
print(os.path.normpath('c://windows\\System32\\../Temp/') ) ##../向左跳过一级
三、路径处理
获取自己想要的路径,具体应用如下
1、方式一:使用os.path.normpath()
import os,sys
##实现一:
possible_topdir = os.path.normpath(os.path.join(
os.path.abspath(__file__),
os.pardir, ##上一级
os.pardir
))
##实现二:
possible_topdir = os.path.normpath(os.path.join(
os.path.abspath(__file__),
'..', ##上一级
'..'
)) print(possible_topdir)
# sys.path.insert(0,possible_topdir)
2、方式二:使用os.path.dirname()
x=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
print(x)
六、sys模块
一、sys的基本使用
import sys
# print(sys.argv) #命令行参数List,第一个元素是程序本身路径
# print(sys.argv[1]) ##取出相对应的地址
# print(sys.argv[2])
# python C:\Users\CTB-BJB-0012\PycharmProjects\python36\s19\day6\常用模块\6 sys模块.py 3306 sys.exit(0) ##退出程序,正常退出exit(0)
sys.version #获取python解释程序的版本信息
sys.maxint #最大的int值
sys.path #返回模块的搜索路径,初始化时使用python PATH环境变量的值
sys.platform #返回操作系统平台名称
二、sys模块实战
1、实现探索:打印进度条,显示百分比
实现思路:指定的对齐方式,显示宽度,打印的字符串;让后面的覆盖前面的内容,形成动态增长的效果
左对齐
print('[%10s]' %'#')
右对齐
实现第一步探索
print('[%-10s]' %'#')
print('[%-10s]' %'##')
print('[%-10s]' %'###')
print('[%-10s]' %'####') 打印%,两个%%取消百分号的特殊意义
print('%d%%' %30)
print(('[%%-%ds]' %50) %'#') #暂时不打印%
2、代码实现
import sys
# import time
def progress(percent,width=50):
show_str=('[%%-%ds]' %width) %(int(percent*width)*'#')
print('\r%s %s%%' %(show_str,int(percent*100)),end='',file=sys.stdout,flush=True) #立即将结果,刷新一下 total_size=102400000
recv_size=0
while recv_size < total_size:
# time.sleep(0.2) #1024
recv_size+=1024 #每次加 percent=recv_size/total_size
progress(percent,width=30)
七、shutil模块
高级的文件、文件夹、压缩包处理模块
一、shutil的基本操作
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# __author__ = "wzs"
#2017/10/21 import shutil
# 将文件内容拷贝到另一个文件中
shutil.copyfileobj(fsrc,fdst[,length])
shutil.copyfileobj(open('6sys模块.py','r',encoding='utf-8'),open('sys_new.py','w',encoding='utf-8')) # 拷贝文件,目标文件无需存在
shutil.copyfile('src','dst')
shutil.copyfile('a.txt','b.txt') # 仅拷贝权限。内容、组、用户均不变。目标文件必须存在
shutil.copymode('src','dst')
shutil.copymode('a.txt','b.txt') # 仅拷贝状态信息,包括:mode bits,atime,mtime,flags 。目标文件必须存在
shutil.copystat('src','dst')
shutil.copystat('a.txt','b.txt') # 拷贝文件和权限。目标文件无需存在
shutil.copy('src','dst')
shutil.copy('a.txt','b.txt') # 拷贝文件和状态信息。目标文件无需存在
shutil.copy2('src','dst')
shutil.copy2('a.txt','b.txt') # 递归的去拷贝文件夹
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
import shutil
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除 # 拷贝软连接
import shutil
shutil.copytree('f1', 'f2', symlinks=True, ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) # 通常的拷贝都把软连接拷贝成硬链接,即对待软连接来说,创建新的文件 # 递归的去删除文件
# shutil.rmtree(path[, ignore_errors[, onerror]])
import shutil
import os
os.makedirs('www/html/api')
shutil.rmtree('www') # 递归移动文件,它类似mv命令。相当于重命名
import shutil
shutil.move('www','ok')
二、文件压缩,解压处理
1、模块操作小解
创建压缩包并返回文件路径,例如:zip、tar 创建压缩包并返回文件路径,例如:zip、tar base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/
format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
root_dir: 要压缩的文件夹路径(默认当前目录)
owner: 用户,默认当前用户
group: 组,默认当前组
logger: 用于记录日志,通常是logging.Logger对象
2、shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,
# 将ok下文件打包防止当前程序目录(可以自己指定路径,打包的路径可以是绝对路径)
import shutil
ret = shutil.make_archive("data_bak",'gztar',root_dir='ok')
1、使用zipfile模块创建和读取zip压缩包
#打包压缩
import zipfile
z=zipfile.ZipFile('data_bak.zip','w')
z.write('a.log')
z.write('a.txt')
z.write('b.txt')
z.close() #解压:目录不存在会自动创建
z=zipfile.ZipFile('data_bak.zip','r')
z.extractall(path='html/')
z.close() #ZipFile的常用方法
namelist:返回zip文件中包含的所有文件和文件夹的字符串列表;
extract:从zip文件中提取单个文件;
extractall:从zip文件中提取所有文件。
使用Python的命令行工具创建zip格式的压缩包
-l 显示zip格式压缩包中的文件列表
-c 创建zip格式压缩包:若压缩包里面有文件,会先清空,然后将后面的内容添加进去
-e 提取zip格式压缩包:后面的目录不存在,会自动创建。
-t 验证文件是一个有效的zip格式压缩包
python -m zipfile -c kube-heapster.zip kubernetes-dashboard.yaml
python -m zipfile -c kube-heapster.zip ssl/
python -m zipfile -e kube-heapster.zip test
python -m zipfile -l kube-heapster.zip
python命令行实践
2、使用tarfile模块创建和读取压缩包内容
# 压缩
import tarfile
obj=tarfile.open('data_bak.tar.gz','w')
obj.add('a.log',arcname='a.log.bak')
obj.add('a.txt',arcname='a.txt.bak')
obj.add('b.txt',arcname='b.txt.bak')
obj.close() # 解压
obj=tarfile.open('data_bak.tar.gz','r')
obj.extractall('aaa')
obj.close() #提取压缩包内信息:tarfile 中有不少函数,其中,最常用的是 :
getnames :获取 tar 包中的文件列表;
extract :提取单个文件;
extractall :提取所有文件
案例:备份指定文件到压缩包
例如,备份Nginx的访问日志,备份MySQL的binlog日志。这些数据备份到压缩包中,并在压缩包的名称中使用时间标识,不但有利于文件管理,便于查找,而且能够有效减少磁盘占用空间。
from __future__ import print_function
import os
import fnmatch
import tarfile
import datetime def find_specific_files(root, pattern=['*'], exclude_dirs=[]):
pass def main():
patterns = ['*.jpg', '*jpeg', '*.tiff', '*.png']
now = datetime.datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
filename = "all_image_{0}.tar.gz".format(now)
with tarfile.open(filename, 'w:gz') as f:
for item in find_specific_files("*", patterns):
f.add(item) if __name__ == '__main__':
main()
3、案例:暴力破解zip压缩包的密码
###撞库方法破解压缩包密码(前提要有强大的密码库,不然也无法破解)
import shutil
import tarfile obj = tarfile.open('kube-heapster.zip','r')
with open('password.txt') as pf:
for line in pf:
try:
obj.extractall(pwd=line.strip())
print("password is {0}".format(line.strip()))
except:
pass
撞库破解压缩包的密码
八、joson&pickcle模块
eval内置方法可以将一个字符串转换成python对象,不过eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能使用,但遇到特殊类型时,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值
一、什么是序列化?
我们把对象从内存中变成可存储或传输的过程称之为序列化。在python中叫picking,在其他语言中称之为serialization,marshalling,flattening,都是一个意思
二、为什么要序列化
、数据持久化保存
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
、跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling
三、如何序列化之json和pickle(使用方法一样)
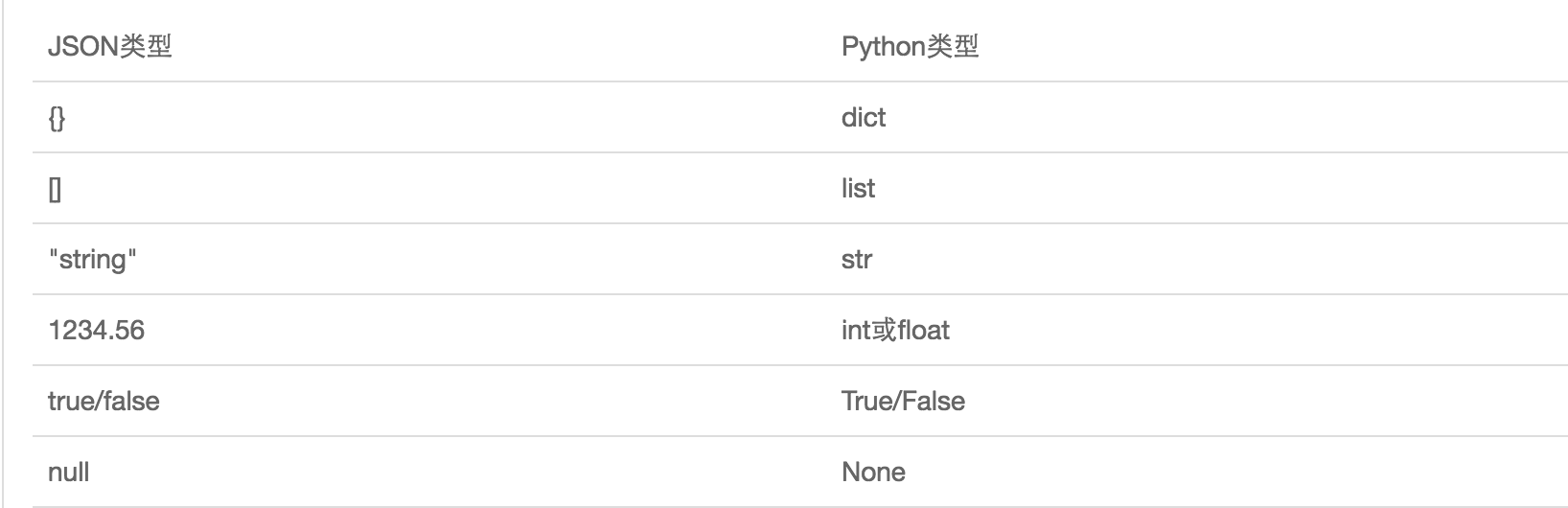
若要在不同语言之间传递对象,就必须把对象序列化成标准格式,比如XML,但更好的方法是系列为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便存储到磁盘或者通过网络传输,JSON不仅是标准格式,并且比XML更快,而且可以直接在web页面中读取,非常方便

四、json模块
1、将文件内容转换成json可以识别的字符串类型,打印到终端上
单引号不能被json识别
import json
user={'name':'egon','pwd':'egon123'}
print(json.dumps(user))
print(str(user))
2、将数据写入文件中 json.dumps() :复杂版
import json
user={'name':'egon','pwd':'egon123','age':22}
with open('db.json','w',encoding='utf-8') as f:
f.write(json.dumps(user))
序列化
with open('db.json','r',encoding='utf-8') as f:
data=f.read()
dic=json.loads(data)
print(dic['age']) ##取值验证
反序列化
3、将数据写入文件中json.dump():简化版
import json
user={'name':'egon','pwd':'egon123','age':22}
json.dump(user,open('db1.json','a',encoding='utf-8')) ##序列化
dic=json.load(open('db1.json','r',encoding='utf-8')) ##反序列化
print(dic,type(dic))
五、pickle模块

pickle可以序列化Python的所有数据类型
1、序列化、反序列化字典
import pickle
d={'a':1}
# 序列化
d_pkl=pickle.dumps(d)
with open('1.pkl','wb') as f:
f.write(d_pkl)
# 简化
pickle.dump(d,open('2.pkl','wb')) # 反序列化
x=pickle.load(open('2.pkl','rb'))
print(x)
序列化、反序列化字典
2、序列化、反序列化函数(没有这个应用场景)
import json,pickle
def func():
print('from 序列表.py') # json.dumps(func) #不可序列化函数
# pickle序列化
# pickle.dump(func,open('3.pkl','wb'))
# 序列化是一个内存地址,反序列化时,这个内存地址一定要存在
# pickle反序列化
f=pickle.load(open('3.pkl','rb'))
f()
九、shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
# 序列化,会形成三个文件,后面是序列化的内容
dic={'a':1,'b':2}
d=shelve.open(r'db.sh1')
d['egon']={'pwd':'','age':18}
d['alex']={'pwd':'','age':28}
d['x']=dic
d.close() # 反序列,不用指定反解时,打开文件的模式
obj=shelve.open(r'db.sh1')
print(obj['x']['a'])
十、configparser模块
一、测试文件test.conf
[mysql]
user = root
password = 123 [mysqld]
character-server-set = utf-8
port = 3306
x = True
y = 11.11
二、读取数据库
import configparser
obj=configparser.ConfigParser()
obj.read('my.cnf') print(obj.sections()) #取出文件的section:['mysql', 'mysqld']
print(obj.options('mysql')) #取出指定section内的values
print(obj.items('mysql')) #取出指定section内的items:既有key又有value # 取出某条具体的配置
print(obj.get('mysql','user')) #get拿到的数据是字符串类型
print(type(obj.getint('mysqld','port'))) #不用转化类型,直接使用相应的方法,取出整型
print(type(obj.getboolean('mysqld','x'))) #直接取出布尔值
print(type(obj.getfloat('mysqld'
三、判断数据是否存在
import configparser
obj=configparser.ConfigParser()
obj.read('my.cnf') print(obj.has_section('mysql')) #section是否存在
print(obj.has_option('mysql','host'))
四、增加、更改数据
实现——会先将原文件内容读取出来,写入新的内容,然后一并写入源文件
section存在,直接给原来的key赋予新的值,即直接更改源文件相对应的值
import configparser
obj=configparser.ConfigParser()
obj.read('my.cnf') obj.add_section('wzs')
obj.set('wzs','password','')
obj.set('wzs','is_ok','True') obj.write(open('my.cnf','w'))
五、删除指定的section和option
import configparser
obj=configparser.ConfigParser()
obj.read('my.cnf')
obj.remove_section('mysqld')
obj.remove_option('mysql','user')
obj.write(open('my.cnf','w'))
六、实战:形成下面的文件
[DEFAULT]
serveraliveinterval = 45
compression = yes
compressionlevel = 9
forwardx11 = yes [bitbucket.org]
user = hg [topsecret.server.com]
host port = 50022
forwardx11 = no
example.ini
import configparser
config = configparser.ConfigParser()
config["DEFAULT"] = {'ServerAliveInterval': '',
'Compression': 'yes',
'CompressionLevel': ''} config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '' # mutates the parser
topsecret['ForwardX11'] = 'no' # same here
config['DEFAULT']['ForwardX11'] = 'yes'
with open('example.ini', 'w') as configfile:
config.write(configfile)
实现代码
十一、hashlib模块
一、hash的基本知识
hash:一种算法 ,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
hash三个特点:
1.内容相同则hash运算结果相同,内容稍微改变则hash值则变
2.不可逆推
3.相同算法:无论校验多长的数据,得到的哈希值长度固定。
注意:把一段很长的数据update多次,与一次update这段长数据,得到的结果一样,但是update多次为校验大文件提供了可能。
1、单行字符串校验
import hashlib
m = hashlib.md5() # m=hashlib.sha256()
m.update('hello'.encode('utf8'))
print(m.hexdigest()) ##获取hash值 # 5d41402abc4b2a76b9719d911017c592
m.update('wzs'.encode('utf8'))
print(m.hexdigest()) # 4d2a80ad7dcecf5e94233bc595ed6287
m2 = hashlib.md5()
m2.update('hellowzs'.encode('utf8'))
print(m2.hexdigest()) # 4d2a80ad7dcecf5e94233bc595ed6287
2、多行内容进行校验:使用for循环对每行进行验证,节约系统资源
import hashlib
with open(r'G:\data\PyCharm_Project\Python\s19\day6\常用模块\example.ini','rb') as f:
m=hashlib.md5()
for line in f:
m.update(line)
print(m.hexdigest())
二、 模拟撞库破解密码
加密算法虽然依然非常厉害,但时候存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密。
1、将数据加密
import hashlib
s='alex3714'
m=hashlib.md5()
m.update(s.encode('utf-8'))
s_hash=m.hexdigest()
print(s_hash) #aee949757a2e698417463d47acac93df
数据加密
2、具体实现代码
import hashlib
passwds=[
'alex3714',
'',
'alex123',
'123alex',
'Alex@1203'
] def make_dic(passwds):
dic={}
for passwd in passwds:
m=hashlib.md5()
m.update(passwd.encode('utf-8'))
dic[passwd]=m.hexdigest()
return dic
def break_code(s1,dic):
for p in dic:
if s1 == dic[p]:
return p s1='aee949757a2e698417463d47acac93df'
dic=make_dic(passwds)
res=break_code(s1,dic)
print(res)
二、增强安全机制:密码加盐
import hashlib
# m=hashlib.md5('天王盖地虎'.encode('utf-8')) ##加盐
m=hashlib.sha3_512('天王盖地虎'.encode('utf-8')) ##加盐
m.update('wzs_perfect'.encode('utf-8'))
m.update('宝塔镇河妖'.encode('utf-8'))
print(m.hexdigest()) #fc5e038d38a57032085441e7fe7010b0
密码加盐
三、hmac模块
python还有一个hmac模块,它内部对我们创建key和内容及进一步的处理然后加密
密码加盐
import hmac
# 要保证两次校验的结果是一样的,处理内容一样以外,key必须一样
m1=hmac.new('你很牛棒棒的'.encode('utf-8'))
m1.update('wzs_perfect'.encode('utf-8'))
print(m1.hexdigest()) #8d5e7e804f99b4d4e48c3659dcf39482
处理内容相同,key不同,加密版不同
# m2=hmac.new('你很牛'.encode('utf-8'))
# m2.update('wzs_perfect'.encode('utf-8'))
# print(m2.hexdigest()) #4b66f8b0872a0802af087f9c8784aaf2
解密
m3=hmac.new('你很牛棒棒的'.encode('utf-8'))
m3.update('wzs_'.encode('utf-8'))
m3.update('perfect'.encode('utf-8'))
print(m3.hexdigest()) #8d5e7e804f99b4d4e48c3659dcf39482
十二、suprocess模块
##用来执行系统命令 import subprocess ##查看目录下的东西
res=subprocess.Popen(r'dir G:\data\PyCharm_Project\Python\s19\day6\常用模块\10xml模块\10xml模块.py',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE) print('============>',res)
print('========>',res.stdout.read())
print('========>',res.stderr.read().decode('gbk')) # dir file_path|findstr xml$
res1=subprocess.Popen(r'dir G:\data\PyCharm_Project\Python\s19\day6\常用模块\10xml模块',
shell=True,
stdout=subprocess.PIPE,) #stidin=res1.stout
res2=subprocess.Popen(r'findstr xml$',
shell=True,
stdin=res1.stdout,
stdout=subprocess.PIPE,)
print(res2.stdout.read().decode('gbk'))
十三、xml模块
xml是实现不同语言或程序之间进行数据交换的协议,个json差不多,但json使用起来更简单。至今很多传统公司的很多系统接口还主要是使用xml
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
example.xml
一、xml的操作
import xml.etree.ElementTree as ET
tree=ET.parse('server.xml')
root=tree.getroot() for child in root:
print('====>',child)
for i in child:
print(i.tag,i.attrib,i.text) # 查找element元素的三种方式
years=root.iter('year') #扫描整个xml文档树,找到所有
for i in years:
print(i) res1=root.find('country') #谁来调,就从谁下一层开始找,只找一个
print(res1) res2=root.findall('country') #谁来调,就从谁下一层开始找,只找一个
print(res2) # 修改
# 将文件每个年份加1
years=root.iter('year') #扫描整个xml文档树,找到所有
for year in years:
year.text=str(int(year.text)+1) ##更改原来的项目
year.set('updated','yes') ##添加新的项目
year.set('version','1.0')
tree.write('b.xml')
# tree.write('server.xml') # 删除
# 删除指定country底下rank的值大于10
for country in root.iter('country'):
#print(country.tag)
rank=country.find('rank')
if int(rank.text) > 10:
country.remove(rank)
tree.write('server.xml') # 增加节点
for country in root.iter('country'):
e=ET.Element('\tegon')
e.text='hello'
e.attrib={'age':'18'}
country.append(e)
tree.write('server.xml')
Day6 Python常用的模块的更多相关文章
- python 常用的模块
面试的过程中经常被问到使用过那些python模块,然后我大脑就出现了一片空白各种模块一顿说,其实一点顺序也没有然后给面试官造成的印象就是自己是否真实的用到这些模块,所以总结下自己实际工作中常用的模块: ...
- 第四章:4.0 python常用的模块
1.模块.包和相关语法 使用模块好处: 最大的好处是大大提高了代码的可维护性.其次,编写代码不必从零开始.当一个模块编写完毕,就可以被其他地方引用.我们在编写程序的时候,也经常引用其他模块,包括Pyt ...
- Day6 - Python基础6 模块shelve、xml、re、subprocess、pymysql
本节目录: 1.shelve模块 2.xml模块 3.re模块 4.subprocess模块 5.logging模块 6.pymysql 1.shelve 模块 shelve模块是一个简单的k,v将内 ...
- python学习之day6,常用标准模块
1.时间模块 time import time #时间戳转字符串格式 a = time.time() print(a) #打印时间戳 b = time.localtime(a) #把时间戳转换成时间对 ...
- python 常用第三方模块
除了内建的模块外,Python还有大量的第三方模块. 基本上,所有的第三方模块都会在https://pypi.python.org/pypi上注册,只要找到对应的模块名字,即可用pip安装. 本章介绍 ...
- python常用小模块使用汇总
在写代码过程中常用到一些好用的小模块,现整理汇总一下: 1.获取当前的文件名和目录名,并添到系统环境变量中. file = os.path.abspath(__file__) ...
- Python 常用系统模块整理
Python中的常用的系统模块中部分函数等的整理 random: 随机数 sys: 系统相关 os: 系统相关的 subprocess: 执行新的进程 multiprocessing: 进程相关 th ...
- [转] Python 常用第三方模块 及PIL介绍
原文地址 除了内建的模块外,Python还有大量的第三方模块. 基本上,所有的第三方模块都会在PyPI - the Python Package Index上注册,只要找到对应的模块名字,即可用pip ...
- python常用sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.modules.keys() 返回所有已经导入的模块列表 sys.exc_info() 获取当前正在处理的异常类,exc_typ ...
随机推荐
- [原]openstack-kilo--issue(二十)External network cannot is not reachable associate Port
issue==== INFO neutron.api.v2.resource [req-79a36d02-114b--b9ed-0a10c6d69451 ] update failed (client ...
- linux-Centos 7下bond与vlan技术的结合
服务器eno1与eno2作bonding,捆绑成bond0接口,服务器对端交换机端口,同属于301.302号vlan接口 vlan 301: 10.1.2.65/27 ...
- 查看,设置,设备的 竖屏-横屏模式 screen.orientation
<body> <div id="doc"></div> <div id="model"></div> ...
- 三剑客之awk
简介 awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大.简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再 ...
- 洛谷P1403 约数研究【思维】
题目:https://www.luogu.org/problemnew/show/P1403 题意: 定义$f(n)$为n的因子个数.给定一个数n,求$f(1)$到$f(n)$之和. 思路: 最直接的 ...
- 蚂蚁金服研发的金融级分布式中间件SOFA背后的故事
导读:GIAC大会期间,蚂蚁金服杨冰,黄挺等讲师面向华南技术社区做了<数字金融时代的云原生架构转型路径>和<从传统服务化走向Service Mesh>等演讲,就此机会,高可用架 ...
- UDP,TCP的套接字编程的Python实现
UDP,TCP的套接字编程的Python实现 套接字:连接应用层和运输层,应用层的网络应用程序使用IP地址+端口号来标识自己,然后通过套接字调用运输层为其服务,网络应用程序只能指定自己要使用的网络类型 ...
- 主从读写分离----mysql-proxy0.8.5安装与配置
废话不多说,直接开干: 1.安装环境: yum -y install libevent glib2 lua gcc gcc-c++ autoconf mysql-devel libtool pkgco ...
- React 60S倒计时
React 60S倒计时 1.设置状态: 2.函数主体: 3.应用: 4..效果图:
- 数据在内存中的存储方式( Big Endian和Little Endian的区别 )(x86系列则采用little endian方式存储数据)
https://www.cnblogs.com/renyuan/archive/2013/05/26/3099766.html 1.故事的起源 “endian”这个词出自<格列佛游记>.小 ...