YOLO(v1)
《You Only Look once:Unified,Real-Time Object Dectection》
以前的图像检测网络其实都是在分类网络的基础上进行修改,而YoLo是将检测问题切切实实地当作一个回归问题进行研究(它将bounding box回归和类别概率分开)因此这样的一个端到端的网络在单张图片上只需要进行一次评估就可以获得bounding box和物体的类别概率。

Yolo这里就是完全将检测变成了回归问题,通过卷积层和全连接层获得bounding box的位置坐标和类别概率(和以前的检测网络是有所区别的,比较直接暴力)
它主要有三个优点:
(1) 检测速度快,标准的能达到45fps,更快的能达到150fps
(2) 由于是对整张图进行回归,所以可以提取全文的信息;
(3) 泛化能力更强;
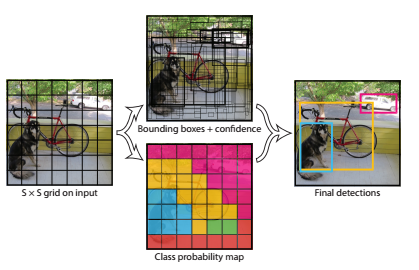
实际操作时,将一张图resize为448*448大小然后分割为S*S个单位格子,每个格子产生B个bounding boxes(每个box产生5个量,它们为box中心点的x和y坐标以及box的长和宽以及confidence,confidence表示“These scores encode both the probability of that class appearing in the box and how well the predicted box fits the object.”),同时每个cell还要产生C个类别概率(C为类别总数);
其中:confidence的计算公式见下:

(等式左边第二项应该表示cell中含有物体的概率,应该是所有类别概率的总和,等式第一项表示这个物体属于某类的概率);
最后的全连接层会预测: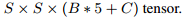
网络结构如下:

训练:
首先利用ImageNet 1000-class的分类任务数据集Pretrain卷积层。使用上述网络中的前20 个卷积层,加上一个 average-pooling layer,最后加一个全连接层,作为 Pretrain 的网络。训练大约一周的时间,使得在ImageNet 2012的验证数据集Top-5的精度达到 88%,这个结果跟 GoogleNet 的效果相当。
将Pretrain的结果的前20层卷积层应用到Detection中,并加入剩下的4个卷积层及2个全连接。 同时为了获取更精细化的结果,将输入图像的分辨率由 224* 224 提升到 448* 448。 将所有的预测结果都归一化到 0~1, 使用 Leaky RELU 作为激活函数。 为了防止过拟合,在第一个全连接层后面接了一个 ratio=0.5 的 Dropout 层。 为了提高精度,对原始图像做数据提升。
损失函数:
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification 这个三个方面达到很好的平衡。
简单的全部采用了sum-squared error loss来做这件事会有以下不足:
第一点:
a) 8维(B=2,(x,y,w,h))的localization error和20维的classification error同等重要显然是不合理的。
b) 如果一些栅格中没有object(一幅图中这种栅格很多),那么就会将这些栅格中的bounding box的confidence 置为0,相比于较少的有object的栅格,这些不包含物体的栅格对梯度更新的贡献会远大于包含物体的栅格对梯度更新的贡献,这会导致网络不稳定甚至发散。
解决方案如下:
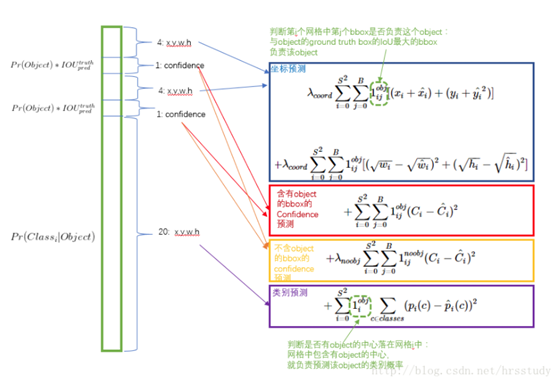
更重视8维的坐标预测,给这些损失前面赋予更大的loss weight, 记为 λcoord ,在pascal VOC训练中取5。(上图蓝色框)
对没有object的bbox的confidence loss,赋予小的loss weight,记为 λnoobj ,在pascal VOC训练中取0.5。(上图橙色框)
有object的bbox的confidence loss (上图红色框) 和类别的loss (上图紫色框)的loss weight正常取1。
第二点:
对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏相同的尺寸对IOU的影响更大。而sum-square error loss中对同样的偏移loss是一样。
为了缓和这个问题,作者用了一个巧妙的办法,就是将box的width和height取平方根代替原本的height和width。 如下图:small bbox的横轴值较小,发生偏移时,反应到y轴上的loss(下图绿色)比big box(下图红色)要大。
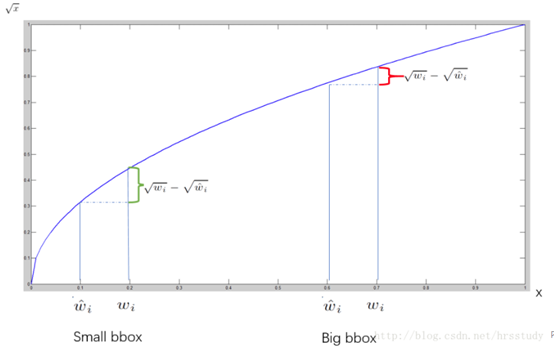
在 YOLO中,每个栅格预测多个bounding box,但在网络模型的训练中,希望每一个物体最后由一个bounding box predictor来负责预测。
因此,当前哪一个predictor预测的bounding box与ground truth box的IOU最大,这个 predictor就负责 predict object。
这会使得每个predictor可以专门的负责特定的物体检测。随着训练的进行,每一个 predictor对特定的物体尺寸、长宽比的物体的类别的预测会越来越好。
YOLO的不足:
(1) 互相靠近的物体数量不能太多;
(2) 不擅长检测小目标;
(3) 因为yolo是数据驱动的,因此当目标具有新的尺寸比时或者是非常规的尺寸比例时,yolo的泛化能力较弱;
(4) YOLO采用了多个下采样层(池化层),网络学到的物体特征并不精细,因此也会影响检测效果
(5) YOLO loss函数中,大物体IOU误差和小物体IOU误差对网络训练中loss贡献值接近(虽然采用求平方根方式,但没有根本解决问题)。因此,对于小物体,小的IOU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性;
(6) 由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率;
(7) 虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷;
后期,作者为了改进YOLO的这些不足,提出了更好的版本YOLO9000。
代码:Linux(https://pjreddie.com/darknet/yolo/)
Windows(https://github.com/zhaolili/darknet)
YOLO(v1)的更多相关文章
- 目标检测之YOLO V1
前面介绍的R-CNN系的目标检测采用的思路是:首先在图像上提取一系列的候选区域,然后将候选区域输入到网络中修正候选区域的边框以定位目标,对候选区域进行分类以识别.虽然,在Faster R-CNN中利用 ...
- YOLO v1之总结篇(linux+windows)
YOLO出自2016 CVPR You Only Look Once:Unified, Real-Time Object Detection,也是一个非常值得学习的框架,不得不说facebook的技术 ...
- Object Detection(RCNN, SPPNet, Fast RCNN, Faster RCNN, YOLO v1)
RCNN -> SPPNet -> Fast-RCNN -> Faster-RCNN -> FPN YOLO v1-v3 Reference RCNN: Rich featur ...
- DNN:windows使用 YOLO V1,V2
本文有修改,如有疑问,请移步原文. 原文链接: YOLO v1之总结篇(linux+windows) 此外: YOLO-V2总结篇 Yolo9000的改进还是非常大的 由于原版的官方YOLOv ...
- YOLO V1损失函数理解
YOLO V1损失函数理解: 首先是理论部分,YOLO网络的实现这里就不赘述,这里主要解析YOLO损失函数这一部分. 损失函数分为三个部分: 代表cell中含有真实物体的中心. pr(object) ...
- 目标检测论文解读5——YOLO v1
背景 之前热门的目标检测方法都是two stage的,即分为region proposal和classification两个阶段,本文是对one stage方法的初次探索. 方法 首先看一下模型的网络 ...
- YOLO V1、V2、V3算法 精要解说
前言 之前无论是传统目标检测,还是RCNN,亦或是SPP NET,Faste Rcnn,Faster Rcnn,都是二阶段目标检测方法,即分为“定位目标区域”与“检测目标”两步,而YOLO V1,V2 ...
- YOLO v1到YOLO v4(下)
YOLO v1到YOLO v4(下) Faster YOLO使用的是GoogleLeNet,比VGG-16快,YOLO完成一次前向过程只用8.52 billion 运算,而VGG-16要30.69bi ...
- YOLO v1到YOLO v4(上)
YOLO v1到YOLO v4(上) 一. YOLO v1 这是继RCNN,fast-RCNN和faster-RCNN之后,rbg(RossGirshick)针对DL目标检测速度问题提出的另外一种框 ...
- 目标检测:YOLO(v1 to v3)——学习笔记
前段时间看了YOLO的论文,打算用YOLO模型做一个迁移学习,看看能不能用于项目中去.但在实践过程中感觉到对于YOLO的一些细节和技巧还是没有很好的理解,现学习其他人的博客总结(所有参考连接都附于最后 ...
随机推荐
- AGC 016 F - Games on DAG(状压dp)
题意 给你一个有 \(n\) 个点 \(m\) 条边 DAG 图,点的标号和拓扑序一致. 现在有两个人进行博弈,有两个棋子分别在 \(1, 2\) 号点上,需要不断移动到它指向的点上. 如果当前两个点 ...
- android 开启闪光灯小应用
该程序需要在AndroidManifest.xml添加权限,属性 android:screenOrientation="portrait" android.permission.C ...
- ubuntu 13.04 开发环境搭建
install ubuntu1, mysql serversudo apt-get install mysql-server2, ssh sudo apt-get install openssh-se ...
- CF741D Arpa’s letter-marked tree and Mehrdad’s Dokhtar-kosh paths
CF741D Arpa’s letter-marked tree and Mehrdad’s Dokhtar-kosh paths 好像这个题只能Dsu On Tree? 有根树点分治 统计子树过x的 ...
- 洛谷P1247 取火柴游戏
经典NIM游戏. 取XOR和即可. 注意输出方案时,找到大于异或和sum的,变为a[i] ^ sum即可. #include <cstdio> ; int a[N]; int main() ...
- jnlp初次试用
1.jnlp是什么?是java提供的一种让你可以通过浏览器直接执行java应用程序的途径,它使你可以直接通过一个网页上的url连接打开一个 java应 用程序.好处就不用说了,如果你的java应用程序 ...
- 目标检测网络之 R-FCN
R-FCN 原理 R-FCN作者指出在图片分类网络中具有平移不变性(translation invariance),而目标在图片中的位置也并不影响分类结果;但是检测网络对目标的位置比较敏感.因此Fas ...
- mysql数据库user表host字段的%问题
搜索: mysql数据库user表host字段的%问题 连接:http://blog.csdn.net/xiaomengh/article/details/48706149 在mysql数据库中,使用 ...
- PHP iconv 解决utf-8和gb2312编码转换问题
就一个很简单的函数iconv();但是就是这个函数在网上找了很多例子,都无法成功转换,这是为什么呢? 终于皇天不负有心人,答案还是让我找到了. 网上的都是这样用的 <?php $co ...
- python类变量和实例变量的区别
类变量:是为类服务的,类所有的实例都共享使用,在一个地方被改变,所有调用的地方变量值都改变.定义类时的写法为类名.变量名 实例变量:是在实例中生效的,每个实例变量的值都根据实例本身需求进行修改,不会影 ...