[Paper] Selection and replacement algorithm for memory performance improvement in Spark
Summary
Spark does not have a good mechanism to select reasonable RDDs to cache their partitions in limited memory. --> Propose a novel selection algorithm, by which Spark can automatically select the RDDs to cache their partitions in memory according to the number of use for RDDs. --> speeds up iterative computations.
Spark use least recently used (LRU) replacement algorithm to evict RDDs, which only consider the usage of the RDDs. --> a novel replacement algorithm called weight replacement (WR) algorithm, which takes comprehensive consideration of the partitions computation cost, the number of use for partitions, and the sizes of the partitions.
Preliminary Information
Cache mechanism in Spark
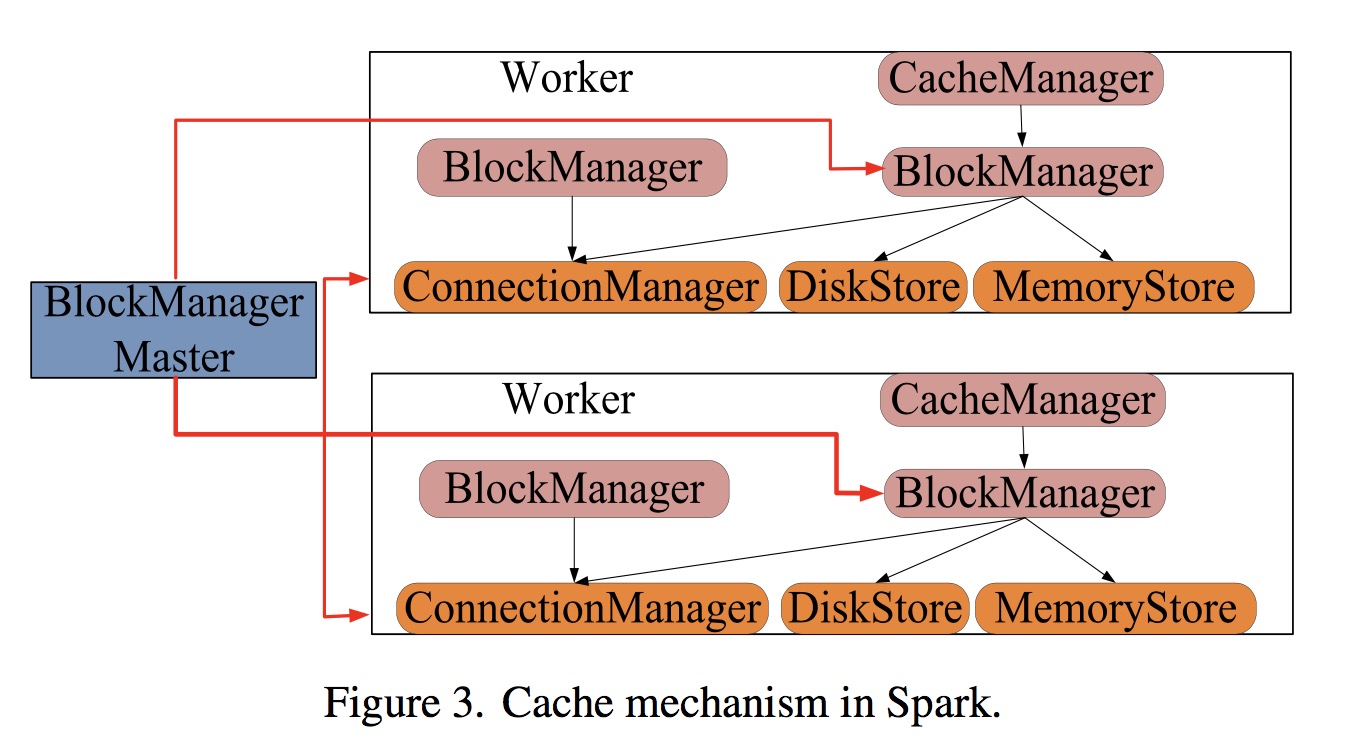
- When RDD partitions have been cached in memory during the iterative computation, an operation which needs the partitions will get them by CacheManager.
- All operations including reading or caching in CacheManager mainly depend on the API of BlockManager. BlockManager decides whether partitions are obtained from memory or disks.
Scheduling model
- The LRU algorithm only considers whether those partitions are recently used while ignores the partitions computation cost and the sizes of the partitions.
- The number of use for partitions can be known from the DAG before tasks are performed.
Let Nij be the number of use of j-th partition of RDDi.
Let Sij be the size of j-th partition or RDDi. - The computation time is also an important part. --> Each partition of RDDi starting time STij and finishing time FTij can roughly express its execution and communication time.
Consider the computation cost of partition as Costj = FTij - STij. - After that, we set up a scheduling model and obtain the weight of Pij, which can be expressed as:
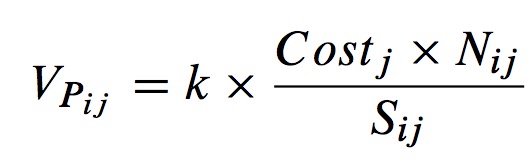
where k is the correction parameter, and it's set to a constant. - Finally, we assume that there are h partitions in RDDi, so the weight of RDDi is:
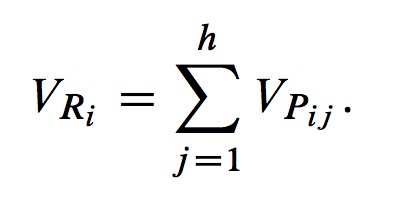
Proposed Algorithm
Selection algorithm
- For a given DAG graph,we can get the num of uses for each RDD, expressioned as NRDDi.
- The pseudocode:

Replacement algorithm
- In this paper, we use weight of partition to evaluate the importance of the partitions.
- When many partitions are cached in memory, we use QuickSort algorithm to sort the partitions according to the value of the partitions.
- The pseudocode:

Experiments
- five servers, six virtual machines, each vm has 100G disk, 2.5GHZ and runs Ubuntu 12.04 operation system while memory is variable, and we set it as 1G, 2G, or 4G in different conditions.
- Hadoop 2.10.4 and Spark-1.1.0.
- use ganglia to observe the memory usage.
- use pageRank algorithm to do expirement, it's iterative.
[Paper] Selection and replacement algorithm for memory performance improvement in Spark的更多相关文章
- Partitioned Replacement for Cache Memory
In a particular embodiment, a circuit device includes a translation look-aside buffer (TLB) configur ...
- Flash-aware Page Replacement Algorithm
1.Abstract:(1)字体太乱,单词中有空格(2) FAPRA此名词第一出现时应有“ FAPRA(Flash-aware Page Replacement Algorithm)”说明. 2.in ...
- Inside Amazon's Kafkaesque "Performance Improvement Plans"
Amazon CEO and brilliant prick Jeff Bezos seems to have lost his magic touch lately. Investors, empl ...
- Hive-Container killed by YARN for exceeding memory limits. 9.2 GB of 9 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task times, most recen ...
- Spring Boot Memory Performance
The Performance Zone is brought to you in partnership with New Relic. Quickly learn how to use Docke ...
- 计算机系统结构总结_Memory Hierarchy and Memory Performance
Textbook: <计算机组成与设计——硬件/软件接口> HI <计算机体系结构——量化研究方法> QR 这是youtube上一个非常好的memory syst ...
- PatentTips - Control register access virtualization performance improvement
BACKGROUND OF THE INVENTION A conventional virtual-machine monitor (VMM) typically runs on a compute ...
- SQL Performance Improvement Techniques(转)
原文地址:http://www.codeproject.com/Tips/1023621/SQL-Performance-Improvement-Techniques This article pro ...
- Ceilometer Polling Performance Improvement
Ceilometer的数据采集agent会定期对nova/keystone/neutron/cinder等服务调用其API的获取信息,默认是20秒一次, # Polling interval for ...
随机推荐
- navicat和 plsql 连接oracle数据库 总结
打开 navicat -->工具-->选项-->oci 右侧选择oci.dll 的路径 默认 在 navicat的安装目录下有一个 instantclient 的文件夹 直接选 ...
- reflow 和 repaint
Reflow(渲染):对于DOM结构中的各个元素都有自己的盒模型,浏览器根据各种样式(浏览器的.开发人员定义的等)来计算,并根据计算结果将元素放到它该出现的位置,这个过程称之为reflow. refl ...
- element-ui table中排序 取消表格默认排序问题
sortTable 设置为 custom 一定要设置在列上
- win 安装plsql的步骤
1.下载oracle和plsql地址:http://pan.baidu.com/s/1bTlcom,http://pan.baidu.com/s/1c2BMsZe 2.首先安装plsql 这个比较简单 ...
- leetcode-algorithms-13 Roman to Integer
leetcode-algorithms-13 Roman to Integer Roman numerals are represented by seven different symbols: I ...
- 杂记-格式化Date默认格式,日期加一天,jstl判断字符类型,ajax模拟from表单后台跳转页面,jstl访问数据库并在页面显示
1.格式化Date默认格式 String str="Sun Oct 08 22:36:45 CST 2017"; SimpleDateFormat sdf = new Simple ...
- TOYS
TOYS Calculate the number of toys that land in each bin of a partitioned toy box. Mom and dad have a ...
- 一、集合框架(Collection和Collections的区别)
一.Collection和Map 是一个接口 Collection是Set,List,Queue,Deque的接口 Set:无序集合,List:链表,Queue:先进先出队列,Deque:双向链表 C ...
- java.lang.Exception: DEBUG STACK TRACE for PoolBackedDataSource.close().
java.lang.Exception: DEBUG STACK TRACE for PoolBackedDataSource.close(). java.lang.Exception: DEBUG ...
- 分布式锁与实现(一)基于Redis实现
目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题.分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency).可用性( ...