查找->动态查找表->哈希表
文字描述
哈希表定义
在前面讨论的各种查找算法中,都是建立在“比较”的基础上。记录的关键字和记录在结构中的相对位置不存在确定的关系,查找的效率依赖于查找过程中所进行的比较次数。而理想的情况是希望不经过任何比较,一次存取便能得到所查记录,那就必须在记录的存储位置和关键字之间建立一个确定的对应关系f。查找时,只要根据这个对应关系f找到给定值K的像f(K)。若结构中存在关键字和K相等的记录,则必定在f(K)的存储位置上,由此,不需要进行比较就可以直接取得所查记录。在此,这个对应关系f被称为哈希函数。按这个思想建立的表为哈希表。
(1)哈希函数是一个映像,因此哈希函数的设定很灵活,只要使得任何关键字由此所得的哈希函数值都落在表长允许范围之内即可。
(2)对不同的关键字可能得到同一哈希地址,即key1不等于key2,而f(key1)=f(key2)。这种现象称为冲突。具有相同函数值的关键字对该哈希函数来说称为同义词。一般情况下,冲突只能尽可能地少,而不能完全避免。因此哈希函数是从关键字集合到地址集合的映像。
综上,哈希表定义:根据设定的哈希函数H(key)和处理冲突的方法将一组关键字映像到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“像”作为记录在表中的存储位置,这种表便称为哈希表,这一映像过程称为哈希造表或散列,所得存储位置成为哈希地址或散列地址。
哈希函数
(1)直接定址法
取关键字或关键字的某个线形函数值为哈希地址.即H(key) = key 或 H(key)=a*key+b。
由于直接定址所得地址集合和关键字集合的大小相同。因此,对于不同的关键字不会发生冲突。但实际中能使用这种哈希函数的情况很少。
(2)数字分析法
假设关键字是以r为基的数(如:以10为基的十进制数),并且哈希表中可能出现的关键字都是事先知道的,则可取关键字的若干数位组成哈希地址。
比如一系列已知的关键字中,中间的4位十进制数可看成近乎随即的,因此可取其中任意两位,或取其中两位与另外两位的叠加求和后舍去进位作为哈希地址.
(3)平方取中法
取关键字平方后的中间几位为哈希地址。
在选定哈希函数时不一定能知道关键字的全部情况,取其中哪几位都不一定合适,而一个数平方后的中间几位和数的每一位都相关,由此使随机分布的关键字得到的哈希地址也是随机的。取的位数由表长决定。
(4)折叠法
将关键字分割成位数相同的几部分(最后一部分的位数可以不同),然后取这几部分的叠加和(舍去进位)作为哈希地址,这方法称为折叠法。
关键字位数很多,且关键字上每一位上数字分布大致均匀时,可以采用折叠法计算哈希地址。
(5)除留余数法
取关键字被某个不大于哈希表表长m的数p除后所得余数为哈希地址。即 H(key) = key MOD p; (p小于等于m)
这是一种最简单也最常用的构造哈希函数的方法。不仅可以对关键字直接取模(MOD),也可在折叠、平方取中等运算之后取模。由众人经验,一般选p为质数或不包含小于20的质因数的合数。
(6)随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机函数。
通常,当关键字长度不等时采用此法构造哈希函数较合适。
实际工作中需视不同情况采用不同的哈希函数。通常,考虑的因素有:
A 计算哈希函数所需时间
B 关键字的长度
C 哈希表的大小
D 关键字的分布情况
E 记录的查找频率
处理冲突
(1)开放定址法
Hi = (H(key)+di) MOD m ; i=1,2,…,k (k小于等于m-1)
其中:H(key)为哈希函数;m为哈希表表长;di为增量序列,可有下列3种取法;
(1.1) di = 1,2,3,…,m-1,称为线性探测再散列
(1.2) di = 12, -12, 22, -22, 32, …, k2(或者-k2),(k小于等于[m/2]), 称为二次探测再散列。
(1.3) di = 伪随机数列,称为伪随机探测散列。
例如,在长度为11的哈希表中已填有关键字分别为17,60,29的记录(哈希函数H(key)=key MOD 11),现要在插入第四个关键字为38的记录,由哈希函数得到哈希地址为5,产生冲突。
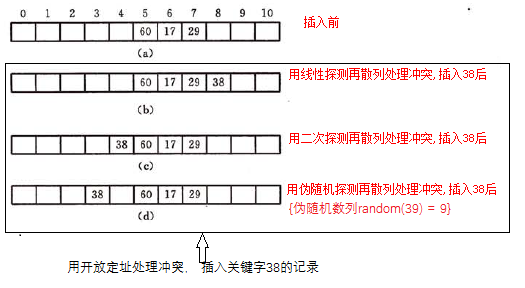
(2)再哈希法
Hi = RHi(key), i=1,2,…,k
RHi均是不同的哈希函数,即在同义词产生地址冲突时计算另一个哈希函数地址,直到冲突不再发生。这种方法不宜产生“聚集”,但增加了计算时间。
(3)链地址法
将所有关键字为同义词的记录存储在同一线性链表中。假设某哈希函数产生的哈希地址在区间[0,…,m-1]上,则设立一个指针型向量Chain ChainHash[m]; 其每个分量的初始状态都是空指针。凡哈希地址为i的记录都插入到头指针为ChainHash[i]的链表中。在链表中的插入位置可以在表头或表尾或中间,以保持同义词在同一线性链表中按关键字有序。
(4)建立一个公共溢出区
假设哈希函数的值域为[0,…,m-1],则设向量HashTable[0,…,m-1]为基本表,基本表中每个分量存放一个记录;另设立向量OverTable[0,…,v]为溢出表。所有关键字和基本表中关键字为同义词的记录,不管他们由哈希函数得到的哈希地址是什么,一旦发送冲突,都填入溢出表。
例题

按第2种方法构造的哈希表中,查找K=38的过程为:先求哈希地址H(38) =12, a.elem[12]不空且a.elem[12].key不等于38, 则找下一地址H1=(12+1) MOD 16 = 13, 由于a.elem[13]是空记录,则表明表中不存在关键字等于38的记录。
哈希表的查找
在哈希表上进行查找的过程和哈希造表的过程基本一致。给定K值,根据造表时设定的哈希函数求得哈希地址,若表中此位置上没有记录,则查找不成功;否则比较关键字,若和给定值相等,则查找成功;否则根据造表时设定的处理冲突的方法找“下一地址”,直到哈希表中某个位置为“空”或者表中所填记录的关键字等于给定值时为止。
哈希表的查找分析
从哈希表中的查找过程可知:
(1)由于“冲突”的产生,使得哈希表的查找过程仍然是一个给定值和关键字进行比较的过程。因此,仍需以平均查找长度作为衡量哈希表的查找效率的量度。
(2)哈希表中的平均查找长度取决于三个因素:哈希函数,处理冲突的方法和哈希表的装填因子。
哈希函数的“好坏”首先影响出现冲突的频繁程度。但是,对于“均匀的”哈希函数可以假定:不同的哈希函数对同一组随即的关键字,产生冲突的可能性相同,因为一般情况下设定的哈希函数是均匀的,则可不考虑它对平均查找长度的影响。
对同一组关键字,设定相同的哈希函数,则不同的处理冲突的方法得到的哈希表不同,它们的平均查找长度也不同。显然,开放地址法中的线性探测再散列法在处理冲突的过程中易产生记录的二次聚集,即容易使地址不相同的记录又产生新的冲突;而链地址法在处理冲突时不会发生二次聚集的情况,因为哈希地址不同的记录在不同的链表中。
一般,处理冲突方法相同的哈希表,其平均查找长度依赖于哈希表的装填因子α。α定义: (表中填入的记录数)/(哈希表的长度); α标志哈希表的装满程度; α越小,发生冲突的可能性越小; 反之,α越大,表中已填入的记录越多,再填记录时,发生冲突的可能性越大,查找时需比较的关键字的个数也就越多。
*如下几个证明平均查找长度的过程略
不同的处理冲突方法构成的哈希表查找成功时的平均查找长度

不同的处理冲突方法构成的哈希表查找不成功时的平均查找长度

从上述分析可知,哈希表的平均查找长度是α的函数,与元素个数n无关。
另外,若在非链地址处理冲突的哈希表中删除一个记录,则需在该记录的位置上填入一个特殊的符号,以免找不到它之后填入的“同义词”的记录。
代码实现
#include <stdio.h>
#include <stdlib.h> #define DEBUG
#define EQ(a,b) ((a)==(b))
#define LT(a,b) ((a)< (b))
#define LQ(a,b) ((a)<=(b))
#define SUCCESS 1
#define UNSUCCESS 0
#define DUTLICATE -1 #define NULLKEY -1
//定义关键字类型为int
typedef int KeyType;
//定义结点类型
typedef struct{
KeyType k;
}ElemType;
//定义哈希表类型
typedef struct{
//数据元素存储基址
ElemType *elem;
//当前数据元素个数
int count;
//hashsize[sizeindex]为当前容量
int sizeindex;
}HashTable; //哈希表容量递增表,尽量是一个合适的素数序列
int hashsize[] = {, , , }; //重建哈希表
int RecreateHashTable(HashTable *H){
int i = ;
int t = (((sizeof(hashsize))/(sizeof(int)) -));
if(H->sizeindex >= t){
return -;
}
if(H->sizeindex < ){
H->elem = realloc(H->elem, hashsize[]);
H->sizeindex = ;
}else{
H->elem = realloc(H->elem, hashsize[H->sizeindex+]);
H->sizeindex += ;
}
for(i=H->count; i<hashsize[H->sizeindex]; i++){
H->elem[i].k = NULLKEY;
}
return ;
} //哈希函数的构造法: 除留余数法
int Hash(KeyType K){
return (K % (hashsize[]-));
} //处理冲突的方法: 采用开放定址法中的线性探测再散列法
int collision(int *p, int *c){
*p = ((*p + *c) % (hashsize[]-));
return ;
} //在哈希表H中查找关键码为K的元素,若查找成功,已p指示待查数据元素在表中位置,并返回success;
//否则,以p指示插入位置,并返回unsuccess, c用以表示冲突次数,并设置其处置为0,供建表插入时参考
int SearchHash(HashTable H, KeyType K, int *p, int *c){
//求得哈希地址
*p = Hash(K);
while((H.elem[*p].k != NULLKEY) //该表中填有记录
&& !EQ(K, H.elem[*p].k) //并且与该表中已有记录不等
){
*c = *c + ;
if(*c >= (hashsize[H.sizeindex]/)){
//冲突次数达到闸值上限, 则不再探测
return UNSUCCESS;
}else{
//求得下一探测地址
collision(p, c);
}
}
if(EQ(K, H.elem[*p].k)){
//查找成功,p返回待查数据元素位置
return SUCCESS;
}else{
//查找不成功,p返回的是插入位置
return UNSUCCESS;
}
} //哈希表的插入操作
//查找不成功时插入数据元素e到哈希表H中,并返回OK;
//若冲突次数过大,则重建哈希表.
int InsertHash(HashTable *H, ElemType e){
int c = ;
int p = ;
if(SearchHash(*H, e.k, &p, &c) == SUCCESS){
//表示哈西表H中已经有相同关键字的元素
printf("insert(%d) dulicate!!\n", e.k);
return DUTLICATE;
}else if(c < (hashsize[H->sizeindex]/)){
//冲突次数未达到上限, (c的闸值可以调整)
H->elem[p] = e;
H->count += ;
printf("insert(%d) success!!\n", e.k);
return SUCCESS;
}else{
//重建哈希表
RecreateHashTable(H);
printf("insert(%d) unsuccess!!\n", e.k);
return UNSUCCESS;
}
} int main(int argc, char *argv[]){
printf("哈希函数采用除留余数法: (K % (%d))\n", hashsize[]-);
printf("解决冲突采用开放定址法中的线性探测再散列法: ((*p + *c++) % (%d))\n", hashsize[]-);
HashTable H;
H.elem = NULL;
H.count = ;
H.sizeindex = -; RecreateHashTable(&H);
int i = ;
ElemType e;
KeyType k = ;
while(){
scanf("%d", &k);
if(k < )
break;
e.k = k;
InsertHash(&H, e);
}
for(i=; i<hashsize[H.sizeindex]; i++){
if(H.elem[i].k == NULLKEY){
printf("elem[%d]=NULLKEY\n", i);
}else{
printf("elem[%d]=%d\n", i, H.elem[i]);
}
}
return ;
}
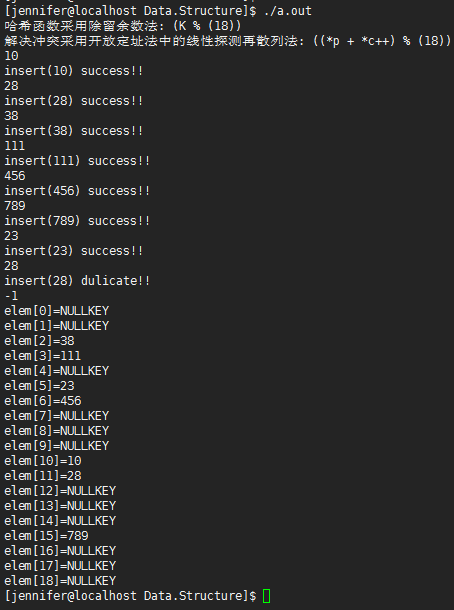
哈希表构造: 除留余数法-开放定址法中的线性探测再散列
代码运行
查找->动态查找表->哈希表的更多相关文章
- 查找-------(HashCode)哈希表的原理
这段时间 在 准备软件设计师考试 目的是想复习一下 自己以前没怎么学的知识 在这个过程中 有了很大的收获 对以前不太懂得东西 在复习的过程中 有了很大程度的提高 比如在复习 程序 ...
- 1. Two Sum (快速排序;有序数组的查找: 两个指针; 哈希表)
Given an array of integers, return indices of the two numbers such that they add up to a specific ta ...
- hash表/哈希表
https://blog.csdn.net/duan19920101/article/details/51579136 简单理解就是一个通过映射直接查找的表(散列表),用哈希函数将数据按照其存储特点进 ...
- 查找->动态查找表->二叉排序树
文字描述 二叉排序树的定义 又称二叉查找树,英文名为Binary Sort Tree, 简称BST.它是这样一棵树:或者是一棵空树:或者是具有下列性质的二叉树:(1)若它的左子树不空,则左子树上所有结 ...
- 查找->动态查找表->键树(无代码)
文字描述 键树定义 键树又叫数字查找树,它是一棵度大于或等于2的树,树中的每个结点中不是包含一个或几个关键字,而是只含有组成关键字的符号.例如,若关键字是数值,则结点中只包含一个数位:若关键字是单词, ...
- 查找->动态查找表->B+树(无代码)
文字描述 B+树定义 B+树是应文件系统所需而出的一种B-树的变型树.一棵m阶的B+树和m阶的B-树的差异在于: (1)有n棵子树的结点中含有n个关键字 (2)所有的叶子结点中包含了全部关键字的信息, ...
- 查找->动态查找表->平衡二叉树
文字描述 平衡二叉树(Balanced Binary Tree或Height-Balanced Tree) 因为是俄罗斯数学家G.M.Adel’son-Vel’skii和E.M.Landis在1962 ...
- 数据结构和算法(Golang实现)(26)查找算法-哈希表
哈希表:散列查找 一.线性查找 我们要通过一个键key来查找相应的值value.有一种最简单的方式,就是将键值对存放在链表里,然后遍历链表来查找是否存在key,存在则更新键对应的值,不存在则将键值对链 ...
- 哈希表工作原理 (并不特指Java中的HashTable)
1. 引言 哈希表(Hash Table)的应用近两年才在NOI中出现,作为一种高效的数据结构,它正在竞赛中发挥着越来越重要的作用. 哈希表最大的优点,就是把数据的存储和查找消耗的时 ...
随机推荐
- PaaS 应用引擎
这里主要是梳理一下应用引擎(XXXX App Engine),它一般被归类到PaaS领域.应用引擎即提供了各种编程语言开发的应用所需的一整套运行环境:它开箱即用,你只需部署应用的代码即可,无需前期的环 ...
- [NM]打开NetworkManager和wpa_supplicant的DEBUG接口
turn on the DEBUG log in /etc/NetworkManager/NetworkManager.conf and restart NetworkManager. [loggin ...
- github新建repositories后import已有code 随后同步更新
github上,可以forks别人已有的项目,而且同步更新合并也很方便,但如果是自己新建的项目,而导入的是别人的代码修改后,别人的又更新了,自己想获取他的更新,怎么办呢?其实很简单. # git cl ...
- Cisco DHCP Snooping + IPSG 功能实现
什么是DHCP? DHCP(Dynamic Host Configuration Protocol,动态主机配置协议)是一个局域网的网络协议,前身是BOOTP协议, 使用UDP协议工作,常用的2个端口 ...
- windows server 2008 R2 计划任务备份系统
实验环境拓扑图: 实验效果: Windows Server Backup 可以设置备份计划,但只能按日进行备份,不能设置按周或月进行备份.所以,需要使用到 windows Server 2008 R2 ...
- Springboot学习笔记(六)-配置化注入
前言 前面写过一个Springboot学习笔记(一)-线程池的简化及使用,发现有个缺陷,打个比方,我这个线程池写在一个公用服务中,各项参数都定死了,现在有两个服务要调用它,一个服务的线程数通常很多,而 ...
- 利用反射将Model转化为sql
public string GetInsertSqlByModel(Object o) { StringBuilder sbStart = new StringBuilder(); StringBui ...
- xampp+YII搭建网站
一.安装xampp xampp专为php开发设计,需要的apache,mysql,php已经自带了.特别提醒,请下载PHP版本高于5.4支持Yii2.0的xampp 二.配置环境变量 在系统的环境变量 ...
- 10享元模式Flyweight
一.什么是享元模式 Flyweight模式也叫享元模式,是构造型模式之 一,它通过与其他类似对象共享数据来减小内存 占用. 二.享元模式的结构 三.享元模式的角色和职责 抽象享元角色: 所有具体享元类 ...
- windows下特殊字符无法用来命名
原则上可以利用键盘输入的英文字母.符号.空格.中文等均可以作为合法字符,但由于以下字符由系统保留它用,因此不能用在文件命名中: : / \ ? * “ < > | 注: ...