(3) MySQL分区表使用方法
1. 确认MySQL服务器是否支持分区表
命令:
show plugins;

2. MySQL分区表的特点
- 在逻辑上为一个表,在物理上存储在多个文件中
HASH分区(HASH)
HASH分区的特点
- 根据MOD(分区键,分区数)的值把数据行存储到表的不同分区中
- 数据可以平均的分布在各个分区中
- HASH分区的键值必须是一个INT类型的值,或是通过函数可以转为INT类型
如何建立HASH分区表
以INT类型字段 customer_id为分区键
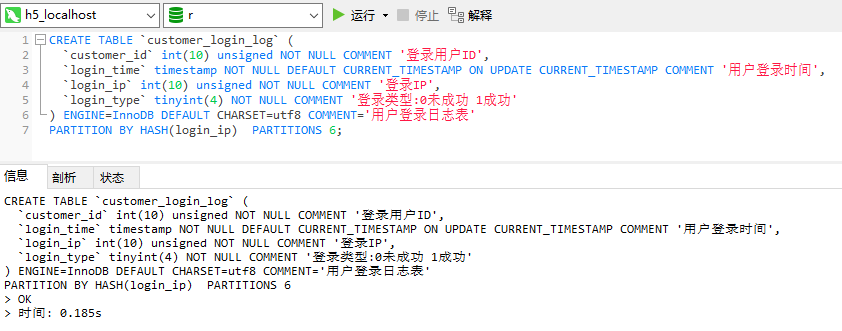
CREATE TABLE `customer_login_log` (
`customer_id` int(10) unsigned NOT NULL COMMENT '登录用户ID',
`login_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '用户登录时间',
`login_ip` int(10) unsigned NOT NULL COMMENT '登录IP',
`login_type` tinyint(4) NOT NULL COMMENT '登录类型:0未成功 1成功'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户登录日志表'
PARTITION BY HASH(customer_id) PARTITIONS 4;
以非INT类型字段 login_time 为分区键(需要先转换成INT类型)
CREATE TABLE `customer_login_log` (
`customer_id` int(10) unsigned NOT NULL COMMENT '登录用户ID',
`login_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '用户登录时间',
`login_ip` int(10) unsigned NOT NULL COMMENT '登录IP',
`login_type` tinyint(4) NOT NULL COMMENT '登录类型:0未成功 1成功'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户登录日志表'
PARTITION BY HASH(UNIX_TIMESTAMP(login_time)) PARTITIONS 4;
customer_login_log 表如果不分区,在物理磁盘上文件为
customer_login_log.frm # 存储表原数据信息
customer_login_log.ibd # Innodb数据文件
如果按上面的建HASH分区表,则有五个文件
customer_login_log.frm
customer_login_log#P#p0.ibd
customer_login_log#P#p1.ibd
customer_login_log#P#p2.ibd
customer_login_log#P#p3.ibd
演示

使用起来和不分区是一样的,看起来只有一个数据库,其实有多个分区文件,比如我们要插入一条数据,不需要指定分区,MySQL会自动帮我们处理

查询

范围分区(RANGE)
RANGE分区特点
- 根据分区键值的范围把数据行存储到表的不同分区中
- 多个分区的范围要连续,但是不能重叠
- 默认情况下使用VALUES LESS THAN属性,即每个分区不包括指定的那个值
如何建立RANGE分区

如果没有定义p3分区,当插入的customer_id大于29999时会报错,定义了则超过的数据都存入p3中
RANGE分区的适用场景
- 分区键为日期或是时间类型 (可以使得各个分区表的数据比较均衡,如果按上面的例子中以整型id为分区键,假如活跃用户集中在10000-19999之间,则p1中的数据量就会比其他分区的数据量大很多,这就失去了分区的意义;而且按时间类型分区,如果要按时间顺序进行数据的归档,则只需要对某一个分区进行归档就可以了)
- 所有查询中都包括分区键(避免跨分区查询)
- 定期按分区范围清理历史数据
LIST分区
LIST分区的特点
- 按分区键取值的列表进行分区
- 同范围分区一样,各分区的列表值不能重复
- 每一行数据必须能找到对应的分区列表,否则数据插入失败
如何建立LIST分区

如果插入一条login_type为10的数据行,则会报错
3. 如何为登录日志表(customer_login_log)分区
业务场景
- 用户每次登录都会记录customer_login_log日志
- 用户登录日志保存一年,1年后可以删除或者归档
登录日志表的分区类型及分区键
- 使用RANGE分区
- 以login_time为分区键
分区后的用户登录日志表
按年份分区存储,所以用YEAR函数进行了转化
CREATE TABLE `customer_login_log` (
`customer_id` int(10) unsigned NOT NULL COMMENT '登录用户ID',
`login_time` DATETIME NOT NULL COMMENT '用户登录时间',
`login_ip` int(10) unsigned NOT NULL COMMENT '登录IP',
`login_type` tinyint(4) NOT NULL COMMENT '登录类型:0未成功 1成功'
) ENGINE=InnoDB
PARTITION BY RANGE (YEAR(login_time))(
PARTITION p0 VALUES LESS THAN (2017),
PARTITION p1 VALUES LESS THAN (2018),
PARTITION p2 VALUES LESS THAN (2019)
)
插入并查询数据

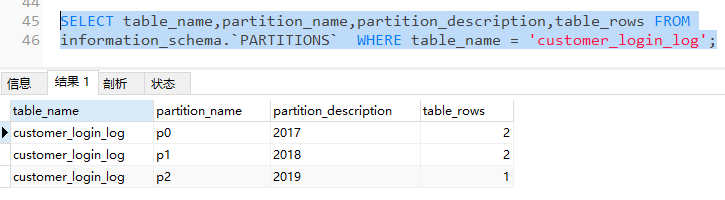
查询指定表中的分区数据情况
SELECT table_name,partition_name,partition_description,table_rows FROM
information_schema.`PARTITIONS` WHERE table_name = 'customer_login_log';
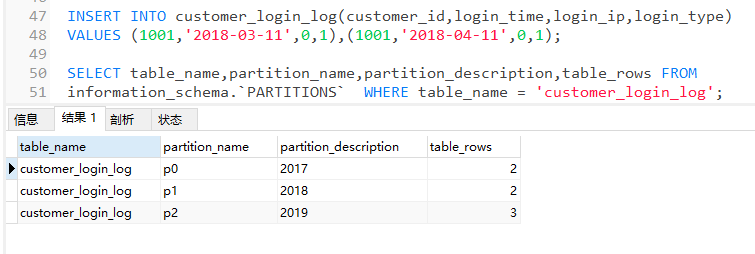
再插入2条18年的日志,会存入p2表中
之前说过建立分区表时,最好建立一个MAXVALUE的分区,这里之所以没有建立,是为了数据维护的方便,如果我们建立了MAXVALUE分区,很容易忽视一个问题,当我们2019年有的数据插入时,会自动存入那个MAXVALUE分区中,之后在做数据维护时会不方便,所以没有建立MAXVALUE分区
而是通过计划任务的方式,在每年年底的时候增加这个分区,比如我们现在在2018年年底,我们需要在日志表中为2019年建立日志分区,否则2019年的日志都会插入失败

我们可以通过下面语句
增加分区
ALTER TABLE customer_login_log ADD PARTITION (PARTITION p3 VALUES LESS THAN(2020))
增加分区,并插入数据

删除分区
假如我们现在要删除2016年到2017年间一年的数据,因为我们已经做了分区,所以只需要通过一条语句,删除p0分区即可
ALTER TABLE customer_login_log DROP PARTITION p0;
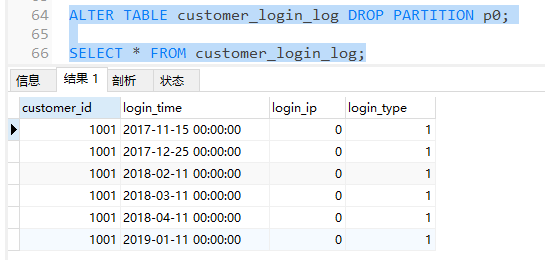
可以发现p0分区已被删除,且2016年的日志全部被清除了
归档分区历史数据
我们可能有另一种需求对数据进行归档
Mysql版本>=5.7,归档分区历史数据非常方便,提供了一个交换分区的方法
分区数据归档迁移条件:
- MySQL>=5.7
- 结构相同
- 归档到的数据表一定要是非分区表
- 非临时表;不能有外键约束
- 归档引擎要是:archive
建表并交换分区
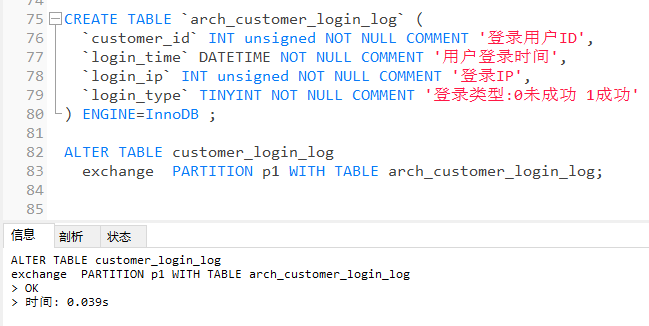
CREATE TABLE `arch_customer_login_log` (
`customer_id` INT unsigned NOT NULL COMMENT '登录用户ID',
`login_time` DATETIME NOT NULL COMMENT '用户登录时间',
`login_ip` INT unsigned NOT NULL COMMENT '登录IP',
`login_type` TINYINT NOT NULL COMMENT '登录类型:0未成功 1成功'
) ENGINE=InnoDB ;
ALTER TABLE customer_login_log
exchange PARTITION p1 WITH TABLE arch_customer_login_log;
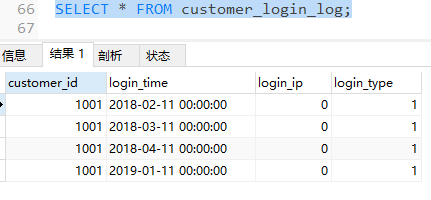
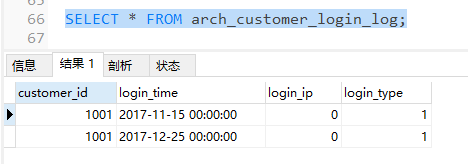
可以发现,原customer_login_log表中的2017年的数据(p1分区中的数据)已转移到了arch_customer_login_log表中,但是p1分区未删除,只是数据转移了,所以我们还需要执行DROP命令删除分区,以免有数据插入其中
将归档数据的存储引擎改为归档引擎
最后我们将归档数据的存储引擎改为归档引擎,命令为
ALTER TABLE customer_login_log ENGINE=ARCHIVE;
使用归档引擎的好处是:它比Innodb所占用的空间更少,但是归档引擎只能进行查询操作,不能进行写操作
4. 使用分区表的主要事项
- 结合业务场景选择分区键,避免跨分区查询
- 对分区表进行查询最好在WHERE从句中包含分区键
- 具有主键或唯一索引的表,主键或唯一索引必须是分区键的一部分(这也是为什么我们上面分区时去掉了主键登录日志id(login_id)的原因,不然就无法按照上面的按年份进行分区,所以分区表其实更适合在MyISAM引擎中)
关于MyISAM和Innodb的索引区别
1.关于自动增长
myisam引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。
innodb引擎的自动增长咧必须是索引,如果是组合索引也必须是组合索引的第一列。
2.关于主键
myisam允许没有任何索引和主键的表存在,
myisam的索引都是保存行的地址。
innodb引擎如果没有设定主键或者非空唯一索引,就会自动生成一个6字节的主键(用户不可见)
innodb的数据是主索引的一部分,附加索引保存的是主索引的值。
3.关于count()函数
myisam保存有表的总行数,如果select count(*) from table;会直接取出出该值
innodb没有保存表的总行数,如果使用select count(*) from table;就会遍历整个表,消耗相当大,但是在加了wehre 条件后,myisam和innodb处理的方式都一样。
4.全文索引
myisam支持 FULLTEXT类型的全文索引
innodb不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。(sphinx 是一个开源软件,提供多种语言的API接口,可以优化mysql的各种查询)
5.delete from table
使用这条命令时,innodb不会从新建立表,而是一条一条的删除数据,在innodb上如果要清空保存有大量数据的表,最 好不要使用这个命令。(推荐使用truncate table,不过需要用户有drop此表的权限)
6.索引保存位置
myisam的索引以表名+.MYI文件分别保存。
innodb的索引和数据一起保存在表空间里。
(3) MySQL分区表使用方法的更多相关文章
- MySQL分区表使用方法
原文:MySQL分区表使用方法 1. 确认MySQL服务器是否支持分区表 命令: show plugins; 2. MySQL分区表的特点 在逻辑上为一个表,在物理上存储在多个文件中 HASH分区(H ...
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 30多条mysql数据库优化方法【转】
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 数据切分——Mysql分区表的建立及性能分析
Mysql的安装方法可以参考: http://blog.csdn.net/jhq0113/article/details/43812895 Mysql分区表的介绍可以参考: http://blog.c ...
- 转载:30多条mysql数据库优化方法,千万级数据库记录查询轻松解决
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- 详解MySQL分区表
当数据库数据量涨到一定数量时,性能就成为我们不能不关注的问题,如何优化呢? 常用的方式不外乎那么几种: 1.分表,即把一个很大的表达数据分到几个表中,这样每个表数据都不多. 优点:提高并发量,减小锁的 ...
- 查看mysql数据库版本方法总结
当你接手某个mysql数据库管理时,首先你需要查看维护的mysql数据库版本:当开发人员问你mysql数据库版本时,而恰好你又遗忘了,那么此时也需要去查看mysql数据库的版本............ ...
- MySQL 分区表
转载自MySQL 分区表 今天统计数据的时候发现一张表使用了表分区,借此机会记录一下. 1. 什么是表分区? 表分区,是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分.从逻辑上看, ...
- Mysql --分区表的管理与维护
改变一个表的分区方案只需使用alter table 加 partition_options 子句就可以了.和创建分区表时的create table语句很像 创建表 CREATE TABLE trb3 ...
随机推荐
- 分布式系统理论--CAP理论、BASE理论
问题的提出 在计算机科学领域,分布式一致性是一个相当重要且被广泛探索与论证问题,首先来看三种业务场景. 1.火车站售票 假如说我们的终端用户是一位经常坐火车的旅行家,通常他是去车站的售票处购买车票,然 ...
- java实体转json忽略属性
1: import com.alibaba.fastjson.annotation.JSONField; fastjson 过滤指定字段 @JSONField(serialize=false)priv ...
- 函数 y=x^x的分析
关于函数 y=xx的分析: 由图像得,y在负无穷大到0图像处处不连续,故y的定义域为(0,正无穷大): 故该函数不就是y=e^(lnxx)吗? 1.定义域:我们变形一下,y=e^(xlnx),显然是0 ...
- mysql字符类型大小写敏感的讨论
mysql字符类型默认是不区分大小写的,即select * from t where name='AAA'与='aaa'没区别,以下是测试的例子 (root)); (root,,,,'BbB'); ( ...
- [漏洞分析]thinkphp 5.x全版本任意代码执行分析全记录
0x00 简介 2018年12月10日中午,thinkphp官方公众号发布了一个更新通知,包含了一个5.x系列所有版本存在被getshell的高风险漏洞. 吃完饭回来看到这个公告都傻眼了,整个tp5系 ...
- 基于URL的高层次Java网络编程
一致资源定位器URL URL(Uniform Resource Locator)是一致资源定位器的简称,它表示Internet上某一资源的地址.通过URL我们可以访问Internet上的各种网络资源, ...
- 10,EasyNetQ-发布确认
默认的AMQP发布不是事务性的,并且不能保证您的消息实际上会到达代理. AMQP指定了一个事务性发布,但是对于RabbitMQ来说,它非常慢,我们还没有通过EasyNetQ API支持. 对于高性能保 ...
- Orleans高级功能
一.Reentrant Grains二.请求上下文三.激活垃圾收集四.外部任务和Grains五.序列化六.代码生成七.在Silo内的应用程序引导八.拦截器九.取消令牌十.Powershell客户端十一 ...
- Metasploit AFP爆破模块afp_login
Metasploit AFP爆破模块afp_login AFP是苹果系统支持的文件服务.用户可以使用指定的账户名和密码进行远程文件管理.afp_login是一个AFP认证信息暴力破解模块.它支持对 ...
- 【nodeJS爬虫】前端爬虫系列
写这篇 blog 其实一开始我是拒绝的,因为爬虫爬的就是cnblog博客园.搞不好编辑看到了就把我的账号给封了:). 言归正传,前端同学可能向来对爬虫不是很感冒,觉得爬虫需要用偏后端的语言,诸如 ph ...