关于Mysql 的 ICP、MRR、BKA等特性
一、ICP( Index_Condition_Pushdown)
对 where 中过滤条件的处理,根据索引使用情况分成了三种:(何登成)index key, index filter, table filter
如果WHERE条件可以使用索引,MySQL 会把这部分过滤操作放到存储引擎层,存储引擎通过索引过滤,把满足的行从表中读取出。ICP能减少Server层访问存储引擎的次数和引擎层访问基表的次数。
- session级别设置:set optimizer_switch="index_condition_pushdown=on
对于InnoDB表,ICP只适用于辅助索引
当使用ICP优化时,执行计划的Extra列显示Using index condition提示
不支持主建索引的ICP(对于Innodb的聚集索引,完整的记录已经被读取到Innodb Buffer,此时使用ICP并不能降低IO操作)
当 SQL 使用覆盖索引时但只检索部分数据时,ICP 无法使用
ICP的加速效果取决于在存储引擎内通过ICP筛选掉的数据的比例
index_condition_pushdown会大大减少行锁的个数,如select for update, 因为行锁是在引擎层的
例如:
现在的索引
- show index from sm_performance_all;
- +--------------------+------------+-------------------------------+--------------+----------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
- | Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
- +--------------------+------------+-------------------------------+--------------+----------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
- | sm_performance_all | 0 | PRIMARY | 1 | id | A | 40527 | NULL | NULL | | BTREE | | |
- | sm_performance_all | 1 | FK_a9t29a4b2af1vfny1j2minc1x | 1 | company_id | A | 316 | NULL | NULL | YES | BTREE | | |
- | sm_performance_all | 1 | FK_n3ng4a5qju19fw8qy4uskp4g1 | 1 | bill_id | A | 21532 | NULL | NULL | YES | BTREE | | |
- | sm_performance_all | 1 | FK_eb13u3xwslt9t7wwuycg7vha6 | 1 | car_id | A | 16794 | NULL | NULL | YES | BTREE | | |
- | sm_performance_all | 1 | FK_2bfhskvklf6mdk557tc3yy3y1 | 1 | commission_entity_id | A | 177 | NULL | NULL | YES | BTREE | | |
- | sm_performance_all | 1 | FK_6fr5ib5iyjyu155dncmc48cwr | 1 | member_card_id | A | 34 | NULL | NULL | YES | BTREE | | |
- | sm_performance_all | 1 | FK_93p22vcog266wa82i44a6m18b | 1 | user_id | A | 483 | NULL | NULL | YES | BTREE | | |
- | sm_performance_all | 1 | FK_p6nc7l6ewnkcpm2y4o3wct81r | 1 | member_card_bill_id | A | 4 | NULL | NULL | YES | BTREE | | |
- | sm_performance_all | 1 | billId_userId_memberCarBillId | 1 | bill_id | A | 24194 | NULL | NULL | YES | BTREE | | |
- | sm_performance_all | 1 | billId_userId_memberCarBillId | 2 | user_id | A | 25688 | NULL | NULL | YES | BTREE | | |
- | sm_performance_all | 1 | billId_userId_memberCarBillId | 3 | member_card_bill_id | A | 25946 | NULL | NULL | YES | BTREE | | |
- +--------------------+------------+-------------------------------+--------------+----------------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
- 11 rows in set (0.00 sec)
现在的语句执行情况
- explain select * from sm_performance_all p where p.date_created>'2018-01-01' and p.date_created< '2018-02-01' and p.type=0;
- +----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
- +----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
- | 1 | SIMPLE | p | NULL | ALL | NULL | NULL | NULL | NULL | 40527 | 1.11 | Using where |
- +----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+-------------+
- 1 row in set, 1 warning (0.00 sec)
- 添加索引后
ALTER TABLE sm_performance_all add index date_created_type(date_created, type );
- explain select * from sm_performance_all p where p.date_created>'2018-01-01' and p.date_created< '2018-02-01' and p.type=0;
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+-----------------------+
- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+-----------------------+
- | 1 | SIMPLE | p | NULL | range | date_created_type | date_created_type | 6 | NULL | 1 | 10.00 | Using index condition |
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+-----------------------+
- 1 row in set, 1 warning (0.00 sec)
二、MRR(Multi-Range Read )
随机 IO 转化为顺序 IO 以降低查询过程中 IO 开销的一种手段,这对IO-bound类型的SQL语句性能带来极大的提升。
MRR can be used for InnoDB and MyISAM tables for index range scans and equi-join operations.
A portion of the index tuples are accumulated in a buffer.
The tuples in the buffer are sorted by their data row ID.
Data rows are accessed according to the sorted index tuple sequence.
上述的SQL语句需要根据辅助索引date_created_type进行查询,但是由于要求得到的是表中所有的列,因此需要回表进行读取。而这里就可能伴随着大量的随机I/O。这个过程如下图所示:
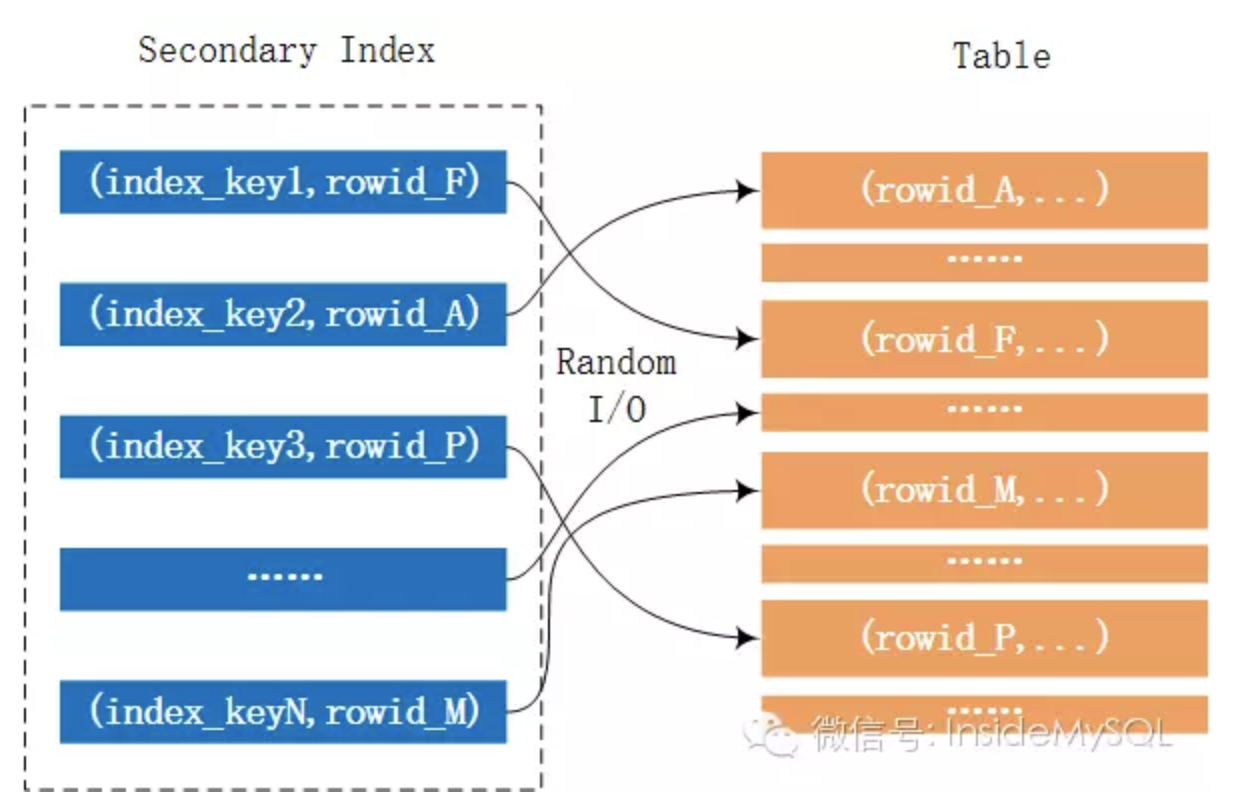
而MRR的优化在于,并不是每次通过辅助索引就回表去取记录,而是将其rowid给缓存起来,然后对rowid进行排序后,再去访问记录,这样就能将随机I/O转化为顺序I/O,从而大幅地提升性能。这个过程如下所示:
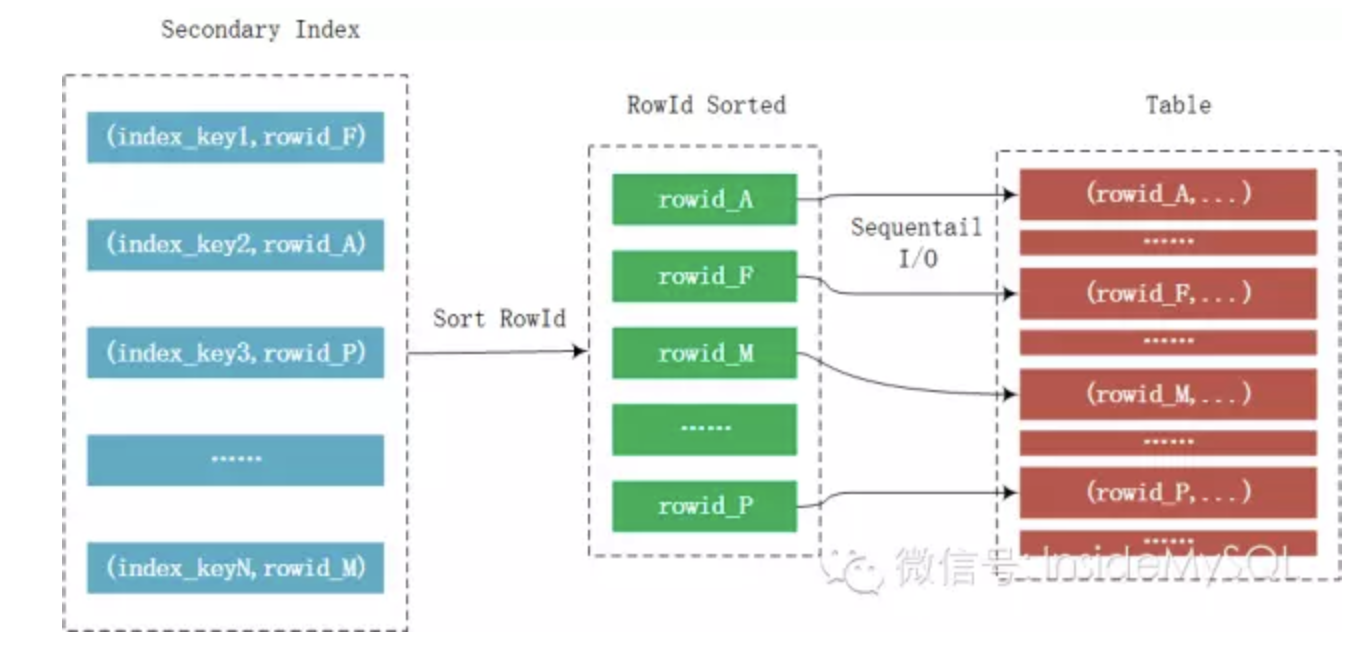
然而,在MySQL当前版本中,基于成本的算法过于保守,导致大部分情况下优化器都不会选择MRR特性。为了确保优化器使用mrr特性,请执行下面的SQL语句:
set optimizer_switch='mrr=on,mrr_cost_based=off';
读取全部字段时
- explain select * from sm_performance_all p where p.date_created>'2018-01-01' and p.date_created< '2018-02-01' and p.type=0;
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+----------------------------------+
- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+----------------------------------+
- | 1 | SIMPLE | p | NULL | range | date_created_type | date_created_type | 6 | NULL | 1 | 10.00 | Using index condition; Using MRR |
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+----------------------------------+
- 1 row in set, 1 warning (0.00 sec)
只读取部分字段时:
- 读取外键
- explain select car_id from sm_performance_all p where p.date_created>'2018-01-01' and p.date_created< '2018-02-01' and p.type=0;
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+----------------------------------+
- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+----------------------------------+
- | 1 | SIMPLE | p | NULL | range | date_created_type | date_created_type | 6 | NULL | 1 | 10.00 | Using index condition; Using MRR |
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+----------------------------------+
- 1 row in set, 1 warning (0.00 sec)
读取主键- explain select id from sm_performance_all p where p.date_created>'2018-01-01' and p.date_created< '2018-02-01' and p.type=0;
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+--------------------------+
- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+--------------------------+
- | 1 | SIMPLE | p | NULL | range | date_created_type | date_created_type | 6 | NULL | 1 | 10.00 | Using where; Using index |
- +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+--------------------------+
- 1 row in set, 1 warning (0.00 sec)
For MRR, a storage engine uses the value of the read_rnd_buffer_size system variable as a guideline for how much memory it can allocate for its buffer.
默认256KB
- show GLOBAL VARIABLES like '%buffer_size';
- +-------------------------+----------+
- | Variable_name | Value |
- +-------------------------+----------+
- | bulk_insert_buffer_size | 8388608 |
- | innodb_log_buffer_size | 16777216 |
- | innodb_sort_buffer_size | 1048576 |
- | join_buffer_size | 262144 |
- | key_buffer_size | 8388608 |
- | myisam_sort_buffer_size | 8388608 |
- | preload_buffer_size | 32768 |
- | read_buffer_size | 131072 |
- | read_rnd_buffer_size | 262144 |
- | sort_buffer_size | 262144 |
- +-------------------------+----------+
- 10 rows in set (0.00 sec)
三、表连接实现方式
3.1 Nested Loop Join
将驱动表/外部表的结果集作为循环基础数据,然后循环该结果集,每次获取一条数据作为下一个表的过滤条件查询数据,然后合并结果,获取结果集返回给客户端。Nested-Loop一次只将一行传入内层循环, 所以外层循环(的结果集)有多少行, 内存循环便要执行多少次,效率非常差。
- EXPLAIN SELECT * from sm_performance_all p LEFT JOIN sm_bill b ON p.bill_id > b.car_id where p.company_id>1024;
- +----+-------------+-------+------------+-------+------------------------------+------------------------------+---------+------+--------+----------+------------------------------------------------+
- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
- +----+-------------+-------+------------+-------+------------------------------+------------------------------+---------+------+--------+----------+------------------------------------------------+
- | 1 | SIMPLE | p | NULL | range | FK_a9t29a4b2af1vfny1j2minc1x | FK_a9t29a4b2af1vfny1j2minc1x | 9 | NULL | 20263 | 100.00 | Using index condition; Using MRR |
- | 1 | SIMPLE | b | NULL | ALL | car_id_idx | NULL | NULL | NULL | 738383 | 100.00 | Range checked for each record (index map: 0x2) |
- +----+-------------+-------+------------+-------+------------------------------+------------------------------+---------+------+--------+----------+------------------------------------------------+
- 2 rows in set, 1 warning (0.00 sec)
3.2 Block Nested-Loop Join
将外层循环的行/结果集存入join buffer, 内层循环的每一行与整个buffer中的记录做比较,从而减少内层循环的次数。主要用于当被join的表上无索引。
- CREATE TABLE t1 (a int PRIMARY KEY, b int);
- CREATE TABLE t2 (a int PRIMARY KEY, b int);
- INSERT INTO t1 VALUES (1,2), (2,1), (3,2), (4,3), (5,6), (6,5), (7,8), (8,7), (9,10);
- INSERT INTO t2 VALUES (3,0), (4,1), (6,4), (7,5);
- EXPLAIN
- SELECT * FROM t1 LEFT JOIN t2 ON t1.a = t2.a WHERE t2.b <= t1.a AND t1.a <= t1.b;
- +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
- | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
- +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
- | 1 | SIMPLE | t1 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 9 | 33.33 | Using where |
- | 1 | SIMPLE | t2 | NULL | ALL | PRIMARY | NULL | NULL | NULL | 4 | 25.00 | Using where; Using join buffer (Block Nested Loop) |
- +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
- 2 rows in set, 1 warning (0.00 sec)
3.3 Batched Key Access
当被join的表能够使用索引时,就先好顺序,然后再去检索被join的表。对这些行按照索引字段进行排序,因此减少了随机IO。如果被Join的表上没有索引,则使用老版本的BNL策略。
参考:
mysql reference : multi-range read
关于Mysql 的 ICP、MRR、BKA等特性的更多相关文章
- MySQL Index--BNL/ICP/MRR/BKA
MySQL关联查询算法: BNL(Block Nested-Loop) ICP(Index Condition Pushdown) MRR(Multi-Range Read) BKA(Batched ...
- MySQL--BNL/ICP/MRR/BKA
#======================================================##MySQL关联查询算法:BNL(Block Nested-Loop)ICP(Index ...
- MySQL · 特性分析 · 优化器 MRR & BKA【转】
MySQL · 特性分析 · 优化器 MRR & BKA 上一篇文章咱们对 ICP 进行了一次全面的分析,本篇文章小编继续为大家分析优化器的另外两个选项: MRR & batched_ ...
- MySQL 8.0.2复制新特性(翻译)
译者:知数堂星耀队 MySQL 8.0.2复制新特性 MySQL 8 正在变得原来越好,而且这也在我们MySQL复制研发团队引起了一阵热潮.我们一直致力于全面提升MySQL复制,通过引入新的和一些有趣 ...
- PostgreSQL 和 MySQL 在用途、好处、特性和特点上的异同
PostgreSQL 和 MySQL 在用途.好处.特性和特点上的异同. PostgreSQL 和 MySQL 是将数据组织成表的关系数据库.这些表可以根据每个表共有的数据链接或关联.关系数据库使您的 ...
- 【mysql】关于ICP、MRR、BKA等特性
一.Index Condition Pushdown(ICP) Index Condition Pushdown (ICP)是mysql使用索引从表中检索行数据的一种优化方式,从mysql5.6开始支 ...
- MySQL中有关icp mrr和bka的特性
文辉考我的问题,有关这三个的特性,如果在面试过程中,个人见解可以答以下 icp MyQL数据库会在取出索引的同时,判断是否进行WHERE条件过滤,也就是把WHERE的部分过滤操作放在存储引擎层,在某些 ...
- ICP、MRR、BKA等特性
一.Index Condition Pushdown(ICP) Index Condition Pushdown (ICP)是 mysql 使用索引从表中检索行数据的一种优化方式,从mysql5.6开 ...
- MRR,BKA,ICP相关
MRR Multi-Range Read,多范围读,5.6以上版本开始支持 工作原理&优化效果: 将查询到的辅助索引结果放在一个缓冲(read_rnd_buffer_size = 4M)中 将 ...
随机推荐
- Ogre2.1 Hlms与渲染流程
在我前面三篇说明Ogre2.x的文章里,第一篇大致说了下Hlms,第二篇说了下和OpenGL结合比较紧的渲染,本文用来说下Hlms如何影响渲染流程中,因为有些概念已经在前面二文里说过了,本文就不再提, ...
- Office 2007 打开时总是出现配置进度框
解决办法: cmd 打开控制台 输入命令:reg add HKCU\Software\Microsoft\Office\12.0\Word\Options /v NoReReg /t REG_DWOR ...
- 使用Three.js里的各种光源
1.three.js库提供的光源 three.js库提供了一些列光源,而且没种光源都有特定的行为和用途.这些光源包括: 光源名称/描述 AmbientLight(环境光)/这是一种基础光源,它的颜色会 ...
- 51 IP核查询
康芯的IP核 Oregano systems 公司的MC8051 IP CoreSynthesizeable VHDL Microcontroller IP-Core User Guide这个里面51 ...
- 写在开始前---web前后端对接
现阶段接口对接问题: 1.接口乱,不清晰明了,无文档或文档过期 2.接口和业务不匹配.不可用 3.前后端沟通,工程复杂化 4.不能深入了解业务 5.任务延期 注:前后端对业务深入了解,接口之间都是有联 ...
- twisted 学习笔记一:事件循环
from twisted.internet import reactor import time def printTime(): print "Current time is", ...
- ls --help 常用命令
$ ls --help Usage: ls [OPTION]... [FILE]... List information about the FILEs (the current directory ...
- 01List.ashx(班级列表动态页面)
01List.html <!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <he ...
- 这些简单实用的Word技巧,你get了吗
快速选中多个对象 如果需要将某些文本设置成相同的格式,我们不需要一个个的设置,只要选中多个文本然后一起设置就可以了. 单击开始——选择编辑——选择——选择格式相似的文本 快速清除所有格式 那么当我们不 ...
- log4j组件的用法(log4j1)
在实际的项目开发和维护中,日志是经常用到的一个内容.遇到问题的时候,经常需要通过日志去查出问题的所在并解决问题. 通常我们会用: System.out.println(xxx); 来打印运行中所需要的 ...