java高并发编程(一)
读马士兵java高并发编程,引用他的代码,做个记录。
一、分析下面程序输出:
/**
* 分析一下这个程序的输出
* @author mashibing
*/ package yxxy.c_005; public class T implements Runnable { private int count = 10; public synchronized void run() {
count--;
System.out.println(Thread.currentThread().getName() + " count = " + count);
} public static void main(String[] args) {
T t = new T();
for(int i=0; i<5; i++) {
new Thread(t, "THREAD" + i).start();
}
} }
THREAD0 count = 9
THREAD4 count = 8
THREAD1 count = 7
THREAD3 count = 6
THREAD2 count = 5
分析:
/**
* 对比上面一个小程序,分析一下这个程序的输出
* @author mashibing
*/ package yxxy.c_006; public class T implements Runnable { private int count = 10; public synchronized void run() {
count--;
System.out.println(Thread.currentThread().getName() + " count = " + count);
} public static void main(String[] args) { for(int i=0; i<5; i++) {
T t = new T();
new Thread(t, "THREAD" + i).start();
}
} }
THREAD0 count = 9
THREAD4 count = 9
THREAD3 count = 9
THREAD1 count = 9
THREAD2 count = 9
分析:
/**
* 同步和非同步方法是否可以同时调用?
* @author mashibing
*/ package yxxy.c_007; public class T { public synchronized void m1() {
System.out.println(Thread.currentThread().getName() + " m1 start...");
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " m1 end");
} public void m2() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " m2 ");
} public static void main(String[] args) {
T t = new T(); new Thread(()->t.m1(), "t1").start();
new Thread(()->t.m2(), "t2").start();
} }
t1 m1 start...
t2 m2
t1 m1 end
public static void main(String[] args) {
T t = new T();
new Thread(t::m1, "t1").start();
new Thread(t::m2, "t2").start();*/
}
public static void main(String[] args) {
T t = new T();
new Thread(new Runnable(){
@Override
public void run() {
t.m1();
}
}, "t1").start();
new Thread(new Runnable(){
@Override
public void run() {
t.m2();
}
}, "t2").start();
}
四、对业务写方法加锁,对业务读方法不加锁,容易产生脏读问题(dirtyRead)
/**
* 对业务写方法加锁
* 对业务读方法不加锁
* 容易产生脏读问题(dirtyRead)
*/ package yxxy.c_008; import java.util.concurrent.TimeUnit; public class Account {
String name;
double balance; public synchronized void set(String name, double balance) {
this.name = name; try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
} this.balance = balance;
} public double getBalance(String name) {
return this.balance;
} public static void main(String[] args) {
Account a = new Account();
new Thread(()->a.set("zhangsan", 100.0)).start(); try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
} System.out.println(a.getBalance("zhangsan")); try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
} System.out.println(a.getBalance("zhangsan"));
}
}
0.0
100.0
分析:
public synchronized double getBalance(String name) {
return this.balance;
}
五、一个同步方法可以调用另外一个同步方法:
/**
* 一个同步方法可以调用另外一个同步方法,一个线程已经拥有某个对象的锁,再次申请的时候仍然会得到该对象的锁.
* 也就是说synchronized获得的锁是可重入的.(可重入的意思就是获得锁之后还可以再获得一遍)
* @author mashibing
*/
package yxxy.c_009; import java.util.concurrent.TimeUnit; public class T {
synchronized void m1() {
System.out.println("m1 start");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
m2();
} synchronized void m2() {
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("m2");
}
}
分析:
六、重入锁的另外一种情形,继承中子类的同步方法调用父类的同步方法
/**
* 一个同步方法可以调用另外一个同步方法,一个线程已经拥有某个对象的锁,再次申请的时候仍然会得到该对象的锁.
* 也就是说synchronized获得的锁是可重入的
* 这里是继承中有可能发生的情形,子类调用父类的同步方法
* @author mashibing
*/
package yxxy.c_010; import java.util.concurrent.TimeUnit; public class T {
synchronized void m() {
System.out.println("m start");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("m end");
} public static void main(String[] args) {
new TT().m();
} } class TT extends T {
@Override
synchronized void m() {
System.out.println("child m start");
super.m();
System.out.println("child m end");
}
}
child m start
m start
m end
child m end
七、synchronized同步方法如果遇到异常,锁就会被释放
/**
* 程序在执行过程中,如果出现异常,默认情况锁会被释放
* 所以,在并发处理的过程中,有异常要多加小心,不然可能会发生不一致的情况。
* 比如,在一个web app处理过程中,多个servlet线程共同访问同一个资源,这时如果异常处理不合适,
* 在第一个线程中抛出异常,其他线程就会进入同步代码区,有可能会访问到异常产生时的数据。
* 因此要非常小心的处理同步业务逻辑中的异常
* @author mashibing
*/
package yxxy.c_011; import java.util.concurrent.TimeUnit; public class T {
int count = 0;
synchronized void m() {
System.out.println(Thread.currentThread().getName() + " start");
while(true) {
count ++;
System.out.println(Thread.currentThread().getName() + " count = " + count);
try {
TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) {
e.printStackTrace();
} if(count == 5) {
int i = 1/0; //此处抛出异常,锁将被释放,要想不被释放,可以在这里进行catch,然后让循环继续
}
}
} public static void main(String[] args) {
T t = new T(); new Thread(()->t.m(), "t1").start(); try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
} new Thread(()->t.m(), "t2").start();
} }
t1 start
t1 count = 1
t1 count = 2
t1 count = 3
t1 count = 4
t1 count = 5
t2 start
t2 count = 6
Exception in thread "t1" java.lang.ArithmeticException: / by zero
at yxxy.c_011.T.m(T.java:28)
at yxxy.c_011.T.lambda$0(T.java:36)
at java.lang.Thread.run(Thread.java:745)
t2 count = 7
t2 count = 8
t2 count = 9
/**
* 程序在执行过程中,如果出现异常,默认情况锁会被释放
* 所以,在并发处理的过程中,有异常要多加小心,不然可能会发生不一致的情况。
* 比如,在一个web app处理过程中,多个servlet线程共同访问同一个资源,这时如果异常处理不合适,
* 在第一个线程中抛出异常,其他线程就会进入同步代码区,有可能会访问到异常产生时的数据。
* 因此要非常小心的处理同步业务逻辑中的异常
* @author mashibing
*/
package yxxy.c_011; import java.util.concurrent.TimeUnit; public class T {
int count = 0;
synchronized void m() {
System.out.println(Thread.currentThread().getName() + " start");
while(true) {
count ++;
System.out.println(Thread.currentThread().getName() + " count = " + count);
try {
TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) {
e.printStackTrace();
} if(count == 5) {
try{
int i = 1/0; //此处抛出异常,锁将被释放,要想不被释放,可以在这里进行catch,然后让循环继续
}catch(Exception e){
System.out.println(e.getMessage());
}
}
}
} public static void main(String[] args) {
T t = new T(); new Thread(()->t.m(), "t1").start(); try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
} new Thread(()->t.m(), "t2").start();
} }
t1 start
t1 count = 1
t1 count = 2
t1 count = 3
t1 count = 4
t1 count = 5
/ by zero
t1 count = 6
t1 count = 7
t1 count = 8
t1 count = 9
t1 count = 10
t1 count = 11
t1 count = 12
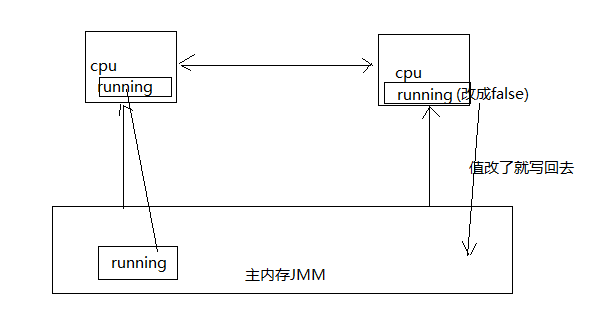
八、volatile关键字
/**
* volatile 关键字,使一个变量在多个线程间可见
* A B线程都用到一个变量,java默认是A线程中保留一份copy,这样如果B线程修改了该变量,则A线程未必知道
* 使用volatile关键字,会让所有线程都会读到变量的修改值
*
* 在下面的代码中,running是存在于堆内存的t对象中
* 当线程t1开始运行的时候,会把running值从内存中读到t1线程的工作区,在运行过程中直接使用这个copy,并不会每次都去
* 读取堆内存,这样,当主线程修改running的值之后,t1线程感知不到,所以不会停止运行
*
* 使用volatile,将会强制所有线程都去堆内存中读取running的值
*
* 可以阅读这篇文章进行更深入的理解
* http://www.cnblogs.com/nexiyi/p/java_memory_model_and_thread.html
*
* volatile并不能保证多个线程共同修改running变量时所带来的不一致问题,也就是说volatile不能替代synchronized
* @author mashibing
*/
package yxxy.c_012; import java.util.concurrent.TimeUnit; public class T {
volatile boolean running = true; //对比一下有无volatile的情况下,整个程序运行结果的区别
void m() {
System.out.println("m start");
while(running) {
}
System.out.println("m end!");
} public static void main(String[] args) {
T t = new T(); new Thread(t::m, "t1").start(); try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
} t.running = false;
} }
分析:
图:
九、volatile并不能保证多个线程共同修改running变量时所带来的不一致问题,也就是说volatile不能替代synchronized
/**
* volatile并不能保证多个线程共同修改running变量时所带来的不一致问题,也就是说volatile不能替代synchronized
* 运行下面的程序,并分析结果
* @author mashibing
*/
package yxxy.c_013; import java.util.ArrayList;
import java.util.List; public class T {
volatile int count = 0;
void m() {
for(int i=0; i<10000; i++) count++;
} public static void main(String[] args) {
T t = new T(); List<Thread> threads = new ArrayList<Thread>(); for(int i=0; i<10; i++) {
threads.add(new Thread(t::m, "thread-"+i));
} threads.forEach((o)->o.start()); threads.forEach((o)->{
try {
o.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}); System.out.println(t.count); } }
volatile和synchronized区别?
/**
* 对比上一个程序,可以用synchronized解决,synchronized可以保证可见性和原子性,volatile只能保证可见性
* @author mashibing
*/
package yxxy.c_014; import java.util.ArrayList;
import java.util.List; public class T {
int count = 0;
synchronized void m() {
for (int i = 0; i < 10000; i++) count++;
} public static void main(String[] args) {
T t = new T(); List<Thread> threads = new ArrayList<Thread>(); for (int i = 0; i < 10; i++) {
threads.add(new Thread(t::m, "thread-" + i));
} threads.forEach((o) -> o.start()); threads.forEach((o) -> {
try {
o.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}); System.out.println(t.count);
}
}
运行结果:100000
十一、使用AtomXXX类
/**
* 解决同样的问题的更高效的方法,使用AtomXXX类
* AtomXXX类本身方法都是原子性的,但不能保证多个方法连续调用是原子性的
* @author mashibing
*/
package yxxy.c_015; import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger; public class T {
AtomicInteger count = new AtomicInteger(0); void m() {
for (int i = 0; i < 10000; i++)
count.incrementAndGet(); //count++
} public static void main(String[] args) {
T t = new T(); List<Thread> threads = new ArrayList<Thread>(); for (int i = 0; i < 10; i++) {
threads.add(new Thread(t::m, "thread-" + i));
} threads.forEach((o) -> o.start()); threads.forEach((o) -> {
try {
o.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}); System.out.println(t.count);
}
}
运行结果:100000
/**
* synchronized优化
* 同步代码块中的语句越少越好
* 比较m1和m2
* @author mashibing
*/
package yxxy.c_016; import java.util.concurrent.TimeUnit; public class T { int count = 0; synchronized void m1() {
//do sth need not sync
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
//业务逻辑中只有下面这句需要sync,这时不应该给整个方法上锁
count ++; //do sth need not sync
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
} void m2() {
//do sth need not sync
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
//业务逻辑中只有下面这句需要sync,这时不应该给整个方法上锁
//采用细粒度的锁,可以使线程争用时间变短,从而提高效率
synchronized(this) {
count ++;
}
//do sth need not sync
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
分析:
/**
* 锁定某对象o,如果o的属性发生改变,不影响锁的使用
* 但是如果o变成另外一个对象,则锁定的对象发生改变
* 应该避免将锁定对象的引用变成另外的对象
* @author mashibing
*/
package yxxy.c_017; import java.util.concurrent.TimeUnit; public class T {
Object o = new Object(); void m() {
synchronized(o) {
while(true) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}
}
} public static void main(String[] args) {
T t = new T();
//启动第一个线程
new Thread(t::m, "t1").start(); try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
//创建第二个线程
Thread t2 = new Thread(t::m, "t2"); t.o = new Object(); //锁对象发生改变,所以t2线程得以执行,如果注释掉这句话,线程2将永远得不到执行机会 t2.start();
}
}
运行结果:
t1
t1
t1
t2
t1
t2
t1
t2
t1
t2
t1
t2
t1
t2
t1
t2
t1
t2
t1
...
分析:
/**
* 不要以字符串常量作为锁定对象
* 在下面的例子中,m1和m2其实锁定的是同一个对象
* 这种情况还会发生比较诡异的现象,比如你用到了一个类库,在该类库中代码锁定了字符串“Hello”,
* 但是你读不到源码,所以你在自己的代码中也锁定了"Hello",这时候就有可能发生非常诡异的死锁阻塞,
* 因为你的程序和你用到的类库不经意间使用了同一把锁
*
* jetty
*
* @author mashibing
*/
package yxxy.c_018; public class T { String s1 = "Hello";
String s2 = "Hello"; void m1() {
synchronized(s1) { }
} void m2() {
synchronized(s2) { }
}
}
java高并发编程(一)的更多相关文章
- [ 高并发]Java高并发编程系列第二篇--线程同步
高并发,听起来高大上的一个词汇,在身处于互联网潮的社会大趋势下,高并发赋予了更多的传奇色彩.首先,我们可以看到很多招聘中,会提到有高并发项目者优先.高并发,意味着,你的前雇主,有很大的业务层面的需求, ...
- 关于Java高并发编程你需要知道的“升段攻略”
关于Java高并发编程你需要知道的"升段攻略" 基础 Thread对象调用start()方法包含的步骤 通过jvm告诉操作系统创建Thread 操作系统开辟内存并使用Windows ...
- Java高并发编程基础三大利器之CountDownLatch
引言 上一篇文章我们介绍了AQS的信号量Semaphore<Java高并发编程基础三大利器之Semaphore>,接下来应该轮到CountDownLatch了. 什么是CountDownL ...
- java高并发编程(三)
java高并发主要有三块知识点: synchronizer:同步器,在多个线程之间互相之间怎么进行通讯,同步等: 同步容器:jdk提供了同步性的容器,比如concurrentMap,concurren ...
- java高并发编程(五)线程池
摘自马士兵java并发编程 一.认识Executor.ExecutorService.Callable.Executors /** * 认识Executor */ package yxxy.c_026 ...
- java高并发编程(四)高并发的一些容器
摘抄自马士兵java并发视频课程: 一.需求背景: 有N张火车票,每张票都有一个编号,同时有10个窗口对外售票, 请写一个模拟程序. 分析下面的程序可能会产生哪些问题?重复销售?超量销售? /** * ...
- java高并发编程(二)
马士兵java并发编程的代码,照抄过来,做个记录. 一.分析下面面试题 /** * 曾经的面试题:(淘宝?) * 实现一个容器,提供两个方法,add,size * 写两个线程,线程1添加10个元素到容 ...
- [高并发]Java高并发编程系列开山篇--线程实现
Java是最早开始有并发的语言之一,再过去传统多任务的模式下,人们发现很难解决一些更为复杂的问题,这个时候我们就有了并发. 引用 多线程比多任务更加有挑战.多线程是在同一个程序内部并行执行,因此会对相 ...
- java高并发编程基础之AQS
引言 曾经有一道比较比较经典的面试题"你能够说说java的并发包下面有哪些常见的类?"大多数人应该都可以说出 CountDownLatch.CyclicBarrier.Sempah ...
随机推荐
- 各种浏览器兼容trim()的方法
一.利用while方法解决 function trim(str) { while (str[0] == ' ') { str = str.slice(1); } while (str[str.leng ...
- java-冒泡排序、选择排序、二分查找
1.冒泡排序 public void bubbleSort(int[] arr) { for (int i = 0; i < arr.length - 1; i++) { //外循环只需要比较a ...
- random(随机模块)
程序中有很多地方需要用到随机字符,比如登录网站的随机验证码,通过random模块可以很容易生成随机字符串 >>> random.randrange(1,10) #返回1-10之间的一 ...
- 20165313 《Java程序设计》第五周学习总结
教材学习总结 下面是我认为的重点,不足之处还请谅解: 1内部类:在一个类中定义另一个类:外嵌类:包含内部类的类. 2内部类的类体中不能声明类变量和类方法:外嵌类的类体中可以用内部类声明对象. 3非内部 ...
- hdu2886 Lou 1 Zhuang 数学/快速幂
All members of Hulafly love playing the famous network game called 'Lou 1 Zhuang' so much that Super ...
- oracle重做日志文件硬盘坏掉解决方法
rman target/ list backup; list backup summary; 删除数据库数据文件夹下的log日志,例如/u01/app/oracle/oradata/ORCL下的所有后 ...
- js面向对象编程 ---- 系列教程
原 js面向对象编程:数据的缓存 原 js面向对象编程:如何检测对象类型 原 js面向对象编程:if中可以使用那些作为判断条件呢? 原 js面向对象编程:this到底代表什么?第二篇 原 js面向对象 ...
- 实现一个函数,可以左旋字符串中的k个字符
ABCD左旋一个字符得到BCDAABCD左旋两个字符得到CDAB ABCD BACD BCAD BCDA CBDA CDBA CDAB 发现规律: 如果左旋一个字符则可以将第一个字符依次与后面的字符交 ...
- ML(4)——逻辑回归
Logistic Regression虽然名字里带“回归”,但是它实际上是一种分类方法,“逻辑”是Logistic的音译,和真正的逻辑没有任何关系. 模型 线性模型 由于逻辑回归是一种分类方法,所以我 ...
- Oracle11g 密码延迟认证导致library cache lock的情况分析
在 Oracle 11g 中,为了提升安全性,Oracle 引入了『密码延迟验证』的新特性.这个特性的作用是,如果用户输入了错误的密码尝试登录,那么随着登录错误次数的增加,每次登录前验证的时间也会增加 ...