[Python数据挖掘]第8章、中医证型关联规则挖掘
一、背景和挖掘目标


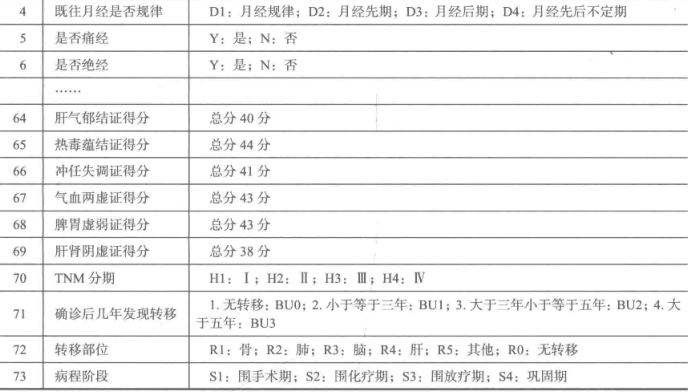

二、分析方法与过程

1、数据获取



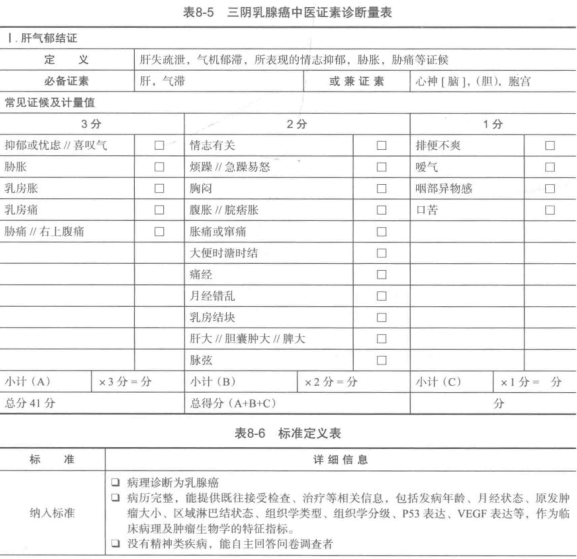

2、数据预处理
1.筛选有效问卷(根据表8-6的标准)
共发放1253份问卷,其中有效问卷数为930
2.属性规约
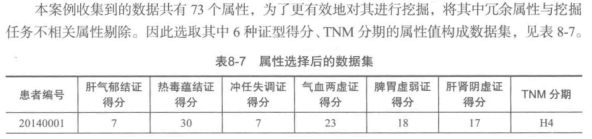
3.数据变换

'''
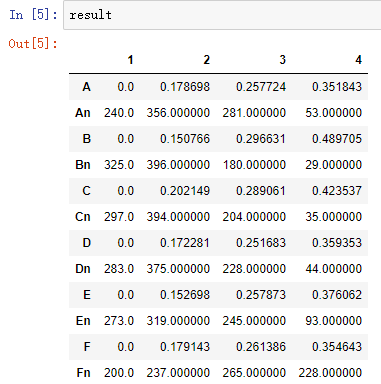
聚类离散化,最后的result的格式为:
1 2 3 4
A 0 0.178698 0.257724 0.351843
An 240 356.000000 281.000000 53.000000
即(0, 0.178698]有240个,(0.178698, 0.257724]有356个,依此类推。
'''
from __future__ import print_function
import pandas as pd
from sklearn.cluster import KMeans #导入K均值聚类算法 typelabel ={u'肝气郁结证型系数':'A', u'热毒蕴结证型系数':'B', u'冲任失调证型系数':'C', u'气血两虚证型系数':'D', u'脾胃虚弱证型系数':'E', u'肝肾阴虚证型系数':'F'}
k = 4 #需要进行的聚类类别数 #读取数据并进行聚类分析
data = pd.read_excel('data/data.xls') #读取数据
keys = list(typelabel.keys())
result = pd.DataFrame() if __name__ == '__main__': #判断是否主窗口运行,如果是将代码保存为.py后运行,则需要这句,如果直接复制到命令窗口运行,则不需要这句。
for i in range(len(keys)):
#调用k-means算法,进行聚类离散化
print(u'正在进行“%s”的聚类...' % keys[i])
kmodel = KMeans(n_clusters = k, n_jobs = 4) #n_jobs是并行数,一般等于CPU数较好
kmodel.fit(data[[keys[i]]].as_matrix()) #训练模型 r1 = pd.DataFrame(kmodel.cluster_centers_, columns = [typelabel[keys[i]]]) #聚类中心
r2 = pd.Series(kmodel.labels_).value_counts() #分类统计
r2 = pd.DataFrame(r2, columns = [typelabel[keys[i]]+'n']) #转为DataFrame,记录各个类别的数目
r = pd.concat([r1, r2], axis = 1).sort_values(typelabel[keys[i]]) #匹配聚类中心和类别数目
r.index = [1, 2, 3, 4] r[typelabel[keys[i]]] = pd.rolling_mean(r[typelabel[keys[i]]], 2) #rolling_mean()用来计算相邻2列的均值,以此作为边界点。
r[typelabel[keys[i]]][1] = 0.0 #这两句代码将原来的聚类中心改为边界点。
result = result.append(r.T) result.to_excel('tmp/data_processed.xls')
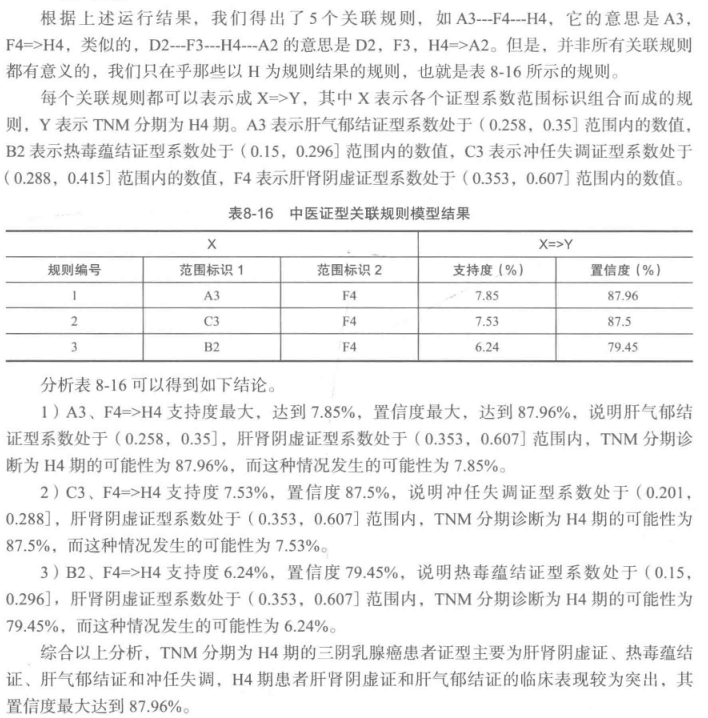
3、模型构建

首先准备apriori.py,代码没看懂,不过可以直接调用
#apriori代码
from __future__ import print_function
import pandas as pd #自定义连接函数,用于实现L_{k-1}到C_k的连接
def connect_string(x, ms):
x = list(map(lambda i:sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i,len(x)):
if x[i][:l-1] == x[j][:l-1] and x[i][l-1] != x[j][l-1]:
r.append(x[i][:l-1]+sorted([x[j][l-1],x[i][l-1]]))
return r #寻找关联规则的函数
def find_rule(d, support, confidence, ms = u'--'):
result = pd.DataFrame(index=['support', 'confidence']) #定义输出结果 support_series = 1.0*d.sum()/len(d) #支持度序列
column = list(support_series[support_series > support].index) #初步根据支持度筛选
k = 0 while len(column) > 1:
k = k+1
print(u'\n正在进行第%s次搜索...' %k)
column = connect_string(column, ms)
print(u'数目:%s...' %len(column))
sf = lambda i: d[i].prod(axis=1, numeric_only = True) #新一批支持度的计算函数 #创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf,column)), index = [ms.join(i) for i in column]).T support_series_2 = 1.0*d_2[[ms.join(i) for i in column]].sum()/len(d) #计算连接后的支持度
column = list(support_series_2[support_series_2 > support].index) #新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = [] for i in column: #遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j]+i[j+1:]+i[j:j+1]) cofidence_series = pd.Series(index=[ms.join(i) for i in column2]) #定义置信度序列 for i in column2: #计算置信度序列
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))]/support_series[ms.join(i[:len(i)-1])] for i in cofidence_series[cofidence_series > confidence].index: #置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))] result = result.T.sort_values(['confidence','support'], ascending = False) #结果整理,输出
print(u'\n结果为:')
print(result)
return result
from __future__ import print_function
import pandas as pd
from apriori import * #导入自行编写的apriori函数
import time #导入时间库用来计算用时 data = pd.read_csv('data/apriori.txt', header = None, dtype = object) #读取数据 start = time.clock() #计时开始
print(u'\n转换原始数据至0-1矩阵...')
ct = lambda x : pd.Series(1, index = x[pd.notnull(x)]) #转换0-1矩阵的过渡函数
b = map(ct, data.as_matrix()) #用map方式执行
data = pd.DataFrame(list(b)).fillna(0) #实现矩阵转换,空值用0填充
end = time.clock() #计时结束
print(u'\n转换完毕,用时:%0.2f秒' %(end-start))
del b #删除中间变量b,节省内存 support = 0.06 #最小支持度
confidence = 0.75 #最小置信度
ms = '---' #连接符,默认'--',用来区分不同元素,如A--B。需要保证原始表格中不含有该字符 start = time.clock() #计时开始
print(u'\n开始搜索关联规则...')
find_rule(data, support, confidence, ms)
end = time.clock() #计时结束
print(u'\n搜索完成,用时:%0.2f秒' %(end-start))

[Python数据挖掘]第8章、中医证型关联规则挖掘的更多相关文章
- [Python数据挖掘]第4章、数据预处理
数据预处理主要包括数据清洗.数据集成.数据变换和数据规约,处理过程如图所示. 一.数据清洗 1.缺失值处理:删除.插补.不处理 ## 拉格朗日插值代码(使用缺失值前后各5个未缺失的数据建模) impo ...
- [Python数据挖掘]第6章、电力窃漏电用户自动识别
一.背景与挖掘目标 相关背景自查 二.分析方法与过程 1.EDA(探索性数据分析) 1.分布分析 2.周期性分析 2.数据预处理 1.数据清洗 过滤非居民用电数据,过滤节假日用电数据(节假日用电量明显 ...
- [Python数据挖掘]第7章、航空公司客户价值分析
一.背景和挖掘目标 二.分析方法与过程 客户价值识别最常用的是RFM模型(最近消费时间间隔Recency,消费频率Frequency,消费金额Monetary) 1.EDA(探索性数据分析) #对数据 ...
- [Python数据挖掘]第3章、数据探索
1.缺失值处理:删除.插补.不处理 2.离群点分析:简单统计量分析.3σ原则(数据服从正态分布).箱型图(最好用) 离群点(异常值)定义为小于QL-1.5IQR或大于Qu+1.5IQR import ...
- [Python数据挖掘]第2章、Python数据分析简介
<Python数据分析与挖掘实战>的数据和代码,可从“泰迪杯”竞赛网站(http://www.tipdm.org/tj/661.jhtml)下载获得 1.Python数据结构 2.Nump ...
- [Python数据挖掘]第5章、挖掘建模(下)
四.关联规则 Apriori算法代码(被调函数部分没怎么看懂) from __future__ import print_function import pandas as pd #自定义连接函数,用 ...
- [Python数据挖掘]第5章、挖掘建模(上)
一.分类和回归 回归分析研究的范围大致如下: 1.逻辑回归 #逻辑回归 自动建模 import pandas as pd from sklearn.linear_model import Logist ...
- 【机器学习实战】第8章 预测数值型数据:回归(Regression)
第8章 预测数值型数据:回归 <script type="text/javascript" src="http://cdn.mathjax.org/mathjax/ ...
- 进击的Python【第十七章】:jQuery的基本应用
进击的Python[第十七章]:jQuery的基本应用
随机推荐
- python经常使用的十进制、16进制、字符串、字节串之间的转换(长期更新帖)
进行协议解析时.总是会遇到各种各样的数据转换的问题,从二进制到十进制,从字节串到整数等等 废话不多上.直接上样例 整数之间的进制转换: 10进制转16进制: hex(16) ==> 0x10 ...
- Windows 主机名映射地址
在开发中大数据集群中我们自己的电脑主机名映射不到集群的主机名下面我们就去修改自己电脑 主机名映射地址 c/Windows/System32/drivers/etc/host 文件将主机名和IP地址 ...
- Python读取xlsx翻译文案
首先安装Python,然后安装模块 //查找模块(非必须) pip search xlrd //安装模块 pip install xlrd 由于输出要是utf-8所以需要设置默认环境为utf-8 # ...
- 记一次mariadb升级故障
由于做mariadb集群,将版本从自带的5.5升级到10.0.3,升级成功后发现起不来 查journal log,只有一行warning can’t create test file /var/lib ...
- jar包通过exe4j打包成exe可执行文件
https://blog.csdn.net/jia611/article/details/42060945 参照此文即可,注意,我的是maven打包成的jar,选择maincalss时,需要选择jar ...
- IntelliJ IDEA 指定Java编译版本
在IntelliJ IDEA 15中使用Maven时,IDEA将默认的编译版本.源码版本设置为jdk5.编译项目的时候出现警告:”Warning:Java: 源值1.5已过时, 将在未来所有发行版中删 ...
- VUE-006-通过路由 router.push 传递 params 参数(路由 name 识别,请求链接不显示)
在前端页面表单列表修改时,经常需要在页面切换的时候,传递需要修改的表单内容,通常可通过路由进行表单参数的传递. 首先,配置页面跳转路由.在 router/index.js 中配置相应的页面跳转路由,如 ...
- python NLTK安装
stanford nltk在python中如何安装使用一直都很神秘,看了一些帖子感觉讳莫如深.研究了几天,参考<nlp汉语自然语言处理原理与实践>,发现方法如下: 1.安装JAVA 8+环 ...
- pymysql连接数据库报错:'NoneType' object has no attribute 'encoding'
直接写 utf8 即可.
- vs code代码对齐快捷键
vscode缩进快捷键: 选中文本: Ctrl + [ 和 Ctrl + ] 实现文本的向左移动或者向右移动: vscode代码对齐快捷键: 选中文本: Shift + ...