全文检索-Elasticsearch (一) 安装与基础概念
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口
Elasticsearch由java开发,所以在搭建时,需先安装java JDK
几个基本概念
- 索引(Index)
一个索引就是含有相似结构或性质特性的文档的集合,例如用户信息数据可以作为一个索引,文章信息也可应作为另一个索引。
- 文档(Document)
文档是索引的基本单元,可以理解成关系数据库表中的一条记录,包含了一组属性信息,同时包含一个唯一标识这一组属性值的ID,通过该ID可以更新一个文档,也可以删除一个文档。
- 分片(Shards)和副本(Replicas)
一个索引进行分割,分成多个片段,每一个片段称为一个分片,这样划分可以很好地管理索引,跨节点存储, 每个分片本身是一个全功能的完全独立的“索引”,它可以部署在集群中的任何节点;副本是为了保证一个分片的可用性,冗余复制存储,当一个分片对应的数据无法读取时,可以读取其副本,正常提供搜索服务。
副本根据官方文档有以下两个重要作用
- 高可用。它提供了高可用来以防分片或节点宕机。为此,一个非常重要的注意点是绝对不要将一个分片的拷贝放在跟这个分片相同的机器上。
- 高并发。它允许你的分片可以提供超出自身吞吐量的搜索服务,搜索行为可以在分片所有的副本中并行执行。
- 集群(cluster)
一个集群是由一个或多个节点(服务器)组成的,通过所有的节点一起保存你的全部数据并且提供联合索引和搜索功能的节点集合。每个集群有一个唯一的名称标识,默认是“elasticsearch”。这个名称非常重要,因为一个节点(Node)只有设置了这个名称才能加入集群,成为集群的一部分。
- 节点(Node)
一个节点是一个单一的服务器,是集群的一部分,存储数据,并且参与集群的索引和搜索功能。跟集群一样,节点在启动时也会被分配一个唯一的标识名称,这个名称默认是一个随机的UUID(Universally Unique IDentifier)。如果你不想用默认的名称,你可以自己定义节点的名称。这个名称对于管理集群节点,识别哪台服务器对应集群中的哪个节点有重要的作用。
安装-搭建集群
准备三台服务器搭建三个集群节点:
192.168.0.101
192.168.0.102
192.168.0.103
之后在官网下载ES,分别为三台服务器装上Elasticsearch
对于windows服务器,在官网有两种格式下载: ZIP和MSI,可以任选
- ZIP格式安装:
下载解压后,直接在bin文件中执行elasticsearch.bat即可运行Elasticsearch,
或是执行elasticsearch-service.bat安装成服务即可
- MSI格式安装:
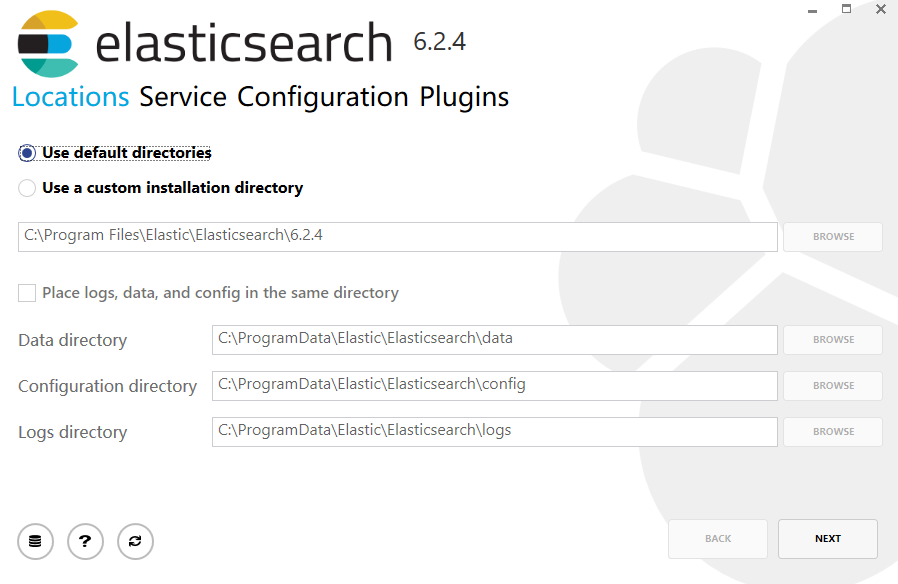
1.运行elasticsearch-6.2.4.msi;出现如图以下界面,默认目录或是选择目录安装,下一步
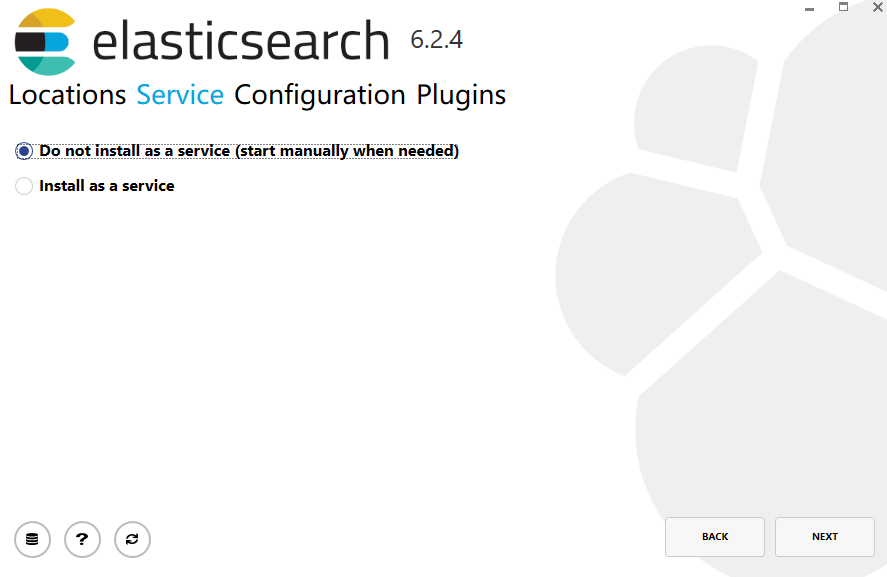
2.可以选择是否安装成windows服务,这边先不选择,改为手动开启
3.进行基本配置。下一步
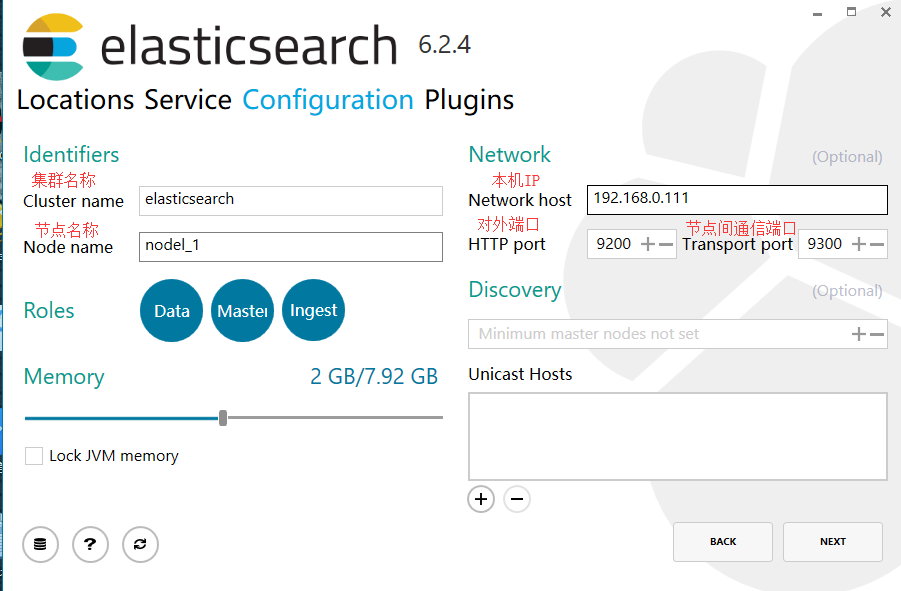
4.先不选任何插件或是分词器,之后安装即可
- 不管是哪种安装方式,想搭建集群,每个节点还需进入ElasticSearch安装目录下config文件夹中,打开elasticsearch.yml进行配置
节点一配置信息:
bootstrap.memory_lock: false
cluster.name: elasticsearch #集群名称,所有节点必须一致,才能自动加入集群
http.port: 9200 #对外通信端口
network.host: 192.168.0.101 #本机IP
node.data: true #是否为数据节点
node.ingest: true
node.master: true #是否为候选主节点
node.name: node-1 #节点名称
path.data: C:\Elasticsearch\data #索引数据保存目录
path.logs: C:\Elasticsearch\logs #日记保存目录
transport.tcp.port: 9300 #节点间通信端口
discovery.zen.ping.unicast.hosts: ["192.168.0.102:9300", "192.168.0.103:9300"] #设置集群自动发现机器ip集合 ,
discovery.zen.minimum_master_nodes: 2 #一般用node数/2 + 1。node数不能为偶数 防止脑裂现象
节点二配置信息
bootstrap.memory_lock: false
cluster.name: elasticsearch #集群名称,所有节点必须一致,才能自动加入集群
http.port: 9200 #对外通信端口
network.host: 192.168.0.102 #本机IP
node.data: true #是否为数据节点
node.ingest: true
node.master: true #是否为候选主节点
node.name: node-2 #节点名称
path.data: C:\Elasticsearch\data #索引数据保存目录
path.logs: C:\Elasticsearch\logs #日记保存目录
transport.tcp.port: 9300 #节点间通信端口
discovery.zen.ping.unicast.hosts: ["192.168.0.101:9300", "192.168.0.103:9300"] #设置集群自动发现机器ip集合 ,
discovery.zen.minimum_master_nodes: 2 #一般用node数/2 + 1。node数不能为偶数 防止脑裂现象
节点三配置信息
bootstrap.memory_lock: false
cluster.name: elasticsearch #集群名称,所有节点必须一致,才能自动加入集群
http.port: 9200 #对外通信端口
network.host: 192.168.0.103 #本机IP
node.data: true #是否为数据节点
node.ingest: true
node.master: true #是否为候选主节点
node.name: node-3 #节点名称
path.data: C:\Elasticsearch\data #索引数据保存目录
path.logs: C:\Elasticsearch\logs #日记保存目录
transport.tcp.port: 9300 #节点间通信端口
discovery.zen.ping.unicast.hosts: ["192.168.0.101:9300", "192.168.0.102:9300"] #设置集群自动发现机器ip集合 ,
discovery.zen.minimum_master_nodes: 2 #一般用node数/2 + 1。node数不能为偶数 防止脑裂现象
- 分别运行elasticsearch,直接通过chrom应用安装elasticsearch-head浏览器插件,elasticsearch-head可以查看es集群的运行状态以及数据
结果如下(还未加入任何索引):
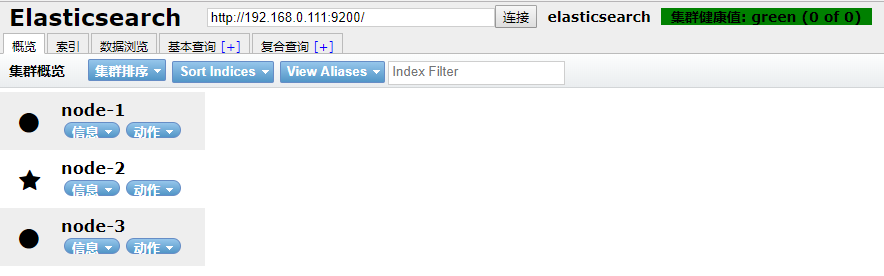
集群健康值说明:
- 绿色:所有的主分片和副本分片都正常可用;
- 黄色:所有的主分片可用,但是部分副本分片不可用
- 红色:部分主分片不可用
全文检索-Elasticsearch (一) 安装与基础概念的更多相关文章
- 【Elasticsearch学习】之基础概念
Elasticsearch是一个近实时的分布式搜索引起,其底层基于开源全文搜索库Lucene:Elasticsearch对Lucene进行分装,对外提供REST API 的操作接口.基于 ES,可以快 ...
- [Elasticsearch] 全文搜索 (一) 基础概念和match查询
全文搜索(Full Text Search) 现在我们已经讨论了搜索结构化数据的一些简单用例,是时候开始探索全文搜索了 - 如何在全文字段中搜索来找到最相关的文档. 对于全文搜索而言,最重要的两个方面 ...
- RabbitMQ 入门之基础概念
什么是消息队列(MQ) 消息是在不同应用间传递的数据.这里的消息可以非常简单,比如只包含字符串,也可以非常复杂,包含多个嵌套的对象.消息队列(Message Queue)简单来说就是一种应用程序间的通 ...
- 白日梦的ES笔记三:万字长文 Elasticsearch基础概念统一扫盲
目录 一.导读 二.彩蛋福利:账号借用 三.ES的Index.Shard及扩容机制 四.ES支持的核心数据类型 4.1.数字类型 4.2.日期类型 4.3.boolean类型 4.4.二进制类型 4. ...
- ElasticSearch安装和核心概念
1.ElasticSearch安装 elasticsearch的安装超级easy,解压即用(要事先安装好java环境). 到官网 http://www.elasticsearch.org下载最新版的 ...
- Elasticsearch教程之基础概念
基础概念 Elasticsearch有几个核心概念.从一开始理解这些概念会对整个学习过程有莫大的帮助. 1.接近实时(NRT) Elasticsearch是一个接近实时的搜索平台.这意味 ...
- MongoDB入门系列(一):基础概念和安装
概述 MongoDB是目前非常流行的一种非关系型数据库,作为入门系列的第一篇本篇文章主要介绍Mongdb的基础概念知识包括命名规则.数据类型.功能以及安装等. 环境: OS:Windows Versi ...
- ElasticSearch 全文检索— ElasticSearch 安装部署
ElasticSearch 规划-集群规划 ElasticSearch 规划-集群规划 ElasticSearch 规划-用户规划 ElasticSearch 规划-目录规划 ElasticSearc ...
- ELK&ElasticSearch5.1基础概念及配置文件详解【转】
1. 配置文件 elasticsearch/elasticsearch.yml 主配置文件 elasticsearch/jvm.options jvm参数配置文件 elasticsearch/log4 ...
随机推荐
- 【转】Zookeeper 安装和配置
转自:http://coolxing.iteye.com/blog/1871009 Zookeeper的安装和配置十分简单, 既可以配置成单机模式, 也可以配置成集群模式. 下面将分别进行介绍. 单机 ...
- Javascript 标识符及同名标识符的优先级
一.定义 标识符(Identifier)就是一个名字,用来对变量.函数.属性.参数进行命名,或者用做某些循环语句中的跳转位置的标记. //变量 var Identifier = 123; //属性 ( ...
- RSP小组——团队冲刺博客一——(领航)
RSP小组--团队冲刺博客一--领航 冲刺日期:2018年12月10日 团队目标 经过团队讨论,我们最新确定的α版本所需实现内容如下: 1.实现游戏代码的实现 2.在Android Studio上实现 ...
- box-shadow 画叮当猫
值 描述 h-shadow 必需.水平阴影的位置.允许负值 v-shadow 必需.垂直阴影的位置.允许负值 blur 可选.模糊距离 spread 可选.阴影的尺寸 color 可选.阴影的颜色.请 ...
- Oracle DBLINK的相关知识整理
一.DBLINK(Database Link)概念 dblink,顾名思义就是数据库的链接.当我们要跨本地数据库访问另一个数据库中的表的数据时,在本地数据库中就必须要创建远程数据库的dblink,通过 ...
- [LeetCode] Inorder Successor in BST II 二叉搜索树中的中序后继节点之二
Given a binary search tree and a node in it, find the in-order successor of that node in the BST. Th ...
- Spring源码学习-容器BeanFactory(一) BeanDefinition的创建-解析资源文件
写在前面 从大四实习至今已一年有余,作为一个程序员,一直没有用心去记录自己工作中遇到的问题,甚是惭愧,打算从今日起开始养成写博客的习惯.作为一名java开发人员,Spring是永远绕不过的话题,它的设 ...
- TCSL:遇到网络正常,但是添加网口打印机总是失效的问题。
1. 环境 这家店要换成TCSL餐饮系统,但是店主希望在换系统时候,保持原来系统正常运转.所以,一开始踩点和实施都是小心翼翼~~ 不过,还是遇到问题,没法打印,如果开启TCSL打印服务,就会和原来的餐 ...
- 用appuploader生成发布证书和描述性文件
本帖最后由 长发飘 于 2017-4-13 12:34 编辑 之前用AppCan平台开发了一个应用,平台可以同时生成安卓版和苹果版,想着也把这应用上架到App Store试试,于是找同学借了个苹果开发 ...
- Parallel线程安全问题
废话不多说,上代码: using System; using System.Collections.Generic; using System.Threading.Tasks; namespace P ...