Kafka从入门到进阶
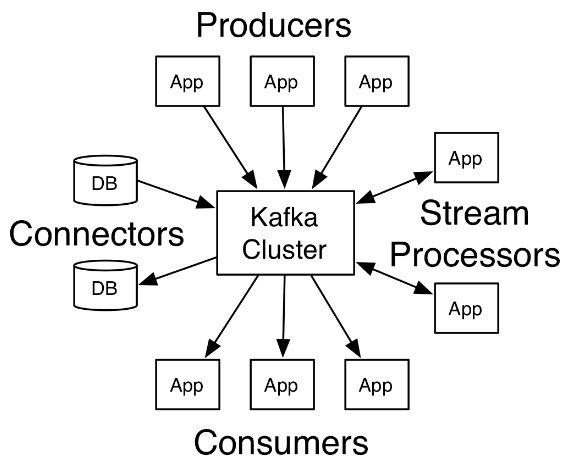
1. Apache Kafka是一个分布式流平台
1.1 流平台有三个关键功能:
- 发布和订阅流记录,类似于一个消息队列或企业消息系统
- 以一种容错的持久方式存储记录流
- 在流记录生成的时候就处理它们
1.2 Kafka通常用于两大类应用:
- 构建实时流数据管道,在系统或应用程序之间可靠地获取数据
- 构建对数据流进行转换或输出的实时流媒体应用程序
1.3 有几个特别重要的概念:
Kafka is run as a cluster on one or more servers that can span multiple datacenters.
The Kafka cluster stores streams of records in categories called topics.
Each record consists of a key, a value, and a timestamp.
Kafka作为集群运行在一个或多个可以跨多个数据中心的服务器上
从这句话表达了三个意思:
- Kafka是以集群方式运行的
- 集群中可以只有一台服务器,也有可能有多台服务器。也就是说,一台服务器也是一个集群,多台服务器也可以组成一个集群
- 这些服务器可以跨多个数据中心
Kafka集群按分类存储流记录,这个分类叫做主题
这句话表达了以下几个信息:
- 流记录是分类存储的,也就说记录是归类的
- 我们称这种分类为主题
- 简单地来讲,记录是按主题划分归类存储的
每个记录由一个键、一个值和一个时间戳组成
1.4 Kafka有四个核心API:
- Producer API :允许应用发布一条流记录到一个或多个主题
- Consumer API :允许应用订阅一个或多个主题,并处理流记录
- Streams API :允许应用作为一个流处理器,从一个或多个主题那里消费输入流,并将输出流输出到一个或多个输出主题,从而有效地讲输入流转换为输出流
- Connector API :允许将主题连接到已经存在的应用或者数据系统,以构建并允许可重用的生产者或消费者。例如,一个关系型数据库的连接器可能捕获到一张表的每一次变更
(画外音:我理解这四个核心API其实就是:发布、订阅、转换处理、从第三方采集数据。)
在Kafka中,客户端和服务器之间的通信是使用简单的、高性能的、与语言无关的TCP协议完成的。
2. Topics and Logs(主题和日志)
一个topic是一个分类,或者说是记录被发布的时候的一个名字(画外音:可以理解为记录要被发到哪儿去)。
在Kafka中,topic总是有多个订阅者,因此,一个topic可能有0个,1个或多个订阅该数据的消费者。
对于每个主题,Kafka集群维护一个分区日志,如下图所示:
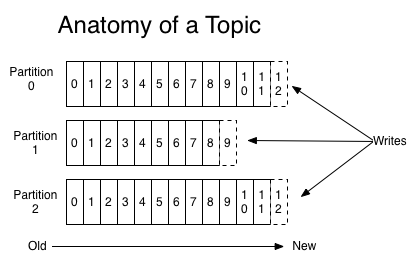
每个分区都是一个有序的、不可变的记录序列,而且记录会不断的被追加,一条记录就是一个结构化的提交日志(a structured commit log)。
分区中的每条记录都被分配了一个连续的id号,这个id号被叫做offset(偏移量),这个偏移量唯一的标识出分区中的每条记录。(PS:如果把分区比作数据库表的话,那么偏移量就是主键)
Kafka集群持久化所有已发布的记录,无论它们有没有被消费,记录被保留的时间是可以配置的。例如,如果保留策略被设置为两天,那么在记录发布后的两天内,可以使用它,之后将其丢弃以释放空间。在对数据大小方面,Kafka的性能是高效的,恒定常量级的,因此长时间存储数据不是问题。
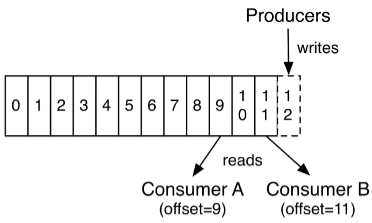
事实上,唯一维护在每个消费者上的元数据是消费者在日志中的位置或者叫偏移量。偏移量是由消费者控制的:通常消费者在读取记录的时候会线性的增加它的偏移量,但是,事实上,由于位置(偏移量)是由消费者控制的,所有它可以按任意它喜欢的顺序消费记录。例如:一个消费者可以重置到一个较旧的偏移量来重新处理之前已经处理过的数据,或者跳转到最近的记录并从“现在”开始消费。
这种特性意味着消费者非常廉价————他们可以来来去去的消息而不会对集群或者其它消费者造成太大影响。
日志中的分区有几个用途。首先,它们允许日志的规模超出单个服务器的大小。每个独立分区都必须与宿主的服务器相匹配,但一个主题可能有多个分区,所以它可以处理任意数量的数据。第二,它们作为并行的单位——稍后再进一步。
(
画外音:简单地来说,日志分区的作用有两个:一、日志的规模不再受限于单个服务器;二、分区意味着可以并行。
什么意思呢?主题建立在集群之上,每个主题维护了一个分区日志,顾名思义,日志是分区的;每个分区所在的服务器的资源(比如:CPU、内存、带宽、磁盘等)是有限的,如果不分区(可以理解为等同于只有一个)的话,必然受限于这个分区所在的服务器,那么多个分区的话就不一样了,就突破了这种限制,服务器可以随便加,分区也可以随便加。
)
3. Distribution(分布)
日志的分区分布在集群中的服务器上,每个服务器处理数据,并且分区请求是共享的。每个分区被复制到多个服务器上以实现容错,到底复制到多少个服务器上是可以配置的。
Each partition is replicated across a configurable number of servers for fault tolerance.
每个分区都有一个服务器充当“leader”角色,并且有0个或者多个服务器作为“followers”。leader处理对这个分区的所有读和写请求,而followers被动的从leader那里复制数据。如果leader失败,followers中的其中一个会自动变成新的leader。每个服务器充当一些分区的“leader”的同时也是其它分区的“follower”,因此在整个集群中负载是均衡的。
也就是说,每个服务器既是“leader”也是“follower”。我们知道一个主题可能有多个分区,一个分区可能在一个服务器上也可能跨多个服务器,然而这并不以为着一台服务器上只有一个分区,是可能有多个分区的。每个分区中有一个服务器充当“leader”,其余是“follower”。leader负责处理这个它作为leader所负责的分区的所有读写请求,而该分区中的follow只是被动复制leader的数据。这个有点儿像HDFS中的副本机制。例如:分区-1有服务器A和B组成,A是leader,B是follower,有请求要往分区-1中写数据的时候就由A处理,然后A把刚才写的数据同步给B,这样的话正常请求相当于A和B的数据是一样的,都有分区-1的全部数据,如果A宕机了,B成为leader,接替A继续处理对分区-1的读写请求。
需要注意的是,分区是一个虚拟的概念,是一个逻辑单元。
4. Producers(生产者)
生产者发布数据到它们选择的主题中。生产者负责选择将记录投递到哪个主题的哪个分区中。要做这件事情,可以简单地用循环方式以到达负载均衡,或者根据一些语义分区函数(比如:基于记录中的某些key)
5. Consumers(消费者)
消费者用一个消费者组名来标识它们自己(PS:相当于给自己贴一个标签,标签的名字是组名,以表明自己属于哪个组),并且每一条发布到主题中的记录只会投递给每个订阅的消费者组中的其中一个消费者实例。消费者实例可能是单独的进程或者在单独的机器上。
如果所有的消费者实例都使用相同的消费者组,那么记录将会在这些消费者之间有效的负载均衡。
如果所有的消费者实例都使用不同的消费者组,那么每条记录将会广播给所有的消费者进程。
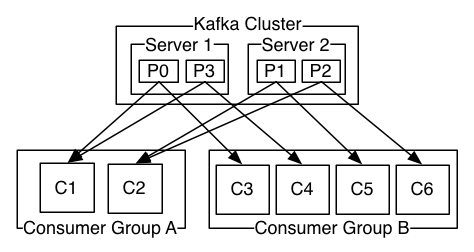
上图中其实那个Kafka Cluster换成Topic会更准确一些
一个Kafka集群有2个服务器,4个分区(P0-P3),有两个消费者组。组A中有2个消费者实例,组B中有4个消费者实例。
通常我们会发现,主题不会有太多的消费者组,每个消费者组是一个“逻辑订阅者”(以消费者组的名义订阅主题,而非以消费者实例的名义去订阅)。每个组由许多消费者实例组成,以实现可扩展性和容错。这仍然是发布/订阅,只不过订阅者是一个消费者群体,而非单个进程。
在Kafka中,这种消费方式是通过用日志中的分区除以使用者实例来实现的,这样可以保证在任意时刻每个消费者都是排它的消费,即“公平共享”。Kafka协议动态的处理维护组中的成员。如果有心的实例加入到组中,它们将从组中的其它成员那里接管一些分区;如果组中有一个实例死了,那么它的分区将会被分给其它实例。
(画外音:什么意思呢?举个例子,在上面的图中,4个分区,组A有2个消费者,组B有4个消费者,那么对A来讲组中的每个消费者负责4/2=2个分区,对组B来说组中的每个消费者负责4/4=1个分区,而且同一时间消息只能被组中的一个实例消费。如果组中的成员数量有变化,则重新分配。)
Kafka只提供分区下的记录的总的顺序,而不提供主题下不同分区的总的顺序。每个分区结合按key划分数据的能力排序对大多数应用来说是足够的。然而,如果你需要主题下总的记录顺序,你可以只使用一个分区,这样做的做的话就意味着每个消费者组中只能有一个消费者实例。
6. 保证
在一个高级别的Kafka给出下列保证:
- 被一个生产者发送到指定主题分区的消息将会按照它们被发送的顺序追加到分区中。也就是说,如果记录M1和M2是被同一个生产者发送到同一个分区的,而且M1是先发送的,M2是后发送的,那么在分区中M1的偏移量一定比M2小,并且M1出现在日志中的位置更靠前。
- 一个消费者看到记录的顺序和它们在日志中存储的顺序是一样的。
- 对于一个副本因子是N的主题,我们可以容忍最多N-1个服务器失败,而不会丢失已经提交给日志的任何记录。
7. Spring Kafka
Spring提供了一个“模板”作为发送消息的高级抽象。它也通过使用@KafkaListener注释和“监听器容器”提供对消息驱动POJOs的支持。这些库促进了依赖注入和声明式的使用。
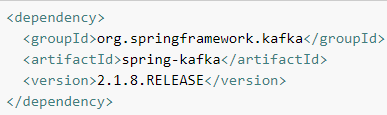
7.1 纯Java方式
package com.cjs.example.quickstart; import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.kafka.core.*;
import org.springframework.kafka.listener.KafkaMessageListenerContainer;
import org.springframework.kafka.listener.MessageListener;
import org.springframework.kafka.listener.config.ContainerProperties; import java.util.HashMap;
import java.util.Map; public class PureJavaDemo { /**
* 生产者配置
*/
private static Map<String, Object> senderProps() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.101.5:9093");
props.put(ProducerConfig.RETRIES_CONFIG, 0);
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
} /**
* 消费者配置
*/
private static Map<String, Object> consumerProps() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.101.5:9093");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "hello");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "100");
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
} /**
* 发送模板配置
*/
private static KafkaTemplate<Integer, String> createTemplate() {
Map<String, Object> senderProps = senderProps();
ProducerFactory<Integer, String> producerFactory = new DefaultKafkaProducerFactory<>(senderProps);
KafkaTemplate<Integer, String> kafkaTemplate = new KafkaTemplate<>(producerFactory);
return kafkaTemplate;
} /**
* 消息监听器容器配置
*/
private static KafkaMessageListenerContainer<Integer, String> createContainer() {
Map<String, Object> consumerProps = consumerProps();
ConsumerFactory<Integer, String> consumerFactory = new DefaultKafkaConsumerFactory<>(consumerProps);
ContainerProperties containerProperties = new ContainerProperties("test");
KafkaMessageListenerContainer<Integer, String> container = new KafkaMessageListenerContainer<>(consumerFactory, containerProperties);
return container;
} public static void main(String[] args) throws InterruptedException {
String topic1 = "test"; // 主题 KafkaMessageListenerContainer container = createContainer();
ContainerProperties containerProperties = container.getContainerProperties();
containerProperties.setMessageListener(new MessageListener<Integer, String>() {
@Override
public void onMessage(ConsumerRecord<Integer, String> record) {
System.out.println("Received: " + record);
}
});
container.setBeanName("testAuto"); container.start(); KafkaTemplate<Integer, String> kafkaTemplate = createTemplate();
kafkaTemplate.setDefaultTopic(topic1); kafkaTemplate.sendDefault(0, "foo");
kafkaTemplate.sendDefault(2, "bar");
kafkaTemplate.sendDefault(0, "baz");
kafkaTemplate.sendDefault(2, "qux"); kafkaTemplate.flush();
container.stop(); System.out.println("结束");
} }
运行结果:
Received: ConsumerRecord(topic = test, partition = 0, offset = 67, CreateTime = 1533300970788, serialized key size = 4, serialized value size = 3, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = foo)
Received: ConsumerRecord(topic = test, partition = 0, offset = 68, CreateTime = 1533300970793, serialized key size = 4, serialized value size = 3, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = bar)
Received: ConsumerRecord(topic = test, partition = 0, offset = 69, CreateTime = 1533300970793, serialized key size = 4, serialized value size = 3, headers = RecordHeaders(headers = [], isReadOnly = false), key = 0, value = baz)
Received: ConsumerRecord(topic = test, partition = 0, offset = 70, CreateTime = 1533300970793, serialized key size = 4, serialized value size = 3, headers = RecordHeaders(headers = [], isReadOnly = false), key = 2, value = qux)
7.2 更简单一点儿,用SpringBoot
package com.cjs.example.quickstart; import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.core.KafkaTemplate; @Configuration
public class JavaConfigurationDemo { @KafkaListener(topics = "test")
public void listen(ConsumerRecord<String, String> record) {
System.out.println("收到消息: " + record);
} @Bean
public CommandLineRunner commandLineRunner() {
return new MyRunner();
} class MyRunner implements CommandLineRunner { @Autowired
private KafkaTemplate<String, String> kafkaTemplate; @Override
public void run(String... args) throws Exception {
kafkaTemplate.send("test", "foo1");
kafkaTemplate.send("test", "foo2");
kafkaTemplate.send("test", "foo3");
kafkaTemplate.send("test", "foo4");
}
}
}
application.properties配置
spring.kafka.bootstrap-servers=192.168.101.5:9092
spring.kafka.consumer.group-id=world
8. 生产者
package com.cjs.example.send; import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.IntegerSerializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory; import java.util.HashMap;
import java.util.Map; @Configuration
public class Config { public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.101.5:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return props;
} public ProducerFactory<Integer, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
} @Bean
public KafkaTemplate<Integer, String> kafkaTemplate() {
return new KafkaTemplate<Integer, String>(producerFactory());
} }
package com.cjs.example.send; import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback; @Component
public class MyCommandLineRunner implements CommandLineRunner { @Autowired
private KafkaTemplate<Integer, String> kafkaTemplate; public void sendTo(Integer key, String value) {
ListenableFuture<SendResult<Integer, String>> listenableFuture = kafkaTemplate.send("test", key, value);
listenableFuture.addCallback(new ListenableFutureCallback<SendResult<Integer, String>>() {
@Override
public void onFailure(Throwable throwable) {
System.out.println("发送失败啦");
throwable.printStackTrace();
} @Override
public void onSuccess(SendResult<Integer, String> sendResult) {
System.out.println("发送成功," + sendResult);
}
});
} @Override
public void run(String... args) throws Exception {
sendTo(1, "aaa");
sendTo(2, "bbb");
sendTo(3, "ccc");
} }
运行结果:
发送成功,SendResult [producerRecord=ProducerRecord(topic=test, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=aaa, timestamp=null), recordMetadata=test-0@37]
发送成功,SendResult [producerRecord=ProducerRecord(topic=test, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=2, value=bbb, timestamp=null), recordMetadata=test-0@38]
发送成功,SendResult [producerRecord=ProducerRecord(topic=test, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=3, value=ccc, timestamp=null), recordMetadata=test-0@39]
9. 消费者@KafkaListener
package com.cjs.example.receive; import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.IntegerDeserializer;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.TopicPartition;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.AbstractMessageListenerContainer;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.listener.config.ContainerProperties;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload; import java.util.HashMap;
import java.util.List;
import java.util.Map; @Configuration
public class Config2 { @Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<Integer, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Integer, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setConcurrency(3);
ContainerProperties containerProperties = factory.getContainerProperties();
containerProperties.setPollTimeout(2000);
// containerProperties.setAckMode(AbstractMessageListenerContainer.AckMode.MANUAL_IMMEDIATE);
return factory;
} private ConsumerFactory<Integer,String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerProps());
} private Map<String, Object> consumerProps() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.101.5:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "hahaha");
// props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, IntegerDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
return props;
} @KafkaListener(topics = "test")
public void listen(String data) {
System.out.println("listen 收到: " + data);
} @KafkaListener(topics = "test", containerFactory = "kafkaListenerContainerFactory")
public void listen2(String data, Acknowledgment ack) {
System.out.println("listen2 收到: " + data);
ack.acknowledge();
} @KafkaListener(topicPartitions = {@TopicPartition(topic = "test", partitions = "0")})
public void listen3(ConsumerRecord<?, ?> record) {
System.out.println("listen3 收到: " + record.value());
} @KafkaListener(id = "xyz", topics = "test")
public void listen4(@Payload String foo,
@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) Integer key,
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
@Header(KafkaHeaders.OFFSET) List<Long> offsets) {
System.out.println("listen4 收到: ");
System.out.println(foo);
System.out.println(key);
System.out.println(partition);
System.out.println(topic);
System.out.println(offsets);
} }
9.1 Committing Offsets
如果enable.auto.commit设置为true,那么kafka将自动提交offset。如果设置为false,则支持下列AckMode(确认模式)。
消费者poll()方法将返回一个或多个ConsumerRecords
- RECORD :处理完记录以后,当监听器返回时,提交offset
- BATCH :当对poll()返回的所有记录进行处理完以后,提交偏offset
- TIME :当对poll()返回的所有记录进行处理完以后,只要距离上一次提交已经过了ackTime时间后就提交
- COUNT :当poll()返回的所有记录都被处理时,只要从上次提交以来收到了ackCount条记录,就可以提交
- COUNT_TIME :和TIME以及COUNT类似,只要这两个中有一个为true,则提交
- MANUAL :消息监听器负责调用Acknowledgment.acknowledge()方法,此后和BATCH是一样的
- MANUAL_IMMEDIATE :当监听器调用Acknowledgment.acknowledge()方法后立即提交
10. Spring Boot Kafka
10.1 application.properties
spring.kafka.bootstrap-servers=192.168.101.5:9092
10.2 发送消息
package com.cjs.example; import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController; import javax.annotation.Resource; @RestController
@RequestMapping("/msg")
public class MessageController { @Resource
private KafkaTemplate<String, String> kafkaTemplate; @RequestMapping("/send")
public String send(String topic, String key, String value) {
kafkaTemplate.send(topic, key, value);
return "ok";
} }
10.3 接收消息
package com.cjs.example; import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.KafkaListeners;
import org.springframework.stereotype.Component; @Component
public class MessageListener { /**
* 监听订单消息
*/
@KafkaListener(topics = "ORDER", groupId = "OrderGroup")
public void listenToOrder(String data) {
System.out.println("收到订单消息:" + data);
} /**
* 监听会员消息
*/
@KafkaListener(topics = "MEMBER", groupId = "MemberGroup")
public void listenToMember(ConsumerRecord<String, String> record) {
System.out.println("收到会员消息:" + record);
} /**
* 监听所有消息
*
* 任意时刻,一条消息只会发给组中的一个消费者
*
* 消费者组中的成员数量不能超过分区数,这里分区数是1,因此订阅该主题的消费者组成员不能超过1
*/
// @KafkaListeners({@KafkaListener(topics = "ORDER", groupId = "OrderGroup"),
// @KafkaListener(topics = "MEMBER", groupId = "MemberGroup")})
// public void listenToAll(String data) {
// System.out.println("啊啊啊");
// } }
11. pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>com.cjs.example</groupId>
<artifactId>cjs-kafka-example</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging> <name>cjs-kafka-example</name>
<description></description> <parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties> <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build> </project>
12. 其它
有兴趣的话可以看一下其它几篇:
《Kafka介绍》
13. 参考
http://spring.io/projects/spring-kafka
https://docs.spring.io/spring-boot/docs/2.0.4.RELEASE/reference/htmlsingle/#boot-features-kafka
Kafka从入门到进阶的更多相关文章
- 推荐 10 本 Go 经典书籍,从入门到进阶(含下载方式)
书单一共包含 10 本书,分为入门 5 本,进阶 5 本.我读过其中 7 本,另外 3 本虽然没读过,但也是网上推荐比较多的. 虽然分了入门和进阶,但是很多书中这两部分内容是都包含了的.大家看的时候可 ...
- SQL Server 扩展事件(Extented Events)从入门到进阶(1)——从SQL Trace到Extented Events
由于工作需要,决定深入研究SQL Server的扩展事件(Extended Events/xEvents),经过资料搜索,发现国外大牛的系列文章,作为“学习”阶段,我先翻译这系列文章,后续在工作中的心 ...
- Wireshark入门与进阶系列(一)
摘自http://blog.csdn.net/howeverpf/article/details/40687049 Wireshark入门与进阶系列(一) “君子生非异也,善假于物也”---荀子 本文 ...
- Wireshark入门与进阶系列(二)
摘自http://blog.csdn.net/howeverpf/article/details/40743705 Wireshark入门与进阶系列(二) “君子生非异也,善假于物也”---荀子 本文 ...
- Wireshark入门与进阶---数据包捕获与保存的最基本流程
Wireshark入门与进阶系列(一) "君子生非异也.善假于物也"---荀子 本文由CSDN-蚍蜉撼青松 [主页:http://blog.csdn.net/howeverpf]原 ...
- SQL Server AlwaysON从入门到进阶(3)——基础架构
本文属于SQL Server AlwaysON从入门到进阶系列文章 前言: 本文将更加深入地讲解WSFC所需的核心组件.由于AlwaysOn和FCI都需要基于WSFC之上,因此我们首先要了解在Wind ...
- SQL Server AlwaysON从入门到进阶(2)——存储
本文属于SQL Server AlwaysON从入门到进阶系列文章 前言: 本节讲解关于SQL Server 存储方面的内容,相对于其他小节而言这节比较短.本节会提供一些关于使用群集或者非群集系统过程 ...
- SQL Server AlwaysON从入门到进阶(1)——何为AlwaysON?
本文属于SQL Server AlwaysON从入门到进阶系列文章 本文原文出自Stairway to AlwaysOn系列文章.根据工作需要在学习过程中顺带翻译以供参考.系列文章包含: SQL Se ...
- SQL Server 扩展事件(Extented Events)从入门到进阶(4)——扩展事件引擎——基本概念
本文属于 SQL Server 扩展事件(Extented Events)从入门到进阶 系列 在第一二节中,我们创建了一些简单的.类似典型SQL Trace的扩展事件会话.在此过程中,介绍了很多扩展事 ...
随机推荐
- 当使用xmapp时session序列化生成的文件的路径
由于没有安装tomcat而是安的xmapp所以序列化和反序列化时并没有在tomcat的里边生成session文件而是在java的工作路径下生成在以下路径下 D:\pro\java\workspace\ ...
- vue获取当前对象
<li v-for="img in willLoadImg" @click="selectImg($event)"> <img class=& ...
- Adams 2013自定义插件方法zz
1.Adams插件介绍 Adams的高级模块(如Controls控制模块.Vibration振动模块.Durability耐久性模块等)是以插件的形式集成在Adams软件中.通过Adams提供的插件管 ...
- 学习随笔:Vue.js与Django交互以及Ajax和axios
1. Vue.js地址 Staticfile CDN(国内): https://cdn.staticfile.org/vue/2.2.2/vue.min.js unpkg:会保持和npm发布的最新的版 ...
- Ext使用中问题总结
隐藏 Ext.form.DateField 的触发(trigger)元素使其内容不能修改并使其所有的文本框(text field)显示格式为Y-m-d items : [{ xtype : ' dat ...
- spring为什么推荐使用构造器注入?
闲谈 Spring框架对Java开发的重要性不言而喻,其核心特性就是IOC(Inversion of Control, 控制反转)和AOP,平时使用最多的就是其中的IOC,我们通过将组件交由Spr ...
- OI中常犯的傻逼错误总结
OI中常犯的傻逼错误总结 问题 解决方案 文件名出错,包括文件夹,程序文件名,输入输出文件名 复制pdf的名字 没有去掉调试信息 调试时在后面加个显眼的标记 数组开小,超过定义大小,maxn/ ...
- TypeScript 函数-函数类型
//指定参数类型 function add(x:number,y:number){ console.log("x:"+x); // reutrn(x+y); } //指定函数类型 ...
- Flume+Kafka+Storm+Hbase+HDSF+Poi整合
Flume+Kafka+Storm+Hbase+HDSF+Poi整合 需求: 针对一个网站,我们需要根据用户的行为记录日志信息,分析对我们有用的数据. 举例:这个网站www.hongten.com(当 ...
- ssh 连接失败 sz rz 安装
sz 下载命令, rz上传命令的安装 sudo apt-get install lrzsz 1. 检查sshd服务的状态以及端口是否正常, 如下为正常状态 sudo netstat -nlp | gr ...