【机器学习】--线性回归中L1正则和L2正则
一、前述
L1正则,L2正则的出现原因是为了推广模型的泛化能力。相当于一个惩罚系数。
二、原理
L1正则:Lasso Regression
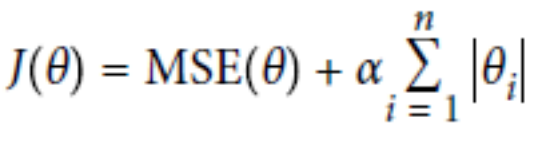
L2正则:Ridge Regression

总结:
经验值 MSE前系数为1 ,L1 , L2正则前面系数一般为0.4~0.5 更看重的是准确性。
L2正则会整体的把w变小。
L1正则会倾向于使得w要么取1,要么取0 ,稀疏矩阵 ,可以达到降维的角度。
ElasticNet函数(把L1正则和L2正则联合一起):

总结:
1.默认情况下选用L2正则。
2.如若认为少数特征有用,可以用L1正则。
3.如若认为少数特征有用,但特征数大于样本数,则选择ElasticNet函数。
代码一:L1正则
# L1正则
import numpy as np
from sklearn.linear_model import Lasso
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1) lasso_reg = Lasso(alpha=0.15)
lasso_reg.fit(X, y)
print(lasso_reg.predict(1.5)) sgd_reg = SGDRegressor(penalty='l1')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
代码二:L2正则
# L2正则
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1) #两种方式第一种岭回归
ridge_reg = Ridge(alpha=1, solver='auto')
ridge_reg.fit(X, y)
print(ridge_reg.predict(1.5))#预测1.5的值
#第二种 使用随机梯度下降中L2正则
sgd_reg = SGDRegressor(penalty='l2')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
代码三:Elastic_Net函数
# elastic_net函数
import numpy as np
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import SGDRegressor X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
#两种方式实现Elastic_net
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
elastic_net.fit(X, y)
print(elastic_net.predict(1.5)) sgd_reg = SGDRegressor(penalty='elasticnet')
sgd_reg.fit(X, y.ravel())
print(sgd_reg.predict(1.5))
【机器学习】--线性回归中L1正则和L2正则的更多相关文章
- 【机器学习】--鲁棒性调优之L1正则,L2正则
一.前述 鲁棒性调优就是让模型有更好的泛化能力和推广力. 二.具体原理 1.背景 第一个更好,因为当把测试集带入到这个模型里去.如果测试集本来是100,带入的时候变成101,则第二个模型结果偏差很大, ...
- 贝叶斯先验解释l1正则和l2正则区别
这里讨论机器学习中L1正则和L2正则的区别. 在线性回归中我们最终的loss function如下: 那么如果我们为w增加一个高斯先验,假设这个先验分布是协方差为 的零均值高斯先验.我们在进行最大似然 ...
- L1正则和L2正则的比较分析详解
原文链接:https://blog.csdn.net/w5688414/article/details/78046960 范数(norm) 数学上,范数是一个向量空间或矩阵上所有向量的长度和大小的求和 ...
- L1正则与L2正则
L1正则是权值的绝对值之和,重点在于可以稀疏化,使得部分权值等于零. L1正则的含义是 ∥w∥≤c,如下图就可以解释为什么会出现权值为零的情况. L1正则在梯度下降的时候不可以直接求导,可以有以下几种 ...
- L1 正则 和 L2 正则的区别
L1,L2正则都可以看成是 条件限制,即 $\Vert w \Vert \leq c$ $\Vert w \Vert^2 \leq c$ 当w为2维向量时,可以看到,它们限定的取值范围如下图: 所以它 ...
- 大白话5分钟带你走进人工智能-第十四节过拟合解决手段L1和L2正则
第十四节过拟合解决手段L1和L2正则 第十三节中, ...
- 大白话5分钟带你走进人工智能-第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归
第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归 上一节中我们讲解了L1和L2正则的概念,知道了L1和L2都会使不重要的维度权重下降得多,重要的维度权重下降得少,引入 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- Spark2.0机器学习系列之12: 线性回归及L1、L2正则化区别与稀疏解
概述 线性回归拟合一个因变量与一个自变量之间的线性关系y=f(x). Spark中实现了: (1)普通最小二乘法 (2)岭回归(L2正规化) (3)La ...
随机推荐
- Docker 学习2 Docker基础用法
一.docker架构 1.client端 2.server端,docker daemo守护进程,监听在套接字之上.docker支持三种类型套接字. a.ip vs套接字:即IP + 端口套接字 b.i ...
- 洛谷 p2678 跳石头 题解
一道裸的二分答案 如果不会分治的去找dalao吧,本蒟蒻只会二分 不知道二分答案的看这里 这位dalao解释的很详细其实只是随便找了一个 那里面貌似也有这个题的题解,但我还是要写(才不是应付老师) 关 ...
- 开发环境中Docker的使用
一. Ubuntu16.04+Django+Redis+Nginx的Web项目Docker化 1.创建Django项目的image # 创建项目image 执行 docker build -t ccn ...
- vue-cli3.0安装element-ui组件及按需引入element-ui组件
在VUE-CLI 3下的第一个Element-ui项目(菜鸟专用) (https://www.cnblogs.com/xzqyun/p/10780659.html) 上面这个链接是vue-cli3.0 ...
- babel分析
现在都用 ES6 新语法以及 ES7 新特性来写应用了,但是浏览器和相关的环境还不能友好的支持,需要用到 Babel 转码器来转换成 ES5 的代码 相信大家都看到过如下的名词: babel-pres ...
- BUAA面向对象设计与构造——第一单元总结
BUAA面向对象设计与构造——第一单元总结 第一阶段:只支持一元多项式的表达式求导 1. 程序结构 由于是第一次接触面向对象的编程,加之题目要求不算复杂,我在第一次作业中并没有很好利用面向对象的特点, ...
- 【C语言编程练习】5.7填数字游戏求解
之前的东西就不上传了,大致就跟现在的一样 1. 题目要求 计算 ABCD * E DCBA 这个算式中每个字母代表什么数字? 2. 题目分析 如果是我们人去做这道题会怎么办,一定是这样想把,一个四位 ...
- git cannot lock ref
参考博客:https://blog.csdn.net/lindexi_gd/article/details/79213042 错误原文: cannot lock ref ‘refs/remotes/o ...
- CentOS7 VMware-Tools安装与共享文件夹设置
一. VMware-Tools安装 1.加载VMware Tools的光驱:点击"虚拟机"->"安装VMware Tools".这里,由于我已经安装了,所 ...
- elasticsearch简单操作
现在,启动一个节点和kibana,接下来的一切操作都在kibana中Dev Tools下的Console里完成 创建一篇文档 将小黑的小姨妈的个人信息录入elasticsearch.我们只要输入 PU ...