the python challenge闯关记录(0-8)
0 第零关
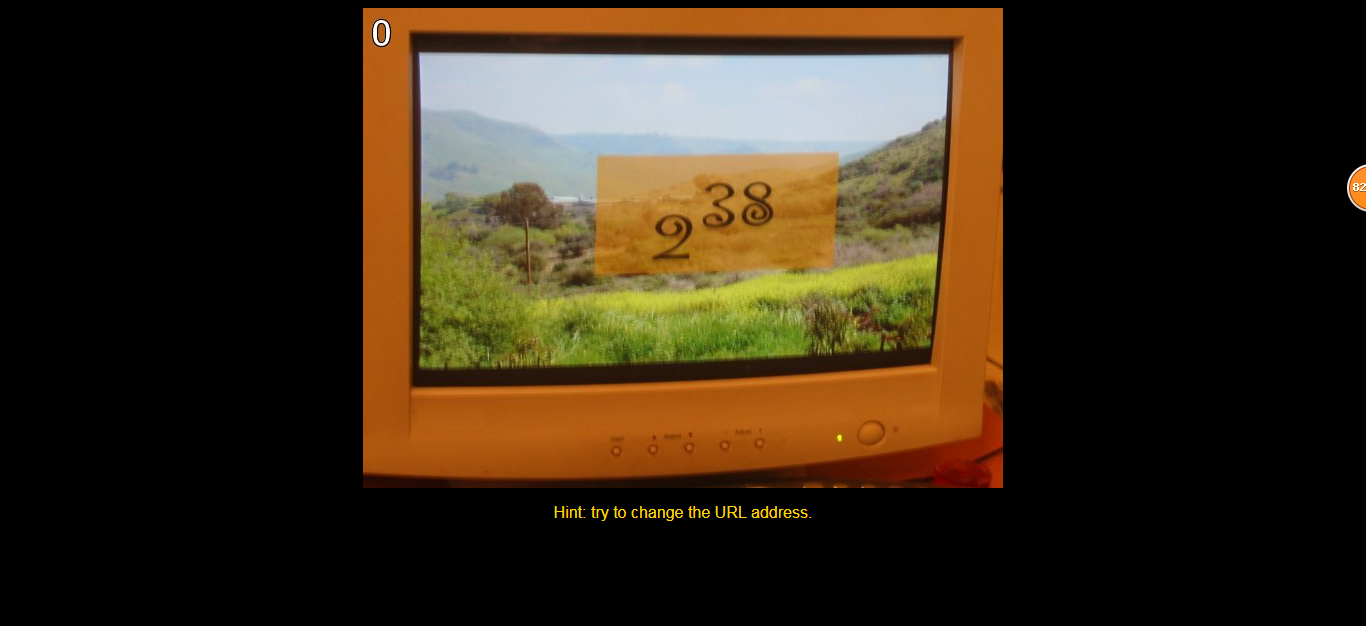
2**38 = 274877906944
下一关的url:http://www.pythonchallenge.com/pc/def/274877906944.html
1 第一关

移位计算,可以看出来是移动2位
def trans_str(s):
inword = 'abcdefghijklmnopqrstuvwxyz'
outword = 'cdefghijklmnopqrstuvwxyzab'
transtab = str.maketrans(inword, outword)
new_str = s.translate(transtab)
return new_str if __name__ == '__main__':
s = "g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw " \
"rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj"
print(trans_str(s))
s1 = 'map'
print(trans_str(s1))
得到答案:
i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that's why this text is so long. using string.maketrans() is recommended. now apply on the url
ocr
第二关url:http://www.pythonchallenge.com/pc/def/ocr.html
2 第二关

识别字符,也许他可能在书中,也可能在页面源码中。
打开页面源代码,发现提示:
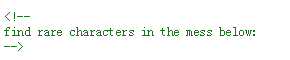
在下面混乱的字符中找到比较少的字符
new_list = []
for i in s:
if i not in new_list:
new_list.append(i)
new_dict = {}
for j in new_list:
new_dict[j] = s.count(j)
print(new_dict)
得到结果:
{'%': 6104, '$': 6046, '@': 6157, '_': 6112, '^': 6030, '#': 6115, ')': 6186, '&': 6043, '!': 6079, '+': 6066, ']': 6152, '*': 6034, '}': 6105, '[': 6108, '(': 6154, '{': 6046, '\n': 1219, 'e': 1, 'q': 1, 'u': 1, 'a': 1, 'l': 1, 'i': 1, 't': 1, 'y': 1}
发现出现一次的字符为:equality
则第三关的url为:http://www.pythonchallenge.com/pc/def/equality.html
3 第三关

一个小的字母,两边被三个大的字符包围,就像这样的格式xXXXxXXXx.。
照例查看网页源代码:

看来要处理的就是这堆字符串。
编写程序:
import requests
import re def parse_one():
response = requests.get('http://www.pythonchallenge.com/pc/def/equality.html')
reponse_text = response.text
pattern = re.compile('[^A-Z][A-Z]{3}([a-z])[A-Z]{3}[^A-Z]')
items = re.findall(pattern, reponse_text)
print(''.join(items)) if __name__ == "__main__":
parse_one()
得到结果:
linkedlist
那么第四关的url就为:http://www.pythonchallenge.com/pc/def/linkedlist.html
输入后为

将最后3位改为php,则url为:http://www.pythonchallenge.com/pc/def/linkedlist.php
4 第四关
进去后发现只有一张图

照例查看网页源代码:

urllib对你也许有帮助,不要尝试所有的nothings,它不会结束,400次或者更高。
点击图片,出现:

这应该是一个不断变换nothing的访问,直到访问出正确的网页才会得到答案。
初始的nothing可以设置为12345

修改上面的程序:
import requests
import re def parse_one(name):
url = 'http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing={}'.format(name)
response = requests.get(url)
reponse_text = response.text
pattern = re.compile('(\d+)')
items = re.findall(pattern, reponse_text)[0]
print(items)
return parse_one(items) if __name__ == "__main__":
name = ''
parse_one(name)
运行到16044时发生错误,我们打开网页看下:

要求我们将16044/2继续进行,我们将16044/2继续进行,发现到82683又出现错误,其实错误出现在它的前一级82682:
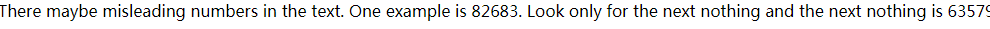
出现了2个误导,发现第二个是正确的nothing,换上正确的nothng继续执行.
最后得到最终的网页66831

第五关的url为:http://www.pythonchallenge.com/pc/def/peak.html
5 第五关

继续打开网页源代码,得到提示是

这个可能要使用python里面的pickle库
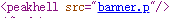
要解析这个banner.p,打开这个文件

一大串需要解析的数据,我们编写程序:
import pickle
import requests def parse_one():
url = 'http://www.pythonchallenge.com/pc/def/banner.p'
response = requests.get(url)
con = pickle.loads(response.text.encode())
for i in con:
print(''.join([j[0]*j[1] for j in i])) if __name__ == '__main__':
parse_one()
得到结果:
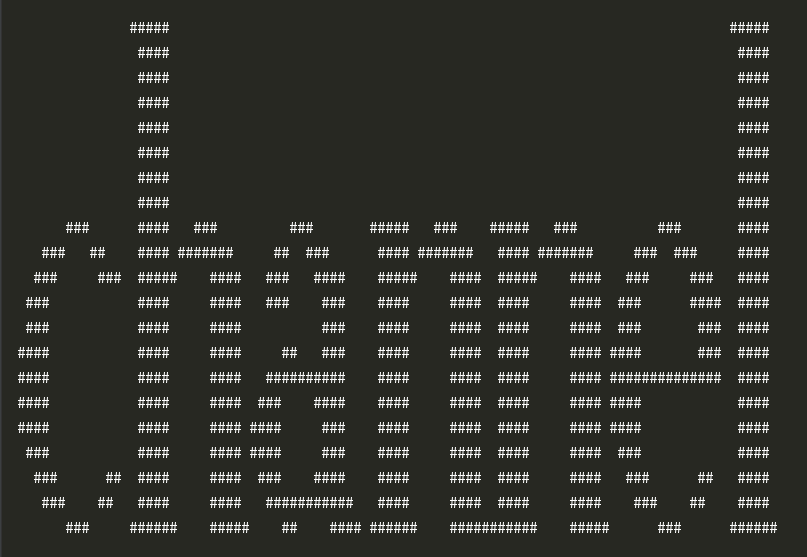
第六关的url为:http://www.pythonchallenge.com/pc/def/channel.html
6 第六关

照例查看源代码:

意思让捐钱,没看到其他有用的信息。注意到html换成了zip

然后把html换成了zip下载下来一个zip文件channel.zip
打开这个文件你会发现很多的txt文件
在其中找到了带有提示的文件readme.txt
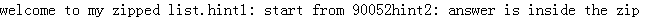
提示1:从90052开始:提示2:答案在zip里面,编写程序
import zipfile
import re def parse_one(name):
if name in file_name:
with file_zip.open(name, 'r') as f:
content = f.read().decode()
print(content)
next_file = re.findall('\d+', content)[0] + '.txt'
return parse_one(next_file) if __name__ == '__main__':
file_zip = zipfile.ZipFile(r'D:\workspace\pachong\ceshi\channel.zip')
file_name = file_zip.namelist()
parse_one('90052.txt')
发现报错得到结果

联想到zipfile的comment属性,于是修改代码
import zipfile
import re def parse_one(name):
if name in file_name:
with file_zip.open(name, 'r') as f:
content = f.read().decode()
com = file_zip.getinfo(name).comment
com_lst.append(com.decode())
print(content)
try:
next_file = re.findall('\d+', content)[0] + '.txt'
except Exception:
return None
return parse_one(next_file) if __name__ == '__main__':
file_zip = zipfile.ZipFile(r'D:\workspace\pachong\ceshi\channel.zip')
file_name = file_zip.namelist()
com_lst = []
parse_one('90052.txt')
print(''.join(com_lst))
得到结果:
第七关的url为:http://www.pythonchallenge.com/pc/def/hockey.html
打开网页为:

提示我们看得到的结果
所以第七关的url应该为http://www.pythonchallenge.com/pc/def/oxygen.html
7 第七关

只有一张图,查看源代码也没有发现任何提示,只好百度了下
首先,利用画图工具可得出该图片的像素是:629*95,再将这段马赛克区域的坐标提取出来:横坐标的范围是:0-609,纵坐标的范围是:43-53。
利用Image模块得到里面的像素列表
from PIL import Image def parse_picture(img):
data = [img.getpixel((i, j)) for i in range(0, 609) for j in range(43, 53)]
print(data) if __name__ == '__main__':
img = Image.open(r'D:\workspace\pachong\ceshi\oxygen.png', 'r')
parse_picture(img)
得到结果:

输出的像素是一个有着4个元素的元祖列表,其中每个元组里面的第四个元素都是255,并且每个元祖重复7次,那么如何将这些输出结果与答案联系?一般情况,答案的链接都是英文字母,那么可以尝试使用函数`chr`把这些ASCII码转换为字母。
修改代码:
from PIL import Image def parse_picture(img):
data = [chr(img.getpixel((i, j))[0]) for i in range(0, 609, 7) for j in range(43, 53, 7)]
new_dd = ''.join(data)
print(new_dd) # 看到所有的字符都是出现2个,遍历一下让每个字符都出现一次
new_d = ''
for i in range(0, len(new_dd), 2):
new_d += new_dd[i]
print(new_d) if __name__ == '__main__':
img = Image.open(r'D:\workspace\pachong\ceshi\oxygen.png', 'r')
parse_picture(img)
得到答案:
smart guy, you made it. the next level is [105, 110, 116, 101, 103, 114, 105, 116, 121]
将上述列表转换为字符:
str_lst = [105, 110, 116, 101, 103, 114, 105, 116, 121]
new_str = map(chr, str_lst)
print(''.join(new_str))
得到最终的字符串:integrity
第八关的url为:http://www.pythonchallenge.com/pc/def/integrity.html
8 第八关

查看源代码:

un和pw可能和usename和password有关,发现href="../return/good.html这个链接,打开确实是需要输入usename和password的,源代码中的un和pw可能就是username和password,可能是需要数据转换,BZh91AY&SY这是代表一种bzip2的压缩算法的.应该使用bz2模块,编写代码
import bz2 def main():
username = bz2.decompress(un)
password = bz2.decompress(pw)
print(username.decode(), password.decode()) if __name__ == '__main__':
un = b'BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084'
pw = b'BZh91AY&SY\x94$|\x0e\x00\x00\x00\x81\x00\x03$ \x00!\x9ah3M\x13<]\xc9\x14\xe1BBP\x91\xf08'
main()
注意:un,pw要作为bytes处理,得到答案:
huge file
输入后到达下一关:http://www.pythonchallenge.com/pc/return/good.html
the python challenge闯关记录(0-8)的更多相关文章
- the python challenge闯关记录(9-16)
9 第九关 是一张图,上面有很多的黑点,查看网页源代码发现了上一关的提示: 还发现了一大串的数字 感觉又是一个使用PIL库进行图像处理的题,百度后知道要将这些点连接起来并重新画图.但是不能在原始图上修 ...
- The Python Challenge 闯关笔记
The Python Challenge : http://www.pythonchallenge.com/ Level 0: 看提示图片中为2**38,计算值为274877906944. Hint: ...
- Python Challenge 第一关
偶然在网上看到这个,PYTHON CHALLENGE,利用Python语言闯关,觉得挺有意思,就记录一下. 第0关应该算个入口吧,试了好几次才试出来,没什么代码就不写了.计算一个结果出来就行. 第一关 ...
- Python Challenge 过关心得(0)
最近开始用Openerp进行开发,在python语言本身上并没有什么太大的进展,于是决定利用空闲时间做一点python练习. 最终找到了这款叫做Python Challenge(http://www. ...
- THEPYTHONCHALLENG闯关记录
由于是自己看视频学python,总觉得不写几行代码就什么都没有学到. 找了一个写代码的网站其实只是因为这个看起来好玩. 闯关地址http://www.pythonchallenge.com/index ...
- Python 爬虫闯关(第一关)
在学习爬虫时,遇到了一个有意思的网站,这个网站设置了几个关卡,需要经过爬虫进行闯关,随着关卡的网后,难度不断增加,在闯关的过程中需要学习不同的知识,你的爬虫水平也自然随之提高. 今天我们先来第一关,访 ...
- python函数编程闯关总结
文件处理相关 1,编码问题 (1)请问python2与python3中的默认编码是什么? python .x默认的字符编码是ASCII,默认的文件编码也是ASCII python .x默认的字符编码是 ...
- Python Challenge 第九关
第九关只有一幅图,上面有一些黑点.网页名字叫:connect the dots.可能是要把这些点连起来. 查看源代码,果然有两个整数集合 first 和 second.并且有个提示:first+sec ...
- Python Challenge 第二关
第二关和第一关一样,还是一幅图和一行提示.提示说的是: recognize the characters. maybe they are in the book, but MAYBE they are ...
随机推荐
- 使用腾讯云服务器CentOS搭建JavaWeb环境
yum list java* yum install java-1.7.0-openjdk* -y java -version cd /usr/local wget https://mc.qcloud ...
- 课堂小记---JavaScript(3)
操作DOM var newDOM=DOM元素.cloneNode(参数); 克隆(复制)当前节点,参数默认为false只复制当前节点元素.参数为true时复制当前元素及其后代和所有属性. day06 ...
- 今天分享三种方法实现Linux系统调用,感兴趣的朋友可以参考一下
系统调用(System Call)是操作系统为在用户态运行的进程与硬件设备(如CPU.磁盘.打印机等)进行交互提供的一组接口.当用户进程需要发生系统调用时,CPU 通过软中断切换到内核态开始执行内核系 ...
- JVM调优入门之初探
JVM:程序计数器,jvm栈,本地方法栈,堆,方法区 JVM:虚拟机内存又分有:年轻代(eden,servivor s0,servivor s1),年老代(tenured),永久代() 问题1:如何查 ...
- 20175305张天钰《java程序设计》第五周学习总结
<java程序设计>第五周学习总结 接口与实现 知识小点: (1)用Arrays.sort方法对所有实现Comparable接口的对象进行排序 (2)接口体现了has-a关系,继承体现了i ...
- redis深入了解
来自:https://www.cnblogs.com/lixinjie/p/a-key-point-of-redis-in-interview.html 是数据结构而非类型 很多文章都会说,redis ...
- 在ASP.NET Core 中怎样使用 EF 框架读取数据库数据
添加测试数据 我们首先使用 SQLite Studio 添加三条数据 ID Name 1 李白 2 杜甫 3 白居易 使用 SQLite Studio 打开我们的 blogging.db 数据库,双击 ...
- Sightseeing trip POJ - 1734 -Floyd 最小环
POJ - 1734 思路 : Floyd 实质 dp ,优化掉了第三维. dp [ i ] [ j ] [ k ] 指的是前k个点优化后 i -> j 的最短路. 所以我们就可以 ...
- spring 应用
Spring框架本身会托管bean. 1.使用时需要注意对于包本身扫描配置. 2.使用注解本身包需要在扫描路径下.
- 华为ssh远程登录,配置