分布式系列九: kafka
分布式系列九: kafka概念
官网上的介绍是kafka是apache的一种分布式流处理平台. 最初由Linkedin开发, 使用Scala编写. 具有高性能,高吞吐量的特定.
包含三个关键能力:
- 发布/订阅, 类似于消息队列或企业消息系统;
- 容错容忍
- 即时处理流记录
## 适合的应用场景
因为其高性能,高吞吐量,时效性等特定, 同时内置的集群,分区, 复制支持, 使其更适合于处理大规模消息能力. 一些大数据相关的场景, 比如日志收集, 消息系统, 用户行为分析, 运营指标数据-服务器性能数据, 实时流处理统计等均可用kafka.
安装和集群配置
如同其他组件一样, 下载解压后, 使用
bin目录下的脚本启动.转到
config目录下, 此目录下的文件时kafka的配置文件.server.properties文件中的broker.id节点表示集群的本机的节点id. 例如:broker.id=1;
server.properties文件中的listeners节点配置本机ip, 否则启动会报错. 例如:listeners=PLAINTEXT://192.168.1.11:9092
其他比较重要的节点:
num.partitions=1topic的分区数量.
log.dirs=/tmp/kafka-logslog日志目录server.properties文件的zookeeper.connect=ip1:2181,ip2:2181配置zookeeper集群的链接,逗号分割各zookeeper地址.
kafka架构
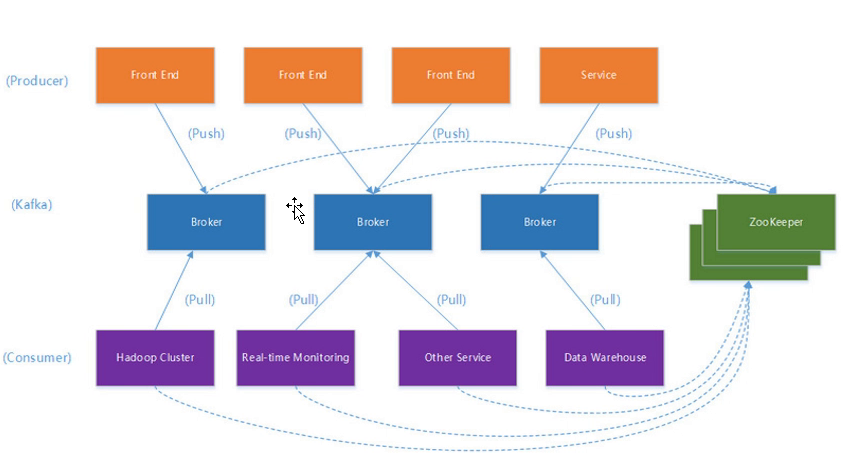
其中 broker 可以理解为kafka的一个服务, 多个broker组成kafka的一个集群.
kafka通过zookeeper做集群管理.
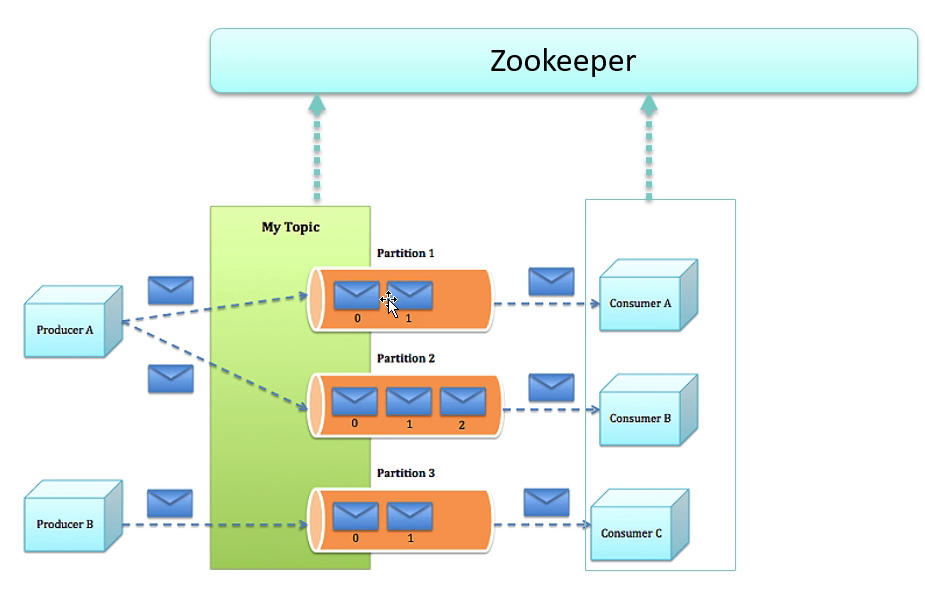
topic 是kafka存储流记录的类别. 一个topic可能对应对个分区partition.
consumer group 消费者可以按节点划分为若干组, 组内只有一个consumer可以处理同一个消息.但组之间都可以接收同一消息.
kafka实现
几个重要概念
- kafka在一个或多个能跨多个数据中心的节点服务器组成的集群上运行
- kafka集群存储的记录流是称为
topics的类型 - 每个记录由key,value以及timestamp组成
kafka包含四个核心API
- Producer
- Consumer
- Streams : 以流处理器的形式,将一个或多个topics输入流消费为一个或多个输出的topics.
- Connector : 构建和运行可重用的, 连接kafka的topics到已有程序或数据系统的生产者或消费者程序. 例如, 连接到关系数据库中的表, 捕获对其的任何更改.
Topics和日志
kafka 的 topics 总是多端注册的. 一个 topic 可能有0个或多个订阅到其写入的数据的消费者.
topics 维护了一个 partition 组的日志. 每个 partition 其中的每个记录都是顺序的, 不可变的. 每条记录都有给其分配的序列id, 叫做offset.
kafka 集群使用配置的保留周期持久化保存了所有的记录, 不管是否被消费. 例如, 如果保留策略为2天, 那一条记录被发布后的两天内都是可以被消费的,过后其将被丢弃以腾出空间.
消费者其实仅保留了offset. 消费者可以根据这个offset线性读取记录, 但也可以控制offset来处理历史数据或跳过最近的记录.
分区的目的: 一是伸缩性得到保证;二是每个分区可以作为一个并行单元.
分布式
可以为每个分区设置0个或多个容错备份.
对于每个分区都有leader和follower, leader处理读写请求, follower同步leader, leader下线后,follower中会自动选举出新的leader. 每个服务器都作为某些分区的leader以及其他分区的follower, 这样就实现了负载均衡.
消费者
消费者使用consumer group名称标记它们. consumer group相同的消费者将作为一个整体,仅消费一次. 如果每个消费者都有各自的group, 那每个记录将广播给所有的消费者处理. 如果所有的消费者都标记为同一个group, 则这些消费者之间以负载均衡的形式执行消费.
将若干constomer标记为一个group一般用来做容错和负载均衡.
kafka作为消息系统
基于queue的消息系统和pub/sub的消息系统都有各自的优缺点. queue 的特点是记录从消费者的池中选择一个来进行处理, pub/sub 的特定是广播给所有消费者. 因此, queue可以在多个实例间分片处理, 不幸的是queue无法广播, 一旦读取数据就不存在了. pub/sub 允许广播, 但无法伸缩处理, 因为消息广播给所有消费者了.
kafka 可以使用 consumer group 来实现两种概念. 同时其也有队列系统的顺序保证. 因此kafka做的更好, 因为partition的存在, 可以使得队列顺序性和可伸缩性同时得到保证, 但要注意, 消费者实例不能多余分区数.
kafka作为存储系统
数据写入kafka的磁盘并且可以复制容错. kafka允许生产者等到确认, 这样就能保证数据被真正持久化了. 另外, 分布式结构很好使用了伸缩性.
kafka可视为一种专用于高性能, 低延迟的日志存储分布式文件系统.
kafka用于流处理
它使用生产者和消费者API进行输入,使用Kafka进行有状态存储,并在流处理器实例之间使用相同的组机制来实现容错。
适用的场景是处理无序数据, 代码修改后的重新处理, 执行有序状态计算.
组合使用
消息系统, 存储系统, 和实时流处理可以在适当的场景组合使用.
分布式系列九: kafka的更多相关文章
- kafka系列九、kafka事务原理、事务API和使用场景
一.事务场景 最简单的需求是producer发的多条消息组成一个事务这些消息需要对consumer同时可见或者同时不可见 . producer可能会给多个topic,多个partition发消息,这些 ...
- 搞懂分布式技术21:浅谈分布式消息技术 Kafka
搞懂分布式技术21:浅谈分布式消息技术 Kafka 浅谈分布式消息技术 Kafka 本文主要介绍了这几部分内容: 1基本介绍和架构概览 2kafka事务传输的特点 3kafka的消息存储格式:topi ...
- 分布式消息队列 Kafka
分布式消息队列 Kafka 2016-02-25 杜亦舒 Kafka是一个高吞吐量的.分布式的消息系统,由Linkedin开发,开发语言为scala具有高吞吐.可扩展.分布式等特点 适用场景 活动数据 ...
- java基础解析系列(九)---String不可变性分析
java基础解析系列(九)---String不可变性分析 目录 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)---In ...
- java多线程系列(九)---ArrayBlockingQueue源码分析
java多线程系列(九)---ArrayBlockingQueue源码分析 目录 认识cpu.核心与线程 java多线程系列(一)之java多线程技能 java多线程系列(二)之对象变量的并发访问 j ...
- Kafka系列之-Kafka入门
接下来的这些博客,主要内容来自<Learning Apache Kafka Second Edition>这本书,书不厚,200多页.接下来摘录出本书中的重要知识点,偶尔参考一些网络资料, ...
- 后端分布式系列:分布式存储-HDFS 与 GFS 的设计差异
「后端分布式系列」前面关于 HDFS 的一些文章介绍了它的整体架构和一些关键部件的设计实现要点. 我们知道 HDFS 最早是根据 GFS(Google File System)的论文概念模型来设计实现 ...
- 分布式系列四: HTTP及HTTPS协议
分布式系列四: HTTP及HTTPS协议 非常全面的一篇HTTP的文章: 关于HTTP协议,一篇就够了 还有一个帮助理解HTTPS的文章: 也许,这样理解HTTPS更容易 本文的一些描述摘自这篇文章 ...
- 分布式系列六: WebService简介
WebSerice盛行的时代已经过去, 这里只是简单介绍下其基本概念, 并用JDK自带的API实现一个简单的服务. WebSerice的概念 WebService是一种跨平台和跨语言的远程调用(RPC ...
随机推荐
- Batch Normalization的解释
输入的标准化处理是对图片等输入信息进行标准化处理,使得所有输入的均值为0,方差为1 normalize = T.Normalize([0.485, 0.456, 0.406],[0.229, 0.22 ...
- 基于nodejs的流水线式的CRUD服务。依赖注入可以支持插件。
写代码好多年了,发现大家的思路都是写代码.写代码.写代码,还弄了个称号——码农. 我是挺无语的,我的思路是——不写代码.不写代码.不写代码! 无聊的代码为啥要重复写呢?甚至一写写好几年. 举个例子吧, ...
- js实现分段上传文件
使用js实现分段上传文件,本文使用了FileReader对象,可参考:https://developer.mozilla.org/zh-CN/docs/Web/API/FileReader 1)获取文 ...
- windows安全更新程序(KB4093112) 安装失败 错误0x80070011
解决办法:win + R → 输入regedi 将默认安装路径改回C盘的program files
- java集合-HashSet源码解析
HashSet 无序集合类 实现了Set接口 内部通过HashMap实现 // HashSet public class HashSet<E> extends AbstractSet< ...
- FreeMarker 入门
目录 FreeMarker是什么 为什么要学习FreeMarker FreeMarker相关站点
- C#技巧记录——持续更新
作为一名非主修C#的程序员,在此记录下学习与工作中C#的有用内容,持续更新 对类型进行约束,class指定了类型必须是引用类型,new()指定了类型必须具有一个无参的构造函数 where T : cl ...
- [转帖]Shell脚本中的break continue exit return
Shell脚本中的break continue exit return 转自:http://www.cnblogs.com/guosj/p/4571239.html break结束并退出循环 cont ...
- Sass 笔记
Sass 笔记 1. 安装,依赖Ruby sass依赖Ruby, 所以Windows要先安装Ruby, Mac自带无需安装 $ gem install sass 2. 两种文件格式 sass scss ...
- BigDecimal(大浮点数)
因为这个单词,和他的四则运算方法总是记不住,所以写入博客,在没有印象的时候再看看自己的博客. BigDecimal的加减乘除不和double float 一样,他需要使用方法来进行加减乘除. 加法:a ...