数据分片一致性hash
一致性hash
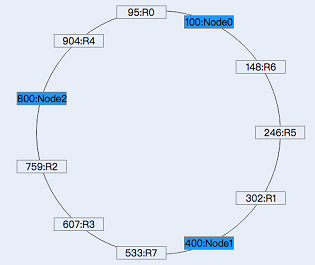
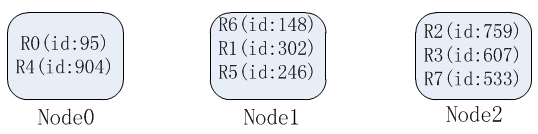
可以看到相比于上述的hash方式,一致性hash方式需要维护的元数据额外包含了节点在环上的位置,但这个数据量也是非常小的。
一致性hash在增加或者删除节点的时候,受到影响的数据是比较有限的,比如这里增加一个节点N3,其在环上的位置为600,因此,原来N2负责的范围段(400, 800]现在由N2(400, 600] N3(600, 800]负责,因此只需要将记录R2(id:759), R3(id: 607) 从N2,迁移到N3:
但是,一致性hash方式在增加节点的时候,只能分摊一个已存在节点的压力;同样,在其中一个节点挂掉的时候,该节点的压力也会被全部转移到下一个节点。我们希望的是“一方有难,八方支援”,因此需要在增删节点的时候,已存在的所有节点都能参与响应,达到新的均衡状态。
因此,在实际工程中,一般会引入虚拟节点(virtual node)的概念。即不是将物理节点映射在hash换上,而是将虚拟节点映射到hash环上。虚拟节点的数目远大于物理节点,因此一个物理节点需要负责多个虚拟节点的真实存储。操作数据的时候,先通过hash环找到对应的虚拟节点,再通过虚拟节点与物理节点的映射关系找到对应的物理节点。
引入虚拟节点后的一致性hash需要维护的元数据也会增加:第一,虚拟节点在hash环上的问题,且虚拟节点的数目又比较多;第二,虚拟节点与物理节点的映射关系。但带来的好处是明显的,当一个物理节点失效是,hash环上多个虚拟节点失效,对应的压力也就会发散到多个其余的虚拟节点,事实上也就是多个其余的物理节点。在增加物理节点的时候同样如此。
工程中,Dynamo、Cassandra都使用了一致性hash算法,且在比较高的版本中都使用了虚拟节点的概念。在这些系统中,需要考虑综合考虑数据分布方式和数据副本,当引入数据副本之后,一致性hash方式也需要做相应的调整, 可以参加cassandra的相关文档。
具体Java实现:将真实节点虚拟节点以hashcode为key放入map中并根据hashcode值排序,根据参数的hashcode获取大于该hashcode的子map集合,这个子map集合的第一个节点就是要命中的节点,如果没有取到子map就获取大map的第一个节点
https://www.cnblogs.com/xybaby/p/7076731.html
http://www.jb51.net/article/124819.htm
String s =“Java”,那么计算机会先计算散列码,然后放入相应的数组中,数组的索引就是从散列码计算来的,然后再装入数组里的容器里,如List.这就相当于把你要存的数据分成了几个大的部分,然后每个部分存了很多值, 你查询的时候先查大的部分,再在大的部分里面查小的,这样就比先行查询要快很多
MongoDB
哈希算法:
可以将任意长度的二进制值映射为较短的,固定长度的二进制值。我们把这个二进制值成为哈希值
哈希值的特点:
* 哈希值是二进制值;
* 哈希值具有一定的唯一性;
* 哈希值极其紧凑;
* 要找到生成同一个哈希值的2个不同输入,在一定时间范围内,是不可能的。
哈希表:
哈希表是一种数据机构。哈希表根据关键字(key),生成关键字的哈希值,然后通过哈希值映射关键字对应的值。哈希表存储了多
余的key(我们本可以只存储值的),是一种用空间换时间的做法。在内存足够的情况下,这种“空间换时间”的做法是值得的。哈希表的
产生,灵感来源于数组。我们知道,数组号称查询效率最高的数据结构,因为不管数组的容量多大,查询的时间复杂度都是O(1)。如果
所有的key都是不重复的整数,那么这就完美了,不需要新增一张哈希表,来做关键字(key)到值(value)的映射。但是,如果key是
字符串,情况就不一样了。我们必须要来建一张哈希表,进行映射。
数据库索引的原理,其实和哈希表是相同的。数据库索引也是用空间换时间的做法
//String的hash值计算 哈希算法在String类中的应用
@Test
public void test1(){
String str = "qaz";
char value[] = str.toCharArray();
int h = 0;
if ( value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
}
System.out.println(h);
}
char类型是可以运算的因为char在ASCII等字符编码表中有对应的数值
System.out.println('a'+" "+(0+'q')+" "+(0+'a')+" :"+('a'+'q'));
a 113 97 :210
就拿jdk中String类的哈希方法来举例,字符串"gdejicbegh"与字符串"hgebcijedg"具有相同的hashCode()返回值-801038016,并且它们具有reverse的关系。这个例子说明了用jdk中默认的hashCode方法判断字符串相等或者字符串回文,都存在反例。
因为不同的对象可能会生成相同的hashcode值
两个对象的hashcode值不等,则必定是两个不同的对象
hash权重算法的要素及原理:
大家都知道,计算机的乘法涉及到移位计算。当一个数乘以2时,就直接拿该数左移一位即可!选择31原因是因为31是一个素数!
所谓素数:
质数又称素数。指在一个大于1的自然数中,除了1和此整数自身外,没法被其他自然数整除的数。
在存储数据计算hash地址的时候,我们希望尽量减少有同样的hash地址,所谓“冲突”。如果使用相同hash地址的数据过多,那么这些数据所组成的hash链就更长,从而降低了查询效率!所以在选择系数的时候要选择尽量长(31 = 11111[2])的系数并且让乘法尽量不要溢出(如果选择大于11111的数,很容易溢出)的系数,因为如果计算出来的hash地址越大,所谓的“冲突”就越少,查找起来效率也会提高。
31的乘法可以由i*31== (i<<5)-1来表示,现在很多虚拟机里面都有做相关优化,使用31的原因可能是为了更好的分配hash地址,并且31只占用5bits!
在java乘法中如果数字相乘过大会导致溢出的问题,从而导致数据的丢失.
而31则是素数(质数)而且不是很长的数字,最终它被选择为相乘的系数的原因不过与此!
.hashCode方法的作用
对于包含容器类型的程序设计语言来说,基本上都会涉及到hashCode。在Java中也一样,hashCode方法的主要作用是为了配合基于散列的集合一起正常运行,这样的散列集合包括HashSet、HashMap以及HashTable。
为什么这么说呢?考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:集合中不允许重复的元素存在)
也许大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了,当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值,实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了,说通俗一点:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。下面这段代码是java.util.HashMap的中put方法的具体实现
put方法是用来向HashMap中添加新的元素,从put方法的具体实现可知,会先调用hashCode方法得到该元素的hashCode值,然后查看table中是否存在该hashCode值,如果存在则调用equals方法重新确定是否存在该元素,如果存在,则更新value值,否则将新的元素添加到HashMap中。从这里可以看出,hashCode方法的存在是为了减少equals方法的调用次数,从而提高程序效率
设计一个类的时候为需要重写equals方法,比如String类,但是千万要注意,在重写equals方法的同时,必须重写hashCode方法
比如设计一个peple类equals方法为 return this.name.equals(((People)obj).name) && this.age== ((People)obj).age; 当把一个people实例作为key放入hashmap再去取的时候(new一个相同姓名年龄的对象)取不到,因为两个实例的hashcode不一致,具体参考hashmap的get方法,如果重写hashcode的方法则没问题return name.hashCode()*37+age;但是,如果name值经常变换,equals方法和hashCode方法中不要依赖于该字段
public static void main(String[] args) {
People p1 = new People("Jack", 12);
System.out.println(p1.hashCode());
HashMap<People, Integer> hashMap = new HashMap<People, Integer>();
hashMap.put(p1, 1);
p1.setAge(13);
System.out.println(hashMap.get(p1));
}
这段代码输出的结果为“null”,想必其中的原因大家应该都清楚了。
因此,在设计hashCode方法和equals方法的时候,如果对象中的数据易变,则最好在equals方法和hashCode方法中不要依赖于该字段
package cn.com.gome.gcoin.util; import java.util.SortedMap;
import java.util.TreeMap; /**
* @author cyq
* 一致性性hash获取对应表
*/
public class ConsistentHashingWithTable {
//自定义分表数量,原引用gcoin-commons包的常量,但是影响spa转移系统,注意后续维护时候保持统一
private static int TRANSACTION_TABLE_NUM = 20;
// 待添加入Hash环的交易表列表
private static String[] transactionTable = new String[TRANSACTION_TABLE_NUM];
static{
for(int ci=0;ci<TRANSACTION_TABLE_NUM;ci++){
transactionTable[ci] = "tbl_account_transaction"+ci;
}
} // key表示交易表的hash值,value表示交易表
private static SortedMap<Integer, String> sortedMap = new TreeMap<Integer, String>();
//虚拟节点的数目,这里写死,为了演示需要,一个真实结点对应10个虚拟节点
private static final int VIRTUAL_NODES = 10; // 程序初始化,将所有的交易表放入sort交易表ap中
static {
for (int i = 0; i < transactionTable.length; i++) {
int hash = getHash(transactionTable[i]);
System.out.println("[" + transactionTable[i] + "]加入集合中, 其Hash值为"
+ hash);
sortedMap.put(hash, transactionTable[i]);
//再添加虚拟节点,遍历LinkedList使用foreach循环效率会比较高
for(int j=0; j<VIRTUAL_NODES; j++){
String virtualNodeName = transactionTable[i] + "&&VN" + String.valueOf(j);
int hashVN = getHash(virtualNodeName);
System.out.println("虚拟节点[" + virtualNodeName + "]被添加, hash值为" + hashVN);
sortedMap.put(hashVN, transactionTable[i]);
}
}
} // 得到应当路由到的结点
public static String getServer(String key) {
// 得到该key的hash值
int hash = getHash(key);
// 得到大于该Hash值的所有Map
SortedMap<Integer, String> subMap = sortedMap.tailMap(hash);
if (subMap.isEmpty()) {
// 如果没有比该key的hash值大的,则从第一个node开始
Integer i = sortedMap.firstKey();
// 返回对应的交易表
return sortedMap.get(i);
} else {
// 第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
// 返回对应的交易表
return subMap.get(i);
}
} // 使用FNV1_32_HASH算法计算交易表的Hash值,这里不使用重写hashCode的方法,最终效果没区别
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5; // 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
} public static void main(String[] args) {
String[] keys = { "73968928317", "73099946651", "72563328728",
"73967405000", "73968349990", "72112754519", "72088646347",
"74728589363", "73955634071", "73099946613", "72563228728",
"73967477000", "73968649990", "72112769519", "72088796347",
"74728333363", "73955688071" };
for (int i = 0; i < keys.length; i++)
System.out.println("[" + keys[i] + "]的hash值为" + getHash(keys[i])+ ", 被路由到结点[" + getServer(keys[i]) + "]");
}
}
数据分片一致性hash的更多相关文章
- 《大数据日知录》读书笔记-ch1数据分片与路由
目前主流大数据存储使用横向扩展(scale out)而非传统数据库纵向扩展(scale up)的方式.因此涉及数据分片.数据路由(routing).数据一致性问题 二级映射关系:key-partiti ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
- Mycat 分片规则详解--一致性hash分片
实现方式:基于hash算法的分片中,算法内部是把记录分片到一种叫做"bucket"(hash桶)的内部算法结构中的,然后hash桶与实际的分片节点一一对应,从此实现了分片.路由的功 ...
- Dynamo涉及的算法和协议——p2p架构,一致性hash容错+gossip协议获取集群状态+向量时钟同步数据
转自:http://www.letiantian.me/2014-06-16-dynamo-algorithm-protocol/ Dynamo是Amazon的一个分布式的键值系统,P2P架构,没有主 ...
- 大数据 --> 一致性Hash算法
一致性Hash算法 一致性Hash算法(Consistent Hash)
- 探索c#之一致性Hash详解
阅读目录: 使用场景 算法原理 虚拟节点 代码示例 使用场景 以Redis为例,当系统需要缓存的内容超过单机内存大小时,例如要缓存100G数据,单机内存仅有16G时.这时候就需要考虑进行缓存数据分片, ...
- 一致性Hash算法及使用场景
一.问题产生背景 在使用分布式对数据进行存储时,经常会碰到需要新增节点来满足业务快速增长的需求.然而在新增节点时,如果处理不善会导致所有的数据重新分片,这对于某些系统来说可能是灾难性的. 那 ...
- php一致性hash算法的应用
阅读这篇博客前首先你需要知道什么是分布式存储以及分布式存储中的数据分片存储的方式有哪些? 分布式存储系统设计(2)—— 数据分片 阅读玩这篇文章后你会知道分布式存储的最优方案是使用 一致性hash算法 ...
- 一致性hash算法及java实现
一致性hash算法是分布式中一个常用且好用的分片算法.或者数据库分库分表算法.现在的互联网服务架构中,为避免单点故障.提升处理效率.横向扩展等原因,分布式系统已经成为了居家旅行必备的部署模式,所以也产 ...
随机推荐
- requirejs的使用和快速理解
样例来自https://www.jianshu.com/p/b8a6824c8e07 requirejs有以下功能 声明不同js文件之间的依赖 可以按需.并行.延时载入js库 可以让我们的代码以模块化 ...
- Java中的字符串截取(substring)的使用
import java.util.*; public class ZiFu { public static void main(String args[]){ System.out.println(& ...
- F#周报2019年第12期
新闻 Amazon.Lambda.RuntimeSupport发布 Forge 3.0架构 Blazor 0.9.0试验版发布 通过微软游戏栈实现更多应用 介绍ASP.NET Core中的gRPC M ...
- io 口方向调整 stm32
zonggo//IO方向设置 CRL为0-7 CRH为 8-15 总共四个寄存器位置有效#define DS18B20_IO_IN() {GPIOB->CRH&=0X0FFFFFFF;G ...
- [Day18]集合框架Collection、迭代器、增强for循环以及泛型
1.集合 1.1集合-本身是一个存储的容器 集合类的基本接口是Collection接口,这个接口有两个基本方法 (1)boolean add(E element) 用于向集合中添加元素,如果添加元素确 ...
- JavaWeb的学习路线
JavaWeb的学习路线 一.BS结构 B/S结构(Browser/Server,浏览器/服务器模式),是WEB兴起后的一种网络结构模式,WEB浏览器是客户端最主要的应用软件.这种模式统一了客户端,将 ...
- memory error python报错
np.array时报错内存溢出,检查了python安装的是64位版本,通过下面dtype=np.uint8不再报错texts_vec = (np.array(texts_vec,dtype=np.ui ...
- FindVisualChild
public static List<T> FindVisualChild<T>(DependencyObject obj) where T : DependencyObjec ...
- 【托业】【跨栏】TEST05
22 23 21. 22 23 24 25 REVIEW TEST05
- Spring+Mybatis 复杂的分组查询
1.需要的结果数据格式为 { "responseCode": "0000", "responseMsg": null, "data ...