R语言之数据处理常用包
dplyr包是Hadley Wickham的新作,主要用于数据清洗和整理,该包专注dataframe数据格式,从而大幅提高了数据处理速度,并且提供了与其它数据库的接口;tidyr包的作者是Hadley Wickham, 该包用于“tidy”你的数据,这个包常跟dplyr结合使用。
dplyr、tidyr包安装及载入
install.packages("dplyr")
install.packages("tidyr")
library(dplyr)
library(tidyr)
使用datasets包中的mtcars数据集做演示,首先将过长的数据整理成友好的tbl_df数据:
mtcars_df = tbl_df(mtcars)
一、dplyr包基本操作
1.1 筛选: filter()
按给定的逻辑判断筛选出符合要求的子数据集
filter(mtcars_df,mpg==21,hp==110) # A tibble: 2 x 11
mpg cyl disp hp drat wt qsec vs am gear carb
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 21 6 160 110 3.9 2.620 16.46 0 1 4 4
2 21 6 160 110 3.9 2.875 17.02 0 1 4 4
1.2 排列: arrange()
按给定的列名依次对行进行排序:
arrange(mtcars_df, disp) #可对列名加 desc(disp) 进行倒序 # A tibble: 32 x 11
mpg cyl disp hp drat wt qsec vs am gear carb
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
2 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
3 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
4 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
5 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
6 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
7 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
8 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
9 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
10 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
# ... with 22 more rows
1.3 选择: select()
用列名作参数来选择子数据集:
select(mtcars_df, disp:wt) # A tibble: 32 x 4
disp hp drat wt
* <dbl> <dbl> <dbl> <dbl>
1 160.0 110 3.90 2.620
2 160.0 110 3.90 2.875
3 108.0 93 3.85 2.320
4 258.0 110 3.08 3.215
5 360.0 175 3.15 3.440
6 225.0 105 2.76 3.460
7 360.0 245 3.21 3.570
8 146.7 62 3.69 3.190
9 140.8 95 3.92 3.150
10 167.6 123 3.92 3.440
# ... with 22 more rows
1.4 变形: mutate()
对已有列进行数据运算并添加为新列:
mutate(mtcars_df,
NO = 1:dim(mtcars_df)[1]) # A tibble: 32 x 12
mpg cyl disp hp drat wt qsec vs am gear carb NO
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
1 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4 1
2 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4 2
3 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1 3
4 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1 4
5 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2 5
6 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1 6
7 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4 7
8 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2 8
9 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2 9
10 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4 10
# ... with 22 more rows
1.5 汇总: summarise()
对数据框调用其它函数进行汇总操作, 返回一维的结果:
summarise(mtcars_df,
mdisp = mean(disp, na.rm = TRUE))
# A tibble: 1 x 1
mdisp
<dbl>
1 230.7219
1.6 分组: group_by()
当对数据集通过group_by()添加了分组信息后,mutate(),arrange() 和 summarise() 函数会自动对这些 tbl 类数据执行分组操作。
cars <- group_by(mtcars_df, cyl)
countcars <- summarise(cars, count = n()) # count = n()用来计算次数 # A tibble: 3 x 2
cyl count
<dbl> <int>
1 4 11
2 6 7
3 8 14
Batting %>%group_by(playerID) %>%summarise(total = sum(G)) %>%arrange(desc(total)) %>%head(5)
二、tidyr包基本操作
2.1 宽转长:gather()
使用gather()函数实现宽表转长表,语法如下:
gather(data, key, value, …, na.rm = FALSE, convert = FALSE)
data:需要被转换的宽形表
key:将原数据框中的所有列赋给一个新变量key
value:将原数据框中的所有值赋给一个新变量value
…:可以指定哪些列聚到同一列中
na.rm:是否删除缺失值 widedata <- data.frame(person=c('Alex','Bob','Cathy'),grade=c(2,3,4),score=c(78,89,88))
widedata
person grade score
1 Alex 2 78
2 Bob 3 89
3 Cathy 4 88
longdata <- gather(widedata, variable, value,-person)
longdata
person variable value
1 Alex grade 2
2 Bob grade 3
3 Cathy grade 4
4 Alex score 78
5 Bob score 89
6 Cathy score 88
2.2 长转宽:spread()
有时,为了满足建模或绘图的要求,往往需要将长形表转换为宽形表,或将宽形表变为长形表。如何实现这两种数据表类型的转换。使用spread()函数实现长表转宽表,语法如下:
spread(data, key, value, fill = NA, convert = FALSE, drop = TRUE)
data:为需要转换的长形表
key:需要将变量值拓展为字段的变量
value:需要分散的值
fill:对于缺失值,可将fill的值赋值给被转型后的缺失值 mtcarsSpread <- mtcarsNew %>% spread(attribute, value)
head(mtcarsSpread)
car am carb cyl disp drat gear hp mpg qsec vs wt
1 AMC Javelin 0 2 8 304 3.15 3 150 15.2 17.30 0 3.435
2 Cadillac Fleetwood 0 4 8 472 2.93 3 205 10.4 17.98 0 5.250
3 Camaro Z28 0 4 8 350 3.73 3 245 13.3 15.41 0 3.840
4 Chrysler Imperial 0 4 8 440 3.23 3 230 14.7 17.42 0 5.345
5 Datsun 710 1 1 4 108 3.85 4 93 22.8 18.61 1 2.320
6 Dodge Challenger 0 2 8 318 2.76 3 150 15.5 16.87 0 3.520
2.3 合并:unit()
unite的调用格式如下:
unite(data, col, …, sep = “_”, remove = TRUE)
data:为数据框
col:被组合的新列名称
…:指定哪些列需要被组合
sep:组合列之间的连接符,默认为下划线
remove:是否删除被组合的列 wideunite<-unite(widedata, information, person, grade, score, sep= "-")
wideunite
information
1 Alex-2-78
2 Bob-3-89
3 Cathy-4-88
2.4 拆分:separate()
separate()函数可将一列拆分为多列,一般可用于日志数据或日期时间型数据的拆分,语法如下:
separate(data, col, into, sep = “[^[:alnum:]]+”, remove = TRUE,
convert = FALSE, extra = “warn”, fill = “warn”, …)
data:为数据框
col:需要被拆分的列
into:新建的列名,为字符串向量
sep:被拆分列的分隔符
remove:是否删除被分割的列 widesep <- separate(wideunite, information,c("person","grade","score"), sep = "-")
widesep
person grade score
1 Alex 2 78
2 Bob 3 89
3 Cathy 4 88
三、data.table
R语言data.table包是自带包data.frame的升级版,用于数据框格式数据的处理,最大的特点快。包括两个方面,一方面是写的快,代码简洁,只要一行命令就可以完成诸多任务,另一方面是处理快,内部处理的步骤进行了程序上的优化,使用多线程,甚至很多函数是使用C写的,大大加快数据运行速度。因此,在对大数据处理上,使用data.table无疑具有极高的效率。这里我们主要讲的是它对数据框结构的快捷处理。
可见separate()函数和unite()函数的功能相反。
和data.frame的高度兼容
DT = data.table(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
下面DT都是用这个data.table
可见它是属于data.table和data.frame类,并且取列,维数,都可以采用data.frame的方法。
DF = data.frame(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
DT = data.table(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9)
DF
DT
identical(dim(DT), dim(DF)) # TRUE
identical(DF$a, DT$a) # TRUE
is.list(DF) # TRUE
is.list(DT) # TRUE
is.data.frame(DT) # TRUE
不过data.frame默认将非数字转化为因子;而data.table 会将非数字转化为字符
data.table数据框也可使用dplyr包的管道,这里不作阐述。
data.table常用的函数
as.data.table(x, keep.rownames=FALSE, ...) 将一个R对象转化为data.table,R可以时矢量,列表,data.frame等,keep.rownames决定是否保留行名或者列表名,默认FALSE,如果TRUE,将行名存在"rn"行中,keep.rownames="id",行名保存在"id"行中。
DF = data.frame(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9) #新建data.frame DF
DT=as.data.table(DF,keep.rownames=TRUE)
setDT(x, keep.rownames=FALSE, key=NULL, check.names=FALSE) 把一个R对象转化为data.table,比as.data.table快,因为以传地址的方式直接修改原对象,没有拷贝
copy(x) 深度拷贝一个data.table,x即data.table对象。data.table为了加快速度,会直接在对象地址修改,因此如果需要就要在修改前copy,直接修改的命令有:=添加一列,set系列命令比如下面提到的setattr,setnames,setorder等;当使用dt_names = names(DT)的时候,修改dt_names会修改原data.table的列名,如果不想被修改,这个时候应copy原data.table,也可以使用dt_names <- copy(names(DT))直接copy列名,这样不必copy整个data.table。
kDT=copy(DT) #kDT时DT的一个copy
rowid(..., prefix=NULL) 产生unique的id,prefix参数在id前面加前缀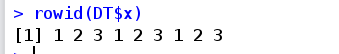
setattr 设置DT的属性,setattr(x,name,value) x时data.table,list或者data.frame,而name时属性名,value时属性值,setnames(x,old,new),设置x的列名,old是旧列名或者数字位置,new是新列名
setcolorder(x,neworder) 重新安排列的顺序,neworder字符矢量或者行数
set(DT,rownum,colnum,value)直接修改某个位置的值,rownum行号,colnum,列号,行号列号推荐使用整型,保证最快速度,方法是在数字后面加L,比如1L,value是需要赋予的值。比:=还快,通常和循环配合使用
至于这个操作究竟有多快,可以看一下(参照官方manual的命令),另外个人觉得最牛的三个函数是set(),fread,和fwrite
fread
fread(input, sep="auto", sep2="auto", nrows=-1L, header="auto", na.strings="NA", file,
stringsAsFactors=FALSE, verbose=getOption("datatable.verbose"), autostart=1L,
skip=0L, select=NULL, drop=NULL, colClasses=NULL,
integer64=getOption("datatable.integer64"),
# default: "integer64"
dec=if (sep!=".") "." else ",", col.names,
check.names=FALSE, encoding="unknown", quote="\"",
strip.white=TRUE, fill=FALSE, blank.lines.skip=FALSE, key=NULL,
showProgress=getOption("datatable.showProgress"), # default: TRUE
data.table=getOption("datatable.fread.datatable") # default: TRUE
)
input输入的文件,或者字符串(至少有一个"\n");
sep列之间的分隔符;
sep2,分隔符内再分隔的分隔符,功能还没有应用;
nrow,读取的行数,默认-l全部,nrow=0仅仅返回列名;
header第一行是否是列名;
na.strings,对NA的解释;
file文件路径,再确保没有执行shell命令时很有用,也可以在input参数输入;
stringsASFactors是否转化字符串为因子,
verbose,是否交互和报告运行时间;
autostart,机器可读这个区域任何行号,默认1L,如果这行是空,就读下一行;
skip跳过读取的行数,为1则从第二行开始读,设置了这个选项,就会自动忽略autostart选项,也可以是一个字符,skip="string",那么会从包含该字符的行开始读;
select,需要保留的列名或者列号,不要其它的;
drop,需要取掉的列名或者列号,要其它的;
colClasses,类字符矢量,用于罕见的覆盖而不是常规使用,只会使一列变为更高的类型,不能降低类型;
integer64,读如64位的整型数;
dec,小数分隔符,默认"."不然就是","
col.names,给列名,默认试用header或者探测到的,不然就是V+列号;
encoding,默认"unknown",其它可能"UTF-8"或者"Latin-1",不是用来重新编码的,而是允许处理的字符串在本机编码;
quote,默认""",如果以双引开头,fread强有力的处理里面的引号,如果失败了就会用其它尝试,如果设置quote="",默认引号不可用
strip.white,默认TRUE,删除结尾空白符,如果FALSE,只取掉header的结尾空白符;
fill,默认FALSE,如果TRUE,不等长的区域可以自动填上,利于文件顺利读入;
blank.lines.skip,默认FALSE,如果TRUE,跳过空白行
key,设置key,用一个或多个列名,会传递给setkey
showProgress,TRUE会显示脚本进程,R层次的C代码
data.table,TRUE返回data.table,FALSE返回data.frame
实例如下,1.8GB的数据读入94秒,可见读入文件速度非常快,
fwrite
fwrite(x, file = "", append = FALSE, quote = "auto",
sep = ",", sep2 = c("","|",""),
eol = if (.Platform$OS.type=="windows") "\r\n" else "\n",
na = "", dec = ".", row.names = FALSE, col.names = TRUE,
qmethod = c("double","escape"),
logicalAsInt = FALSE, dateTimeAs = c("ISO","squash","epoch","write.csv"),
buffMB = 8L, nThread = getDTthreads(),
showProgress = getOption("datatable.showProgress"),
verbose = getOption("datatable.verbose"))
x,具有相同长度的列表,比如data.frame和data.table等;
file,输出文件名,""意味着直接输出到操作台;
append,如果TRUE,在原文件的后面添加;
quote,如果"auto",因子和列名只有在他们需要的时候才会被加上双引号,例如该部分包括分隔符,或者以"\n"结尾的一行,或者双引号它自己,如果FALSE,那么区域不会加上双引号,如果TRUE,就像写入CSV文件一样,除了数字,其它都加上双引号;
sep,列之间的分隔符;
sep2,对于是list的一列,写出去时list成员间以sep2分隔,它们是处于一列之内,然后内部再用字符分开;
eol,行分隔符,默认Windows是"\r\n",其它的是"\n";
na,na值的表示,默认"";
dec,小数点的表示,默认".";
row.names,是否写出行名,因为data.table没有行名,所以默认FALSE;
col.names ,是否写出列名,默认TRUE,如果没有定义,并且append=TRUE和文件存在,那么就会默认使用FALSE;
qmethod,怎样处理双引号,"escape",类似于C风格,用反斜杠逃避双引,“double",默认,双引号成对;
logicalAsInt,逻辑值作为数字写出还是作为FALSE和TRUE写出;
dateTimeAS, 决定 Date/IDate,ITime和POSIXct的写出,"ISO"默认,-2016-09-12, 18:12:16和2016-09-12T18:12:16.999999Z;"squash",-20160912,181216和20160912181216999;"epoch",-17056,65536和1473703936;"write.csv",就像write.csv一样写入时间,仅仅对POSIXct有影响,as.character将digits.secs转化字符并通过R内部UTC转回本地时间。前面三个选项都是用新的特定C代码写的,较快
buffMB,每个核心给的缓冲大小,在1到1024之间,默认80MB
nThread,用的核心数。
showProgress,在工作台显示进程,当用file==""时,自动忽略此参数
verbose,是否交互和报告时间
data.table数据框结构处理语法
data.table[ i , j , by]
i 决定显示的行,可以是整型,可以是字符,可以是表达式,j 是对数据框进行求值,决定显示的列,by对数据进行指定分组,除了by ,也可以添加其它的一系列参数:
keyby,with,nomatch,mult,rollollends,which,.SDcols,on。
i 决定显示的行
DT = data.table(x=rep(c("b","a","c"),each=3), y=c(1,3,6), v=1:9) #新建data.table对象DT
DT[2] #取第二行
DT[2:3] #取第二到第三行
DT[order(x)] #将DT按照X列排序,简化操作,另外排序也可以setkey(DT,x),出来的DT就已经是按照x列排序的了。用haskey(DT)判断DT是否已经设置了key,可以设置多个列作为key
DT[y>2] # DT$y>2的行
DT[!2:4] #除了2到4行剩余的行
DT["a",on="x"] #on 参数,DT[D,on=c("x","y")]取DT上"x","y"列上与D上“x"、"y"的列相关联的行,与D进行merge。比如此例取出DT 中 X 列为"a"的行,和"a"进行merge。on参数的第一列必须是DT的第一列
DT[.("a"), on="x"] #和上面一样.()有类似与c()的作用
DT["a", on=.(x)] #和上面一样
DT[x=="a"] # 和上面一样,和使用on一样,都是使用二分查找法,所以它们速度比用data.frame的快。也可以用setkey之后的DT,输入DT["a"]或者DT["a",on=.(x)]如果有几个key的话推荐用on
DT[x!="b" | y!=3] #x列不等于"b"或者y列不等于3的行
DT[.("b", 3), on=.(x, v)] #取DT的x,v列上x="b",v=3的行
j 对数据框进行求值输出
j 参数对数据进行运算,比如sum,max,min,tail等基本函数,输出基本函数的计算结果,还可以用n输出第n列,.N(总列数,直接在j输入.N取最后一列),:=(直接在data.table上添加列,没有copy过程,所以快,有需要的话注意备份),.SD输出子集,.SD[n]输出子集的第n列,DT[,.(a = .(), b = .())] 输出一个a、b列的数据框,.()就是要输入的a、b列的内容,还可以将一系列处理放入大括号,如{tmp <- mean(y);.(a = a-tmp, b = b-tmp)}
DT[,y] #返回y列,矢量
DT[,.(y)] #返回y列,返回data.table
DT[, sum(y)] #对y列求和
DT[, .(sv=sum(v))] #对y列求和,输出sv列,列中的内容就是sum(v)
DT[, .(sum(y)), by=x] # 对x列进行分组后对各分组y列求总和
DT[, sum(y), keyby=x] #对x列进行分组后对各分组y列求和,并且结果按照x排序
DT[, sum(y), by=x][order(x)] #和上面一样,采取data.table的链接符合表达式
DT[v>1, sum(y), by=v] #对v列进行分组后,取各组中v>1的行出来,各组分别对定义的行中的y求和
DT[, .N, by=x] #用by对DT 用x分组后,取每个分组的总列数
DT[, .SD, .SDcols=x:y] #用.SDcols 定义SubDadaColums(子列数据),这里取出x到之间的列作为子集,然后.SD 输出所有子集
DT[2:5, cat(y, "\n")] #直接在j 用cat函数,输出2到5列的y值
DT[, plot(a,b), by=x] #直接在j用plot函数画图,对于每个x的分组画一张图
DT[, m:=mean(v), by=x] #对DT按x列分组,直接在DT上再添加一列m,m的内容是mean(v),直接修改并且不输出到屏幕上
DT[, m:=mean(v), by=x] [] #加[]将结果输出到屏幕上
DT[,c("m","n"):=list(mean(v),min(v)), by=x][] # 按x分组后同时添加m,n 两列,内容是分别是mean(v)和min(v),并且输出到屏幕
DT[, `:=`(m=mean(v),n=min(v)),by=x][] #内容和上面一样,另外的写法
DT[,(seq = min(y):max(v)), by=x] #输出seq列,内容是min(a)到max(b)
DT[, c(.(y=max(y)), lapply(.SD, min)), by=x, .SDcols=y:v] #对DT取y:v之间的列,按x分组,输出max(y),对y到v之间的列每列求最小值输出。
by,on,with等参数
by 对数据进行分组
on DT[D,on=c("x","y")]取DT上"x","y"列上与D上"x","y”列相关联的行,并与D进行merge
DT[X, on="x"] #左联接
X[DT, on="x"] #右联接
DT[X, on="x", nomatch=0] #内联接,nomatch=0表示不返回不匹配的行,nomatch=NA表示以NA返回不匹配的值
with 默认是TRUE,列名能够当作变量使用,即x相当于DT$"x",当是FALSE时,列名仅仅作为字符串,可以用传统data.frame方法并且返回data.table,x[, cols, with=FALSE] 和x[, .SD, .SDcols=cols]一样


mult 当有i 中匹配到的有多行时,mult控制返回的行,"all"返回全部(默认),"first",返回第一行,"last"返回最后一行
roll 当i中全部行匹配只有某一行不匹配时,填充该行空白,+Inf(或者TRUE)用上一行的值填充,-Inf用下一行的值填充,输入某数字时,表示能够填充的距离,near用最近的行填充
rollends 填充首尾不匹配的行,TRUE填充,FALSE不填充,与roll一同使用

which TRUE返回匹配的行号,NA返回不匹配的行号,默认FALSE返回匹配的行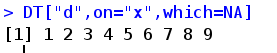
.SDcols 取特定的列,然后.SD就包括了页写选定的特定列,可以对这些子集应用函数处理
allow.cartesian FALSE防止结果超出nrow(x)+nrow(i)行,常常因为i中有重复的列而超出。这里的cartesian和传统上的cartesian不一样。
R语言之数据处理常用包的更多相关文章
- [2]R语言在数据处理上的禀赋之——可视化技术
本文目录 Java的可视化技术 R的可视化技术 二维做图利器plot的参数配置 *权限机制 *plot独有的参数 *plot的type介绍 *title介绍 *公共参数集合--par *par的权限机 ...
- r语言,安装外部包 警告: 无法将临时安装
安装R语言中的外部包时,出现错误提示 试开URL’https://mirrors.tuna.tsinghua.edu.cn/CRAN/bin/windows/contrib/3.3/ggplot2_2 ...
- R语言中的机器学习包
R语言中的机器学习包 Machine Learning & Statistical Learning (机器学习 & 统计学习) 网址:http://cran.r-project ...
- R语言之数据处理
R语言之数据处理 一.向量处理 1.选择和显示向量 data[1] data[3] data[1:3] data[-1]:除第一项以外的所有项 data[c(1,3,4,6)] data[data&g ...
- R语言—如何安装Github包的解决方法,亲测有效
R语言—如何安装Github包的解决方法,亲测有效 准备安装材料: R包-REmap GitHub下载地址:https://github.com/lchiffon/REmap R包-baidumap ...
- R语言:关于rJava包的安装
R语言:关于rJava包的安装 盐池里的萝卜 2014-09-14 00:53:33 在做文本挖掘的时候,会发现分词时候rJava是必须要迈过去的坎儿,所以进行了总结: 第一步:安装rJava和jd ...
- R语言dataframe的常用操作总结
前言:近段时间学习R语言用到最多的数据格式就是data.frame,现对data.frame常用操作进行总结,其中函数大部分来自dplyr包,该包由Hadley Wickham所作,主要用于数据的清洗 ...
- [R语言]foreach和doParallel包实现多个数据库同时查询
R语言在进行数据库查询时,每执行一条语句,都会阻塞.直到查询语句返回结果之后,才会进行下一条语句. 为了能够实现同时对多个数据库进行查询,以节省顺序执行下来的时间,首先考虑通过多线程来进行数据库查询. ...
- [3]R语言在数据处理上的禀赋——par参数详解(一)
本文目录 公共参数列表 par 颜色相关 字体相关 字体大小相关 线条相关 符号相关 线条和符号大小相关 结束 本文首发:program-dog.blogspot.com 注1:本文也曾在csdn发布 ...
随机推荐
- (小数化分数)小数化分数2 -- HDU --1717
链接: http://acm.hdu.edu.cn/showproblem.php?pid=1717 举例: 0.24333333…………=(243-24)/900=73/3000.9545454…… ...
- The First Android App----Starting Another Activity
To respond to the button's on-click event, open the activity_main.xml layout file and add the androi ...
- CGA裁剪算法之线段裁剪算法
CGA裁剪算法之线段裁剪算法 常用的线段裁剪算法有三种:[1]Cohen_SutherLand裁剪算法,[2]中点分割裁剪算法,[3]参数化方法. 1. Cohen_SutherLand裁剪算法 为了 ...
- Python学习-37.Python中的正则表达式
作为一门现代语言,正则表达式是必不可缺的,在Python中,正则表达式位于re模块. import re 这里不说正则表达式怎样去匹配,例如\d代表数字,^代表开头(也代表非,例如^a-z则不匹配任何 ...
- Spark Structured Stream 2
❤Limitations of DStream API Batch Time Constraint application级别的设置. 不支持EventTime event time 比process ...
- 项目笔记---WPF多语言方案
近期由于朋友邀请帮忙给一个开源的游戏“外挂”做一个I18N的解决方案,恰好也是WPF做的,之前有过相关经验,就忙了一个星期终于搞定了,已经提交给作者了,现在这里做一个分享. 这里分享下我个人Fork的 ...
- C#时间加减
DateTime dt =......//减数DateTime dt_n = DateTime.Now;//被减数 long x = dt .ToFileTime();//表示自协调世界时 (UTC) ...
- Python 基础入门
最近业余时间看看Python,从网上找找一些语法看看 http://www.runoob.com/python/python-tutorial.html IDE工具:https://www.pytho ...
- .NET Entity Framework (with Oracle ODP.NET)
一.前言 1.Entity Framework是什么? Entity Framework是微软对ORM框架的实现.类似的实现也有其它方式,如DevExpress 的XPO(eXpress Persis ...
- scapy IPv6 NS NA报文构造
NS 报文构造: #! /bin/python from scapy.all import * a=IPv6(src='2a01:4f8:161:5300::40', dst='ff02::1:ff0 ...