spark算子集锦
Spark 是大数据领域的一大利器,花时间总结了一下 Spark 常用算子,正所谓温故而知新。
Spark 算子按照功能分,可以分成两大类:transform 和 action。Transform 不进行实际计算,是惰性的,action 操作才进行实际的计算。如何区分两者?看函数返回,如果输入到输出都是RDD类型,则认为是transform操作,反之为action操作。
准备
准备阶段包括spark-shell 界面调出以及数据准备。spark-shell 启动命令如下:
bin/spark-shell --master local[*]
其中local[*]是可以更改的,这里启用的是本地模式,出现下面这个界面,恭喜,可以开撸了!
有一点需要说明,sc 和 spark 可以直接在命令行调用,其提示信息如下:
Spark context available as ‘sc’ (master = local[*], app id = local-1547409645312).
Spark session available as ‘spark’.
数据准备
val content =Array("11,Alex,Columbus,7","12,Ryan,New York,8","13,Johny,New York,9","14,Cook,Glasgow,6","15,Starc,Aus,7","16,eric,New York,4","17,richard,Columbus,3")
数据加载和处理
val test_tmp_RDD =sc.parallelize(content).map(line =>line.split(","))
val format_RDD = test_tmp_RDD.map{arr=>
val line = (arr(0).toString,arr(1).toString,arr(2).toString,arr(3).toString)
line match{
case (eid,name,destination,salary) =>(eid,name,destination, salary)
}
}
处理后的结果输出如下:
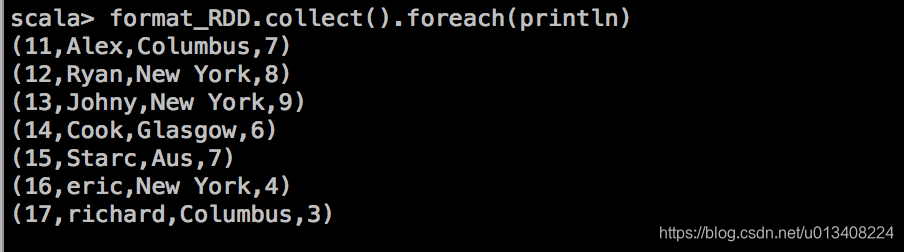
Spark 类型转换
通过命令行输入 format_RDD. 加 tab键,可以显示当前可用的操作,图示如下:
其中 toDF方法能将 RDD 转换成 DataFrame,RDD 转换成 DataFrame 需要隐式转换,需要引入的包如下:
import spark.implicits._
当用 toDF 方法输出后显示如下:
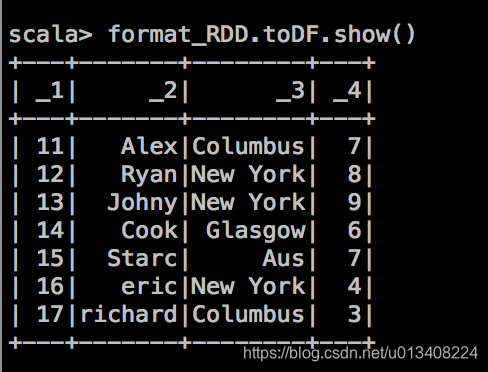
我们尝试带着问题去寻找合适的spark算子,以期达到预想效果。
问一:如何将列名(_1,_2,_3,_4)改成对应的精确的描述信息?
命令行输入 format_RDD.toDF. 加 tab键,显示当前可操作算子如下:
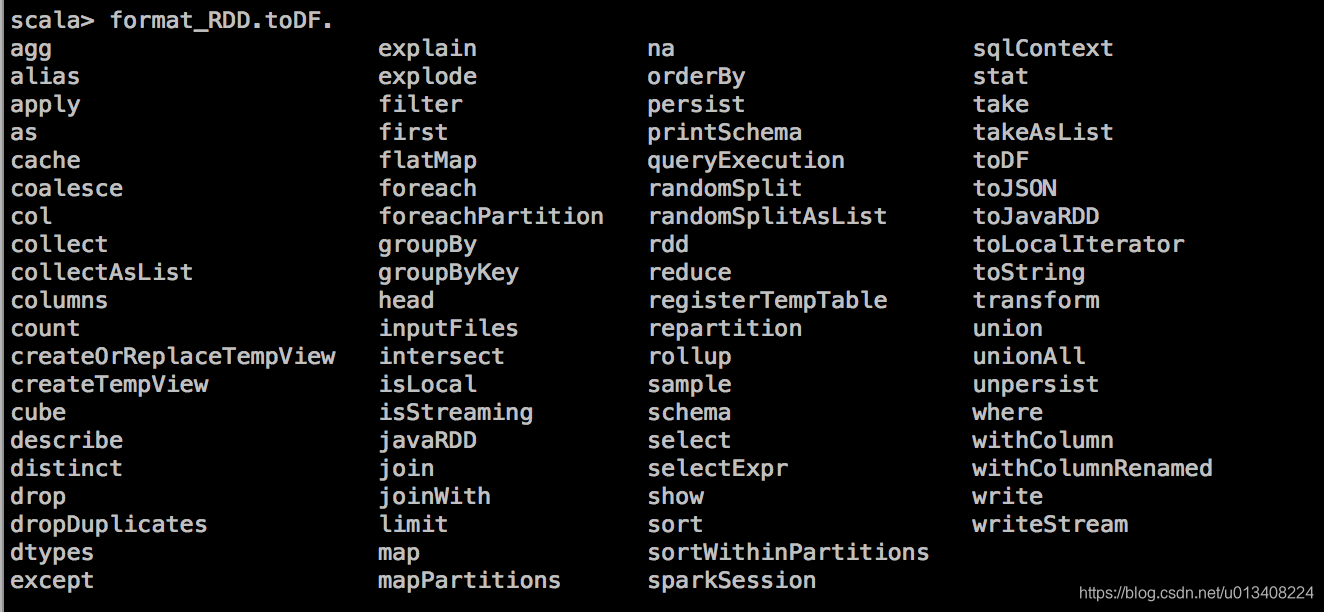
注意 RDD 算子和 DataFrame 算子的不同,我们找到withColumnRenamed方法,尝试操作如下:
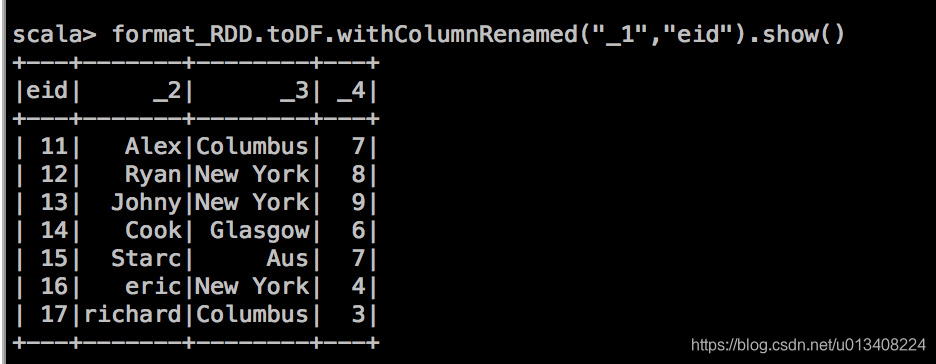
该算子能达到我们预期的效果,另一种方式,toDF函数后面可以直接接列名字符,其定义如下:
def toDF(colNames: String*): DataFrame = ds.toDF(colNames : _*)
更一般的,我们在数据处理阶段,直接将RDD 转换成 DataFrame,需要引入的包如下:
import org.apache.spark.sql.{DataFrame, SparkSession,Row}
import org.apache.spark.sql.types._
需要预先定义一个 StructType,其实现如下:
val schema = StructType(
Array(
StructField("eid",StringType,true)
,StructField("name",StringType,true)
,StructField("destination",StringType,true)
,StructField("salary",StringType,true)
)
)
将 format_RDD的每一行包装成 Row类型,其实现如下:
val format_df_row = format_RDD.map{arr=>
arr match{
case (eid,name,destination,salary) =>Row(eid,name,destination, salary)
}
}
通过 SparkSession 创建 DataFrame,其实现方式如下:
val df = spark.createDataFrame(format_df_row,schema)
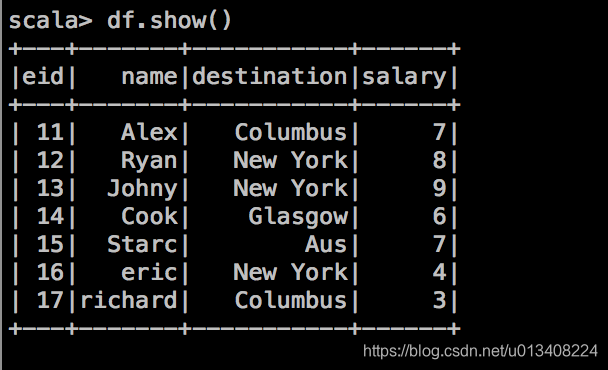
DataFrame 算子
我们可以把 DataFrame 当成数据库中的一张表,对其进行分析和操作。
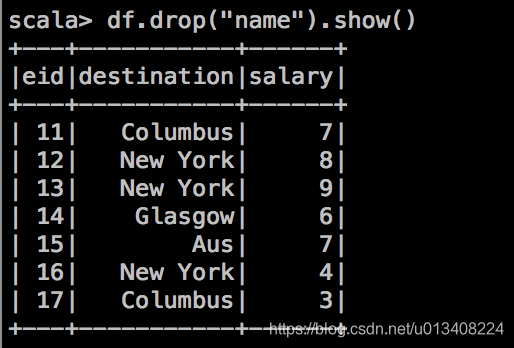
- drop 操作,删除特定列。
- printSchema 操作,打印概要
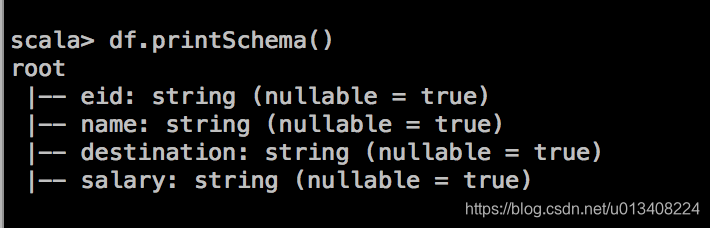
- 对 DataFrame 中的列进行统计分析,包括:count,mean,std,min,max
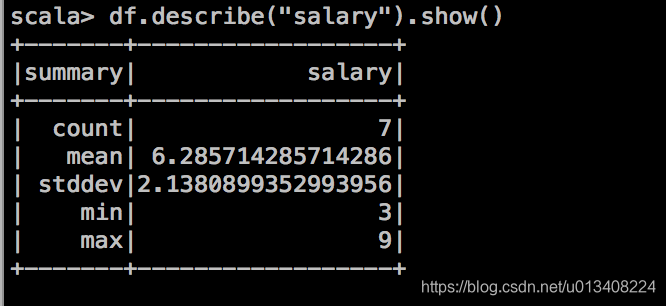
- 将表存成字符串JSON,其操作如下:
- 计算每个地方(destination) 上的最高薪水(salary)

今天的内容就到这里,后续或有更新…
spark算子集锦的更多相关文章
- (转)Spark 算子系列文章
http://lxw1234.com/archives/2015/07/363.htm Spark算子:RDD基本转换操作(1)–map.flagMap.distinct Spark算子:RDD创建操 ...
- Spark算子总结及案例
spark算子大致上可分三大类算子: 1.Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据. 2.Key-Value数据类型的Tran ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...
- UserView--第一种方式set去重,基于Spark算子的java代码实现
UserView--第一种方式set去重,基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import java.util.Ha ...
- spark算子之DataFrame和DataSet
前言 传统的RDD相对于mapreduce和storm提供了丰富强大的算子.在spark慢慢步入DataFrame到DataSet的今天,在算子的类型基本不变的情况下,这两个数据集提供了更为强大的的功 ...
- Spark算子总结(带案例)
Spark算子总结(带案例) spark算子大致上可分三大类算子: 1.Value数据类型的Transformation算子,这种变换不触发提交作业,针对处理的数据项是Value型的数据. 2.Key ...
- Spark算子---实战应用
Spark算子实战应用 数据集 :http://grouplens.org/datasets/movielens/ MovieLens 1M Datase 相关数据文件 : users.dat --- ...
- Spark算子使用
一.spark的算子分类 转换算子和行动算子 转换算子:在使用的时候,spark是不会真正执行,直到需要行动算子之后才会执行.在spark中每一个算子在计算之后就会产生一个新的RDD. 二.在编写sp ...
- Spark:常用transformation及action,spark算子详解
常用transformation及action介绍,spark算子详解 一.常用transformation介绍 1.1 transformation操作实例 二.常用action介绍 2.1 act ...
随机推荐
- 网络流——二分图最优匹配KM算法
前言 其实这个东西只是为了把网络流的内容凑齐而写的(反正我是没有看到过这样子的题不知道田忌赛马算不算) 算法过程 我们令左边的点(其实二分图没有什么左右)为女生,右边的点为男生,那么: 为每一个女生定 ...
- 初识面向对象-封装、property装饰器、staticmathod(静态的方法)、classmethod(类方法) (五)
封装 # class Room:# def __init__(self,name,length,width):# self.__name = name# self.__length = length# ...
- BZOJ 4517--[Sdoi2016]排列计数(乘法逆元)
4517: [Sdoi2016]排列计数 Time Limit: 60 Sec Memory Limit: 128 MBSubmit: 1727 Solved: 1067 Description ...
- Reservoir Sampling-382. Linked List Random Node
Given a singly linked list, return a random node's value from the linked list. Each node must have t ...
- webpack快速入门——处理HTML中的图片
在webpack中是不喜欢你使用标签<img>来引入图片的,但是我们作前端的人特别热衷于这种写法, 国人也为此开发了一个:html-withimg-loader.他可以很好的处理我们在ht ...
- 线程TLAB局部缓存区域(Thread Local Allocation Buffer)
TLAB(Thread Local Allocation Buffer) 1,堆是JVM中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的 2,Sun ...
- jvm(2)类的初始化(一)
[深入Java虚拟机]之三:类初始化 类初始化是类加载过程的最后一个阶段,到初始化阶段,才真正开始执行类中的Java程序代码. 1,下面说的初始化主要是类变量的初始化,实例变量的初始化触发条件不同(一 ...
- SVN常用操作介绍
SVN:全称subversion,开源代码版本控制系统,也就是常说的“版本控制工具”,实现代码.文档等的历史版本保存.共享和权限管理.常用于软件开发项目中,开发将最新的代码放到svn,其他同事可在这个 ...
- POJ 2385
#include <algorithm> #include <cstdlib> #include <numeric> #include <iostream&g ...
- keepalived安装配置实战心得(实现高可用保证网络服务不间断)
keepalived安装配置实战心得(实现高可用保证网络服务不间断) 一.准备2台虚拟机 安装的系统是:centos-release-7-1.1503.el7.centos.2.8.x86_6 ...