Netty源码分析第6章(解码器)---->第1节: ByteToMessageDecoder
Netty源码分析第六章: 解码器
概述:
在我们上一个章节遗留过一个问题, 就是如果Server在读取客户端的数据的时候, 如果一次读取不完整, 就触发channelRead事件, 那么Netty是如何处理这类问题的, 在这一章中, 会对此做详细剖析
之前的章节我们学习过pipeline, 事件在pipeline中传递, handler可以将事件截取并对其处理, 而之后剖析的编解码器, 其实就是一个handler, 截取byteBuf中的字节, 然后组建成业务需要的数据进行继续传播
编码器, 通常是OutBoundHandler, 也就是以自身为基准, 对那些对外流出的数据做处理, 所以也叫编码器, 将数据经过编码发送出去
解码器, 通常是inboundHandler, 也就是以自身为基准, 对那些流向自身的数据做处理, 所以也叫解码器, 将对向的数据接收之后经过解码再进行使用
同样, 在netty的编码器中, 也会对半包和粘包问题做相应的处理
什么是半包, 顾名思义, 就是不完整的数据包, 因为netty在轮询读事件的时候, 每次将channel中读取的数据, 不一定是一个完整的数据包, 这种情况, 就叫半包
粘包同样也不难理解, 如果client往server发送数据包, 如果发送频繁很有可能会将多个数据包的数据都发送到通道中, 如果在server在读取的时候可能会读取到超过一个完整数据包的长度, 这种情况叫粘包
有关半包和粘包, 入下图所示:
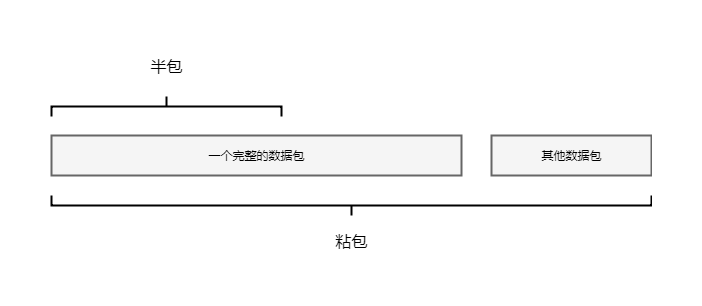
6-0-1
netty对半包的或者粘包的处理其实也很简单, 通过之前的学习, 我们知道, 每个handler是和channel唯一绑定的, 一个handler只对应一个channel, 所以将channel中的数据读取时候经过解析, 如果不是一个完整的数据包, 则解析失败, 将这块数据包进行保存, 等下次解析时再和这个数据包进行组装解析, 直到解析到完整的数据包, 才会将数据包进行向下传递
具体流程是在代码中如何体现的呢?我们进入到源码分析中
第一节: ByteToMessageDecoder
ByteToMessageDecoder解码器, 顾名思义, 是一个将Byte解析成消息的解码器,
我们看他的定义:
public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter{
//类体省略
}
这里继承了ChannelInboundHandlerAdapter, 根据之前的学习, 我们知道, 这是个inbound类型的handler, 也就是处理流向自身事件的handler
其次, 该类通过abstract关键字修饰, 说明是个抽象类, 在我们实际使用的时候, 并不是直接使用这个类, 而是使用其子类, 类定义了解码器的骨架方法, 具体实现逻辑交给子类, 同样, 在半包处理中也是由该类进行实现的
netty中很多解码器都实现了这个类, 并且, 我们也可以通过实现该类进行自定义解码器
我们重点关注一下该类的一个属性:
ByteBuf cumulation;
这个属性, 就是有关半包处理的关键属性, 从概述中我们知道, netty会将不完整的数据包进行保存, 这个数据包就是保存在这个属性中
之前的学习我们知道, ByteBuf读取完数据会传递channelRead事件, 传播过程中会调用handler的channelRead方法, ByteToMessageDecoder的channelRead方法, 就是编码的关键部分
我们看其channelRead方法:
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//如果message是byteBuf类型
if (msg instanceof ByteBuf) {
//简单当成一个arrayList, 用于盛放解析到的对象
CodecOutputList out = CodecOutputList.newInstance();
try {
ByteBuf data = (ByteBuf) msg;
//当前累加器为空, 说明这是第一次从io流里面读取数据
first = cumulation == null;
if (first) {
//如果是第一次, 则将累加器赋值为刚读进来的对象
cumulation = data;
} else {
//如果不是第一次, 则把当前累加的数据和读进来的数据进行累加
cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);
}
//调用子类的方法进行解析
callDecode(ctx, cumulation, out);
} catch (DecoderException e) {
throw e;
} catch (Throwable t) {
throw new DecoderException(t);
} finally {
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= discardAfterReads) {
numReads = 0;
discardSomeReadBytes();
}
//记录list长度
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
//向下传播
fireChannelRead(ctx, out, size);
out.recycle();
}
} else {
//不是byteBuf类型则向下传播
ctx.fireChannelRead(msg);
}
}
这方法比较长, 带大家一步步剖析
首先判断如果传来的数据是ByteBuf, 则进入if块中
CodecOutputList out = CodecOutputList.newInstance() 这里就当成一个ArrayList就好, 用于盛放解码完成的数据
ByteBuf data = (ByteBuf) msg 这步将数据转化成ByteBuf
first = cumulation == null 这里表示如果cumulation == null, 说明没有存储板半包数据, 则将当前的数据保存在属性cumulation中
如果 cumulation != null , 说明存储了半包数据, 则通过cumulator.cumulate(ctx.alloc(), cumulation, data)将读取到的数据和原来的数据进行累加, 保存在属性cumulation中
我们看cumulator属性:
private Cumulator cumulator = MERGE_CUMULATOR;
这里调用了其静态属性MERGE_CUMULATOR, 我们跟过去:
public static final Cumulator MERGE_CUMULATOR = new Cumulator() {
@Override
public ByteBuf cumulate(ByteBufAllocator alloc, ByteBuf cumulation, ByteBuf in) {
ByteBuf buffer;
//不能到过最大内存
if (cumulation.writerIndex() > cumulation.maxCapacity() - in.readableBytes()
|| cumulation.refCnt() > 1) {
buffer = expandCumulation(alloc, cumulation, in.readableBytes());
} else {
buffer = cumulation;
}
//将当前数据buffer
buffer.writeBytes(in);
in.release();
return buffer;
}
};
这里创建了Cumulator类型的静态对象, 并重写了cumulate方法, 这里cumulate方法, 就是用于将ByteBuf进行拼接的方法:
方法中, 首先判断cumulation的写指针+in的可读字节数是否超过了cumulation的最大长度, 如果超过了, 将对cumulation进行扩容, 如果没超过, 则将其赋值到局部变量buffer中
然后将in的数据写到buffer中, 将in进行释放, 返回写入数据后的ByteBuf
回到channelRead方法中:
最后通过callDecode(ctx, cumulation, out)方法进行解码, 这里传入了Context对象, 缓冲区cumulation和集合out:
我们跟到callDecode(ctx, cumulation, out)方法中:
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {
try {
//只要累加器里面有数据
while (in.isReadable()) {
int outSize = out.size();
//判断当前List是否有对象
if (outSize > 0) {
//如果有对象, 则向下传播事件
fireChannelRead(ctx, out, outSize);
//清空当前list
out.clear();
//解码过程中如ctx被removed掉就break
if (ctx.isRemoved()) {
break;
}
outSize = 0;
}
//当前可读数据长度
int oldInputLength = in.readableBytes();
//子类实现
//子类解析, 解析玩对象放到out里面
decode(ctx, in, out);
if (ctx.isRemoved()) {
break;
}
//List解析前大小 和解析后长度一样(什么没有解析出来)
if (outSize == out.size()) {
//原来可读的长度==解析后可读长度
//说明没有读取数据(当前累加的数据并没有拼成一个完整的数据包)
if (oldInputLength == in.readableBytes()) {
//跳出循环(下次在读取数据才能进行后续的解析)
break;
} else {
//没有解析到数据, 但是进行读取了
continue;
}
}
//out里面有数据, 但是没有从累加器读取数据
if (oldInputLength == in.readableBytes()) {
throw new DecoderException(
StringUtil.simpleClassName(getClass()) +
".decode() did not read anything but decoded a message.");
}
if (isSingleDecode()) {
break;
}
}
} catch (DecoderException e) {
throw e;
} catch (Throwable cause) {
throw new DecoderException(cause);
}
}
这里首先循环判断传入的ByteBuf是否有可读字节, 如果还有可读字节说明没有解码完成, 则循环继续解码
然后判断集合out的大小, 如果大小大于1, 说明out中盛放了解码完成之后的数据, 然后将事件向下传播, 并清空out
因为我们第一次解码out是空的, 所以这里不会进入if块, 这部分我们稍后分析, 这里继续往下看
通过 int oldInputLength = in.readableBytes() 获取当前ByteBuf, 其实也就是属性cumulation的可读字节数, 这里就是一个备份用于比较, 我们继续往下看:
decode(ctx, in, out)方法是最终的解码操作, 这部会读取cumulation并且将解码后的数据放入到集合out中, 在ByteToMessageDecoder中的该方法是一个抽象方法, 让子类进行实现, 我们使用的netty很多的解码都是继承了ByteToMessageDecoder并实现了decode方法从而完成了解码操作, 同样我们也可以遵循相应的规则进行自定义解码器, 在之后的小节中会讲解netty定义的解码器, 并剖析相关的实现细节, 这里我们继续往下看:
if (outSize == out.size()) 这个判断表示解析之前的out大小和解析之后out大小进行比较, 如果相同, 说明并没有解析出数据, 我们进入到if块中:
if (oldInputLength == in.readableBytes()) 表示cumulation的可读字节数在解析之前和解析之后是相同的, 说明解码方法中并没有解析数据, 也就是当前的数据并不是一个完整的数据包, 则跳出循环, 留给下次解析, 否则, 说明没有解析到数据, 但是读取了, 所以跳过该次循环进入下次循环
最后判断 if (oldInputLength == in.readableBytes()) , 这里代表out中有数据, 但是并没有从cumulation读数据, 说明这个out的内容是非法的, 直接抛出异常
我们回到channRead方法中:
我们关注finally中的内容:
finally {
if (cumulation != null && !cumulation.isReadable()) {
numReads = 0;
cumulation.release();
cumulation = null;
} else if (++ numReads >= discardAfterReads) {
numReads = 0;
discardSomeReadBytes();
}
//记录list长度
int size = out.size();
decodeWasNull = !out.insertSinceRecycled();
//向下传播
fireChannelRead(ctx, out, size);
out.recycle();
}
首先判断cumulation不为null, 并且没有可读字节, 则将累加器进行释放, 并设置为null
之后记录out的长度, 通过fireChannelRead(ctx, out, size)将channelRead事件进行向下传播, 并回收out对象
我们跟到fireChannelRead(ctx, out, size)方法中:
static void fireChannelRead(ChannelHandlerContext ctx, CodecOutputList msgs, int numElements) {
//遍历List
for (int i = 0; i < numElements; i ++) {
//逐个向下传递
ctx.fireChannelRead(msgs.getUnsafe(i));
}
}
这里遍历out集合, 并将里面的元素逐个向下传递
以上就是有关解码的骨架逻辑
Netty源码分析第6章(解码器)---->第1节: ByteToMessageDecoder的更多相关文章
- Netty源码分析第6章(解码器)---->第4节: 分隔符解码器
Netty源码分析第六章: 解码器 第四节: 分隔符解码器 基于分隔符解码器DelimiterBasedFrameDecoder, 是按照指定分隔符进行解码的解码器, 通过分隔符, 可以将二进制流拆分 ...
- Netty源码分析第6章(解码器)---->第2节: 固定长度解码器
Netty源码分析第六章: 解码器 第二节: 固定长度解码器 上一小节我们了解到, 解码器需要继承ByteToMessageDecoder, 并重写decode方法, 将解析出来的对象放入集合中集合, ...
- Netty源码分析第6章(解码器)---->第3节: 行解码器
Netty源码分析第六章: 解码器 第三节: 行解码器 这一小节了解下行解码器LineBasedFrameDecoder, 行解码器的功能是一个字节流, 以\r\n或者直接以\n结尾进行解码, 也就是 ...
- Netty源码分析第4章(pipeline)---->第4节: 传播inbound事件
Netty源码分析第四章: pipeline 第四节: 传播inbound事件 有关于inbound事件, 在概述中做过简单的介绍, 就是以自己为基准, 流向自己的事件, 比如最常见的channelR ...
- Netty源码分析第4章(pipeline)---->第5节: 传播outbound事件
Netty源码分析第五章: pipeline 第五节: 传播outBound事件 了解了inbound事件的传播过程, 对于学习outbound事件传输的流程, 也不会太困难 在我们业务代码中, 有可 ...
- Netty源码分析第4章(pipeline)---->第6节: 传播异常事件
Netty源码分析第四章: pipeline 第6节: 传播异常事件 讲完了inbound事件和outbound事件的传输流程, 这一小节剖析异常事件的传输流程 首先我们看一个最最简单的异常处理的场景 ...
- Netty源码分析第4章(pipeline)---->第7节: 前章节内容回顾
Netty源码分析第四章: pipeline 第七节: 前章节内容回顾 我们在第一章和第三章中, 遗留了很多有关事件传输的相关逻辑, 这里带大家一一回顾 首先看两个问题: 1.在客户端接入的时候, N ...
- Netty源码分析第5章(ByteBuf)---->第4节: PooledByteBufAllocator简述
Netty源码分析第五章: ByteBuf 第四节: PooledByteBufAllocator简述 上一小节简单介绍了ByteBufAllocator以及其子类UnPooledByteBufAll ...
- Netty源码分析第5章(ByteBuf)---->第5节: directArena分配缓冲区概述
Netty源码分析第五章: ByteBuf 第五节: directArena分配缓冲区概述 上一小节简单分析了PooledByteBufAllocator中, 线程局部缓存和arean的相关逻辑, 这 ...
随机推荐
- ubuntu修改用户环境变量解决音乐播放器Rhythmbox乱码问题
先打开主文件夹 cd /home/user #user是你的用户名 然后编辑用户环境 sudo gedit .profile在打开的文件中添加: export GST_ID3_TAG_ENCODING ...
- 写了一个web使用向导的小插件
运行效果: 引入插件: <link rel="stylesheet" href="ez-guide.css"> <script src=&qu ...
- 「GXOI / GZOI2019」旧词
题目 确定这不是思博题 看起来很神仙,本来以为是\([LNOI2014]LCA\)的加强版,结果发现一个点的贡献是\(s_i\times (deep_i^k-(deep_i-1)^k)\),\(s_i ...
- [HNOI2003]操作系统
嘟嘟嘟 这道题就是一个模拟. 首先我们建一个优先队列,存所有等待的进程,当然第一关键字是优先级从大到小,第二关键字是到达时间从小到大.然后再建一个指针Tim,代表cpu运行的绝对时间. 然后分一下几种 ...
- 【node.js】函数、路由
Node.js中函数的使用与Javascript类似,一个函数可以作为另一个函数的参数.我们可以先定义一个函数,然后传递,也可以在传递参数的地方直接定义函数. function say(word) { ...
- launch edge 和 latch edge 延迟
本文转自 http://www.cnblogs.com/inet2012/archive/2012/03/07/2384149.html launch edge和latch edge分别是指一条路径的 ...
- PAT乙级1029
1029 旧键盘 (20 分) 旧键盘上坏了几个键,于是在敲一段文字的时候,对应的字符就不会出现.现在给出应该输入的一段文字.以及实际被输入的文字,请你列出肯定坏掉的那些键. 输入格式: 输入在 ...
- 《驱蚊神器v1.0》android应用 赶走那些烦人的臭蚊子
<驱蚊神器v1.0>能够非常好地赶走那些个烦人又恼人伤人的臭蚊子,它总是搞得自己没有好的睡眠或歇息,得努力地拍巴巴掌,这下可好了,也少些烦恼了,先深情地眯缝一会儿...此声波怡人不会对人产 ...
- UITapGestureRecognizer 的用法(轻触手势识别器)
最近在项目中用到了手势操作,键盘回收时还是挺常用的,现在总结下,多谢网络上大神们的分享. 先分享下我在项目中用的代码: UITapGestureRecognizer * mytap=[[UITapGe ...
- HBase数据存取流程
一.HBase的特点是什么 1.HBase一个分布式的基于列式存储或者行式存储的数据库,基于hadoop的hdfs存储,zookeeper进行管理. 2.HBase适合存储半结构化或非结构化数据,对于 ...