基于Spark的FPGrowth算法的运用
一、FPGrowth算法理解
Spark.mllib 提供并行FP-growth算法,这个算法属于关联规则算法【关联规则:两不相交的非空集合A、B,如果A=>B,就说A=>B是一条关联规则,常提及的{啤酒}-->{尿布}就是一条关联规则】,经常用于挖掘频度物品集。关于算法的介绍网上很多,这里不再赘述。主要搞清楚几个概念:
1)支持度support(A => B) = P(AnB) = |A n B| / |N|,表示数据集D中,事件A和事件B共同出现的概率;
2)置信度confidence(A => B) = P(B|A) = |A n B| / |A|,表示数据集D中,出现事件A的事件中出现事件B的概率;
3)提升度lift(A => B) = P(B|A):P(B) = |A n B| / |A| : |B| / |N|,表示数据集D中,出现A的条件下出现事件B的概率和没有条件A出现B的概率;
由上可以看出,支持度表示这条规则的可能性大小,而置信度表示由事件A得到事件B的可信性大小。
举个列子:10000个消费者购买了商品,尿布1000个,啤酒2000个,同时购买了尿布和啤酒800个。
1)支持度:在所有项集中出现的可能性,项集同时含有,x与y的概率。尿布和啤酒的支持度为:800/10000=8%
2)置信度:在X发生的条件下,Y发生的概率。尿布-》啤酒的置信度为:800/1000=80%,啤酒-》尿布的置信度为:800/2000=40%
3)提升度:在含有x条件下同时含有Y的可能性(x->y的置信度)比没有x这个条件下含有Y的可能性之比:confidence(尿布=> 啤酒)/概率(啤酒)) = 80%/(2000/10000) 。如果提升度=1,那就是没啥关系这两个
通过支持度和置信度可以得出强关联关系,通过提升的,可判别有效的强关联关系。
直接拿例子来说明问题。首先数据集如下:
r z h k p
z y x w v u t s
s x o n r
x z y m t s q e
z
x z y r q t p二、代码实现。在IDEA中建立Maven工程,然后本地模式调试代码如下:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.mllib.fpm.AssociationRules;
import org.apache.spark.mllib.fpm.FPGrowth;
import org.apache.spark.mllib.fpm.FPGrowthModel; import java.util.Arrays;
import java.util.List; public class FPDemo {
public static void main(String[] args){
String data_path; //数据集路径
double minSupport = 0.2;//最小支持度
int numPartition = ; //数据分区
double minConfidence = 0.8;//最小置信度
if(args.length < ){
System.out.println("<input data_path>");
System.exit(-);
}
data_path = args[];
if(args.length >= )
minSupport = Double.parseDouble(args[]);
if(args.length >= )
numPartition = Integer.parseInt(args[]);
if(args.length >= )
minConfidence = Double.parseDouble(args[]); SparkConf conf = new SparkConf().setAppName("FPDemo").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf); //加载数据,并将数据通过空格分割
JavaRDD<List<String>> transactions = sc.textFile(data_path)
.map(new Function<String, List<String>>() {
public List<String> call(String s) throws Exception {
String[] parts = s.split(" ");
return Arrays.asList(parts);
}
}); //创建FPGrowth的算法实例,同时设置好训练时的最小支持度和数据分区
FPGrowth fpGrowth = new FPGrowth().setMinSupport(minSupport).setNumPartitions(numPartition);
FPGrowthModel<String> model = fpGrowth.run(transactions);//执行算法 //查看所有频繁諅,并列出它出现的次数
for(FPGrowth.FreqItemset<String> itemset : model.freqItemsets().toJavaRDD().collect())
System.out.println("[" + itemset.javaItems() + "]," + itemset.freq()); //通过置信度筛选出强规则
//antecedent表示前项
//consequent表示后项
//confidence表示规则的置信度
for(AssociationRules.Rule<String> rule : model.generateAssociationRules(minConfidence).toJavaRDD().collect())
System.out.println(rule.javaAntecedent() + "=>" + rule.javaConsequent() + ", " + rule.confidence());
}
}
直接在Maven工程中运用上面的代码会有问题,因此这里需要添加依赖项解决项目中的问题,依赖项的添加如下:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.</artifactId>
<version>2.1.</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.</artifactId>
<version>2.1.</version>
</dependency>
</dependencies>
本地模式运行的结果如下:
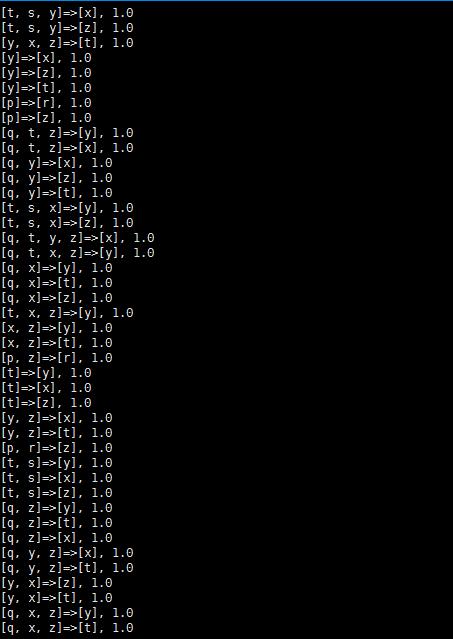
[t, s, y]=>[x], 1.0
[t, s, y]=>[z], 1.0
[y, x, z]=>[t], 1.0
[y]=>[x], 1.0
[y]=>[z], 1.0
[y]=>[t], 1.0
[p]=>[r], 1.0
[p]=>[z], 1.0
[q, t, z]=>[y], 1.0
[q, t, z]=>[x], 1.0
[q, y]=>[x], 1.0
[q, y]=>[z], 1.0
[q, y]=>[t], 1.0
[t, s, x]=>[y], 1.0
[t, s, x]=>[z], 1.0
[q, t, y, z]=>[x], 1.0
[q, t, x, z]=>[y], 1.0
[q, x]=>[y], 1.0
[q, x]=>[t], 1.0
[q, x]=>[z], 1.0
[t, x, z]=>[y], 1.0
[x, z]=>[y], 1.0
[x, z]=>[t], 1.0
[p, z]=>[r], 1.0
[t]=>[y], 1.0
[t]=>[x], 1.0
[t]=>[z], 1.0
[y, z]=>[x], 1.0
[y, z]=>[t], 1.0
[p, r]=>[z], 1.0
[t, s]=>[y], 1.0
[t, s]=>[x], 1.0
[t, s]=>[z], 1.0
[q, z]=>[y], 1.0
[q, z]=>[t], 1.0
[q, z]=>[x], 1.0
[q, y, z]=>[x], 1.0
[q, y, z]=>[t], 1.0
[y, x]=>[z], 1.0
[y, x]=>[t], 1.0
[q, x, z]=>[y], 1.0
[q, x, z]=>[t], 1.0
[t, y, z]=>[x], 1.0
[q, y, x]=>[z], 1.0
[q, y, x]=>[t], 1.0
[q, t, y, x]=>[z], 1.0
[t, s, x, z]=>[y], 1.0
[s, y, x]=>[z], 1.0
[s, y, x]=>[t], 1.0
[s, x, z]=>[y], 1.0
[s, x, z]=>[t], 1.0
[q, y, x, z]=>[t], 1.0
[s, y]=>[x], 1.0
[s, y]=>[z], 1.0
[s, y]=>[t], 1.0
[q, t, y]=>[x], 1.0
[q, t, y]=>[z], 1.0
[t, y]=>[x], 1.0
[t, y]=>[z], 1.0
[t, z]=>[y], 1.0
[t, z]=>[x], 1.0
[t, s, y, x]=>[z], 1.0
[t, y, x]=>[z], 1.0
[q, t]=>[y], 1.0
[q, t]=>[x], 1.0
[q, t]=>[z], 1.0
[q]=>[y], 1.0
[q]=>[t], 1.0
[q]=>[x], 1.0
[q]=>[z], 1.0
[t, s, z]=>[y], 1.0
[t, s, z]=>[x], 1.0
[t, x]=>[y], 1.0
[t, x]=>[z], 1.0
[s, z]=>[y], 1.0
[s, z]=>[x], 1.0
[s, z]=>[t], 1.0
[s, y, x, z]=>[t], 1.0
[s]=>[x], 1.0
[t, s, y, z]=>[x], 1.0
[s, y, z]=>[x], 1.0
[s, y, z]=>[t], 1.0
[q, t, x]=>[y], 1.0
[q, t, x]=>[z], 1.0
[r, z]=>[p], 1.0
三、Spark集群部署。代码修改正如:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.mllib.fpm.AssociationRules;
import org.apache.spark.mllib.fpm.FPGrowth;
import org.apache.spark.mllib.fpm.FPGrowthModel; import java.util.Arrays;
import java.util.List; public class FPDemo {
public static void main(String[] args){
String data_path; //数据集路径
double minSupport = 0.2;//最小支持度
int numPartition = ; //数据分区
double minConfidence = 0.8;//最小置信度
if(args.length < ){
System.out.println("<input data_path>");
System.exit(-);
}
data_path = args[];
if(args.length >= )
minSupport = Double.parseDouble(args[]);
if(args.length >= )
numPartition = Integer.parseInt(args[]);
if(args.length >= )
minConfidence = Double.parseDouble(args[]); SparkConf conf = new SparkConf().setAppName("FPDemo");////修改的地方
JavaSparkContext sc = new JavaSparkContext(conf); //加载数据,并将数据通过空格分割
JavaRDD<List<String>> transactions = sc.textFile(data_path)
.map(new Function<String, List<String>>() {
public List<String> call(String s) throws Exception {
String[] parts = s.split(" ");
return Arrays.asList(parts);
}
}); //创建FPGrowth的算法实例,同时设置好训练时的最小支持度和数据分区
FPGrowth fpGrowth = new FPGrowth().setMinSupport(minSupport).setNumPartitions(numPartition);
FPGrowthModel<String> model = fpGrowth.run(transactions);//执行算法 //查看所有频繁諅,并列出它出现的次数
for(FPGrowth.FreqItemset<String> itemset : model.freqItemsets().toJavaRDD().collect())
System.out.println("[" + itemset.javaItems() + "]," + itemset.freq()); //通过置信度筛选出强规则
//antecedent表示前项
//consequent表示后项
//confidence表示规则的置信度
for(AssociationRules.Rule<String> rule : model.generateAssociationRules(minConfidence).toJavaRDD().collect())
System.out.println(rule.javaAntecedent() + "=>" + rule.javaConsequent() + ", " + rule.confidence());
}
}
然后在IDEA中打包成JAR包
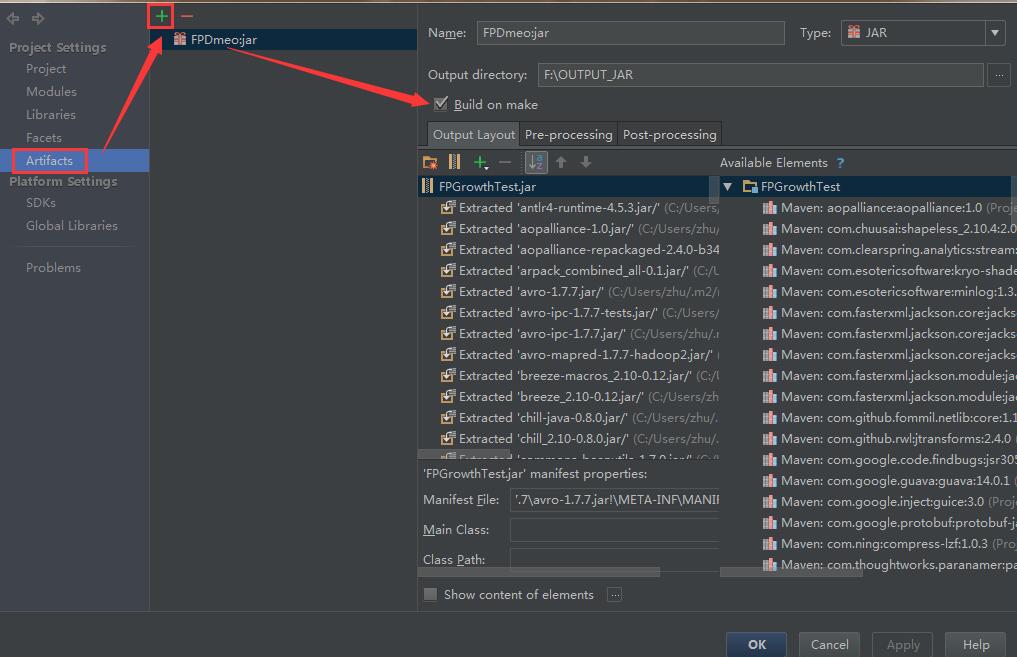

然后在工具栏
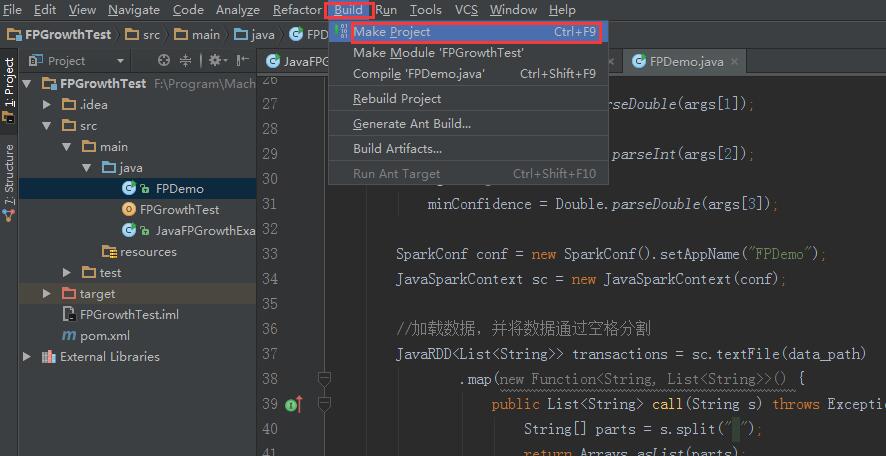
生成Jar包,然后上传到集群中执行命令
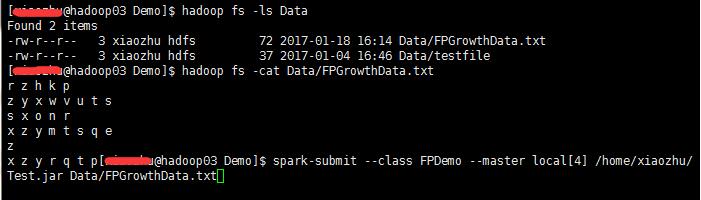
得到结果
基于Spark的FPGrowth算法的运用的更多相关文章
- StreamDM:基于Spark Streaming、支持在线学习的流式分析算法引擎
StreamDM:基于Spark Streaming.支持在线学习的流式分析算法引擎 streamDM:Data Mining for Spark Streaming,华为诺亚方舟实验室开源了业界第一 ...
- Spark机器学习(9):FPGrowth算法
关联规则挖掘最典型的例子是购物篮分析,通过分析可以知道哪些商品经常被一起购买,从而可以改进商品货架的布局. 1. 基本概念 首先,介绍一些基本概念. (1) 关联规则:用于表示数据内隐含的关联性,一般 ...
- Spark MLlib FPGrowth关联规则算法
一.简介 FPGrowth算法是关联分析算法,它采取如下分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-tree),但仍保留项集关联信息.在算法中使用了一种称为频繁模式树(Frequent ...
- 基于FP-Growth算法的关联性分析——学习笔记
数据挖掘 比之前的Ap快,因为只遍历两次. 降序 一.构建FP树 对频繁项集排序,以构成共用关系. 二.基于FP树的频繁项分析 看那个模式基出现过几次.频繁度. 看洗发液的 去掉频繁度小的 构建洗发液 ...
- 使用 FP-growth 算法高效挖掘海量数据中的频繁项集
前言 对于如何发现一个数据集中的频繁项集,前文讲解的经典 Apriori 算法能够做到. 然而,对于每个潜在的频繁项,它都要检索一遍数据集,这是比较低效的.在实际的大数据应用中,这么做就更不好了. 本 ...
- 基于Spark ALS构建商品推荐引擎
基于Spark ALS构建商品推荐引擎 一般来讲,推荐引擎试图对用户与某类物品之间的联系建模,其想法是预测人们可能喜好的物品并通过探索物品之间的联系来辅助这个过程,让用户能更快速.更准确的获得所需 ...
- 使用Apriori算法和FP-growth算法进行关联分析
系列文章:<机器学习实战>学习笔记 最近看了<机器学习实战>中的第11章(使用Apriori算法进行关联分析)和第12章(使用FP-growth算法来高效发现频繁项集).正如章 ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 【机器学习实战】第12章 使用FP-growth算法来高效发现频繁项集
第12章 使用FP-growth算法来高效发现频繁项集 前言 在 第11章 时我们已经介绍了用 Apriori 算法发现 频繁项集 与 关联规则.本章将继续关注发现 频繁项集 这一任务,并使用 FP- ...
随机推荐
- Speeding up Homestead on Windows Using NFS
Speeding up Homestead on Windows Using NFS Sep 07 2015 Homestead Laravel EDIT: I have another articl ...
- TLS/SSL简单过程
.wcf的认证分为两种 1.1 transport模式,在传输层完成认证(只能在传输层完成认证,利用硬件加速效率更高) a.在使用transport模式,非windows凭证的情况下默认使用TLS/S ...
- 浅析10种常见的黑帽seo手法
虽然博主并不认同黑帽seo手法,但是一些常见的黑帽手法还是需要了解的,增加自己对黑帽的认知,也可以在自己优化网站时适时的规避开这些黑帽手法,从而避免自己的网站被搜索引擎惩罚.好了,话不多说,下面进入今 ...
- 2018.10.12 bzoj4712: 洪水(树链剖分)
传送门 树链剖分好题. 考虑分开维护重儿子和轻儿子的信息. 令f[i]f[i]f[i]表示iii为根子树的最优值,h[i]h[i]h[i]表示iii重儿子的最优值,g[i]g[i]g[i]表示iii所 ...
- 2018.08.18 NOIP模拟 travel(贪心)
Travel 题目背景 SOURCE:NOIP2015-SHY4 题目描述 小 A 要进行一次旅行.这回他要在序号为 1 到 n 的 n 个城市之间旅行.这 n 个城市之间共有 m 条连接两个城市的单 ...
- tp5自动生成目录
1.// 定义应用目录 define('APP_PATH', __DIR__ . '/../application/'); // 加载框架引导文件 require __DIR__ . '/../thi ...
- Navicat for oracle cannot load OCI DLL
Navicat for oracle 提示 cannot load OCI DLL87,126,193 instant client package is required for basic and ...
- RabbitMQ添加rabbitmqadmin和其使用方法(类似Redis的redis-cli)
一:先进入rabbitmq的安装目录下的bin目录,执行wget -c http://localhost:15672/cli/rabbitmqadmin:(前提是plugin management已经 ...
- javaScript嵌入式环境Duktape的安装
Duktape 是一个轻量级的嵌入式 JavaScript 引擎,使用duktape可以通过javascript对ESP32进行编程. 首先在下载duktape文件包 mkdir duktape cd ...
- Firemonkey里触发home按键被按下的事件
吾八哥我最近在使用Delphi里的Firemonkey平台写一个叫“由由密码管家”的APP工具,是跨多平台的,如ios/android/windows/macOs.由于是用于密码管理的,那么在手机里操 ...