机器学习: Viola-Jones 人脸检测算法解析(二)
上一篇博客里,我们介绍了VJ人脸检测算法的特征,就是基于积分图像的矩形特征,这些矩形特征也被称为Haar like features, 通常来说,一张图像会生成一个远远高于图像维度的特征集,比如一个 24×24 的图像,会生成162336个矩形特征。在实时的人脸检测应用中,不可能把所有的特征都用上,所有需要做特征选择,这篇博客里,我们将要介绍AdaBoost的训练方法和基于AdaBoost的层级分类器。
AdaBoost 分类
AdaBoost 可以同时进行特征选择与分类器训练,简单来说,AdaBoost 就是将一系列的”弱”分类器通过线性组合,构成一个”强”分类器。如下所示:
h(x) 就是一个”强”分类器,而 hj(x) 就是”弱”分类器,hj(x) 其实是一个简单的阈值函数:
θj 就是阈值,sj∈{−1,1} 以及系数 αj 都由训练的时候确定。结合维基百科和IJCV上的文章 Robust Real-Time Face Detection , 训练算法的具体流程如下:
给定一组N 个训练样本(xi,yi), 其中含有m 个正样本, l 个负样本, 如果 xi 是人脸图像,则 yi=1, 否则 yi=−1,
- 对每一个训练样本 i 赋予一个初始的权值: wi1=1/N
假设一张图像会产生M 个特征,对于每一个特征 fj, j=1,2,...M
1) 对权值重新归一化 wij=wij∑Nt=1wtj
2) 遍历训练集中每个样本特征fj,寻找最优的 θj, sj 使其分类误差最小即: θj,sj=argminθ,s∑Ni=1wijϵij,
其中 ϵij={01ifyi=hj(xi,θj,sj)otherwise
3) 更新下一个特征的权值: wj+1,i=wj,i⋅β1−eij, 如果样本xi 被正确识别则ei=0,否则ei=1. βj=ϵj1−ϵj遍历所有的特征, 可以得到最终的分类器 h(x)=sign(∑Mj=1αjhj(x)) , αj=log1βj
层级分类器
在一张正常的图像中,包含人脸的区域只占整张图像中很小的一部分,如果所有的局部区域都要遍历所有特征的话,这个运算量非常巨大,也非常耗时,所以为了节省运算时间,应该把更多的检测放在潜在的正样本区域上。所以有了层级分类器的概念,层级分类器就是为了将任务简化,一开始用少量的特征将大部分的negative 区域剔除,后面再利用复杂的特征将 false positive 区域剔除。
在层级分类器架构中,每一层次含有一个”强”分类器,所有的矩形特征被分成几组,每一组都包含部分矩形特征,这些矩形特征用在层级分类器的每一阶段,层级分类器的每一阶段都会判别输入的区域是不是人脸,如果肯定不是,那么这个区域会被立即舍弃掉,只有那些被判别为可能是人脸的区域才会被传入下一阶段用更为复杂的分类器进一步的判别。其流程图如下所示:
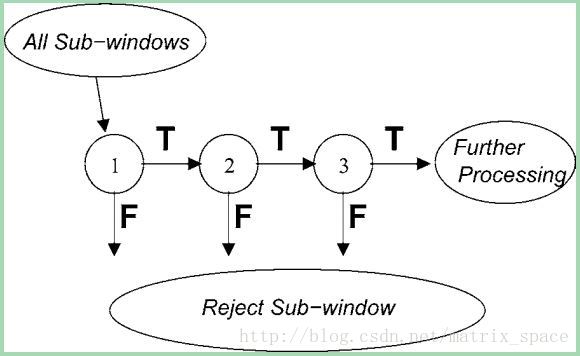
从上图可以看出,所有的局部区域 (sub-windows) 会用比较简单的特征表示,如下图所示。下面的两种特征可以达到100%的检测率,但是也会产生很多的 false positive,一般来说是 50%的FP rate。但是这两种特征对 negative 区域的识别非常高效,所以层级分类器的第一层基本都是用这两种特征加上一个”强”分类器先将大量的negative 区域剔除。对于 false positive 的处理,有赖于后面阶段更多的特征及分类器。

层级分类器的总的识别率D或者false positive F, 是每一层的分类器的识别率 d 和 false postivie f 的乘积,即:
我们利用AdaBoost 训练分类器的时候,目标函数是分类误差,分类误差不能同时反映检测率与false positive rate, 我们可以通过改变阈值的方法来调整检测率与false positive rate, 一般来说,高阈值的分类器的检测率以及false positive rate 都会比较低,而低阈值的分类器的检测率及false positive rate都很高。此外,测试更多的特征将使得分类器提高识别率同时降低false positive rate, 但是测试更多的特征,也会耗费更多的时间。所以一个层级分类器,将综合考虑以下几个因素:
- 层级分类器的层次,即需要多少个分类器;
- 每一层分类器需要测试的特征数 ni;
- 每一层分类器的阈值。
IJCV 的文章提到的算法如下图所示:

一开始需要定义每一层分类器的最大 false positive rate f, 以及最小的检测率 d, 并且需要定义一个全局的 false positive rate Ftarget , 训练的过程中,逐渐增加特征数,利用AdaBoost 进行训练,训练好之后,利用validation set 计算 Fi 和 Di, 逐渐降低第 i 个分类器的阈值,直到当前的层级分类器的检测率不低于 d×Di−1, 然后清空负样本集, 利用当前的层级分类器在数据集上做测试,将所有的 false detections 作为负样本传入下一层分类器的训练。
只有层级分类器的总得 false positive rate Fi 高于设定的 Ftarget,就要增加一层分类器。而后面层的负样本都是由前面分类器产生的 false positive 样本。
在IJCV的文章里,VJ 分类器最后一共是38层,并且含有 6060个特征。 作者给出了前面7层的特征数:
2->10->25->25->50->50->50
参考来源:
https://en.wikipedia.org/wiki/Viola%E2%80%93Jones_object_detection_framework
Viola, Jones: Robust Real-Time Face Detection, IJCV 2001
机器学习: Viola-Jones 人脸检测算法解析(二)的更多相关文章
- 机器学习: Viola-Jones 人脸检测算法解析(一)
在计算机视觉领域中,人脸检测或者物体检测一直是一个非常受关注的领域,而在人脸检测中,Viola-Jones人脸检测算法可以说是非常经典的一个算法,所有从事人脸检测研究的人,都会熟悉了解这个算法,Vio ...
- Python机器学习笔记:异常点检测算法——LOF(Local Outiler Factor)
完整代码及其数据,请移步小编的GitHub 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/MachineLearningNote 在数据挖掘方面,经常需 ...
- 重磅!刷新两项世界纪录的腾讯优图人脸检测算法DSFD开源了!
近日,知名开源社区Github上有个名为DSFD(Dual Shot Face Detector)的算法引起了业内关注,它正是来自于腾讯优图.目前,该算法已经被计算机视觉顶级会议CVPR 2019接收 ...
- 基于Adaboost的人脸检测算法
AdaBoost算法是一种自适应的Boosting算法,基本思想是选取若干弱分类器,组合成强分类器.根据人脸的灰度分布特征,AdaBoost选用了Haar特征[38].AdaBoost分类器的构造过程 ...
- 机器学习--详解人脸对齐算法SDM-LBF
引自:http://blog.csdn.net/taily_duan/article/details/54584040 人脸对齐之SDM(Supervised Descent Method) 人脸对齐 ...
- 吴恩达机器学习笔记55-异常检测算法的特征选择(Choosing What Features to Use of Anomaly Detection)
对于异常检测算法,使用特征是至关重要的,下面谈谈如何选择特征: 异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,例如使用对数函数:
- yolo类检测算法解析——yolo v3
每当听到有人问“如何入门计算机视觉”这个问题时,其实我内心是拒绝的,为什么呢?因为我们说的计算机视觉的发展史可谓很长了,它的分支很多,而且理论那是错综复杂交相辉映,就好像数学一样,如何学习数学?这问题 ...
- 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(二)
前言 已完成数据预处理工作,具体参照: 基于TensorFlow Object Detection API进行迁移学习训练自己的人脸检测模型(一) 设置配置文件 新建目录face_faster_rcn ...
- win10+anaconda+cuda配置dlib,使用GPU对dlib的深度学习算法进行加速(以人脸检测为例)
在计算机视觉和机器学习方向有一个特别好用但是比较低调的库,也就是dlib,与opencv相比其包含了很多最新的算法,尤其是深度学习方面的,因此很有必要学习一下.恰好最近换了一台笔记本,内含一块GTX1 ...
随机推荐
- 线程TLAB区域的深入剖析
(1) 堆是JVM中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的 (2) Sun Hotspot JVM为了提升对象内存分配的效率,对于所创建的线程 ...
- POJ 3627 Bookshelf 贪心 水~
最近学业上堕落成渣了.得开始好好学习了. 还有呀,相家了,好久没回去啦~ 还有和那谁谁谁... 嗯,不能发表悲观言论.说好的. 如果这么点坎坷都过不去的话,那么这情感也太脆弱. ----------- ...
- Python IDLE如何清屏
金gordon 原文 IDLE如何清屏 在学习和使用python的过程中,少不了要与Python IDLE打交道.但使用 Python IDLE 都会遇到一个常见而又懊恼的问题——要怎么清屏? 答案是 ...
- 黑马程序猿-assign、retain、release、nonatomic、atomic、strong、weak
都是用于修饰@property声明的变量 assign:用于非oc对象类型,表示直接赋值(默认值) retain:用于mrc中,用于类属性中有oc对象的情况,表示先推断赋值的对象是否和实例对象变量的值 ...
- Android开发中的小技巧
转自:http://blog.csdn.net/guxiao1201/article/details/40655661 简单介绍: startActivities (Intent[] intents) ...
- iOS开发网络学习七:NSURLSession的基本使用get和post请求
#import "ViewController.h" @interface ViewController () @end @implementation ViewControlle ...
- jquery简单使用(看教程:快全有实例)(固定样式:$().val()设置属性,$().click()设置方法)
jquery简单使用(看教程:快全有实例)(固定样式:$().val()设置属性,$().click()设置方法) 一.总结 1.jquery不懂之处直接看教程,案例都有,有简单又快 2.jquery ...
- C语言高速入门系列(五)
C语言高速入门系列(五) C语言指针初涉 ------转载请注明出处:coder-pig 本节引言: 上一节我们对C ...
- HTML中DOM核心知识有哪些(带实例超详解)
HTML中DOM核心知识有哪些(带实例超详解) 一.总结: 1.先取html元素,然后再对他进行操作,取的话可以getElementById等 2.操作的话,可以是innerHtml,value等等 ...
- 【????】最短路(short)
问题描述: 给出N个点,M条无向边的简单图,问所有点对之间的最短路. 数据输入: 第1行两个正整数N,M(N<=100,M<=5000) 下面M行,每行3个正整数x, y, w,为一条连接 ...