mahout demo——本质上是基于Hadoop的分步式算法实现,比如多节点的数据合并,数据排序,网路通信的效率,节点宕机重算,数据分步式存储
摘自:http://blog.fens.me/mahout-recommendation-api/
测试程序:RecommenderTest.java
测试数据集:item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
测试程序:org.conan.mymahout.recommendation.job.RecommenderTest.java
package org.conan.mymahout.recommendation.job;
import java.io.IOException;
import java.util.List;
import org.apache.mahout.cf.taste.common.TasteException;
import org.apache.mahout.cf.taste.eval.RecommenderBuilder;
import org.apache.mahout.cf.taste.impl.common.LongPrimitiveIterator;
import org.apache.mahout.cf.taste.model.DataModel;
import org.apache.mahout.cf.taste.recommender.RecommendedItem;
import org.apache.mahout.common.RandomUtils;
public class RecommenderTest {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws TasteException, IOException {
RandomUtils.useTestSeed();
String file = "datafile/item.csv";
DataModel dataModel = RecommendFactory.buildDataModel(file);
slopeOne(dataModel);
}
public static void userCF(DataModel dataModel) throws TasteException{}
public static void itemCF(DataModel dataModel) throws TasteException{}
public static void slopeOne(DataModel dataModel) throws TasteException{}
...
每种算法都一个单独的方法进行算法测试,如userCF(),itemCF(),slopeOne()….
5. 基于用户的协同过滤算法UserCF
基于用户的协同过滤,通过不同用户对物品的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐。简单来讲就是:给用户推荐和他兴趣相似的其他用户喜欢的物品。
举例说明:
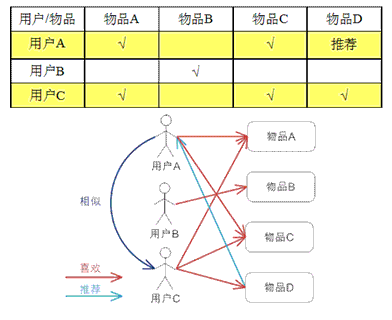
基于用户的 CF 的基本思想相当简单,基于用户对物品的偏好找到相邻邻居用户,然后将邻居用户喜欢的推荐给当前用户。计算上,就是将一个用户对所有物品的偏好作为一个向量来计算用户之间的相似度,找到 K 邻居后,根据邻居的相似度权重以及他们对物品的偏好,预测当前用户没有偏好的未涉及物品,计算得到一个排序的物品列表作为推荐。图 2 给出了一个例子,对于用户 A,根据用户的历史偏好,这里只计算得到一个邻居 – 用户 C,然后将用户 C 喜欢的物品 D 推荐给用户 A。
上文中图片和解释文字,摘自: https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/
算法API: org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender
@Override
public float estimatePreference(long userID, long itemID) throws TasteException {
DataModel model = getDataModel();
Float actualPref = model.getPreferenceValue(userID, itemID);
if (actualPref != null) {
return actualPref;
}
long[] theNeighborhood = neighborhood.getUserNeighborhood(userID);
return doEstimatePreference(userID, theNeighborhood, itemID);
}
protected float doEstimatePreference(long theUserID, long[] theNeighborhood, long itemID) throws TasteException {
if (theNeighborhood.length == 0) {
return Float.NaN;
}
DataModel dataModel = getDataModel();
double preference = 0.0;
double totalSimilarity = 0.0;
int count = 0;
for (long userID : theNeighborhood) {
if (userID != theUserID) {
// See GenericItemBasedRecommender.doEstimatePreference() too
Float pref = dataModel.getPreferenceValue(userID, itemID);
if (pref != null) {
double theSimilarity = similarity.userSimilarity(theUserID, userID);
if (!Double.isNaN(theSimilarity)) {
preference += theSimilarity * pref;
totalSimilarity += theSimilarity;
count++;
}
}
}
}
// Throw out the estimate if it was based on no data points, of course, but also if based on
// just one. This is a bit of a band-aid on the 'stock' item-based algorithm for the moment.
// The reason is that in this case the estimate is, simply, the user's rating for one item
// that happened to have a defined similarity. The similarity score doesn't matter, and that
// seems like a bad situation.
if (count <= 1) {
return Float.NaN;
}
float estimate = (float) (preference / totalSimilarity);
if (capper != null) {
estimate = capper.capEstimate(estimate);
}
return estimate;
}
测试程序:
public static void userCF(DataModel dataModel) throws TasteException {
UserSimilarity userSimilarity = RecommendFactory.userSimilarity(RecommendFactory.SIMILARITY.EUCLIDEAN, dataModel);
UserNeighborhood userNeighborhood = RecommendFactory.userNeighborhood(RecommendFactory.NEIGHBORHOOD.NEAREST, userSimilarity, dataModel, NEIGHBORHOOD_NUM);
RecommenderBuilder recommenderBuilder = RecommendFactory.userRecommender(userSimilarity, userNeighborhood, true);
RecommendFactory.evaluate(RecommendFactory.EVALUATOR.AVERAGE_ABSOLUTE_DIFFERENCE, recommenderBuilder, null, dataModel, 0.7);
RecommendFactory.statsEvaluator(recommenderBuilder, null, dataModel, 2);
LongPrimitiveIterator iter = dataModel.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = recommenderBuilder.buildRecommender(dataModel).recommend(uid, RECOMMENDER_NUM);
RecommendFactory.showItems(uid, list, true);
}
}
程序输出:
AVERAGE_ABSOLUTE_DIFFERENCE Evaluater Score:1.0
Recommender IR Evaluator: [Precision:0.5,Recall:0.5]
uid:1,(104,4.333333)(106,4.000000)
uid:2,(105,4.049678)
uid:3,(103,3.512787)(102,2.747869)
uid:4,(102,3.000000)
mahout demo——本质上是基于Hadoop的分步式算法实现,比如多节点的数据合并,数据排序,网路通信的效率,节点宕机重算,数据分步式存储的更多相关文章
- 从本质上学会基于HarmonyOS开发Hi3861(主要讲授方法)
引言:花半秒钟就看透事物本质的人,和花一辈子都看不透事物本质的人,注定是截然不同的命运 做开发也一样,如果您能看透开发的整个过程,就不会出现"学会了某个RTOS的开发,同样的RTOS开发换一 ...
- 伪基站,卒于5G——本质上是基于网络和UE辅助的伪基站检测,就是将相邻基站的CI、信号强度等信息通过测量报告上报给网络,网络结合网络拓扑、配置信息等相关数据,对所有数据进行综合分析,确认在某个区域中是否存在伪基站
伪基站,卒于5G from:https://www.huxiu.com/article/251252.html?h_s=h8 2018-07-05 21:58收藏27评论6社交通讯 本文来自微 ...
- 基于Hadoop的改进Apriori算法
一.Apriori算法性质 性质一: 候选的k元组集合Ck中,任意k-1个项组成的集合都来自于Lk. 性质二: 若k维数据项目集X={i1,i2,-,ik}中至少存在一个j∈X,使得|L(k-1)(j ...
- 基于FPGA的肤色识别算法实现
大家好,给大家介绍一下,这是基于FPGA的肤色识别算法实现. 我们今天这篇文章有两个内容一是实现基于FPGA的彩色图片转灰度实现,然后在这个基础上实现基于FPGA的肤色检测算法实现. 将彩色图像转化为 ...
- 在Hadoop上运行基于RMM中文分词算法的MapReduce程序
原文:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-count-on-hadoop/ 在Hadoop上运行基于RMM中文分词 ...
- 基于Hadoop的密码安全级别验证
学习Hadoop有一段时间了,期间写过很多Demo,都是针对单个知识点做的验证,今天写个完整的应用程序——基于Hadoop的密码安全级别验证. 在很多网站上注册用户时输入密码都会在下方提示密码安全级别 ...
- [转] X-RIME: 基于Hadoop的开源大规模社交网络分析工具
转自http://www.dataguru.cn/forum.php?mod=viewthread&tid=286174 随着互联网的快速发展,涌现出了一大批以Facebook,Twitter ...
- Hive -- 基于Hadoop的数据仓库分析工具
Hive是一个基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库 ...
- 基于Hadoop的大数据平台实施记——整体架构设计[转]
http://blog.csdn.net/jacktan/article/details/9200979 大数据的热度在持续的升温,继云计算之后大数据成为又一大众所追捧的新星.我们暂不去讨论大数据到底 ...
随机推荐
- POJ 3275 Floyd传递闭包
题意:Farmer John想按照奶牛产奶的能力给她们排序.现在已知有N头奶牛(1 ≤ N ≤ 1,000).FJ通过比较,已经知道了M(1 ≤ M ≤ 10,000)对相对关系.每一对关系表示为&q ...
- DevExpress的GridControl拖拽DraopDown后计算HitInfo的RowHandle错误
最近在使用GridControl的拖拽功能时候遇到了一个问题:当GridControl触发DropDrop事件时,计算对应的RowHandle错误.当把鼠标拖拽到GridView一个单元格的靠上面的部 ...
- js两个页面之间URL传递参数中文乱码
- NFA
任意正则表达式都存在一个与之对应的NFA,反之亦然. 正则表达式 ((A*B|AC)D)对应的NFA(有向图), 其中红线对应的为该状态的ε转换, 黑线表示匹配转换 我们定义的NFA具有以下特点: 正 ...
- hadoop基础学习
MR系类: ①hadoop生态 >MapReduce:分布式处理 >Hdfs:hadoop distribut file system >其他相关框架 ->unstructur ...
- FAQ: SBS 2011. The Windows SBS Manager service terminated unexpectedly
Symptoms The Windows SBS Manager service is stopped with EventID 7034 every half an hour on SBS 2011 ...
- 转载:关于 python ImportError: No module named 的问题
关于 python ImportError: No module named 的问题 今天在 centos 下安装 python setup.py install 时报错:ImportError: N ...
- **PCL:嵌入VTK/QT显示(Code^_^)
中国人真是太不知道分享了,看看这个老外的博客,启发性链接. http://www.pcl-users.org/ 1. 这个是可用的源代码: 原文:I saw a thread with links t ...
- ML及AI资源索引
原文链接:http://blog.csdn.net/pongba/article/details/2915005 机器学习与人工智能学习资源导引 TopLanguage(https://groups. ...
- B站真的是一个神奇的地方,初次用Python爬取弹幕。
"网上冲浪""886""GG""沙发"--如果你用过这些,那你可能是7080后: "杯具"" ...