Spark Streaming 总结
这篇文章记录我使用 Spark Streaming 进行 ETL 处理的总结,主要包含如何编程,以及遇到的问题。
环境
我在公司使用的环境如下:
- Spark: 2.2.0
- Kakfa: 0.10.1
这两个版本算是比较新的。
业务
从 Kafka 中读取数据,用 SQL 处理,写入 Kafka 中。 程序主要分为 3大块:
- 从 Kafka 中读取数据。
- SQL ETL。
- 写入 Kafka。
编程
从 Kafka 中读取数据
spark-streaming-kafka-0-10_2.11
最开始使用spark-streaming-kafka-0-10_2.11。虽然这个包是实验阶段,但是考虑到用起来比较方便,就使用了这个包。整个代码的框架和官方文档的一样。
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// some time later, after outputs have completed
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
编程很快,但是后面遇到了很多问题:
异常错误:WARN TaskSetManager: Lost task 9.0 in stage 1683.0 (TID 9460, 10.62.34.25, executor 9): java.lang.AssertionError: assertion failed: Failed to get records for spark-executor-2017-10-20-1100-streaming-test 1231231 1 13733588428 after polling for 1000。
这个错误是 DirectKafkaStream 在 poll 数据的时候,发现没有数据返回, 代码如下:
```scala
// 从 buffer 获取数据,如果buffer 中没有数据,就 poll 数据。
if (!buffer.hasNext()) { poll(timeout) }
assert(buffer.hasNext(),
s"Failed to get records for $groupId $topic $partition $offset after polling for $timeout")
var record = buffer.next()
...
```
上面的代码的意思是从 kafka 中 poll 数据,如果 timeout 长时间后还没有得到数据,就报错。 而实际我们的 Kafka 数据每秒钟有几千条。 并且 timeout 默认是 1秒,不可能拿不到数据。最后发现
spark-streaming-kafka-0-10_2.11这个包对应的kafka-clients是 0.10.0.1。而这个版本的kafka-clients是有 BUG的,于是将kafka-clients的版本升级到 0.10.2.1。问题解决了。测试的时候,发现在停止掉程序后,在重开程序,重复消费一部分数据。 那么这个问题就是,程序停止的时候没有正确的提交当前消费的 offset。
我们的程序是通过stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)来提交每个 RDD 的 offset 的。而这段代码的背后是将 offsetRanges 保存到了一个队列中。 等到下次从 kafka 中获取下一个 batch 的数据后(通过 compute 函数),顺便将队列中的 offset 提交到 KafkaCluster 中。
代码如下:
// 保存到 queue 中
def commitAsync(offsetRanges: Array[OffsetRange], callback: OffsetCommitCallback): Unit = {
commitCallback.set(callback)
commitQueue.addAll(ju.Arrays.asList(offsetRanges: _*))
} // 提交 offset , 将 queue 中的 offset 保存到 map 中,并提交
protected def commitAll(): Unit = {
val m = new ju.HashMap[TopicPartition, OffsetAndMetadata]()
var osr = commitQueue.poll()
while (null != osr) {
val tp = osr.topicPartition
val x = m.get(tp)
val offset = if (null == x) { osr.untilOffset } else { Math.max(x.offset, osr.untilOffset) }
m.put(tp, new OffsetAndMetadata(offset))
osr = commitQueue.poll()
}
if (!m.isEmpty) {
consumer.commitAsync(m, commitCallback.get)
}
} // 每次从 kafka 中获取数据, 顺便提交 上一次的 offset
override def compute(validTime: Time): Option[KafkaRDD[K, V]] = {
// 获取当前的 offset, 如果程序保存了offset就用程序的,如果没有,就从kafka中读取。
// 当程序重启后,就会从kafka中读取。
val untilOffsets = clamp(latestOffsets())
val offsetRanges = untilOffsets.map { case (tp, uo) =>
val fo = currentOffsets(tp)
OffsetRange(tp.topic, tp.partition, fo, uo)
}
...
// 获取到了数据,并保存在 rdd 中
val rdd = new KafkaRDD[K, V](context.sparkContext, executorKafkaParams, offsetRanges.toArray,
getPreferredHosts, useConsumerCache)
....
// 更新 offset
currentOffsets = untilOffsets
// 重点:提交 queue 中的offset
commitAll()
Some(rdd)
}看完这个逻辑,傻眼了。这样子程序结束,处理完最后一个 batch, 它的 offset 是没有办法提交到 cluster 的,结果就是重复消费。如果要自己写提交 offset 的代码,那和老版本的就没有区别了。
考虑了半天,最终还是用老的包来实现了。
spark-streaming-kafka-0-8
使用老的包,我们的逻辑如下:
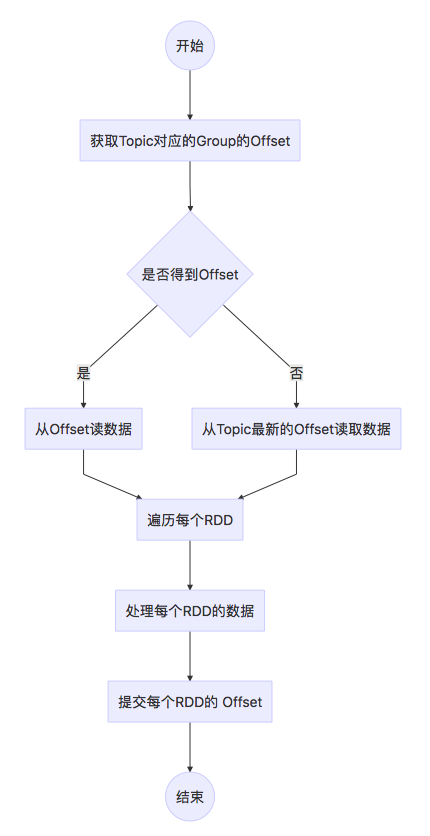
代码实现如下:
...
各种参数初始化
val kafkaCluster = new KafkaCluster(kafkaClusterParams)
val topicAndPartitionSet = kafkaCluster.getPartitions(consumerTopics.toSet).right.get
var consumerOffsetsLong = new mutable.HashMap[TopicAndPartition, Long]()
if (kafkaCluster.getConsumerOffsets(kafkaClusterParams.get("group.id").toString, topicAndPartitionSet).isLeft) {
val latestOffset = kafkaCluster.getLatestLeaderOffsets(topicAndPartitionSet)
topicAndPartitionSet.foreach(tp => {
consumerOffsetsLong.put(tp, latestOffset.right.get(tp).offset)
})
} else {
val consumerOffsetsTemp = kafkaCluster.getConsumerOffsets(kafkaClusterParams.get("group.id").toString, topicAndPartitionSet)
topicAndPartitionSet.foreach(tp => {
consumerOffsetsLong.put(tp, consumerOffsetsTemp.right.get(tp))
})
}
val kafkaClusterParamsBroadcast = ssc.sparkContext.broadcast(kafkaClusterParams)
val stream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder, String](
ssc, kafkaClusterParams, consumerOffsetsLong.toMap, (mmd: MessageAndMetadata[String, String]) => mmd.message() )
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// 处理业务逻辑
val m = new mutable.HashMap[TopicAndPartition, Long]()
if (null != offsetRanges) {
offsetRanges.foreach(
osr => {
val tp = osr.topicAndPartition
m.put(tp, osr.untilOffset)
}
)
}
kafkaCluster.setConsumerOffsets(kafkaClusterParamsBroadcast.value.get("group.id").toString, m.toMap)
}
这样子来处理数据,一切正常。
SQL ETL
SQL ETL 就是使用 Spark SQL 进行处理。如果要对多个同一个 batch 进行多次处理,最好是 将 bacth cache 起来。
将数据写入 Kafak 中
这个就是从网上找的了:
import java.util.concurrent.Future
import org.apache.kafka.clients.producer.{ KafkaProducer, ProducerRecord, RecordMetadata }
class KafkaSink[K, V](createProducer: () => KafkaProducer[K, V]) extends Serializable {
/* This is the key idea that allows us to work around running into
NotSerializableExceptions. */
lazy val producer = createProducer()
def send(topic: String, key: K, value: V): Future[RecordMetadata] =
producer.send(new ProducerRecord[K, V](topic, key, value))
def send(topic: String, value: V): Future[RecordMetadata] =
producer.send(new ProducerRecord[K, V](topic, value))
def close(): Unit = {
producer.close()
}
}
object KafkaSink {
import scala.collection.JavaConversions._
def apply[K, V](config: Map[String, AnyRef]): KafkaSink[K, V] = {
val createProducerFunc = () => {
val producer = new KafkaProducer[K, V](config)
producer
}
new KafkaSink(createProducerFunc)
}
def apply[K, V](config: java.util.Properties): KafkaSink[K, V] = apply(config.toMap)
}
使用方式:
// 广播KafkaSink
val kafkaSinkBroadcast: Broadcast[KafkaSink[String, String]] = {
ssc.sparkContext.broadcast(KafkaSink[String, String](kafkaSinkParams))
}
val kafkaProducerTopicBroadcast = ssc.sparkContext.broadcast(producerTopic)
stream.foreachRDD {
....
kafkaSinkBroadcast.value.send(kafkaProducerTopicBroadcast.value, str)
}
整体上的代码就是这么多。
配置
除了代码,Spark Streaming 还是需要某些配置的,具体如下:
- "spark.executor.cores":"2"。默认的 Yarn 模式下,core 的个数是1个。当 executor 的压力过大的时候,经常会出现 connect reset by peer 和 心跳超时,所以要看情况增加 core 的个数。
- "spark.driver.extraJavaOptions":"-Dlog4j.configuration=file:log4j.properties" 。Spark 默认的日志级别就是 INFO, 通常会打印出很多的信息,日志一晚上就上G了,所以最好自定义自己的配置文件。
- "spark.executor.extraJavaOptions":"-XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintHeapAtGC -XX:+PrintGCTimeStamps" 。 使用 G1 的垃圾回收方式,并打印出具体的信息,方便在 GC 时间过长的时候进行调优。
- "spark.streaming.stopGracefullyOnShutdown":"true"。让 Streaming 程序在收到 Terminate 信号后,处理完最后一个 batch 再退出。通常停止程序的时候,运行两次
kill -15 driver_pid就可以停止掉程序。
"spark.streaming.backpressure.enabled":"true",
"spark.streaming.backpressure.initialRate":"1000000",
"spark.streaming.kafka.maxRatePerPartition":"20000",
这三个参数用来限制消费 kafka 的速度。避免一次消费太多的数据,将程序搞垮掉。
Spark Streaming 总结的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Storm介绍及与Spark Streaming对比
Storm介绍 Storm是由Twitter开源的分布式.高容错的实时处理系统,它的出现令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求.Storm常用于在实时分析.在线机器学 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- spark streaming kafka example
// scalastyle:off println package org.apache.spark.examples.streaming import kafka.serializer.String ...
- Spark Streaming中动态Batch Size实现初探
本期内容 : BatchDuration与 Process Time 动态Batch Size Spark Streaming中有很多算子,是否每一个算子都是预期中的类似线性规律的时间消耗呢? 例如: ...
- Spark Streaming源码解读之No Receivers彻底思考
本期内容 : Direct Acess Kafka Spark Streaming接收数据现在支持的两种方式: 01. Receiver的方式来接收数据,及输入数据的控制 02. No Receive ...
- Spark Streaming架构设计和运行机制总结
本期内容 : Spark Streaming中的架构设计和运行机制 Spark Streaming深度思考 Spark Streaming的本质就是在RDD基础之上加上Time ,由Time不断的运行 ...
- Spark Streaming中空RDD处理及流处理程序优雅的停止
本期内容 : Spark Streaming中的空RDD处理 Spark Streaming程序的停止 由于Spark Streaming的每个BatchDuration都会不断的产生RDD,空RDD ...
- Spark Streaming源码解读之State管理之UpdataStateByKey和MapWithState解密
本期内容 : UpdateStateByKey解密 MapWithState解密 Spark Streaming是实现State状态管理因素: 01. Spark Streaming是按照整个Bach ...
随机推荐
- ubuntu中不能远程连接解决
今天装好ubuntu19.04之后不能远程连接,网上找了很久终于自己解决了.ap 步骤如下:希望对各位有用,哪里不对请指出 第一步我们需要加载openssh-server 等待加载完毕后, ...
- $.ajax 和$.post的区别
https://blog.csdn.net/weixin_39709686/article/details/78680754
- docker初安装的血泪史
最近docker很火,不管是朋友圈内还是公司内聊天都离不开docker,于是对docker产生了极大的好奇心,凭着一颗程序猿的好奇心开始了docker的安装血泪史. 首先我有一台从公司退役的本本x22 ...
- 01《UML大战需求分析》阅读笔记之一
在大二的时候就已经在课堂上对UML也就是统一建模语言有了初步的了解,但是却不怎么明白,虽然可以画图可以完成任务,但是有些糊里糊涂.所以特地把这门书作为精读书籍,想要更加深度地学习UML.很多内容只用语 ...
- JS判断客户端是否是iOS或者Android或者ipad(三)
* * @function: 判断浏览器类型是否是Safari.Firefox.ie.chrome浏览器 * @return: true或false * */ function isSafa ...
- poj2406 Power Strings (kmp 求最小循环字串)
Power Strings Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 47748 Accepted: 19902 ...
- java开发移动端之spring的restful风格定义
https://www.ibm.com/developerworks/cn/web/wa-spring3webserv/index.html
- IOS - 总结(网络状态变更)
- (void)initNetworkMonitor { NSURL *baseURL = [NSURL URLWithString:@"http://www.baidu.com/" ...
- HDU 1023 Train Problem II( 大数卡特兰 )
链接:传送门 题意:裸卡特兰数,但是必须用大数做 balabala:上交高精度模板题,增加一下熟悉度 /************************************************ ...
- 2019-03-15 使用Request POST获取CNABS网站上JSON格式的表格数据,并解析出来用xlwt写到Excel中
import requests import xlwt url = 'https://v1.cn-abs.com/ajax/ChartMarketHandler.ashx' headers={ 'Us ...