HBase编程 API入门系列之modify(管理端而言)(10)
这里,我带领大家,学习更高级的,因为,在开发中,尽量不能去服务器上修改表。
所以,在管理端来修改HBase表。采用线程池的方式(也是生产开发里首推的)
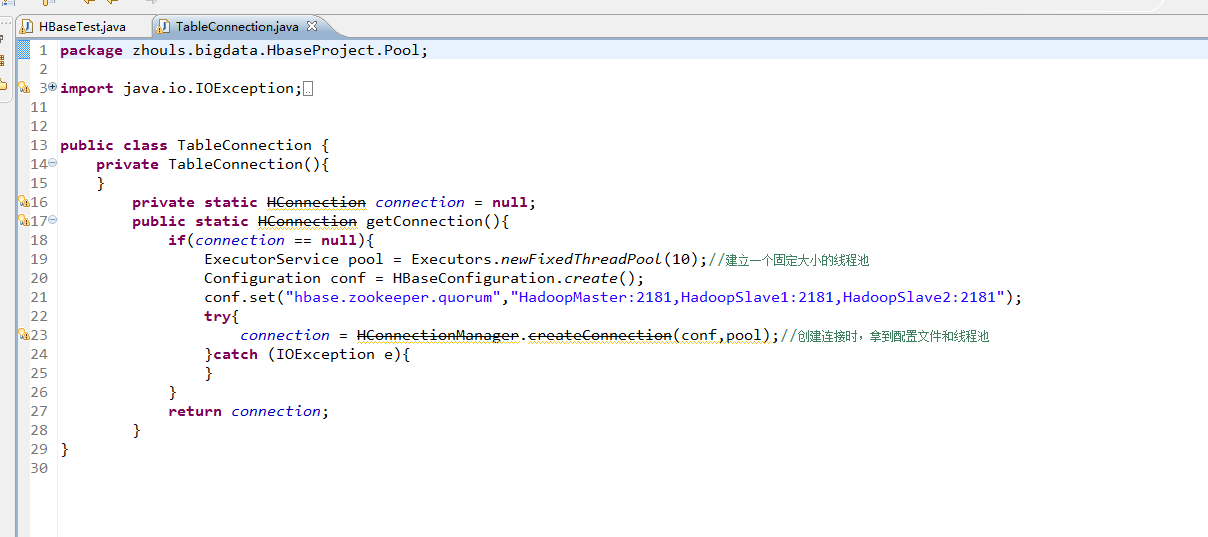
package zhouls.bigdata.HbaseProject.Pool;
import java.io.IOException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
public class TableConnection {
private TableConnection(){
}
private static HConnection connection = null;
public static HConnection getConnection(){
if(connection == null){
ExecutorService pool = Executors.newFixedThreadPool(10);//建立一个固定大小的线程池
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181");
try{
connection = HConnectionManager.createConnection(conf,pool);//创建连接时,拿到配置文件和线程池
}catch (IOException e){
}
}
return connection;
}
}
1、修改HBase表
暂时,有错误
package zhouls.bigdata.HbaseProject.Pool;
import java.io.IOException;
import zhouls.bigdata.HbaseProject.Pool.TableConnection;
import javax.xml.transform.Result;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.HTableInterface;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseTest {
public static void main(String[] args) throws Exception {
// HTable table = new HTable(getConfig(),TableName.valueOf("test_table"));//表名是test_table
// Put put = new Put(Bytes.toBytes("row_04"));//行键是row_04
// put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy1"));//列簇是f,列修饰符是name,值是Andy0
// put.add(Bytes.toBytes("f2"),Bytes.toBytes("name"),Bytes.toBytes("Andy3"));//列簇是f2,列修饰符是name,值是Andy3
// table.put(put);
// table.close();
// Get get = new Get(Bytes.toBytes("row_04"));
// get.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));如现在这样,不指定,默认把所有的全拿出来
// org.apache.hadoop.hbase.client.Result rest = table.get(get);
// System.out.println(rest.toString());
// table.close();
// Delete delete = new Delete(Bytes.toBytes("row_2"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("email"));
// delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("name"));
// table.delete(delete);
// table.close();
// Delete delete = new Delete(Bytes.toBytes("row_04"));
//// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));//deleteColumn是删除某一个列簇里的最新时间戳版本。
// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));//delete.deleteColumns是删除某个列簇里的所有时间戳版本。
// table.delete(delete);
// table.close();
// Scan scan = new Scan();
// scan.setStartRow(Bytes.toBytes("row_01"));//包含开始行键
// scan.setStopRow(Bytes.toBytes("row_03"));//不包含结束行键
// scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));
// ResultScanner rst = table.getScanner(scan);//整个循环
// System.out.println(rst.toString());
// for (org.apache.hadoop.hbase.client.Result next = rst.next();next !=null;next = rst.next() )
// {
// for(Cell cell:next.rawCells()){//某个row key下的循坏
// System.out.println(next.toString());
// System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell)));
// System.out.println("col:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
// System.out.println("value" + Bytes.toString(CellUtil.cloneValue(cell)));
// }
// }
// table.close();
HBaseTest hbasetest =new HBaseTest();
// hbasetest.insertValue();
// hbasetest.getValue();
// hbasetest.delete();
// hbasetest.scanValue();
hbasetest.createTable("test_table3", "f");//先判断表是否存在,再来创建HBase表(生产开发首推)
// hbasetest.deleteTable("test_table4");//先判断表是否存在,再来删除HBase表(生产开发首推)
// hbasetest.modifyTable("test_table","row_02","f",'f:age');
}
//生产开发中,建议这样用线程池做
// public void insertValue() throws Exception{
// HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table"));
// Put put = new Put(Bytes.toBytes("row_01"));//行键是row_01
// put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy0"));
// table.put(put);
// table.close();
// }
//生产开发中,建议这样用线程池做
// public void getValue() throws Exception{
// HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table"));
// Get get = new Get(Bytes.toBytes("row_03"));
// get.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));
// org.apache.hadoop.hbase.client.Result rest = table.get(get);
// System.out.println(rest.toString());
// table.close();
// }
//
//生产开发中,建议这样用线程池做
// public void delete() throws Exception{
// HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table"));
// Delete delete = new Delete(Bytes.toBytes("row_01"));
// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));//deleteColumn是删除某一个列簇里的最新时间戳版本。
//// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));//delete.deleteColumns是删除某个列簇里的所有时间戳版本。
// table.delete(delete);
// table.close();
//
// }
//生产开发中,建议这样用线程池做
// public void scanValue() throws Exception{
// HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table"));
// Scan scan = new Scan();
// scan.setStartRow(Bytes.toBytes("row_02"));//包含开始行键
// scan.setStopRow(Bytes.toBytes("row_04"));//不包含结束行键
// scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));
// ResultScanner rst = table.getScanner(scan);//整个循环
// System.out.println(rst.toString());
// for (org.apache.hadoop.hbase.client.Result next = rst.next();next !=null;next = rst.next() )
// {
// for(Cell cell:next.rawCells()){//某个row key下的循坏
// System.out.println(next.toString());
// System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell)));
// System.out.println("col:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
// System.out.println("value" + Bytes.toString(CellUtil.cloneValue(cell)));
// }
// }
// table.close();
// }
//
//生产开发中,建议这样用线程池做
public void createTable(String tableName,String family) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{
Configuration conf = HBaseConfiguration.create(getConfig());
HBaseAdmin admin = new HBaseAdmin(conf);
HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName));
HColumnDescriptor hcd = new HColumnDescriptor(family);
hcd.setMaxVersions(3);
// hcd.set//很多的带创建操作,我这里只抛砖引玉的作用
tableDesc.addFamily(hcd);
if (!admin.tableExists(tableName)){
admin.createTable(tableDesc);
}else{
System.out.println(tableName + "exist");
}
admin.close();
}
public void modifyTable(String tableName,String rowkey,String family,HColumnDescriptor hColumnDescriptor) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{
Configuration conf = HBaseConfiguration.create(getConfig());
HBaseAdmin admin = new HBaseAdmin(conf);
// HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName));
HColumnDescriptor hcd = new HColumnDescriptor(family);
// NamespaceDescriptor nsd = admin.getNamespaceDescriptor(tableName);
// nsd.setConfiguration("hbase.namespace.quota.maxregion", "10");
// nsd.setConfiguration("hbase.namespace.quota.maxtables", "10");
if (admin.tableExists(tableName)){
admin.modifyColumn(tableName, hcd);
// admin.modifyTable(tableName, tableDesc);
// admin.modifyNamespace(nsd);
}else{
System.out.println(tableName + "not exist");
}
admin.close();
}
//生产开发中,建议这样用线程池做
// public void deleteTable(String tableName)throws MasterNotRunningException, ZooKeeperConnectionException, IOException{
// Configuration conf = HBaseConfiguration.create(getConfig());
// HBaseAdmin admin = new HBaseAdmin(conf);
// if (admin.tableExists(tableName)){
// admin.disableTable(tableName);
// admin.deleteTable(tableName);
// }else{
// System.out.println(tableName + "not exist");
// }
// admin.close();
// }
public static Configuration getConfig(){
Configuration configuration = new Configuration();
// conf.set("hbase.rootdir","hdfs:HadoopMaster:9000/hbase");
configuration.set("hbase.zookeeper.quorum", "HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181");
return configuration;
}
}
HBase编程 API入门系列之modify(管理端而言)(10)的更多相关文章
- HBase编程 API入门系列之create(管理端而言)(8)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门系列之put(客户端而言)(1) 就知道,在这篇博文里,我是在HBase Shell里创建HBase表的. 这里,我带领大家,学习更高 ...
- HBase编程 API入门系列之delete(客户端而言)(3)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面的基础,如下 HBase编程 API入门系列之put(客户端而言)(1) HBase编程 API入门系列之get(客户端而言) ...
- HBase编程 API入门系列之get(客户端而言)(2)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. 前面是基础,如下 HBase编程 API入门系列之put(客户端而言)(1) package zhouls.bigdata.Hba ...
- HBase编程 API入门系列之HTable pool(6)
HTable是一个比较重的对此,比如加载配置文件,连接ZK,查询meta表等等,高并发的时候影响系统的性能,因此引入了“池”的概念. 引入“HBase里的连接池”的目的是: 为了更高的,提高程序的并发 ...
- HBase编程 API入门系列之delete(管理端而言)(9)
大家,若是看过我前期的这篇博客的话,则 HBase编程 API入门之delete(客户端而言) 就知道,在这篇博文里,我是在客户端里删除HBase表的. 这里,我带领大家,学习更高级的,因为,在开发中 ...
- HBase编程 API入门系列之工具Bytes类(7)
这是从程度开发层面来说,为了方便和提高开发人员. 这个工具Bytes类,有很多很多方法,帮助我们HBase编程开发人员,提高开发. 这里,我只赘述,很常用的! package zhouls.bigda ...
- HBase编程 API入门系列之put(客户端而言)(1)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. [hadoop@HadoopSlave1 conf]$ cat regionservers HadoopMasterHadoopS ...
- HBase编程 API入门系列之scan(客户端而言)(5)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. package zhouls.bigdata.HbaseProject.Test1; import javax.xml.trans ...
- HBase编程 API入门系列之delete.deleteColumn和delete.deleteColumns区别(客户端而言)(4)
心得,写在前面的话,也许,中间会要多次执行,连接超时,多试试就好了. delete.deleteColumn和delete.deleteColumns区别是: deleteColumn是删除某一个列簇 ...
随机推荐
- 【sqli-labs】 less25a GET- Blind based -All you OR&AND belong to us -Intiger based(GET型基于盲注的去除了or和and的整型注入)
因为过滤是针对输入的字符串进行的过滤,所以如果过滤了or and的话,提交id=1和id=and1结果应该相同 http://localhost/sqli-labs-master/Less-25a/? ...
- js与Jquery的对比
// document.getElementById("divCommit").style.display="none";// document.g ...
- Js正则匹配处理时间
<html> <body> <script type="text/javascript"> //将long 型 转换为 日期格式 年-月-日 h ...
- eoLinker-AMS开源版JAVA版本正式发布
eoLinker-AMS开源版JAVA版本正式发布! eoLinker深感广大开发者的支持与厚爱,我们一直在努力为大家提供更多更好的接口服务.截止至2018年4月3日,eoLinker-AMS 开源版 ...
- 基于MATLAB的多功能语音处理器
一.设计功能 录制音频,保存音频 对录制的语音信号进行频谱分析,确定该段语音的主要频率范围: 利用采样定理,对该段语音信号进行采样,观察不用采样频率(过采样.欠采样.临界采样)对信号的影响: 实现语音 ...
- mint-ui 取值
//slots:[{values: ['年假', '事假', '病假', '婚假', '其他']}], slots:[{values: []}], onValuesChange(picker,valu ...
- [系统资源攻略]IO第二篇
IO 磁盘通常是计算机最慢的子系统,也是最容易出现性能瓶颈的地方,因为磁盘离 CPU 距离最远而且 CPU 访问磁盘要涉及到机械操作,比如转轴.寻轨等.访问硬盘和访问内存之间的速度差别是以数量级来计算 ...
- 01 c++常见面试题总结
https://www.cnblogs.com/yjd_hycf_space/p/7495640.html C++常见的面试题 http://c.tedu.cn/workplace/217749. ...
- request.getScheme()、 request.getServerName() 、 request.getServerPort() 、 request.getContextPath()
<% String basePath = request.getScheme() + "://" + request.getServerName() + ":&qu ...
- AnimationEvent事件问题
AnimationEvent事件问题 本文章由cartzhang编写,转载请注明出处. 所有权利保留. 文章链接:http://blog.csdn.net/cartzhang/article/deta ...