node——模块分类,require执行顺序,require注意事项,原理
node.js模块
在node.js开发中一个文件就可以认为是一个模块。
一、node.js模块分类
核心模块Code Module、内置模块、原生模块
fs
http
path
url
...
所有内置模块在安装node.js的时候就已经编译成二进制文件,可以直接加载运行(速读较快)
部分内置模块,在node.exe这个进程启动的时候就已经默认加载了,所以可以直接使用。
文件模块
按文件后缀来分
如果加载时,没有指定后缀名,那么就按照如下顺序依次加载相应模块
1.js
2.json
4.node(C/c++编写模块)
自定义模块
mime
cheerio
moment
mongo
...
二、加载顺序
1.require(一个路径)
require('./index2')
//index2.js
//index2.json
//index2.node
//index2文件夹->package.json文件->main(入口文件 app.js->index.js/index.json/index.node)->加载失败
在加载index2的时候,require会先去找index2.js文件,没有就去找.json文件,再没有就找node文件,如果这些都没有,它会认为index2是一个文件夹,如果找到了这个文件夹,require还会去找这个文件夹里面是否有package.json,如果没有就加载失败,如果有,就找package.json里的main(),就加载里面的index.js/index.json/index.node,如果没有,也是失败。
在加载文件模块的时候最好写上后缀,这样会省一些步骤
2.require()的参数不是一个路径,直接是一个模块名称
1).现在核心模块中查找,是否有名字一样的模块,如果有,则直接加载该核心模块
如:require('http')
2)如果核心模块中没有该模块,就很认为是一个第三方模块(自定义模块)
先会去当前js文件所在的目录下找node_modules文件夹,当前目录没有,会去当前执行的文件的父目录里面寻找
三、require加载注意事项
1.所以模块第一次加载完毕以后都会有缓存,第二次加载直接读取缓存,避免了二次开销
因为有缓存,所以模块中的代码只在第一次加载的时候执行一次
2.每次加载模块的时候都有限从缓存中加载,缓存中没有才会按照node.js加载模块规则去查找
3.核心模块Node.js源码编译的时候,都已经编译为二进制执行文件,所以加载速度较快(核心模块加载优先级仅次于缓存加载)
4.试图加载一个和核心模块同名的自定义(第三方模块)是不会成功的
自定义模块要么名字不要和核心模块同名,要么使用路径的方式加载
6.核心模块只能通过模块名称来加载
7.require()加载模块使用./相对路径时,是先对当前模块,不受node命令执行路径影响
8.建议在加载文件模块时,尽量添加文件后缀名
四、require加载原理

在a.js文件中
//加载b.js模块
require('./b.js');
在b.js文件中
function add(x,y){
return x+y;
}
var result=add(100,1000);
console.log(result);
执行a.js

加载自定义模块b.js的时候,会执行一次b.js
修改a.js
//加载b.js模块
require('./b.js'); require('./b.js');
require('./b.js');
require('./b.js');
require('./b.js');
require('./b.js');
执行a.js

由此可见,require模块第一次加载会执行模块代码,后面加载的模块都是从缓存里面获取的,所以不会再去执行模块代码了。
在文件中查找第三方模块时依次查找的路径
console.log(module.paths);

源代码
1.检查Module.cache里有没有缓存的模块实例,如果缓存里面没有,就创建一个Module实例,将创建的Module保存到缓存里面,供下次使用
2.调用module.load()读取模块内容,然后调用modele.compile()编译执行(封装为一个沙盒)改模块
3.如果加载出错,就从缓存中删除该模块
4.返回module.export
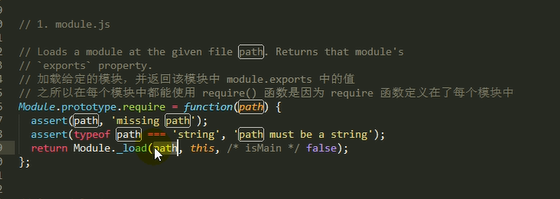
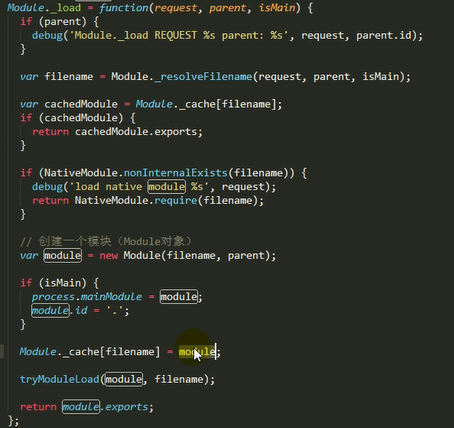
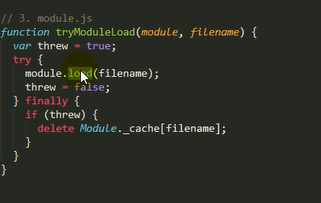
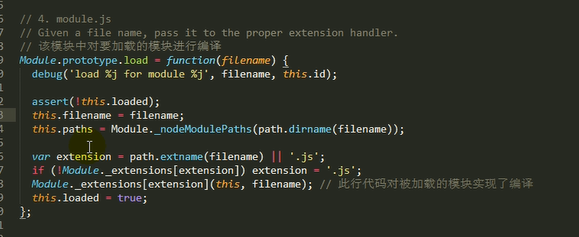
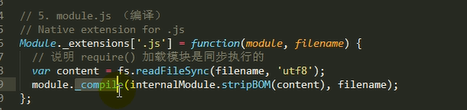

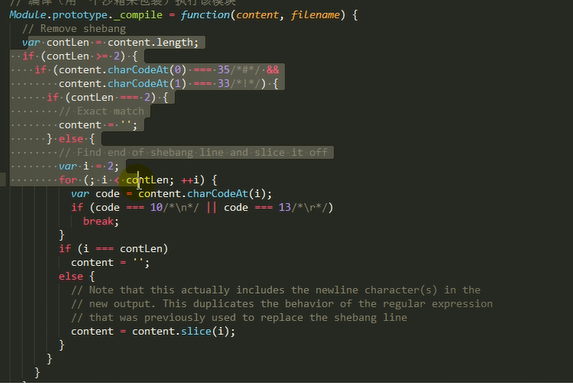
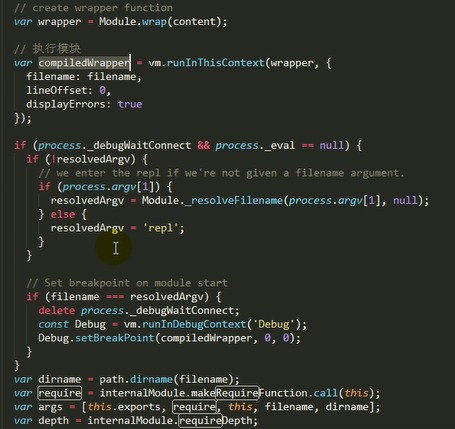

主要做的是通过module._load来加载模块,判断缓存,如果没在缓存里就创建
node——模块分类,require执行顺序,require注意事项,原理的更多相关文章
- python导入模块时的执行顺序
当python导入模块,执行import语句时,到底进行了什么操作?按照python的文档,她执行了如下的操作: 第一步,创建一个新的module对象(它可能包含多个module) 第二步,把这个mo ...
- Node async 控制代码执行顺序
当你有一个集合,你想循环集合,然后对每个集合按照顺序执行相应的方法你可以使用forEachSeries
- Nginx 配置指令的执行顺序(十)
运行在 post-rewrite 阶段之后的是所谓的 preaccess 阶段.该阶段在 access 阶段之前执行,故名preaccess. 标准模块 ngx_limit_req 和 ngx_lim ...
- python接口自动化(二十二)--unittest执行顺序隐藏的坑(详解)
简介 大多数的初学者在使用 unittest 框架时候,不清楚用例的执行顺序到底是怎样的.对测试类里面的类和方法分不清楚,不知道什么时候执行,什么时候不执行.虽然或许通过代码实现了,也是稀里糊涂的一知 ...
- pytest(4)-测试用例执行顺序
前言 上一篇文章我们讲了在pytest中测试用例的命名规则,那么在pytest中又是以怎样的顺序执行测试用例的呢? 在unittest框架中,默认按照ACSII码的顺序加载测试用例并执行,顺序为:09 ...
- 用法:node模块都具备的方法(exports、module、require、__filename、__dirname)
凡是玩弄nodejs的人,都明白,每一个模块都有exports.module.require.__filename.__dirname的方法 清楚了解方法的用法后,玩转node就等于清楚了日常讲话的内 ...
- 深入理解PHP之require/include顺序
深入理解PHP之require/include顺序 作者: Laruence( ) 本文地址: http://www.laruence.com/2010/05/04/1450.html 转载请注明 ...
- day16模块,导入模板完成的三件事,起别名,模块的分类,模块的加载顺序,环境变量,from...import语法导入,from...import *,链式导入,循环导入
复习 ''' 1.生成器中的send方法 -- 给当前停止的yield发生信息 -- 内部调用__next__()取到下一个yield的返回值 2.递归:函数的(直接,间接)自调用 -- 回溯 与 递 ...
- 【Node.js】Event Loop执行顺序详解
本文基于node 0.10.22版本 关于EventLoop是什么,请看阮老师写的什么是EventLoop 本文讲述的是EventLoop中的执行顺序(着重讲setImmediate, setTime ...
随机推荐
- 日常记录-Pandas Cookbook
Cookbook 1.更新内容 2.关于安装 3.Pandas使用注意事项 4.包环境 5.10分钟Pandas初识 6.教程 7.Cookbook 8.数据结构简介 9.基本功能 10.使用文本数据 ...
- [tyvj 1071] LCIS
题目描述 熊大妈的奶牛在小沐沐的熏陶下开始研究信息题目.小沐沐先让奶牛研究了最长上升子序列,再让他们研究了最长公共子序列,现在又让他们要研究最长公共上升子序列了. 小沐沐说,对于两个串A,B,如果它们 ...
- 安装oracle服务端之后再安装oracle客户端导致sqlplus命令无法使用??
首先小编自述一下所遇到的问题: 昨天在已经安装 oracle 服务端的 win7 X64 主机上安装 oracle client 之后,发现我的sqlplus命令无法用了??经过百度,都说我服务没有开 ...
- <url-pattern>/</url-pattern> 拦截请求
一.springmvc 前端控制器 <!-- springmvc的前端控制器 --> <servlet> <servlet-name>fw-sso-web</ ...
- appium运行from appium import webdriver 提示most recent call last
这是因为首次启动提示没有APPIUM 模块,CMD 执行 :pip3 install Appium-Python-Client
- MySQL主要命令(2)
创建表 : create table if not exists employee( //格式:变量名 数据类型, id int, name varchar(30), sex varchar(2), ...
- HDU——T1231 最大连续子序列
http://acm.hdu.edu.cn/showproblem.php?pid=1231 Problem Description 给定K个整数的序列{ N1, N2, ..., NK },其任意连 ...
- structs中通过LabelValueBean构建下拉列表
Action类中增加列表 List<LabelValueBean> list = new ArrayList<LabelValueBean>(); list.add(new L ...
- HDU 3756
很容易就想到把三维转化成了二维,求出点离Z轴的距离,把这个距离当成X坐标,Z轴当Y坐标,然后就变成了求一个直角三角形覆盖这些点 像上一题一样,确定斜率直线的时候,必定是有一点在线上的.于是,可以把直线 ...
- clipper库使用的一些心得
clipper sourceforge官网:http://sourceforge.net/projects/polyclipping/ 1. 版本号差异 之前project里面使用4.8.6,近期升级 ...