java 输入输出IO流 字节流| 字符流 的缓冲流:BufferedInputStream;BufferedOutputStream;BufferedReader(Reader in);BufferedWriter(Writer out)
什么是缓冲流:
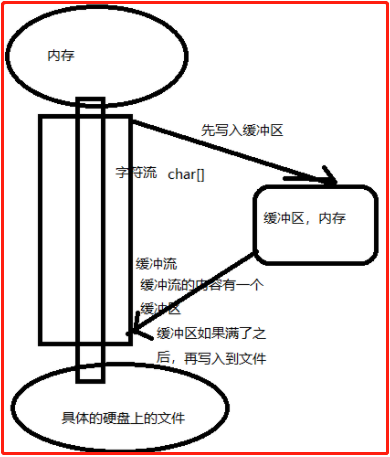
1、字节缓冲流BufferedInputStream;BufferedOutputStream:
- public BufferedInputStream(InputStream in) :创建一个 新的缓冲输入流。
- public BufferedOutputStream(OutputStream out) : 创建一个新的缓冲输出流。
案例对比:
使用缓冲流,拷贝文件每次拷贝1024字节
import java.io.*; /**
* @ClassName FileCopyTryCatchBuffer
* @projectName: object1
* @author: Zhangmingda
* @description: XXX
* date: 2021/4/17.
*/
public class FileCopyTryCatchBuffer {
public static void main(String[] args) {
String srcPath = "C:\\Users\\ZHANGMINGDA\\Pictures\\康熙北巡.jpg";
String dstpath = "C:\\Users\\ZHANGMINGDA\\Pictures\\康熙北巡bak.jpg";
byte[] tmpbytes = new byte[1024];
int copyLength;
long startTime = System.currentTimeMillis();
try(InputStream bfis = new BufferedInputStream(new FileInputStream(srcPath));
OutputStream bfos = new BufferedOutputStream(new FileOutputStream(dstpath))){
while ((copyLength = bfis.read(tmpbytes)) != -1){
bfos.write(tmpbytes,0,copyLength);
}
}catch(FileNotFoundException e){
e.printStackTrace();
}catch (IOException e){
e.printStackTrace();
}
long endTime = System.currentTimeMillis();
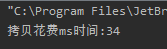
System.out.println("拷贝花费ms时间:" + (endTime - startTime));
}
}
不使用缓冲流,拷贝文件每次拷贝1024字节
import java.io.*; /**
* @ClassName FileCopyBytesExample
* @projectName: object1
* @author: Zhangmingda
* @description: XXX
* date: 2021/4/17.
*/
public class FileCopyBytesExample {
public static void main(String[] args) throws IOException {
long startTime = System.currentTimeMillis();
String srcPath = "C:\\Users\\ZHANGMINGDA\\Pictures\\康熙北巡.jpg";
String dstpath = "C:\\Users\\ZHANGMINGDA\\Pictures\\康熙北巡bak.jpg";
InputStream fis = new FileInputStream(srcPath);
OutputStream fos = new FileOutputStream(dstpath);
byte[] tmpBytes = new byte[1024];
int length ;
while ((length = fis.read(tmpBytes)) != -1) {
fos.write(tmpBytes,0,length);
}
long endTime = System.currentTimeMillis();
fis.close();
fos.close();
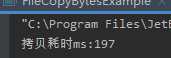
System.out.println("拷贝耗时ms:" + (endTime -startTime));
}
}
2、字符缓冲流BufferedReader(Reader in);BufferedWriter(Writer out) :
- public BufferedReader(Reader in) :创建一个新的缓冲输入流。
- public BufferedWriter(Writer out) : 创建一个新的缓冲输出流。
- BufferedReader: public String readLine() : 读一行文字。读到最后一行返回null。
- BufferedWriter: public void newLine() : 写一行行分隔符,由系统属性定义符号。
练习:打乱的诗词排序
1->独立寒秋,湘江北去,橘子洲头。
2->看万山红遍,层林尽染;
3->漫江碧透,百舸争流。
4->鹰击长空,鱼翔浅底,
5->万类霜天竞自由。
使用treeSet 对诗词语句排序:
import java.io.*;
import java.sql.SQLOutput;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.TreeSet; /**
* @ClassName TextCopyTryCatchExample
* @projectName: object1
* @author: Zhangmingda
* @description: XXX
* date: 2021/4/18.
*/
public class TextCopyTryCatchExample {
public static void main(String[] args){
String srcpath = "输入输出文件读写/src/test/output/沁园春雪-长沙.txt";
String dstpath = "输入输出文件读写/src/test/output/沁园春雪-长沙-sort.txt"; try (BufferedReader bufferedReader = new BufferedReader(new FileReader(srcpath));
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(dstpath))) {
String tmpStringLine ; //存放临时的每行文本
Map<Integer,String> tmpMap = new HashMap<>(); //存放诗词语句和顺序序号的对应
TreeSet<Integer> indexSet = new TreeSet(); //对数字排序
while ((tmpStringLine = bufferedReader.readLine()) != null){
String[] tmpLineArr = tmpStringLine.split("->");
int indexKey = Integer.parseInt(tmpLineArr[0]);
indexSet.add(indexKey); //TreeSet 集合插入元素按数字大小进行自动排序1,2,3...
tmpMap.put(indexKey,tmpLineArr[1]); //Map集合
}
//按顺序遍历,写入到新文件
for(Integer index : indexSet){
System.out.println(index);
bufferedWriter.write(index + "->" + tmpMap.get(index));
bufferedWriter.newLine();
}
}catch (FileNotFoundException e){
e.printStackTrace();
}catch (IOException e ){
e.printStackTrace();
}finally {
}
}
}
import java.io.*;
import java.util.HashMap;
import java.util.Map;
import java.util.Set; /**
* @ClassName TextCopyHashMap
* @projectName: object1
* @author: Zhangmingda
* @description: XXX
* date: 2021/4/18.
*/
public class TextCopyBufferWriterHashMap {
public static void main(String[] args) {
String srcPath = "输入输出文件读写/src/test/output/沁园春雪-长沙.txt";
String dstPath = "输入输出文件读写/src/test/output/沁园春雪-长沙-HashMapSort.txt";
try(BufferedReader bufferedReader = new BufferedReader(new FileReader(srcPath));
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(dstPath))) {
String tmpLine ;
Map<Integer,String> textMap = new HashMap<>();
while ((tmpLine = bufferedReader.readLine()) != null){
String[] tmpLineArr = tmpLine.split("->");
Integer lineIndex = Integer.parseInt(tmpLineArr[0]);
textMap.put(lineIndex,tmpLineArr[1]);
}
System.out.println(textMap); //{1=独立寒秋,湘江北去,橘子洲头。, 2=看万山红遍,层林尽染;, 3=漫江碧透,百舸争流。, 4=鹰击长空,鱼翔浅底,, 5=万类霜天竞自由。}
for(Integer index : textMap.keySet()){
bufferedWriter.write(textMap.get(index));
bufferedWriter.newLine();
}
/**
* 独立寒秋,湘江北去,橘子洲头。
* 看万山红遍,层林尽染;
* 漫江碧透,百舸争流。
* 鹰击长空,鱼翔浅底,
* 万类霜天竞自由。
*/
//复习Map.entrySet() 取值
Set entrySet = textMap.entrySet();
for(Object o : entrySet){
Map.Entry<Integer,String> a = (Map.Entry<Integer,String>)o;
System.out.println(a.getKey() + a.getValue());
/**
* 1独立寒秋,湘江北去,橘子洲头。
* 2看万山红遍,层林尽染;
* 3漫江碧透,百舸争流。
* 4鹰击长空,鱼翔浅底,
* 5万类霜天竞自由。
*/
}
}catch (FileNotFoundException e){
e.printStackTrace();
}catch (IOException e){
e.printStackTrace();
}
}
}
java 输入输出IO流 字节流| 字符流 的缓冲流:BufferedInputStream;BufferedOutputStream;BufferedReader(Reader in);BufferedWriter(Writer out)的更多相关文章
- Java IO流学习总结四:缓冲流-BufferedReader、BufferedWriter
在上一篇文章中Java IO流学习总结三:缓冲流-BufferedInputStream.BufferedOutputStream介绍了缓冲流中的字节流,而这一篇着重介绍缓冲流中字符流Buffered ...
- Java IO学习笔记(二)缓冲流
处理流:包在别的流上的流,可以对被包的流进行处理或者提供被包的流不具备的方法. 一.缓冲流:套接在相应的节点流之上,带有缓冲区,对读写的数据提供了缓冲的功能,提高读写效率,同时增加一些新的方法.可以减 ...
- Java IO流学习总结三:缓冲流-BufferedInputStream、BufferedOutputStream
Java IO流学习总结三:缓冲流-BufferedInputStream.BufferedOutputStream 转载请标明出处:http://blog.csdn.net/zhaoyanjun6/ ...
- Java第三阶段学习(四、缓冲流)
一.缓冲流: Java中提供了一套缓冲流,它的存在,可提高IO流的读写速度 缓冲流,根据流的分类分为:字节缓冲流与字符缓冲流. 二.字节缓冲流: 字节缓冲流根据流的方向,共有2个: 1.写入数据到流中 ...
- java 输入输出IO 转换流-字符编码
编码和其产生的问题: 计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字.英文.标点符号.汉字等字符是二进制数转换之后的结果. 按照某种规则,将字符存储到计算机中,称为编码 .反之,将存 ...
- java 输入输出IO流 字符流 FileWriter FileReader
为什么要使用字符流 当使用字节流读取文本文件时,可能会有一个小问题.就是遇到中文字符时,可能不会显示完整的字符,那是因为一个中文字符可能占用多个字节存储.所以Java提供一些字符流类,以字符为单位读写 ...
- Java之IO流(字节流,字符流)
IO流和Properties IO流 IO流是指计算机与外部世界或者一个程序与计算机的其余部分的之间的接口.它对于任何计算机系统都非常关键, 因而所有 I/O 的主体实际上是内置在操作系统中的.单独的 ...
- java 输入输出IO流:FileOutputStream FileInputStream
什么是IO: 生活中,你肯定经历过这样的场景.当你编辑一个文本文件,忘记了 ctrl+s ,可能文件就白白编辑了.当你电脑上插入一个U盘,可以把一个视频,拷贝到你的电脑硬盘里.那么数据都是在哪些设备上 ...
- IO 复习字节流字符流拷贝文件
/* 本地文件 URL 文件拷贝 *//*文本文件拷贝 可以通过 字符流,也可以通过字节流*/ /*二进制文件拷贝 只可以通过字节流*//* 希望这个例子能帮助搞懂 字符流与字节流的区别 */ imp ...
随机推荐
- 详解Threejs中的光源对象
光源的分类 AmbientLight(环境光),PointLight(点光源),SpotLight(聚光源) 和 DirectionalLight(平行光)是基础光源 HemisphereLight( ...
- CF1578J Just Kingdom
考虑一个点被填满则他需要从其父亲得到\(q_u = \sum_{v = u\ or\ v \in son_u}m_v\) 那么考虑如何这样操作. 我当时world final做的时候,是从上往下遍历, ...
- Codeforces 809C - Find a car(找性质)
Codeforces 题目传送门 & 洛谷题目传送门 首先拿到这类题第一步肯定要分析题目给出的矩阵有什么性质.稍微打个表即可发现题目要求的矩形是一个分形.形式化地说,该矩形可以通过以下方式生成 ...
- Codeforces 639E - Bear and Paradox(二分+贪心)
Codeforces 题目传送门 & 洛谷题目传送门 原来 jxd 作业里也有我会做的题 i 了 i 了 首先这种题目的套路就是先考虑对于一个固定的 \(c\),怎样求出得分最高的策略,而类似 ...
- [linux] 大批量删除任务
一不小心投了巨多任务,或者投递的资源不合理时,想批量杀掉这些任务. kill的方法就不说了,我这里用qdel的方法. 用了这么一条命令: qstat |sed '1,2d' |awk -F' ' '{ ...
- 【GS文献】全基因组选择模型研究进展及展望
目录 1. GS概况 2. GS模型 1)直接法 GBLUP 直接法的模型改进 ①单随机效应 ②多随机效应 2)间接法 间接法模型 基于间接法的模型改进 3. GS模型比较 模型比较结论 4.问题及展 ...
- 【.Net】使用委托实现被引用的项目向上级项目的消息传递事件
前言:在实际项目过程中,经常可能遇到被引用的项目要向上传递消息,但是又不能通过方法进行返回等操作,这个时候委托就派上用场了.以下使用委托,来实现被引用的项目向上传递消息的小教程,欢迎各位大佬提供建议. ...
- 日常Java 2021/10/18
Vecter类实现了一个动态数组,不同于ArrayList的是,Vecter是同步访问的, Vecter主要用在事先不知道数组的大小或可以改变大小的数组 Vecter类支持多种构造方法:Vecter( ...
- ubantu打开摄像头失败
摘要-针对ubantu20 sudo apt install v4l-utils v4l2-ctl --list-devices - cv2 install on ubantu20```针对ubant ...
- 石墨文档Websocket百万长连接技术实践
引言 在石墨文档的部分业务中,例如文档分享.评论.幻灯片演示和文档表格跟随等场景,涉及到多客户端数据同步和服务端批量数据推送的需求,一般的 HTTP 协议无法满足服务端主动 Push 数据的场景,因此 ...