DKT模型及其TensorFlow实现(Deep knowledge tracing with Tensorflow)
今年2月15日,谷歌举办了首届TensorFlow Dev Summit,并且发布了TensorFlow 1.0 正式版。 3月18号,上海的谷歌开发者社区(GDG)组织了针对峰会的专场回顾活动。本文是我在活动上分享的一些回顾,主要介绍了在流利说我们是如何使用TensorFlow来构建学生模型并应用在自适应系统里面的。首发于流利说技术团队公众号原文链接
一、应用背景
自适应学习是什么
自适应学习是现在教育科技领域谈得比较多的一个概念,它的核心问题可以用一句话概括,即通过个性化的规划学习路径,提高学生的学习效率。为什么需要自适应学习?在传统的教学过程中,每个学生的学习路径是一致的,由于学生个人基础和学习能力的差异性,这种千人一面的做法对大部分学生来说这种方式其实比较低效。由此我们很自然的可以想到:如果我们能够根据学生的能力,去匹配合适的教学内容,就应该可以提高他们的学习效率。而这正是自适应系统希望达成的目标。
学生模型
那么自适应学习是如何达成这个目标的呢?这包含了两个核心问题,首先是学生的能力的评估,正确的评估学生的能力是后续一切工作的基础,这是学生模型关心的问题。 其次是在评估好学生的能力后,如何推送合适的内容,这是教学模型所关心的问题。本篇文章我们来讲讲如何利用TensorFlow来构建学生模型。
为了选择一个合适的学生模型,首先需要了解学生学习的过程。一个典型的学习过程是一个时间序列,用户在这个时间序列的各个时刻进行了一些学习行为,从而提高了自身的能力。我们可以假设学生的能力是可以通过学生在各个时刻回答问题的对错来反映的。要注意的是,由于学生学习时间的跨度可能很大,不能认为学生的水平保持不变,所以直接使用一些评测的方法(做了学生能力不变的假设)是不合适的。
Deep Knowledge Tracing
为了对学习序列建模,并评估学生各个时刻的能力,我们采用了Deep Knowledge Tracing(DKT)模型,这个模型是由Stanford大学的Piech Chris等人在NIPS 2015发表的,其本质是一个Seq2Seq的RNN模型,我们来看下模型的结构图:

上图是DKT模型按照时间展开的示意图,其输入序列\(x_1, x_2, x_3 ...\)对应了\(t_1, t_2, t_3 ...\)时刻学生答题信息的编码,隐层状态对应了各个时刻学生的知识点掌握情况,模型的输出序列对应了各时刻学生回答题库中的所有习题答对的概率。
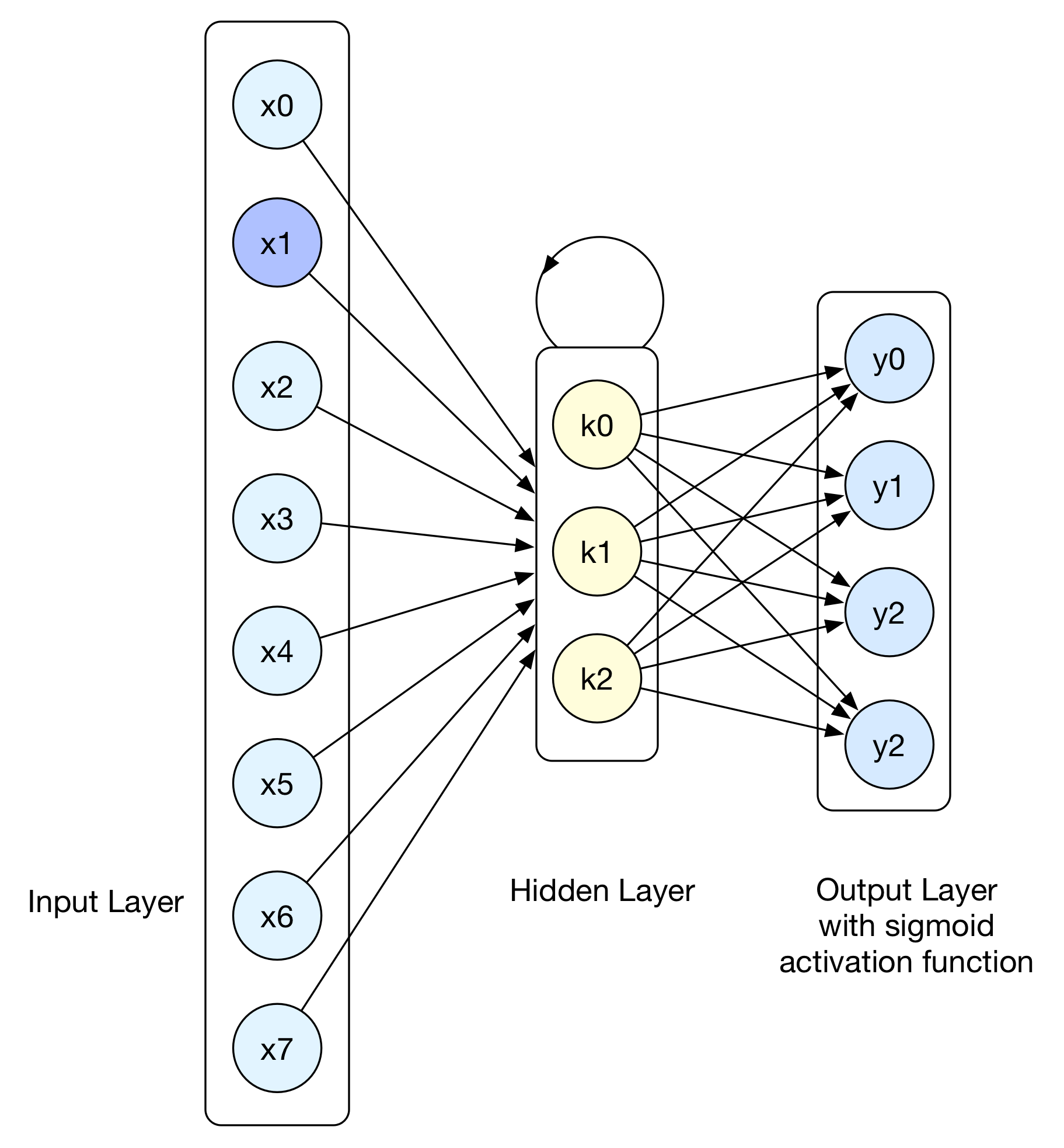
现在以上图为例来看看模型的各层结构。简单起见,假设题库总共有4道习题,那么首先可以确定的输出层的节点数量为4,对应了各题回答正确的概率。接着,如果我们对输出采用one-hot编码,输入层的节点数就是题目数量 * 答题结果 = 4 * 2 = 8个。首先将输入层全连接到RNN的隐层,接着建立隐层到输出层的全连接,最后使用Sigmoid函数作为激活函数,一个基础的DKT模型就构建完毕了。接着为了训练模型,定义如下的损失函数:
\]
其中\(y\)是\(t\)时刻的模型预测输出,\(q_{t+1}\)是\(t+1\)时刻用户回答的题目ID(one-hot向量),\(a_{t+1}\)是\(t+1\)时刻的用户答题的对错, \(\ell\)是binary cross entropy损失函数。下面我们用几十行TensorFlow代码来实现一下这个模型。
二、模型构建
首先初始化模型参数,并且用tf.placeholder来接收模型的输入:
# encoding:utf-8
import tensorflow as tf
class TensorFlowDKT(object):
def __init__(self, config):
self.hidden_neurons = hidden_neurons = config["hidden_neurons"]
self.num_skills = num_skills = config["num_skills"] # 题库的题目数量
self.input_size = input_size = config["input_size"] # 输入层节点数,等于题库数量 * 2
self.batch_size = batch_size = config["batch_size"]
self.keep_prob_value = config["keep_prob"]
# 接收输入
self.input_data = tf.placeholder(tf.float32, [batch_size, None, input_size]) # 答题信息
self.sequence_len = tf.placeholder(tf.int32, [batch_size]) # 一个batch中每个序列的有效长度
self.max_steps = tf.placeholder(tf.int32) # max seq length of current batch.
self.keep_prob = tf.placeholder(tf.float32) # dropout keep prob
# 接收标签信息
self.target_id = tf.placeholder(tf.int32, [batch_size, None]) # 回答的题目ID
self.target_correctness = tf.placeholder(tf.float32, [batch_size, None]) # 答题对错情况
接着构建RNN层:
# create rnn cell
hidden_layers = []
for idx, hidden_size in enumerate(hidden_neurons):
lstm_layer = tf.contrib.rnn.BasicLSTMCell(num_units=hidden_size, state_is_tuple=True)
hidden_layer = tf.contrib.rnn.DropoutWrapper(cell=lstm_layer,output_keep_prob=self.keep_prob)
hidden_layers.append(hidden_layer)
self.hidden_cell = tf.contrib.rnn.MultiRNNCell(cells=hidden_layers, state_is_tuple=True)
# dynamic rnn
state_series, self.current_state = tf.nn.dynamic_rnn(cell=self.hidden_cell, inputs=self.input_data, sequence_length=self.sequence_len,dtype=tf.float32)
这里我们用tf.dynamic_rnn构建了一个多层循环神经网络,cell参数用来指定了隐层神经元的结构,sequence_len参数表示一个batch中各个序列的有效长度。state_series表示隐层的输出,是一个三阶的Tensor,self.current_state表示batch各个序列的最后一个step的隐状态。
输出层:
# output layer
output_w = tf.get_variable("W", [hidden_neurons[-1], num_skills])
output_b = tf.get_variable("b", [num_skills])
self.state_series = tf.reshape(state_series, [batch_size*self.max_steps, hidden_neurons[-1]])
self.logits = tf.matmul(self.state_series, output_w) + output_b
self.mat_logits = tf.reshape(self.logits, [batch_size, self.max_steps, num_skills])
self.pred_all = tf.sigmoid(self.mat_logits) # predict 输出
输出层我们构建了两个变量作为隐层到输出层的连接的参数,并用tf.sigmoid作为激活函数。到这里我们已经可以得到模型的预测输出self.pred_all,这也是一个三阶的张量,shape为(batch_size, self.max_steps, num_skills)。
为了训练模型,还需要计算模型损失函数和梯度,我们结合预测和标签信息来获得损失函数:
# compute loss
flat_logits = tf.reshape(self.logits, [-1])
flat_target_correctness = tf.reshape(self.target_correctness, [-1])
flat_base_target_index = tf.range(batch_size * self.max_steps) * num_skills
flat_bias_target_id = tf.reshape(self.target_id, [-1])
flat_target_id = flat_bias_target_id + flat_base_target_index
flat_target_logits = tf.gather(flat_logits, flat_target_id)
self.pred = tf.sigmoid(tf.reshape(flat_target_logits, [batch_size, self.max_steps]))
self.binary_pred = tf.cast(tf.greater_equal(self.pred, 0.5), tf.int32)
loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=flat_target_correctness, logits=flat_target_logits)
self.loss = tf.reduce_sum(loss)
获得梯度并更新参数:
self.lr = tf.Variable(0.0, trainable=False)
trainable_vars = tf.trainable_variables()
self.grads, _ = tf.clip_by_global_norm(tf.gradients(self.loss, trainable_vars), 4)
optimizer = tf.train.GradientDescentOptimizer(self.lr)
self.train_op = optimizer.apply_gradients(zip(self.grads, trainable_vars))
需要注意的是,在用tf.gradients得到梯度后,我们使用了tf.clip_by_global_norm方法,这主要是为了防止梯度爆炸的现象。最后应用了一次梯度下降得到的self.train_op就是计算图的训练结点。得到训练结点后,我们的计算图(Graph)就已经构造完毕,接着只需要创建一个tf.Session对象,并调用其run()方法来运行计算图就可以进行模型训练和测试了。由于训练和测试的接收的feed_dict类似,我们定义step方法来用作训练和测试,如下:
def step(self, sess, input_x, target_id, target_correctness, sequence_len, is_train):
_, max_steps, _ = input_x.shape
input_feed = {self.input_data: input_x,
self.target_id: target_id,
self.target_correctness: target_correctness,
self.max_steps: max_steps,
self.sequence_len: sequence_len}
if is_train:
input_feed[self.keep_prob] = self.keep_prob_value
train_loss, _, _ = sess.run([self.loss, self.train_op, self.current_state], input_feed)
return train_loss
else:
input_feed[self.keep_prob] = 1
bin_pred, pred, pred_all = sess.run([self.binary_pred, self.pred, self.pred_all], input_feed)
return bin_pred, pred, pred_all
定义assign_lr方法来设置学习率:
def assign_lr(self, session, lr_value):
session.run(tf.assign(self.lr, lr_value))
至此,TensorFlowDKT类就构造完毕了,我们可以这样使用它:
# process data ...
# config and create model
# config = ...
model = TensorFlowDKT(config)
# create session and init all variables
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(num_epoch):
# train
# lr_value = ...
model.assign_lr(sess, lr_value) # assign learning rate
train_generator.shuffle() # random shuffle before each epoch
while not train_generator.end:
input_x, target_id, target_correctness, seqs_len, _ = train_generator.next_batch()
overall_loss += model.step(sess, input_x, target_id, target_correctness, seqs_len, is_train=True)
# test
while not test_generator.end:
input_x, target_id, target_correctness, seqs_len, _ = test_generator.next_batch()
binary_pred, pred, _ = model.step(sess, input_x, target_id, target_correctness, seqs_len, is_train=False)
# calculate metrics ...
Demo的完整代码,见https://github.com/lingochamp/tensorflow-dkt
三、工程实践
流利说的懂你英语课程,到16年12月份为止,已经积累了数亿量级用户答题数据,在处理这些数据优化模型指标的过程中,我们也积累了一些实践经验。
Truncated BPTT
我们收集到的学习数据里,最长的序列长度超过五万。出于计算效率的考虑,包括TensorFlow在内的多数深度框架在进行BPTT的时候都会将序列按照时间维度展开,这在序列长度达到五万的情况下是不现实的(显存会爆)。所以我们需要将长的序列切断分为多个序列,然后保存前一部分序列训练的隐状态作为接下来一部分序列的初始状态输入,这样来进行长序列的训练。
多GPU加速
当数据到达数亿的量级以后,进行一次训练已经需要比较多的时间了,这个时候我们可以通过多GPU并行来加速训练。这里我们使用Multi Tower结构,这是一种数据并行的多GPU方案,我们来看下它的示意图:

可以看到在Multi Tower结构里,每个GPU持有一个模型实例,这些实例之间共享参数的。训练开始后,每次我们将多个batch数据分别喂给各个模型实例,在各GPU设备分别求得梯度信息。 接着,我们将收集到的梯度返回到CPU,取平均以后,用来更新模型的参数。 由于模型的参数是共享的,这也就意味着所有模型实例的参数都得到了更新。接着我们来看下,以TensorFlowDKT类为例,我们如何用Multi Tower结构来构造训练结点:
def multi_gpu_model(num_gpus=1, model_config=None):
tower_grads = []
for i in range(num_gpus):
with tf.device("/gpu:%d" % i):
with tf.name_scope("tower_%d" % i): # 用name_scope区分各模型
model = TensorFlowDKT(model_config) # 为每个GPU构造一个模型实例
tf.add_to_collection("train_model", model) # add_to_collection,方便feed数据
tower_grads.append(model.grads) # 收集梯度信息
tf.add_to_collection("loss", model.loss)
tf.get_variable_scope().reuse_variables() # 重用同一作用域内的变量
with tf.device("cpu:0"):
averaged_gradients = average_gradients(tower_grads) # 对返回的梯度取平均
opt = tf.train.GradientDescentOptimizer(0.5)
train_op = opt.apply_gradients(zip(averaged_gradients, tf.trainable_variables()))
return train_op
其中average_gradients方法的代码可以参考https://github.com/tensorflow/models/blob/master/tutorials/image/cifar10/cifar10_multi_gpu_train.py 。接着我们构造一个方法来返回feed_dict:
def generate_feed_dict(data_generator):
feed_dict = {}
models = tf.get_collection("train_model") # get_collection,取回模型
for model in models:
inputs, target_id, target_correctness, seqs_len, max_len = data_generator.next_batch()
feed_dict[model.input_data] = inputs
feed_dict[model.target_id] = target_id
feed_dict[model.target_correctness] = target_correctness
feed_dict[model.max_steps] = max_len
feed_dict[model.sequence_len] = seqs_len
feed_dict[model.keep_prob] = model.keep_prob_value
return feed_dict
最后由于dynamic_rnn的一些Operation尚不支持GPU,在训练开始前,我们需要配置一下Session避免出错:
sess = tf.Session(config=tf.ConfigProto(allow_soft_placement=True))
完成上面的步骤,我们就可以用多GPU来加速模型训练了。
模型导出
在流利说,学生模型训练是用Python API完成的,而学生模型预测服务则是用C++实现的。关于如何从C++如何从Protobuf文件中加载Graph可以参考https://www.tensorflow.org/tutorials/image_recognition。这里有一个模型导出的问题,即Python 中的tf.train.write_graph方法只能够保存模型的图结构,而不能保存变量的值到Protobuf文件中。这个问题可以通过将Variables转换为tf.constant来解决, tensorflow.python.tools.freeze_graph提供了这样的方法。
结语
TensorFlow是一个十分简单易用的机器学习框架,也是目前最流行的深度学习框架,它可以让机器学习研究者更少的关注底层的问题,而专注于问题的解决和算法的优化上。流利说算法团队从16年初开始就将TensorFlow应用到内部的机器学习项目里面,积累了很多相关的使用经验,从而帮助我们的用更智能算法来服务用户。
References
- Piech, Chris, et al. "Deep knowledge tracing." Advances in Neural Information Processing Systems. 2015.
- https://www.tensorflow.org/
- https://github.com/tensorflow/tensorflow
DKT模型及其TensorFlow实现(Deep knowledge tracing with Tensorflow)的更多相关文章
- Deep Knowledge Tracing (深度知识追踪)
论文:Deep Knowledge Tracing Addressing Two Problems in Deep Knowledge Tracing via Prediction-Consis ...
- Knowledge Tracing -- 基于贝叶斯的学生知识点追踪(BKT)
目前,教育领域通过引入人工智能的技术,使得在线的教学系统成为了智能教学系统(ITS),ITS不同与以往的MOOC形式的课程.ITS能够个性化的为学生制定有效的 学习路径,通过根据学生的答题情况追踪学生 ...
- TensorFlow和深度学习-无需博士学位(TensorFlow and deep learning without a PhD)
1. 概述 原文地址: TensorFlow and deep learning,without a PhD Learn TensorFlow and deep learning, without a ...
- TensorFlow和深度学习入门教程(TensorFlow and deep learning without a PhD)【转】
本文转载自:https://blog.csdn.net/xummgg/article/details/69214366 前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络,并把 ...
- TensorFlow和深度学习新手教程(TensorFlow and deep learning without a PhD)
前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络.并把其PPT的參考学习资料给了我们, 这是codelabs上的教程:<TensorFlow and deep lear ...
- 模型压缩一半,精度几乎无损,TensorFlow推出半精度浮点量化工具包,还有在线Demo...
近日,TensorFlow模型优化工具包又添一员大将,训练后的半精度浮点量化(float16 quantization)工具. 有了它,就能在几乎不损失模型精度的情况下,将模型压缩至一半大小,还能改善 ...
- tensorflow分类-【老鱼学tensorflow】
前面我们学习过回归问题,比如对于房价的预测,因为其预测值是个连续的值,因此属于回归问题. 但还有一类问题属于分类的问题,比如我们根据一张图片来辨别它是一只猫还是一只狗.某篇文章的内容是属于体育新闻还是 ...
- Tensorflow 学习笔记(一)TensorFlow入门
一.计算模型----计算图 1.1 计算图的概念:TensorFlow就是通过图的形式绘制出张量节点的计算过程,例如下图执行了一个a+b的操作. 1.2 计算图的使用 TensorFlow程序一般分为 ...
- 第九章——运行tensorflow(Up and Running with TensorFlow)
本章简单介绍了TensorFlow的安装以及使用.一些细节需要在后续的应用中慢慢把握. TensorFlow并不仅仅局限于神经网络和机器学习,它甚至可以用于量子物理仿真. TensorFlow的优势: ...
随机推荐
- html中引入外部js文件,使用外部js文件里的方法
外部js文件1: /** * 加了window.onload 后,直接引入js文件即可 * 页面资源全部加载完毕后会自动调用window.onload里的回调函数 */ window.addEvent ...
- [NOIP2011 提高组] 观光公交
考虑这类每次都有一类物品贡献相同的物品,求使用了 \(k\) 个物品的最优值,则有考虑考虑贪心. 每次找到一个车到的时间\(>\)最后一个人到的时间,那么找一个覆盖个数最大的地方使用它.
- 洛谷 P4755 - Beautiful Pair(主席树+分治+启发式优化)
题面传送门 wssb,我紫菜 看到这类与最大值统计有关的问题可以很自然地想到分治,考虑对 \([l,r]\) 进行分治,求出对于所有 \(l\le x\le y\le r\) 的点对 \((x,y)\ ...
- python-django 使用class重写视图和模板变量
基于类的视图 c Django模板语法 两个模板引擎如何进行模板文件的查找 模板引擎都找不到的时候,就照模块里面的模板 一旦找到模板不会继续查找了 注意:img_addr是必须和视图里面的变量名字保持 ...
- 添加页面、页面交互、动态添加页面tab
<%@ Control Language="C#" AutoEventWireup="true" CodeFile="ViewDictTosPr ...
- 5 — springboot中的yml多环境配置
1.改文件后缀 2.一张截图搞定多环境编写和切换
- 乱序拼图验证的识别并还原-puzzle-captcha
一.前言 乱序拼图验证是一种较少见的验证码防御,市面上更多的是拖动滑块,被完美攻克的有不少,都在行为轨迹上下足了功夫,本文不讨论轨迹模拟范畴,就只针对拼图还原进行研究. 找一个市面比较普及的顶像乱序拼 ...
- html框架frame iframe
框架 通过使用框架,你可以在同一个浏览器窗口中显示不止一个页面.没分HTML文档称作一个框架. 缺点: 开发人员必须同时跟踪更多的HTML文档 很难打印整张页面 框架结构标签(<frameset ...
- 【编程思想】【设计模式】【结构模式Structural】门面模式/外观模式Facade
Python版 https://github.com/faif/python-patterns/blob/master/structural/facade.py #!/usr/bin/env pyth ...
- 【Linux】【Commands】文本查看类
分屏查看命令:more和less more命令: more FILE 特点:翻屏至文件尾部后自动退出: less命令: less FILE head命令: 查看文件的前n行: head [option ...