U2-关系数据库
2.1 关系数据结构及形式化定义
- 关系数据库系统是支持关系模型的数据库系统。(关系模型由关系数据结构、关系操作集合和关系完整性约束三部分组成)
2.1.1 关系
1-域
- 域是一组具有相同数据类型的值的集合。
eg.{0, 1}; {man, woman}
2-笛卡尔积
- 笛卡尔积是域上的一种集合运算
eg.给定一组域D1,D2,D3,,,,则其笛卡尔积为:D1*D2*D3...={(d1,d2,d3,....) | di∈Di}
- 没一个元素(d1,d2,d3...,dn)叫做一个n元组(简称元组),元组的每一个值di叫做一个分量。
- 一个域允许的不同取值个数称为这个域的基数。
3-关系
D1*D2*D3...*Dn的子集叫做域在D1,D2,...,Dn上的关系,表示为:R(D1,D2,...,Dn)
R表示关系的名字,n表示关系的目或度
若关系中的某一属性组能唯一标识一个元组,而其子集不可以,则称该属性组为候选码。
候选码中的属性称为主属性,不包含在任何候选码中的属性称为非主属性或非码属性。
若一个关系有多个候选码,则选定其中一个为主码(primary key)
关系可以有三种类型:基本关系(基本表或基表),查询表和试图表。
- 基本表:实际存在的表,实际存储数据的逻辑表示
- 查询表:查询结果对应的表
- 试图表:由基本表或其他试图表导出的表,虚表,不对应实际存储数据。
基本关系的六条性质:
- 列是同质的:每个列中的分量是同一类型的数据,来自同一个域。
- 不同的列可出自同一个域,此时每一个列为一个属性
- 列的顺序无所谓:列的次序可以任意调换
- 任意两个元组的候选码不能取相同的值
- 行的顺序无所谓
- 分量必须取原子值,每一个分量都必须是不可分的数据项。
2.1.2 关系模式
关系模式是型,关系是值。关系模式是对关系的描述。
关系的描述称为关系模式,表示为:R(U,D,DOM,F)
- R:关系名
- U:组成该关系的属性名集合
- D:U中属性所来自的域
- DOM: 属性向域的影响集合
- F:属性间数据的依赖关系集合
关系是关系模式在某一时刻的状态和内容。关系模式是静态稳定的,关系是动态随时间变化的(关系操作不断更新着数据库中数据)。
2.1.3 关系数据库
- 关系数据库的型也成为关系数据库模式,是对关系数据库的描述
- 关系数据库的值是这些关系模式在某一时刻对应的关系的集合 - 关系数据库。
2.2 关系操作
2.2.1 基本关系操作
- 查询:集合操作方式,即操作的对象和结果都是集合
- 查询的五种基本操作:选择、投影、并、差、笛卡尔积
- 插入
- 删除
2.2.2 关系数据语言的分类
- 关系代数语言(ISBL)
- 关系演算语言
- 元组关系演算语言(ALPHA,QUEL)
- 域关系盐酸语言(QBE)
- 关系代数和关系演算双重特性:SQL
- SQL是一种结构查询语言,集查询、数据定义、数据操纵和数据控制于译题的关系数据语言。(高度非过成化)
- 修改
2.3 关系完整性
- 关系模型由三类完整性约束:实体完整性、参照完整性(关系的两个不变性)和用户定义的完整性。
2.3.1 实体完整性
- 实体完整性规则:若属性A是基本关系R的主属性,则A不能取空置(null)
2.3.2 参照完整性
若F为基本关系R的一个或一组属性但不是R的码,Ks是基本关系S的主码。若F与Ks相对应,则F是R的外码,R为参照关系,S是被参照关系或目标关系。(RS可为同一关系)
- 参照完整性规则:若属性F是基本关系R的外码,它与基本关系S的主码Ks相对应,则对于R中每个元组在F上的值必须:
- 取空值(F中每个属性值均为空值):尚未给F分配Ks
- 等于S中某个元组的主码值:被参照关系中的一个具体值
2.3.3 用户定义完整性
用户定义完整性即为针对某一具体关系数据库的约束条件,其反映某一具体应用所涉及的数据必须满足的语义要求。
2.4 关系代数
关系代数是一种抽象的查询语言,用对关系的运算来表达查询。
- 关系代数表达式:关系代数中运算经有限次复合后形成的表达式。
2.4.1 传统集合运算(二目运算)
- 并:R∪S={t|t∈R V t∈S}
- 差:R-S={t|t∈R ⋀ t ∉ S}
- 交:R∩S={t|t∈R ⋀ t∈S}
- 笛卡尔积:R*S={tr⌒ts|tr∈R⋀ts∈S}
2.4.2 专门的关系运算
1-符号引入
- 设关系模式为R(A1,A2...An),其一关系设为R,t∈R标识t是R的一个元组。t[Ai]表示元组t中相应于属性Ai的一个分量
- 若R为n目关系,S为m目关系。tr∈R,ts∈S,tr⌒ts称为元组的链接或元组的串接,其是一个n+m列的元组
- 若A={Ai1,Ai2,Ai3,...,Aik},Ain为Ai中的一部分,则A称为属性列或属性组。t[A]=(t[Ai1],t[Ai2],t[Ai3]...)表示元组t在属性列A上诸分量的集合,A平均表示{A1,A2,...}去除{Ai1,Ai2,...}后剩余的属性组。
- 给定关系R(X,Z),XZ为属性组。当t[X]=x时,x在R中的象集定义为:Zx={t[Z]|t∈R,t[X]=x},表示R中属性组X上值x的诸元组在Z上分量的集合。
2-关系运算定义
- 选择(限制)
- 投影:关系R上的投影是从R中选择若干属性列组成新得关系
- 连接(join):两个关系的笛卡尔积中选取属性间满足一定条件的元组
- 除运算:设关系R除关系S结果为关系T,则T包含所有在R但不在S中的属性和值,且T的元组与S的元组的所有组合都在R中。
3-符号整理
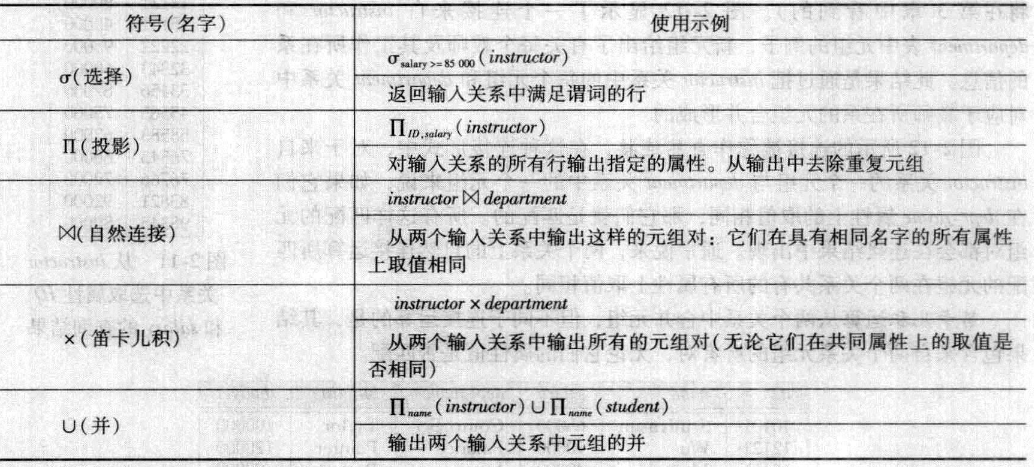
U2-关系数据库的更多相关文章
- 关系数据库SQL之可编程性触发器
前言 前面关系数据库SQL之可编程性函数(用户自定义函数)一文提到关系型数据库提供了可编程性的函数.存储过程.事务.触发器及游标,前文已介绍了函数.存储过程.事务,本文来介绍一下触发器的使用.(还是以 ...
- 前端开发必学技能之一———非关系数据库又像关系数据库的MongoDB快速入门第一步下载与安装
数据库总的来说,分为两个方向:关系数据库和非关系数据库.我们常见的MySQL.Oracle.SQLSerever以及IBMDB2都是属于关系数据库,这里的关系值得是二维表的结构,但是由于随着web的应 ...
- 关系数据库SQL之可编程性事务
前言 前面关系数据库SQL之可编程性函数(用户自定义函数)一文提到关系型数据库提供了可编程性的函数.存储过程.事务.触发器及游标,前文已介绍了函数.存储过程,本文来介绍一下事务的使用.(还是以前面的银 ...
- 关系数据库SQL之可编程性存储过程
前言 前面关系数据库SQL之可编程性函数(用户自定义函数)一文提到关系型数据库提供了可编程性的函数.存储过程.事务.触发器及游标,前文已介绍了函数,本文来介绍一下存储过程的创建.执行.删除.(还是以前 ...
- 关系数据库SQL之高级数据查询:去重复、组合查询、连接查询、虚拟表
前言 接上一篇关系数据库SQL之基本数据查询:子查询.分组查询.模糊查询,主要是关系型数据库基本数据查询.包括子查询.分组查询.聚合函数查询.模糊查询,本文是介绍一下关系型数据库几种高级数据查询SQL ...
- 关系数据库SQL之基本数据查询:子查询、分组查询、模糊查询
前言 上一篇关系数据库常用SQL语句语法大全主要是关系型数据库大体结构,本文细说一下关系型数据库查询的SQL语法. 语法回顾 SELECT [ALL|DISTINCT] <目标列表达式>[ ...
- MongoDB是一个介于关系数据库和非关系数据库之间的产品
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的.他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型.M ...
- NoSQL数据库探讨之一 - 为什么要用非关系数据库?
随着互联网web2.0网站的兴起,非关系型的数据库现在成了一个极其热门的新领域,非关系数据库产品的发展非常迅速.而传统的关系数据库在应付 web2.0网站,特别是超大规模和高并发的SNS类型的web2 ...
- InfluxDb系列:几个关键概念(主要是和关系数据库做对比)
https://docs.influxdata.com/influxdb/v0.9/concepts/key_concepts/ #,measurement,就相当于关系数据库中的table,他就是 ...
- Sqoop -- 用于Hadoop与关系数据库间数据导入导出工作的工具
Sqoop是一款开源的工具,主要用于在Hadoop相关存储(HDFS.Hive.HBase)与传统关系数据库(MySql.Oracle等)间进行数据传递工作.Sqoop最早是作为Hadoop的一个第三 ...
随机推荐
- 算法入门 - 基于动态数组的栈和队列(Java版本)
之前我们学习了动态数组的实现,接下来我们用它来实现两种数据结构--栈和队列.首先,我们先来看一下栈. 什么是栈? 栈是计算机的一种数据结构,它可以临时存储数据.那么它跟数组有何区别呢? 我们知道,在数 ...
- C#协作试取消线程
https://segmentfault.com/q/1010000017109927using System; using System.Collections.Generic; using Sys ...
- springmvc学习日志四
一.回顾 1.文件上传 1.1引入fileupload的jar包 1.2在springmvc的配置文件中引入CommonsMutilpartResolver文件上传解析器 1.3在控制层在写入代码 2 ...
- mac下编译安装grafana
下载grafana源码 从grafana git 仓库下载指定的分支. 编译后端 我下载的时候,grafana的最新release是7.3.7,其需要安装go 1.15版本 生成可执行文件 进入项目根 ...
- rabbitMq可靠消息投递之交换机备份
//备份队列 @Bean("alternate_queue") public Queue alternate_queue() { return new Queue("al ...
- Mysql force index和ignore index 使用实例
前几天统计一个sql,是一个人提交了多少工单,顺便做了相关sql优化.数据大概2000多w. select CustName,count(1) c from WorkOrder where Creat ...
- MySQL(四)——
MySQL官方对索引的定义:索引(Index)是帮助MySQL高效获取数据的数据结构.因此索引的本质就是数据结构.索引的目的在于提高查询效率,可类比字典.书籍的目录等这种形式. 可简单理解为" ...
- 模拟9:T1:斐波那契
Description: 题目描述: 小 C 养了一些很可爱的兔子. 有一天,小 C 突然发现兔子们都是严格按照伟大的数学家斐波那契提出的模型来进行繁衍:一对兔子从出生后第二个月起,每个月刚开 ...
- epoll代码框架
epoll代码实现框架: #define MAX_EVENTS 10 struct epoll_event ev, events[MAX_EVENTS]; int listen_sock, conn_ ...
- linux常用查询命令
1 **系统** 2 # uname -a # 查看内核/操作系统/CPU信息 3 # head -n 1 /etc/issue # 查看操作系统版本 4 # cat /proc/cpuinfo # ...