Python中的BeautifulSoup模块
目录
BeautifulSoup
BeautifulSoup 是Python的一个库,最主要的功能就是从网页爬取我们需要的数据。BeautifulSoup将 html 解析为对象进行处理,全部页面转变为字典或者数组,相对于正则表达式的方式,可以大大简化处理过程。
from bs4 import BeautifulSoupBeautifulSoup将htmll对象转成对象的过程
response=requests.get("https://www.baidu.com") ##获得网页的回应
html=response.text ##获得网页的源代码
soup=BeautifulSoup(html,"html.parser") ##将网页转化成BeautifSoup对象Beautiful Soup将复杂的HTML文档转换成一个复杂的树形结构,每个节点都是python对象,所有对象可以归纳为4种
- Tag
- NavigableString
- BeautifulSoup
- Comment
Tag
Tag 是什么?通俗点讲就是 HTML 中的一个个标签,例如
<html>
<head>
<title>谢公子的小黑屋</title>
</head>
<body>
<h2>这是标题</h2>
<p class="xie" name="p标签">你好,世界</p>
<img src="1.jpg">
<form action='action.php' method="get">
用户名:<input type="text" name="username" /> <br/>
密码: <input type="password" name="passwd" /> <br/>
<input type="submit" value="登录" />
</form>
</body>
</html>上面的 title 、p 等等 HTML 标签加上里面的内容就是 Tag,下面我们来感受一下怎样用 Beautiful Soup 来方便地获取 Tags
print( soup.title ) ##打印出网页的title标签
print( soup.p) ##打印出网页的p标签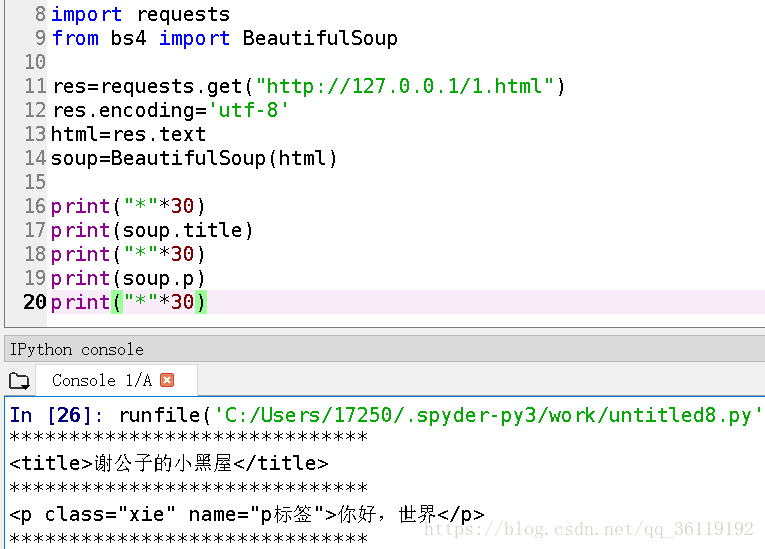
我们可以利用soup加标签名轻松地获取这些标签的内容,但是它查找的是在所有内容中的第一个符号要求的标签
对于 Tag,它有两个重要的属性,是 name 和 attrs
soup.p.name ##p标签的名字
soup.p.string ##p标签的内容
soup.p.attrs ##p标签的属性,返回的是一个字典
soup.p['class'] ##p标签的class属性
soup.p.get('class') ##p标签的class属性,和上面的等价
soup.p['class']="newClass" ##修改p标签的class属性
del soup.p['class'] ##删除p标签的class属性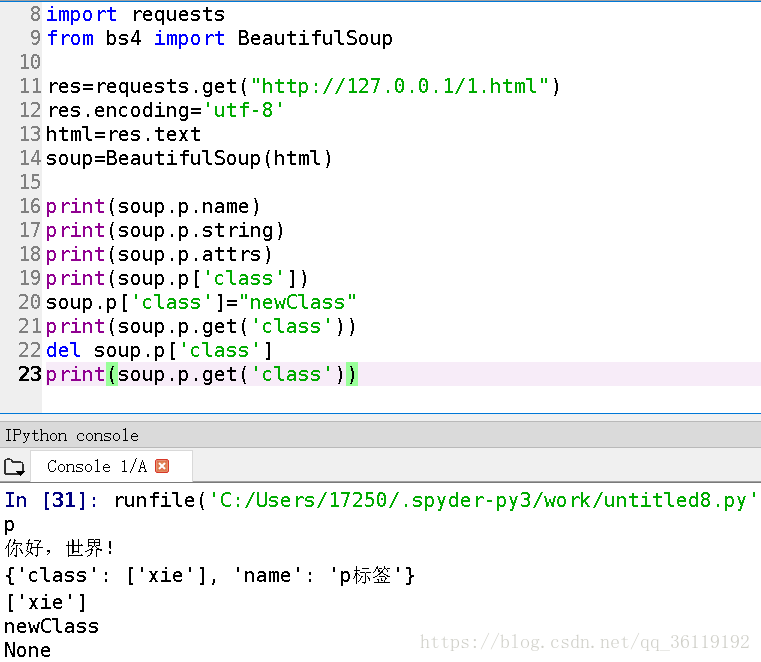
NavigableString
既然我们已经得到了标签的内容,那么如果我们想要获取标签内部的文字怎么办呢?很简单,用 .string 即可
print(soup.p)
print(soup.p.string) ##打印出p标签的内容
## <p class="xie" name="p标签">你好,世界!</p>
## 你好,世界!BeautifulSoup
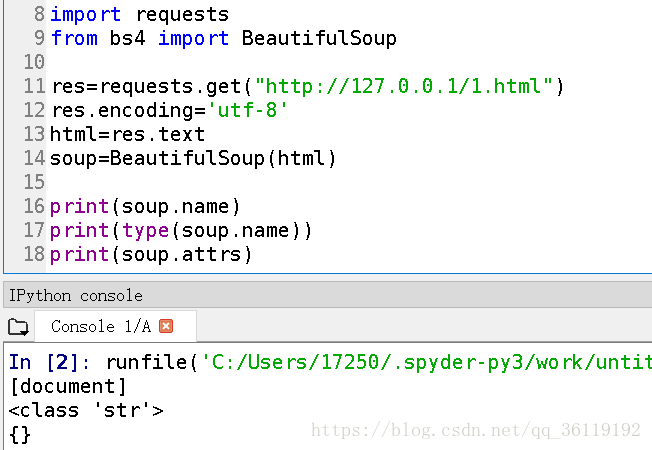
BeautifulSoup对象表示的是一个文档的全部内容。大部分时候,可以把它当做一个Tag对象,是一个特殊的Tag,我们可以分别获取它的类型,名称,以及属性
Comment
Comment对象是一个特殊类型的NavigableString对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦
现在有这么一个网页
<html>
<body>
<p class="xie" name="p标签"><!--你好,世界!--></p>
</body>
</html>
p标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容,我们发现它已经把注释给去掉了,所以这可能会带给我们不必要的麻烦。如果标签中有注释,则是 comment 对象,没有注释则不是 comment对象所以我们在使用前判断是不是属于 comment类型 。

if type(soup.p.string) != bs4.element.Comment:
print (soup.p.string)遍历文档树
直接子节点
.contents 返回的是一个list列表,可以通过索引方式获取
.children 返回的是一个list生成器,我们需要遍历获取所有子孙节点
print(soup.body.contents) ##打印出body标签内的所有标签,返回的是一个列表,包含\n
print(soup.body.contents[0]) ##我们可以通过索引的方式获取
print(soup.body.children) ##返回的是list生成器,需要遍历获取值
for child in soup.body.children:
print(child)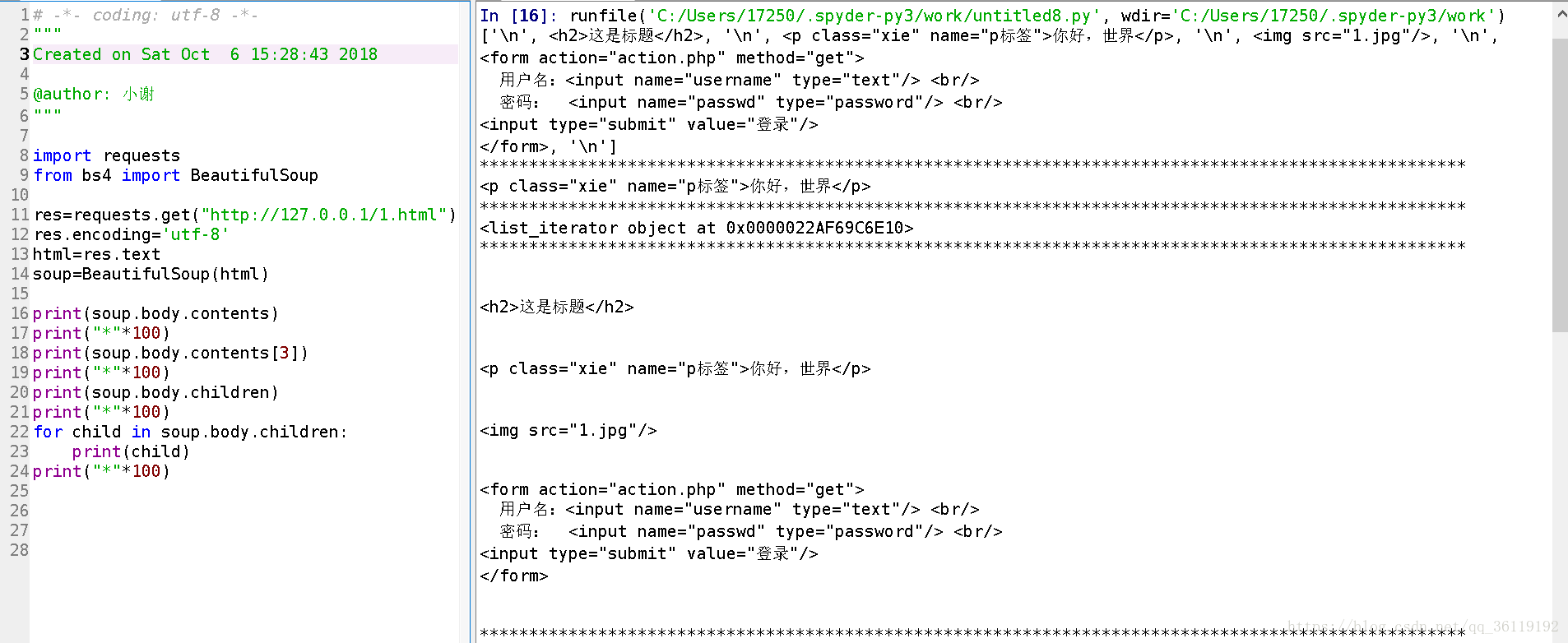
所有子孙节点
.contents和.children属性仅包含tag的直接子节点,.descendants属性可以对所有tag的子孙节点进行递归循环,和children类似
for child in soup.body.descendants: ##遍历所有子孙节点标签
print( child )
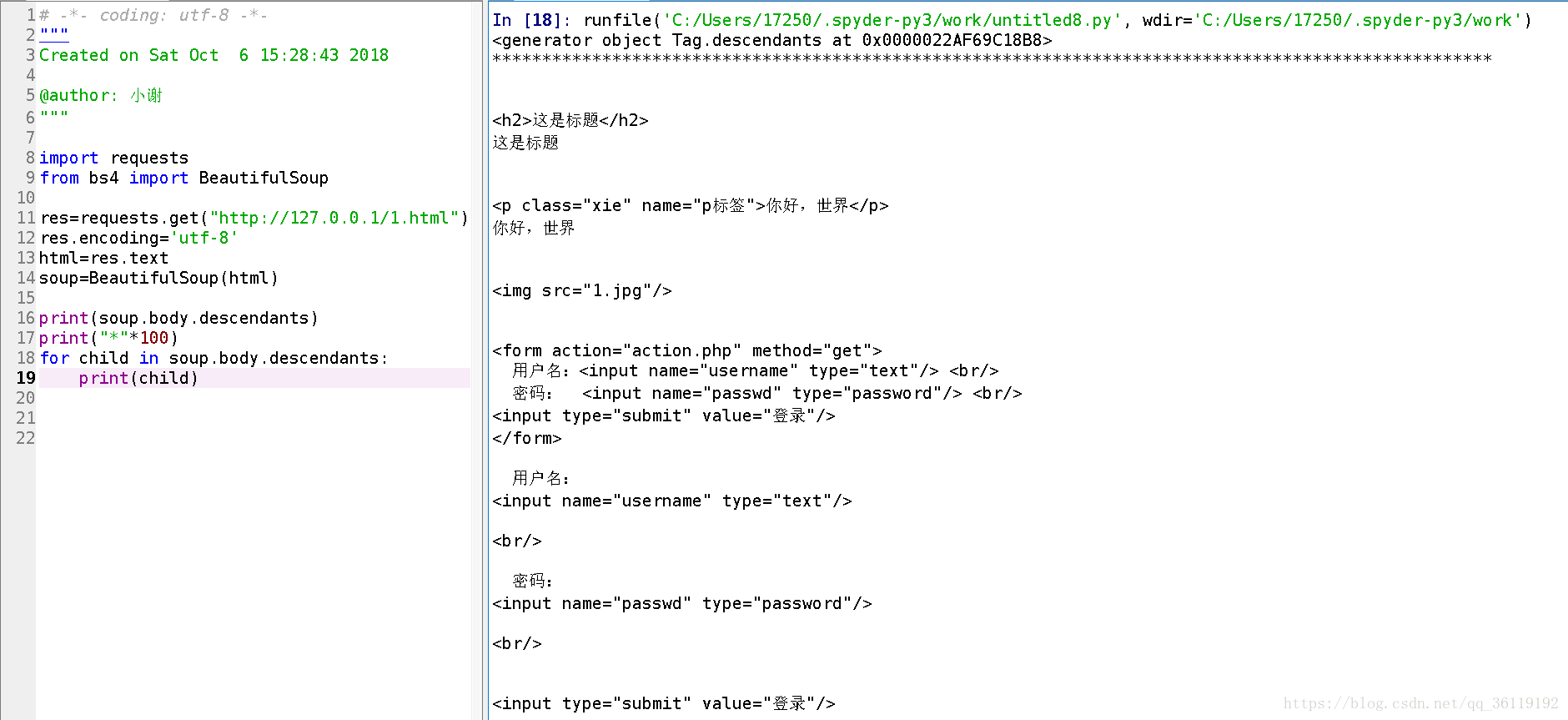
节点内容
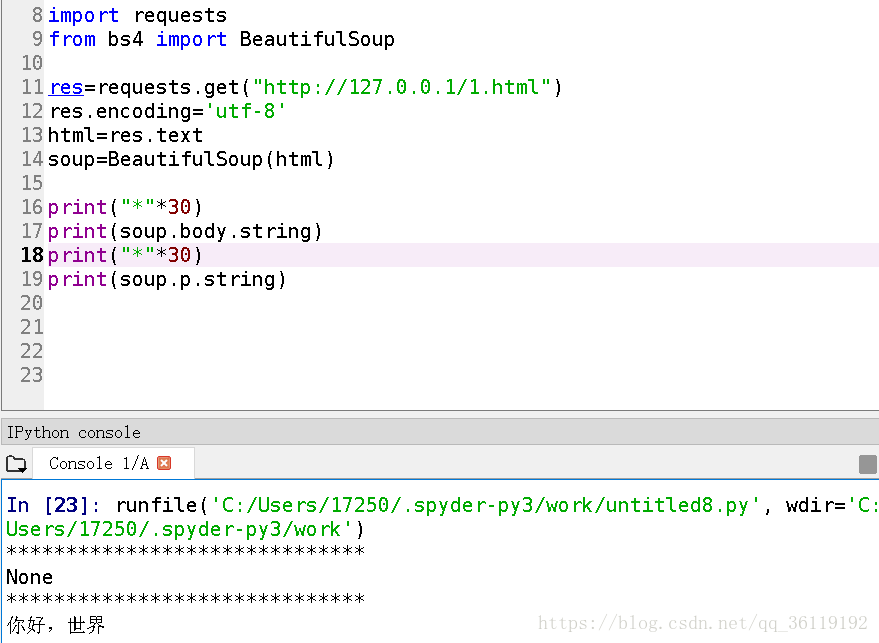
如果一个标签里面没有标签了,那么.string就会返回标签里面的内容。如果标签里面还有其他的标签,则会返回 None
搜索标签
find_all( name , attrs ,recursive , text , **kwargs) 搜素当前页面符合过滤器条件的第一个标签
find_all( name , attrs ,recursive , text , **kwargs) 搜素当前页面符合过滤器条件的所有标签
name参数,查找所有名字为name的 tag,字符串对象会被自动忽略掉
(A) 传字符串
最简单的过滤器是字符串,在搜索方法中传入一个字符串参数,find_all方法会查找所有与字符串完整匹配的内容
print(soup.find_all('a')) ##查找所有的a标签,返回的是一个list列表
print(soup.find_all('a',class_='xie')) ##查找class='xie'的a标签(B)传正则表达式
如果传入正则表达式作为参数,find_all方法会通过正则表达式的match()来匹配内容
for tag in soup.find_all(re.compile("^b")): ##找出所有以b开头的标签
print(tag.name)(c)传列表
如果传入列表参数,find_all将会与列表中任一元素匹配的内容返回。
print(soup.find_all(['a', 'table'])) ##找出所有的a标签和table标签(D)传True
True可以匹配任何值
for tag in soup.find_all(True):
print(tag.name)(E)传方法
如果没有合适过滤器,那么还可以定义一个方法,方法只接收一个元素。如果这个方法返回true,表示当前元素匹配并且被找到,如果不是,则返回false
def has_class_but_no_id(tag): ##定义一个方法,如果tag中包含class属性却不包含id属性,那么返回true
return tag.has_attr('class') and not tag.has_attr('id')
print( soup.find_all(has_class_but_no_id(tag)) )attrs的keyword参数
注意:如果一个指定的参数不是搜素内置的函数名,搜索时会把该参数当做指定名字tag的属性来搜素,如果包含一个名字为id的参数,find_all会搜素每个tag的id属性
print(soup.find_all( id='link' )) ##打印出所有id=link的标签
print(soup.find_all(href=re.compile("elsie"),id='link')) ##打印出href中含有elsie,并且id=link的标签
print(soup.find_all( class_='xie')) ##class是python的关键字,所以加下划线 打印出class为xie的标签text参数
通过text参数可以搜素文档中的字符串内容,与name参数的可选值一样,text参数接受字符串、列表、正则表达式和True
print(soup.find_all(text="name")) ##打印出网页中的name,返回一个列表,没有则返回空
print(soup.find_all(text=re.compile("name"))) ##打印出网页中含有name的词,返回一个列表limit参数
find_all()方法返回全部的搜素结构,如果文档树很大那么搜素会很慢,如果我们不需要全部结果,可以使用limit参数限制返回结果的数量
print(soup.find_all('a',limit=3)) ##找出3个a标签recursive参数
调用tag的find_all()方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜素tag的直接子节点,可以使用参数recursive=False
print(soup.find_all('head',recursive=False))find(name,attrs,recursive,text,**kwargs)
它与find_all()方法唯一的区别是find_all()方法返回结果是只包含第一个元素的列表,而find()方法直接返回结果
CSS选择器
我们在写CSS时,标签名不加任何修饰,类名前加点,id名前加#,在这里我们也可以利用类似的方法来筛选元素,用到的方法是soup.select() , 返回类型是list
通过标签名查找
print(soup.select('title')) ##打印出标签是title的通过类名查找
print(soup.select('.b')) ##打印出类名是b的通过id名查找
print(soup.select('#sister')) ##打印出id名是sister的组合查找
print(soup.select('p #link .xie')) ##打印出p标签中,id=link,class=xie的属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则匹配不到
print(soup.select("a[class='sister']")) ##打印出a标签中class属性是sister的以上的select方法返回的结果都是列表形式,可以遍历形式输出,然后用get_text()方法来获取他的内容
for i in soup.select('a'):
print(i.get_text()) ##打印出a标签中的文本Python中的BeautifulSoup模块的更多相关文章
- 第14.10节 Python中使用BeautifulSoup解析http报文:html标签相关属性的访问
一. 引言 在<第14.8节 Python中使用BeautifulSoup加载HTML报文>中介绍使用BeautifulSoup的安装.导入和创建对象的过程,本节介绍导入后利用Beauti ...
- Python中的random模块,来自于Capricorn的实验室
Python中的random模块用于生成随机数.下面介绍一下random模块中最常用的几个函数. random.random random.random()用于生成一个0到1的随机符点数: 0 < ...
- Python中的logging模块
http://python.jobbole.com/86887/ 最近修改了项目里的logging相关功能,用到了python标准库里的logging模块,在此做一些记录.主要是从官方文档和stack ...
- Python中的random模块
Python中的random模块用于生成随机数.下面介绍一下random模块中最常用的几个函数. random.random random.random()用于生成一个0到1的随机符点数: 0 < ...
- 浅析Python中的struct模块
最近在学习python网络编程这一块,在写简单的socket通信代码时,遇到了struct这个模块的使用,当时不太清楚这到底有和作用,后来查阅了相关资料大概了解了,在这里做一下简单的总结. 了解c语言 ...
- python中的StringIO模块
python中的StringIO模块 标签:python StringIO 此模块主要用于在内存缓冲区中读写数据.模块是用类编写的,只有一个StringIO类,所以它的可用方法都在类中.此类中的大部分 ...
- python中的select模块
介绍: Python中的select模块专注于I/O多路复用,提供了select poll epoll三个方法(其中后两个在Linux中可用,windows仅支持select),另外也提供了kqu ...
- Python中的re模块--正则表达式
Python中的re模块--正则表达式 使用match从字符串开头匹配 以匹配国内手机号为例,通常手机号为11位,以1开头.大概是这样13509094747,(这个号码是我随便写的,请不要拨打),我们 ...
- python中的shutil模块
目录 python中的shutil模块 目录和文件操作 归档操作 python中的shutil模块 shutil模块对文件和文件集合提供了许多高级操作,特别是提供了支持文件复制和删除的函数. 目录和文 ...
随机推荐
- Reincarnation Without New Body(RWNB): Basic Theory and Baseline 现世转生基本理论及简单操作
Abstract 投胎学是一门高深的学问,不仅没有现存的理论,也没有过往的经验.根据种种猜测,投胎后前世的记忆也不能保留,造成了很大的不方便.在本文中,我们绕过了投胎需要"来世"的 ...
- C#类中的字段、属性和方法
C#类中的字段.属性和方法 刚开始学C#,对于类中的字段.属性和方法很难分清,写下这份笔记,帮助理解 字段:与类相关的变量 声明方法与声明变量类似,可在前面添加访问修饰符.static关键字等: 属性 ...
- 死磕Spring之IoC篇 - @Autowired 等注解的实现原理
该系列文章是本人在学习 Spring 的过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring 源码分析 GitHub 地址 进行阅读 Spring 版本:5.1. ...
- 微信小程序自定义Tabber,附详细源码
目录 1,前言 2,说明 3,核心代码 1,前言 分享一个完整的微信小程序自定义Tabber,tabber按钮可以设置为跳转页面,也可以设置为功能按钮.懒得看文字的可以直接去底部,博主分享了小程序代码 ...
- MyBatis(一):JDBC使用存在的问题
JDBC使用步骤: a:加载 JDBC 驱动程序 b:创建数据库的连接对象Connection c:根据链接获取Statement d:拼接SQL语句及设置参数 e:执行SQL并获取结果集 f:关闭使 ...
- 我与FreeBSD的故事之三
联想G400 是我在国美电器线下买的笔记本.我什么也不懂,就随便买了,不随便也不行,谁都知道只要不是那种特别的奸商,基本上货物都是符合价值决定价格这个基本的经济学规律的.所以没钱就失去了选择的自由.到 ...
- 医学图像配准 | Voxelmorph 微分同胚 | MICCAI2019
文章转载:微信公众号「机器学习炼丹术」 作者:炼丹兄(已授权) 联系方式:微信cyx645016617(欢迎交流) 论文题目:'Unsupervised Learning for Fast Proba ...
- 修饰符static和abstract
修饰符static和abstract static static可以修饰类中的方法,属性等,被修饰后的方法和属性可以通过类名直接调用也可以通过对象调用.普通的变量只能通过对象进行调用. 静态方法直接可 ...
- 解决linux sudo apt-get install xx是2出现无法定位软件包方法
解决办法: 在etc/apt/sources.list最后一行添加 deb http://archive.ubuntu.com/ubuntu/ trusty main universe restric ...
- ASP.Net Core中处理异常的几种方法
本文将介绍在ASP.Net Core中处理异常的几种方法 1使用开发人员异常页面(The developer exception page) 2配置HTTP错误代码页 Configuring stat ...