4 - 基于ELK的ElasticSearch 7.8.x技术整理 - 高级篇( 续 ) - 更新完毕
0、前言
- 这里面一些理论和前面的知识点挂钩的,所以:建议看一下另外3篇知识内容
- 基础篇:https://www.cnblogs.com/xiegongzi/p/15684307.html
- java操作篇:https://www.cnblogs.com/xiegongzi/p/15690534.html
- 高级篇1:https://www.cnblogs.com/xiegongzi/p/15757337.html
4.12、文档搜索
4.12.1、不可变的倒排索引
以前的全文检索是将整个文档集合弄成一个倒排索引,然后存入磁盘中,当要建立新的索引时,只要新的索引准备就绪之后,旧的索引就会被替换掉,这样最近的文档数据变化就可以被检索到
而索引一旦被存入到磁盘就是不可变的( 永远都不可以修改 ),而这样做有如下的好处:
- 1、只要索引被读入到内存中了,由于其不变性,所以就会一直留在内存中( 只要空间足够 ),从而当我们做“读操作”时,请求就会进入内存中去,而不会去磁盘中,这样就减小开销,提高效率了
- 2、索引放到内存中之后,是可以进行压缩的,这样做之后,也就可以节约空间了
- 3、放到内存中后,是不需要锁的,如果自己的索引是长期不用更新的,那么就不用怕多进程同时修改它的情况了
当然:这种不可变的倒排索引有好处,那就肯定有坏处了“
- 不可变,不可修改嘛,这就是最大的坏处,当要重定一个索引能够被检索时,就需要重新把整个索引构建一下,这样的话,就会导致索引的数据量很大( 数据量大小有限制了 ),同时要更新索引,那么这频率就会降低了( 这就好比是什么呢?关系型中的表,一张大表检索数据、更新数据效率高不高?肯定不高,所以延伸出了:可变索引 )
4.12.2、可变的倒排索引
又想保留不可变性,又想能够实现倒排索引的更新,咋办?
- 就搞出了
补充索引,所谓的补充索引:有点类似于日志这个玩意儿,就是重建一个索引,然后用来记录最近指定一段时间内的索引中文档数据的更新。这样更新的索引数据就记录在补充索引中了,然后检索数据时,直接找补充索引即可,这样检索时不再重写整个倒排索引了,这有点类似于关系型中的拆表,大表拆小表嘛,但是啊:每一份补充索引都是一份单独的索引啊,这又和分片很像,可是:查询时是对这些补充索引进行轮询,然后再对结果进行合并,从而得到最终的结果,这和前面说过的读流程中说明的协调节点挂上钩了
这里还需要了解一个配套的按段搜索,玩过 Lucene 的可能听过。按段,每段也就可以理解为:补充索引,它的流程其实也很简单:
1、新文档被收集到内存索引缓存
2、不时地提交缓存
- 2.1、一个新的段,一个追加的倒排索引,被写入磁盘
- 2.2、一个新的包含新段名字的提交点被写入磁盘
- 2.3、磁盘进行同步,所有在文件系统缓存中等待的写入都刷新到磁盘,以确保它们被写入物理文件
3、新的段被开启,让它包含的文档可见,以被搜索
4、内存缓存被清空,等待接收新的文档
一样的,段在查询的时候,也是轮询的啊,然后把查询结果合并从而得到的最终结果
另外就是涉及到删除的事情,段本身也是不可变的, 既不能把文档从旧的段中移除,也不能修改旧的段来进行文档的更新,而删除是因为:是段在每个提交点时有一个.del文件,这个文件就是一个删除的标志文件,要删除哪些数据,就对该数据做了一个标记,从而下一次查询的时候就过滤掉被标记的这些段,从而就无法查到了,这叫逻辑删除( 当然:这就会导致倒排索引越积越多,再查询时。轮询来查数据也会影响效率 ),所以也有物理删除,它是把段进行合并,这样就舍弃掉被删除标记的段了,从而最后刷新到磁盘中去的就是最新的数据( 就是去掉删除之后的 ,别忘了前面整的段的流程啊,不是白写的 )
4.13、近实时搜索、文档刷新、文档刷写、文档合并
- ES的最大好处就是实时数据全文检索,但是:ES这个玩意儿并不是真的实时的,而是近实时 / 准实时,原因就是:ES的数据搜索是分段搜索,最新的数据在最新的段中( 每一个段又是一个倒排索引 ),只有最新的段刷新到磁盘中之后,ES才可以进行数据检索,这样的话,磁盘的IO性能就会极大的影响ES的查询效率,而ES的目的就是为了:快速的、准确的获取到我们想要的数据,因此:降低数据查询处理的延迟就very 重要了,而ES对这方面做了什么操作?
- 就是搞的一主多副的方式( 一个主分片,多个副本分片 ),这虽然就是一句话概括了,但是:里面的门道却不是那么简单的
首先来看一下主副操作
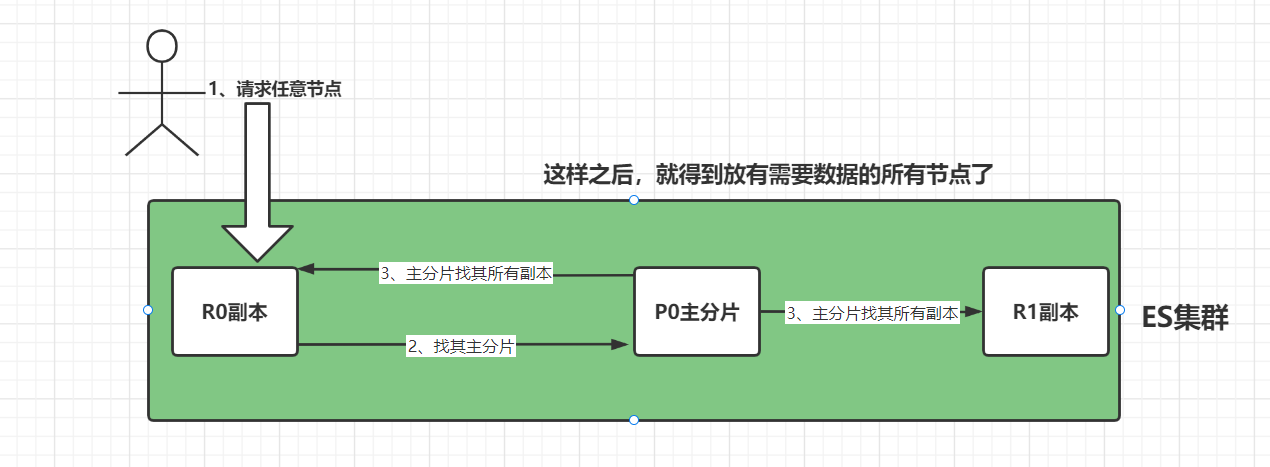
但是:这种去找寻节点的过程想都想得到会造成延时,而延时 = 主分片延时 + 主分片拷贝数据给副本的延时
而且并不是这样就算完了,前面提到了N多次的分段、刷新到磁盘还没上堂呢,所以接着看
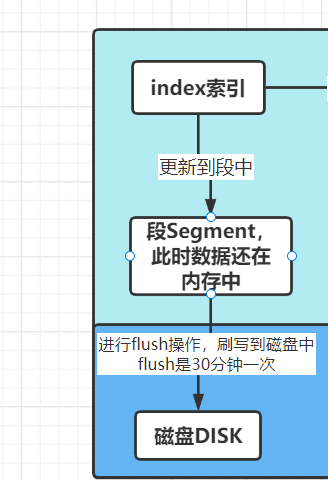
但是:在flush到磁盘中的时候,万一断电了呢?或者其他原因导致出问题了,那最后数据不就没有flush到磁盘吗。因此:其实还有一步操作,把数据保存到另外一个文件中去

数据放到磁盘中之后,translog中的数据就会清空
同时更新到磁盘之后,用户就可以进行搜索数据了
注意:这里要区分一下,数据库中是先更新到log中,然后再更新到内存中,而ES是反着的,是先更新到Segment( 可以直接认为是内存,因它本身就在内存中 ),再更新到log中
可是啊,还是有问题,flush刷写到磁盘是很耗性能的,假如:不断进行更新呢?这样不断进行IO操作,性能好吗?也不行,因此:继续改造( 在Java的JDBC中我说过的 ———— 没有什么是加一层解决不了的,一层不够,那就再来一层 )
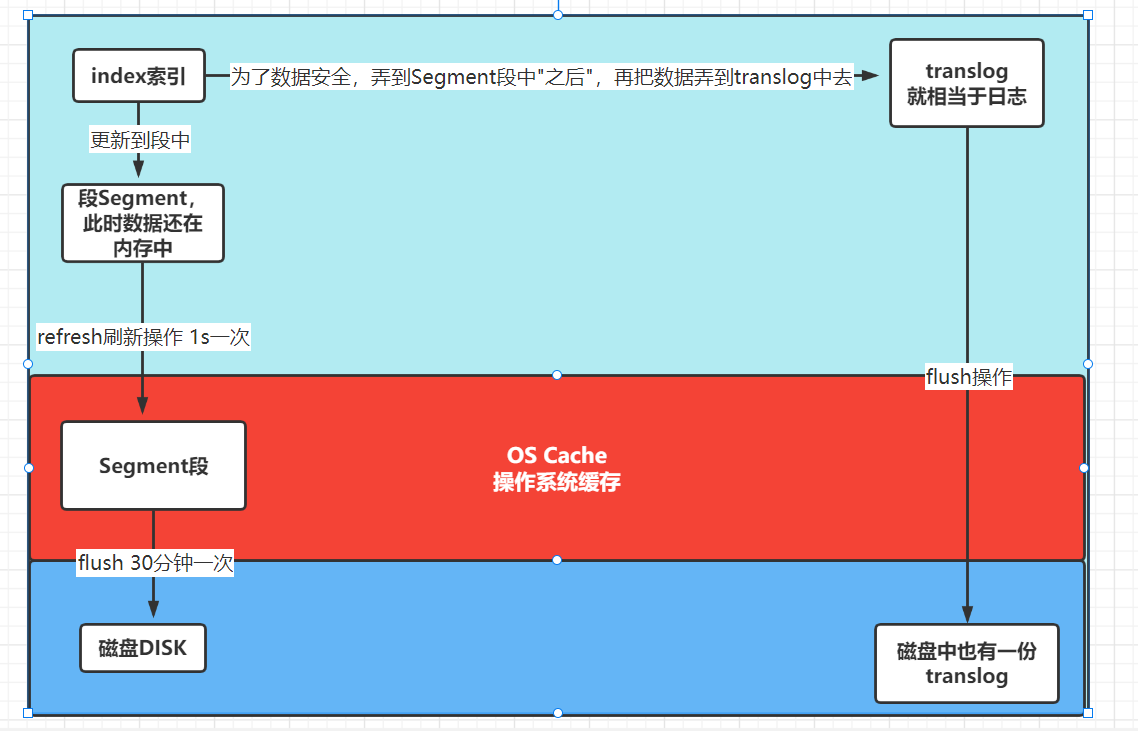
加入了缓存之后,这缓存里面的数据是可以直接用来搜索的,这样就不用等到flush到磁盘之后,才可以搜索了,这大大的提高了性能,而flush到磁盘,只要时间到了,让它自个儿慢慢flush就可以了( 操作系统缓存中的数据断电不会丢失啊,只会在下一次启动的时候,继续执行而已 ),上面这个流程也叫:持久化 / 持久化变更
写入和打开一个新段的轻量的过程叫做refresh。默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说 ES是近实时搜索:文档的变化并不是立即对搜索可见,但会在一秒之内变为可见
- 刷新是1s以内完成的,这是有时间间隙的,因此会造成:搜索一个文档时,可能并没有搜索到,因此:解决办法就是使用refresh API刷新一下即可
- 但是这样也伴随一个问题:虽然这种从内存刷新到缓存中看起来不错,但是还是有性能开销的。并不是所有的情况都需要refresh的,假如:是在索引日志文件呢?去refresh干嘛,浪费性能而已,所以此时:你要的是查询速度,而不是近实时搜索,因此:可以通过一个配置来进行改动,从而降低每个索引的刷新频率
http://ip:port/index_name/_settings # 请求方式:put
# 请求体内容
{
"settings": {
"refresh_interval": "60s"
}
}
- refresh_interval可以在既存索引上进行动态更新。在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来( 虽然有点麻烦,但是按照ES这个玩意儿来说,确实需要这么做比较好 )
# 关闭自动刷新
http://ip:port/users/_settings # 请求方式:put
# 请求体内容
{
"refresh_interval": -1
}
# 每一秒刷新
http://ip:port/users/_settings # 请求方式:put
# 请求体内容
{
"refresh_interval": "1s"
}
- 另外:不断进行更新就会导致很多的段出现( 在内存刷写到磁盘哪里,会造成很多的磁盘文件 ),因此:在哪里利用了文档合并的功能( 也就是段的能力,合并文档,从而让刷写到磁盘中的文档变成一份 )
- 经过上面的思路了解之后,要是面试官问你数据库的优化可以怎么弄?除了常见的,这个分段的思想、分片的思想就可以套上去了,当然再结合Redis的优化方式来回答,更beautiful,顺带还可以扯到Redis和ES来( 面试造飞机,上班拧螺丝嘛,或者就是一部署完就在办公室坐着抠脚 ),这就变成你牵着面试官的鼻子走,而不是他问什么,你去跟着它的思路回答,主动权在自己手上不香吗,面试官面试一个人是有时间限制的,当然:要是不想扯到ES中来,直接根据情况大表拆小表也行
4.14、文档分析
试想:我们在浏览器中,输入一条信息,如:搜索“博客园紫邪情”,为什么连“博客园也搜索出来了?我要的是不是这个结果涩”
这就是全文检索,就是ES干的事情( 过滤数据、检索嘛 ),但是:它做了哪些操作呢?
在ES中有一个文档分析的过程,文档分析的过程也很简单:
将文本拆成适合于倒排索引的独立的词条,然后把这些词条统一变为一个标准格式,从而使文本具有“可搜索性”
而这个文档分析的过程在ES是由一个叫做“分析器 analyzer”的东西来做的,这个分析器里面做了三个步骤
1、字符过滤器:就是用来处理一些字符的嘛,像什么将 & 变为 and 啊、去掉HTML元素啊之类的。它是文本字符串在经过分词之前的一个步骤,文本字符串是按文本顺序经过每个字符串过滤器从而处理字符串的
2、分词器:见名知意,就是用来分词的,也就是将字符串拆分成词条( 字 / 词组 ),这一步和Java中String的split()一样的,通过指定的要求,把内容进行拆分,如:空格、标点符号
3、Token过滤器:这个玩意儿的作用就是 词条经过每个Token过滤器,从而对数据再次进行筛选,如:字母大写变小写、去掉一些不重要的词条内容、添加一些词条( 如:同义词 )
上述的内容不理解没事,待会儿会用IK中文分词器来演示,从而能够更直观的看到效果
在ES中,有提供好的内置分析器、我们也可以自定义、当然还有就是前面说的IK分词器也可以做到( 而重点需要了解的就是IK中文分词器 ,写到这里了,就突然想到一个事儿,牢骚一下:
- 就是有人私聊,说我博客废话太多了,有些不需要的东西写出来干什么?他只想快速上手,其他不相关的滤过比较好,所以我在想:不把事情的前因后果了解到,就直接开干好吗?反正现在的我不把东西整明白,学东西都总感觉缺点什么,从而导致学的东西不是我想要的,这样让我学起来很不爽,虽然理论确实整起来烦得很,我曾经开始接触Java的时候也是这么想的,就想着步子迈大一点,只管技术怎么用就行,理论哪些废话我不想听,可是后来步子迈大了,扯到了胯,后面研究另外一些深一点的东西时,我总觉得少了一些东西,边研究边百度,但是知识点是散的,那不是我想要的知识体系,这种更不爽( 我个人偏向于:自己脑海有知识体系才好,但那时候学是散的,自己一边整一边摸索的 )。你敢相信我当初才用ES时,快速上手到什么地步?就了解了一些基础理论、在linux中用docker-conpose.yml编写了ES和kibana的安装方式( ES和Kibana都在一个yml文件中,就是我第三篇ES —— 高级篇博客中玩linux单机ES时说的那个yml安装方式 )、还有就是Java API各种常用的查询方式,然后就没了,结果后面自己吃了大亏,后面我是把Java重学了一遍,所以别相信什么所谓的“键盘不稀烂、代码不停干”,只撸代码,会处理人际关系那有个鸟用,理论是筑起高楼的地基,好了言归正传吧!!!
在演示在前,先玩kibana吧,原本打算放在后面的,但是越早熟悉越好嘛,所以先把kibana说明了
4.14.1、kibana
准备工作:去Elastic官网下载kibana,官网地址如下:
- https://www.elastic.co/cn/downloads/?elektra=home&storm=hero
- 这网站进去会很慢,进入之后就可以在首页看到一个kibana了,但是需要注意:kibana的版本必须和ES的版本一致,在Java篇中已经说明过了,个人建议:把Windows版和linux版都下载了,玩的时候用Windows版的,linux版后续自己可能会用到
下载好了kibana之后,解压到自己想要的目录( 注:加压会有点久,因为是用Vue写的,里面有模块module 要是加压快的话,可能还下错了 ),然后点击bin/kibana.bat即可启动kibana

启动之后就是上图中的样子,然后访问图中的地址即可,第一次进去会有一个选择页面,try / explore,选择explore就可以了,进去之后就是如下界面
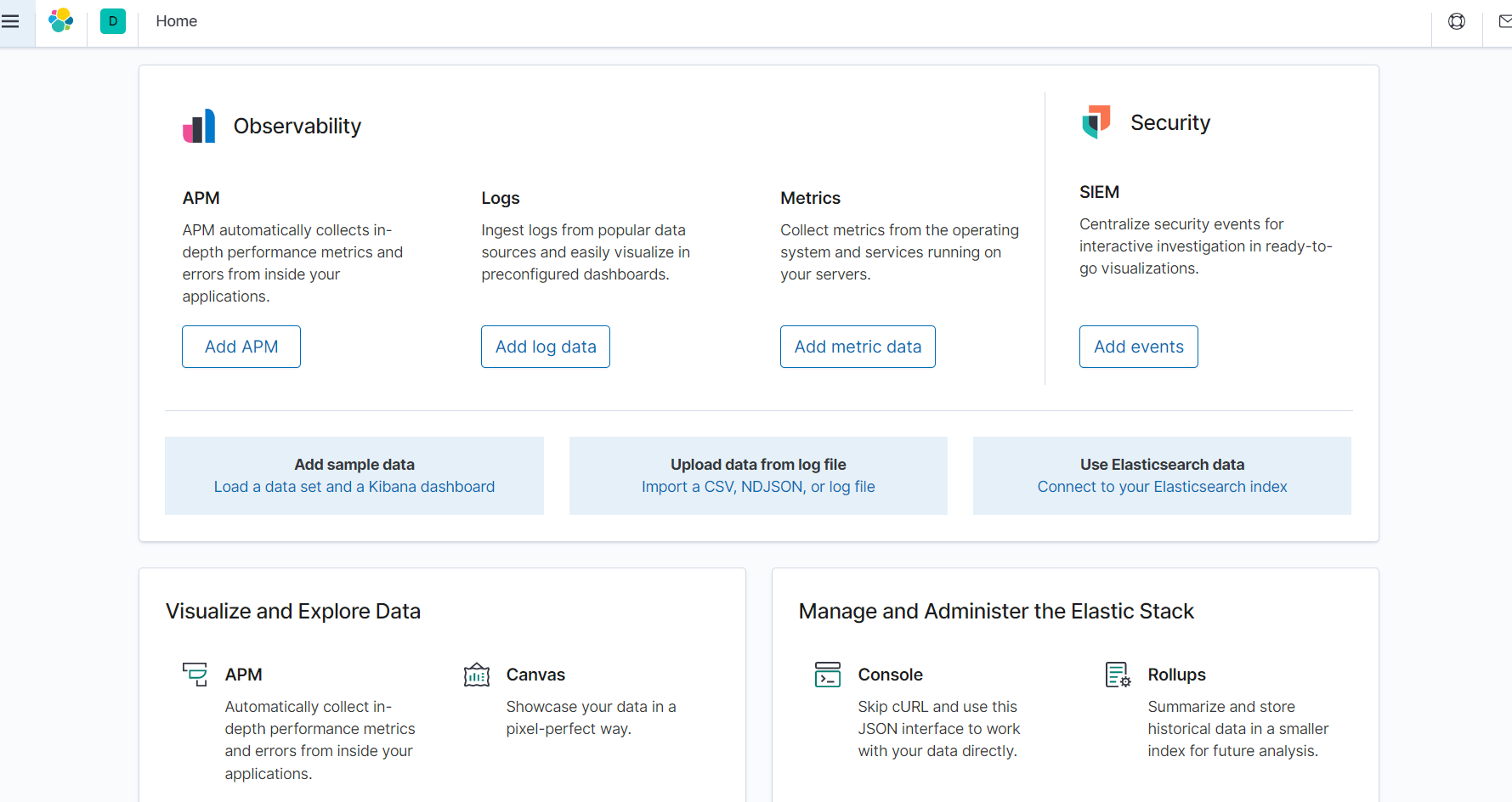
这是英文版,要是没玩过大数据的话,那么里面的一些专业名词根据英文来看根本不知道,所以:汉化吧,kibana本身就提供得有汉化的功能,只需要改动一个配置即可 —— 就是一个i1bn配置而已
进入config/kibana.yml,刷到最底部
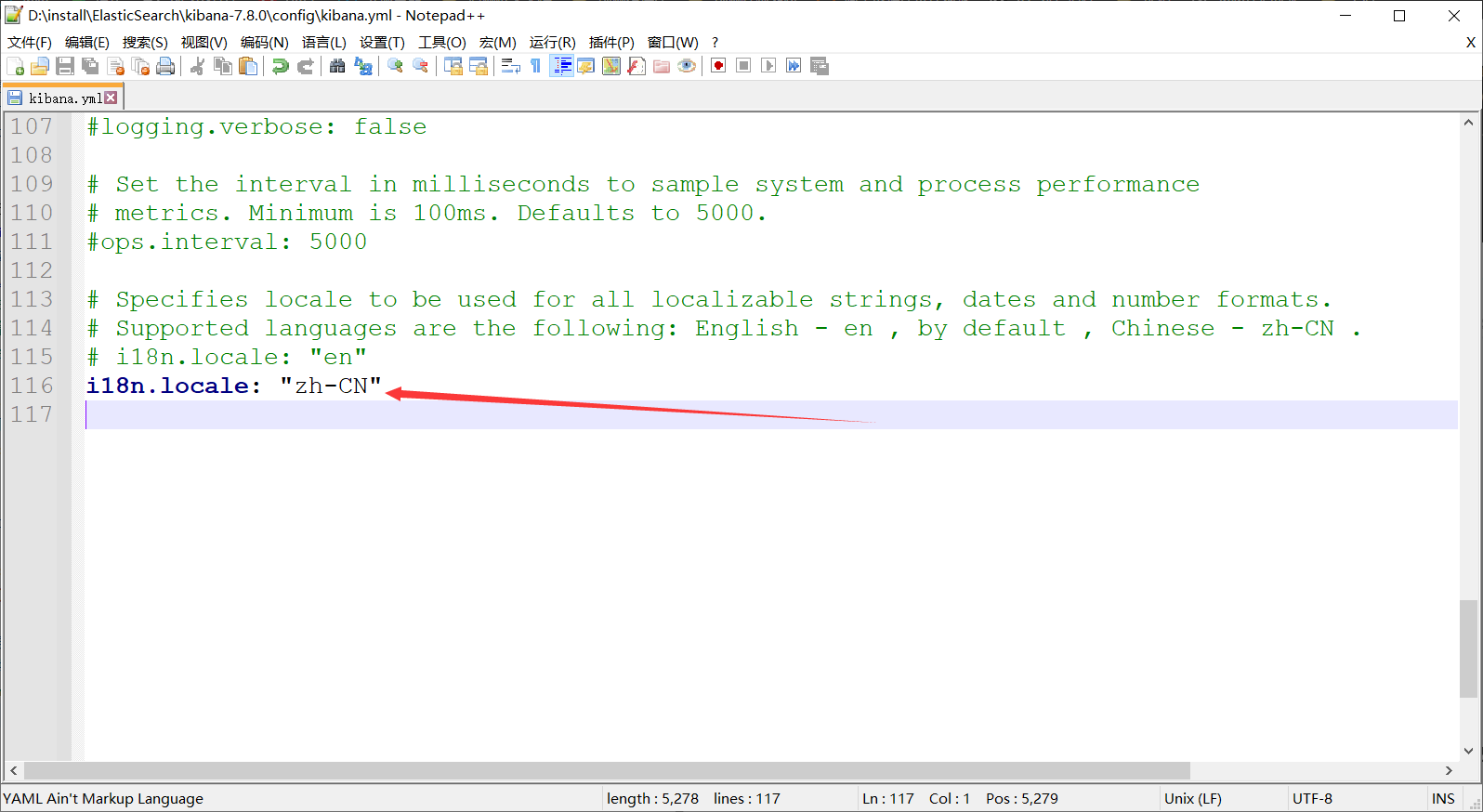
加上上面的信息,然后重启kibana就可以了( 但是:个人建议,先汉化一段时间,等熟悉哪些名词了,然后再转成英文 ,总之最后建议用英文,一是增加英文词汇量,二是熟悉英文专业词 )
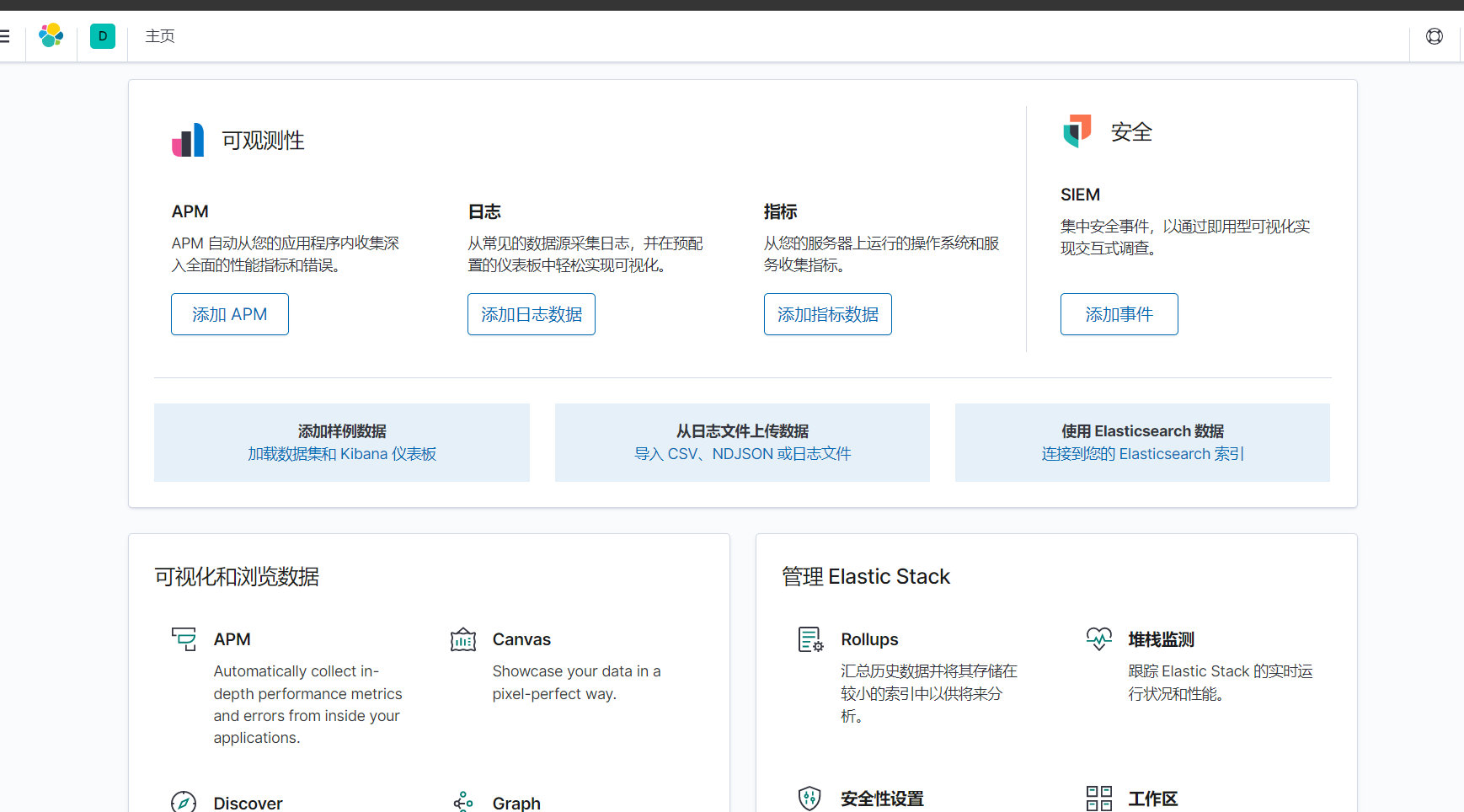
汉化成功
kibana遵循的是rest风格( get、put、delete、post..... ),具体用法接下来玩分析器和后面都会慢慢熟悉
4.14.2、内置分析器
4.14.2.1、标准分析器 standard
这是根据Unicode定义的单词边界来划分文本,将字母转成小写,去掉大部分的标点符号,从而得到的各种语言的最常用文本选择,另外:这是ES的默认分析器,接下来演示一下
启动ES( 这是用的单机,即重新解压启动的那种,另外方式也可以玩,但没演示 )和kibana,打开控制台
编写指令
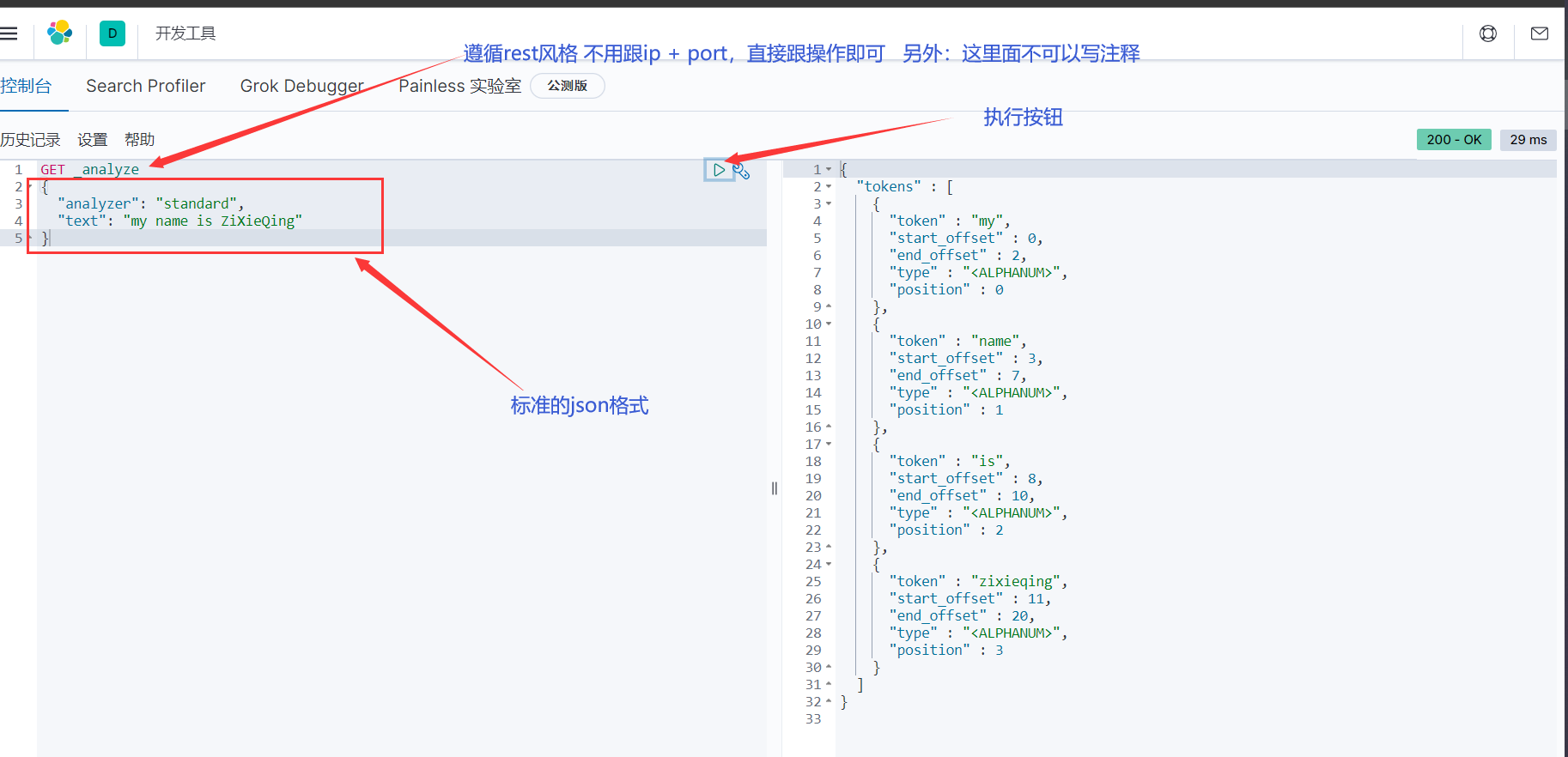
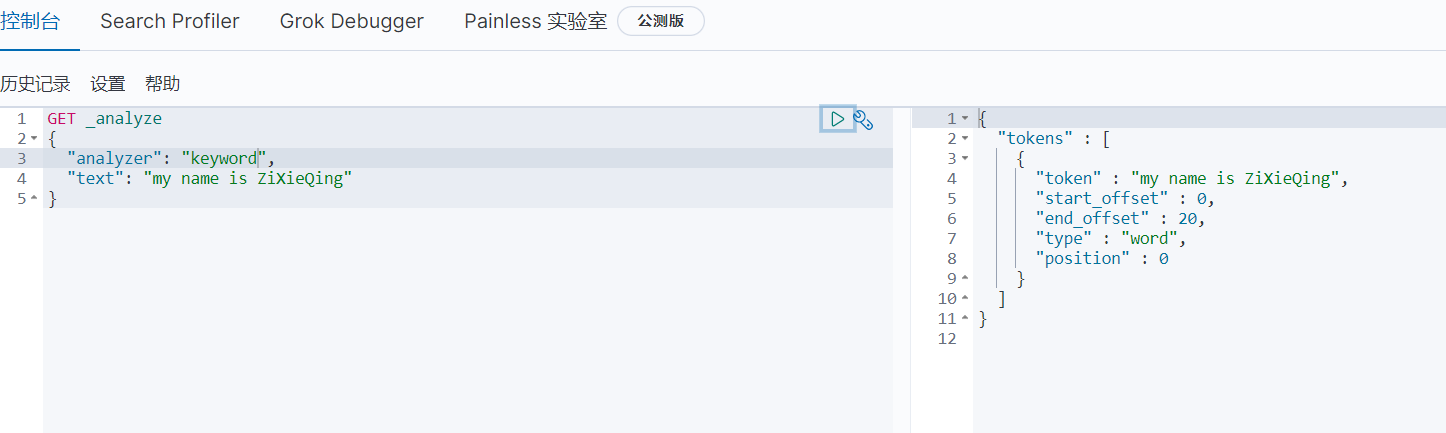
GET _analyze
{
"analyzer": "standard", # analyzer 分析器 standard 标准分析器
"text": "my name is ZiXieQing" # text 文本标识 my name is ZiXieQing 自定义的文本内容
}
# 响应内容
{
"tokens" : [
{
"token" : "my", # 分词之后的词条
"start_offset" : 0,
"end_offset" : 2, # start和end叫偏移量
"type" : "<ALPHANUM>",
"position" : 0 # 当前词条在整个文本中所处的位置
},
{
"token" : "name",
"start_offset" : 3,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "is",
"start_offset" : 8,
"end_offset" : 10,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "zixieqing",
"start_offset" : 11,
"end_offset" : 20,
"type" : "<ALPHANUM>",
"position" : 3
}
]
}
- **从上图可以看出:所谓标准分析器是将文本通过标点符号来分词的( 空格、逗号... ,不信可以自行利用这些标点测试一下,观察右边分词的结果 ),同时大写转小写**
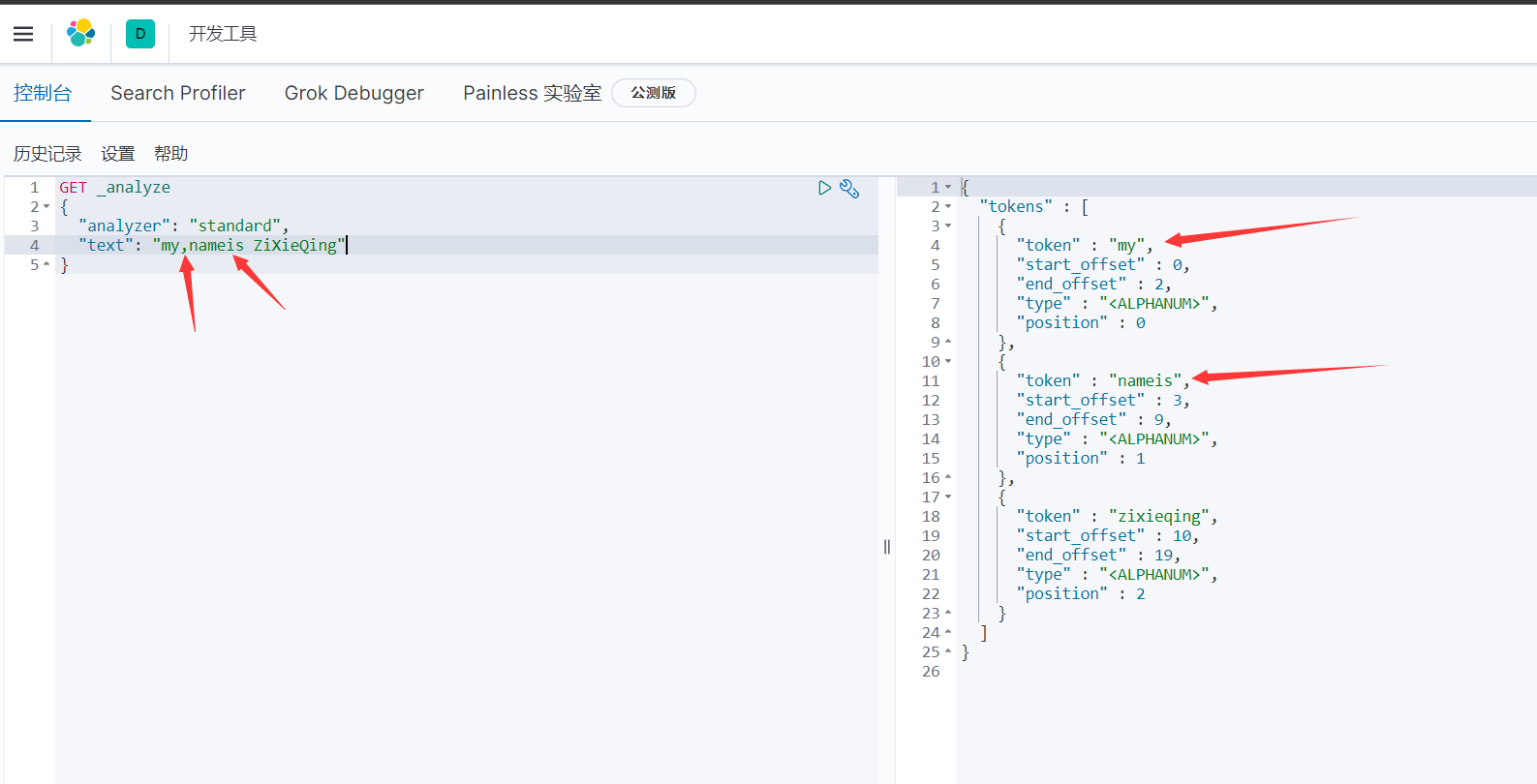
4.14.2.2、简单分析器 simple
- 简单分析器是“按非字母的字符分词,例如:数字、标点符号、特殊字符等,会去掉非字母的词,大写字母统一转换成小写”

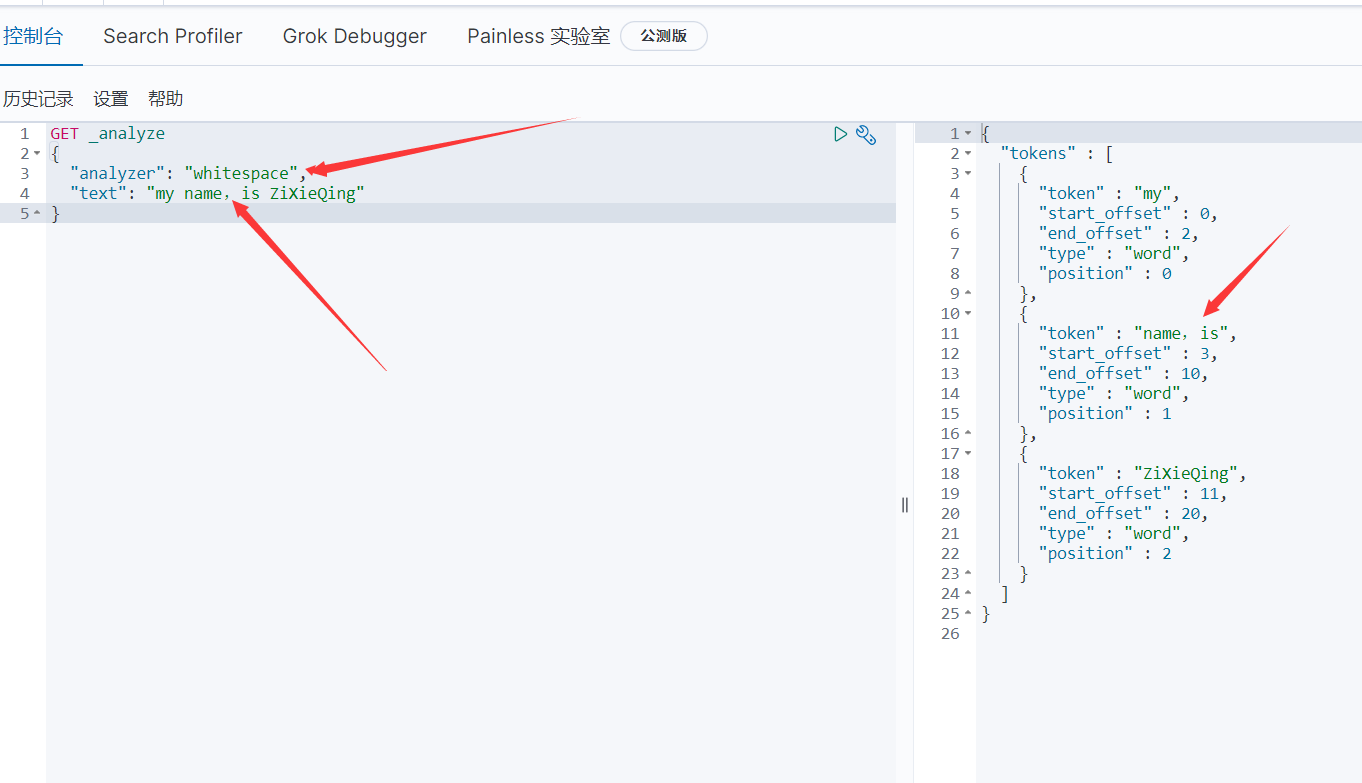
4.14.2.3、空格分析器 whitespace
- 是简单按照空格进行分词,相当于按照空格split了一下,大写字母不会转换成小写
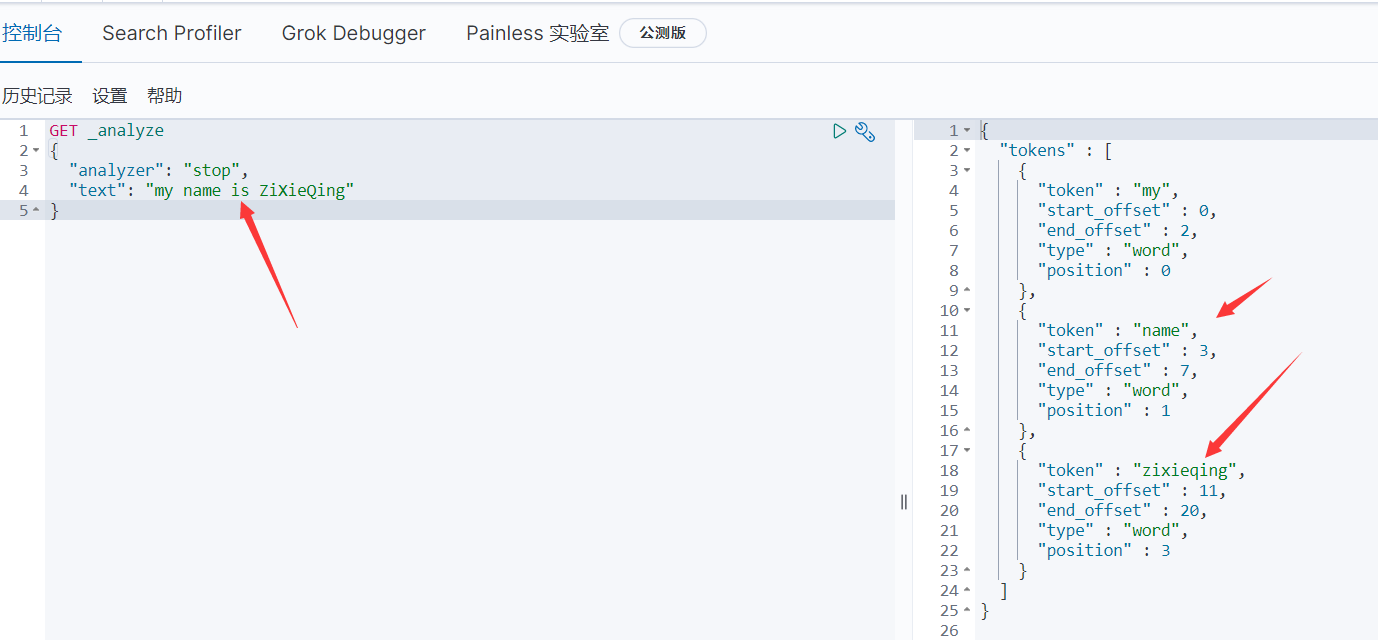
4.14.2.4、去词分析器 stop
- 会去掉无意义的词( 此无意义是指语气助词等修饰性词,补语文:语气词是疑问语气、祈使语气、感叹语气、肯定语气和停顿语气 ),例如:the、a、an 、this等,大写字母统一转换成小写
4.14.2.5、不拆分分析器 keyword
- 就是将整个文本当作一个词
4.14.3、IK中文分词器
来个实验
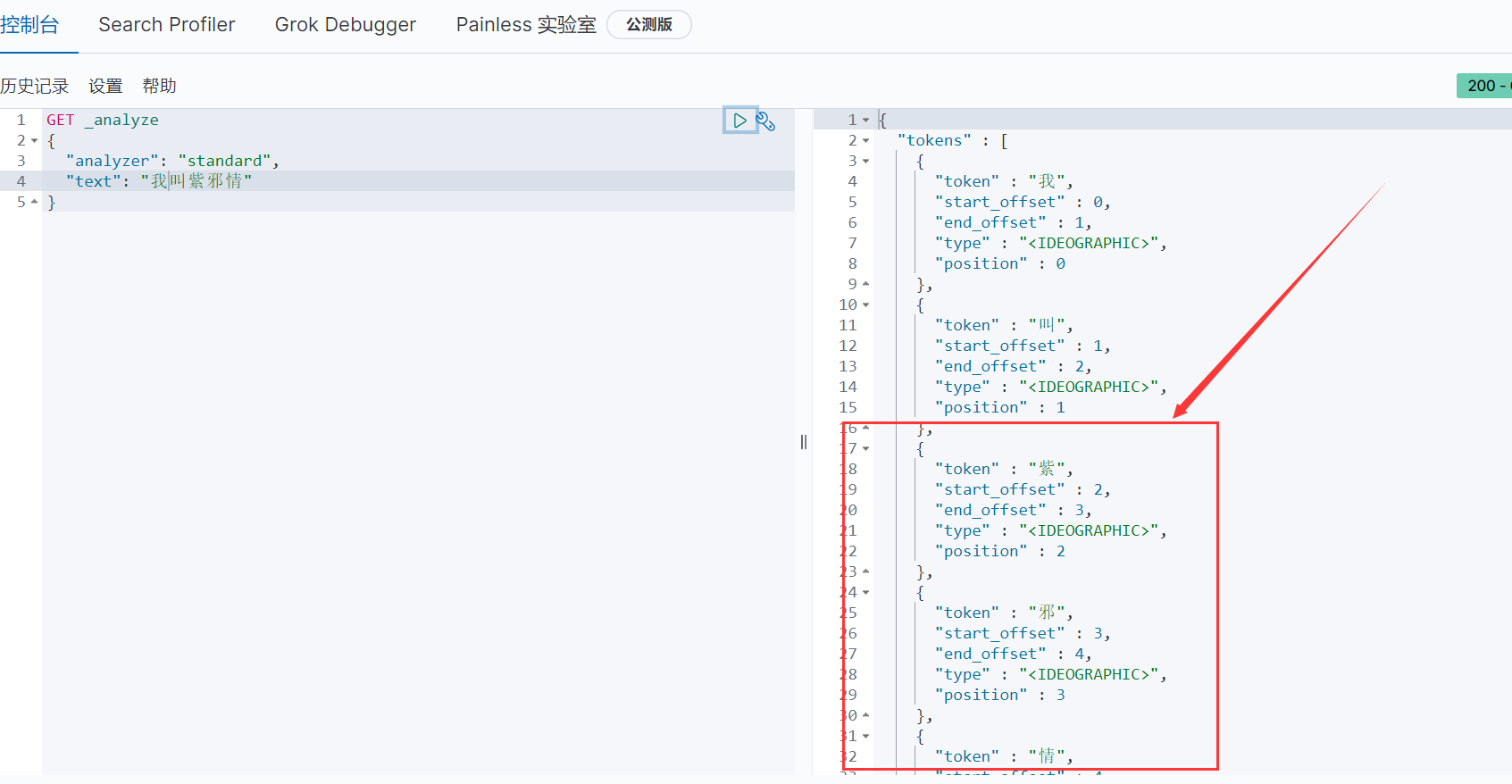
它把我的名字进行拆分了,这不是我想要的,我想要的“紫邪情”应该是一个完整的词,同样道理:想要特定的词汇,如:ID号、用户名....,这些不应该拆分,而ES内置分析器并不能做到,所以需要IK中文分词器( 专门用来处理中文的 )
1、下载IK分词器
- https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.8.0
- 注意:版本对应关系,还是和ES版本对应,https://github.com/medcl/elasticsearch-analysis-ik 这个链接进去之后有详细的版本对应
- 要是感觉github下载慢的话,我把阿里云盘更新了一遍,那里面放出来的包有7.8.0的版本,这里面也有一些其他的东西,有兴趣的下载即可,另外:在这里面有一个chrome-plugin包,这里面有一些chrome的插件,其中有一个fast-github,即:github下载加速器,可以集成到浏览器中,以后下载github的东西就不限速了,云盘链接是:https://www.aliyundrive.com/s/oVC6WWthpUb
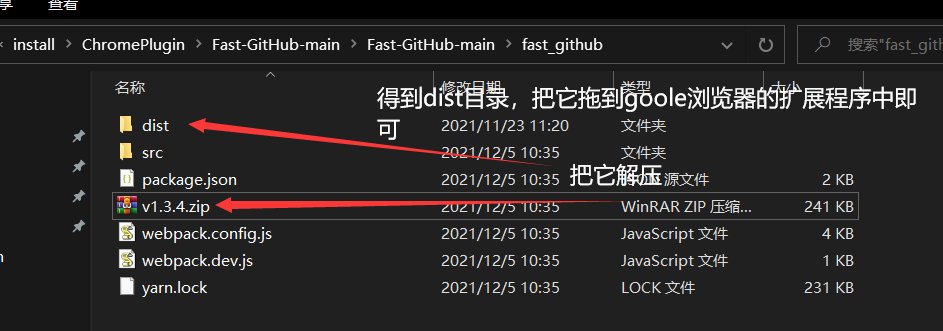
fast-github集成到goole之后如下:
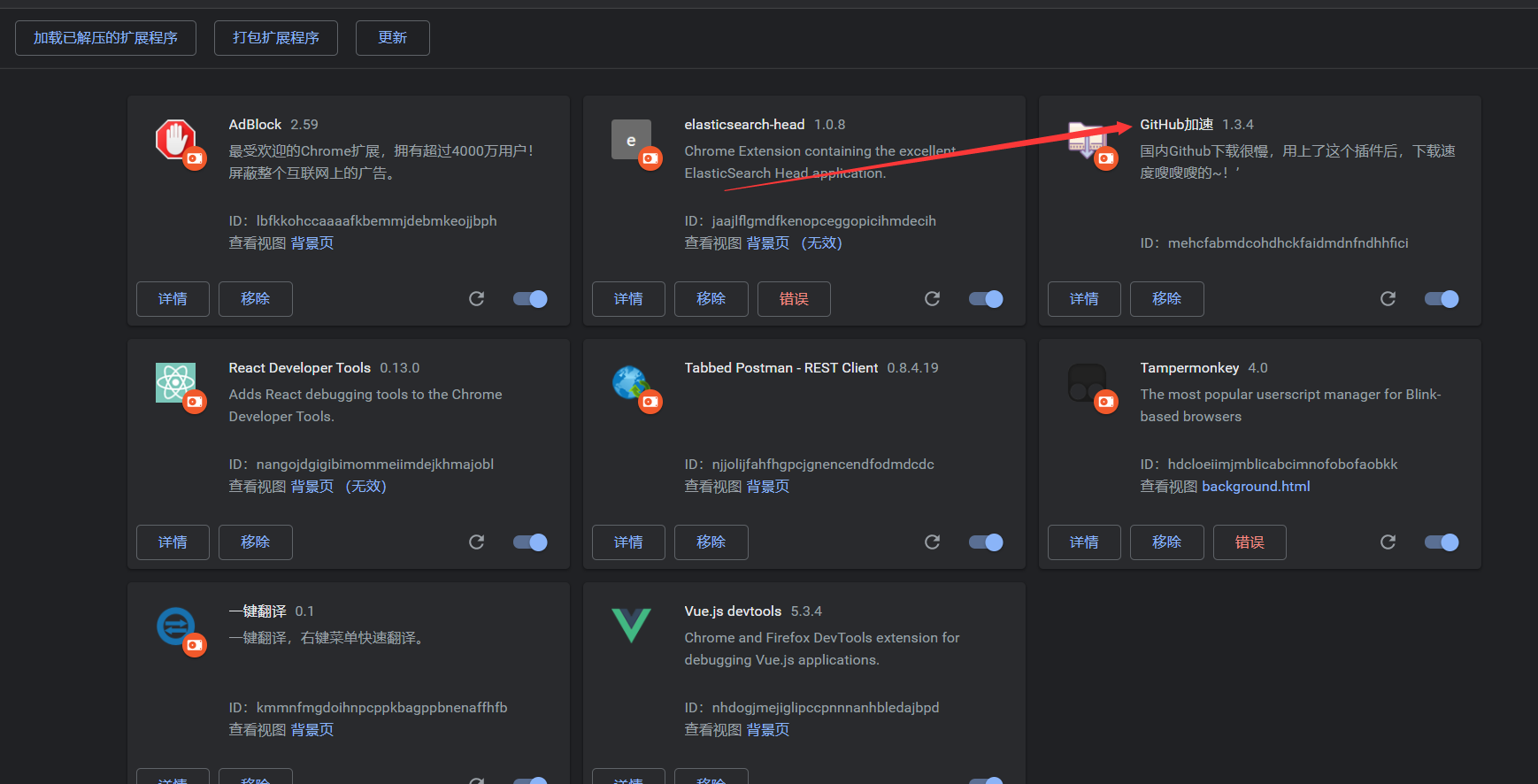
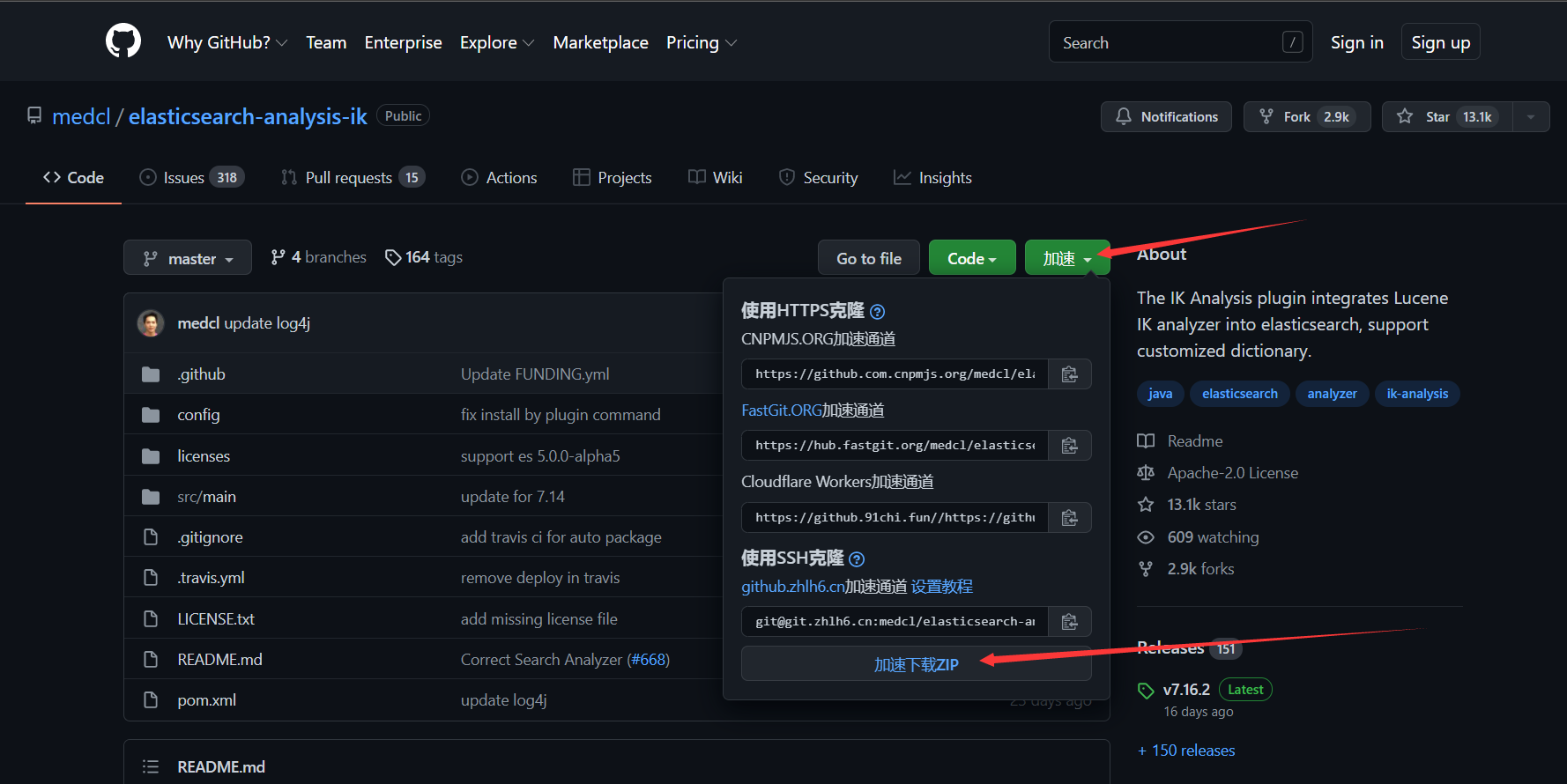
这样以后下载github的东西时,就有一个加速下载了,点击即可快速下载,如:
2、把IK解压到ES/plugins中去,如我的:

3、重启ES即可( kibana开着的话,也要关了重启 ),注意观察:重启时会有一个IK加载过程
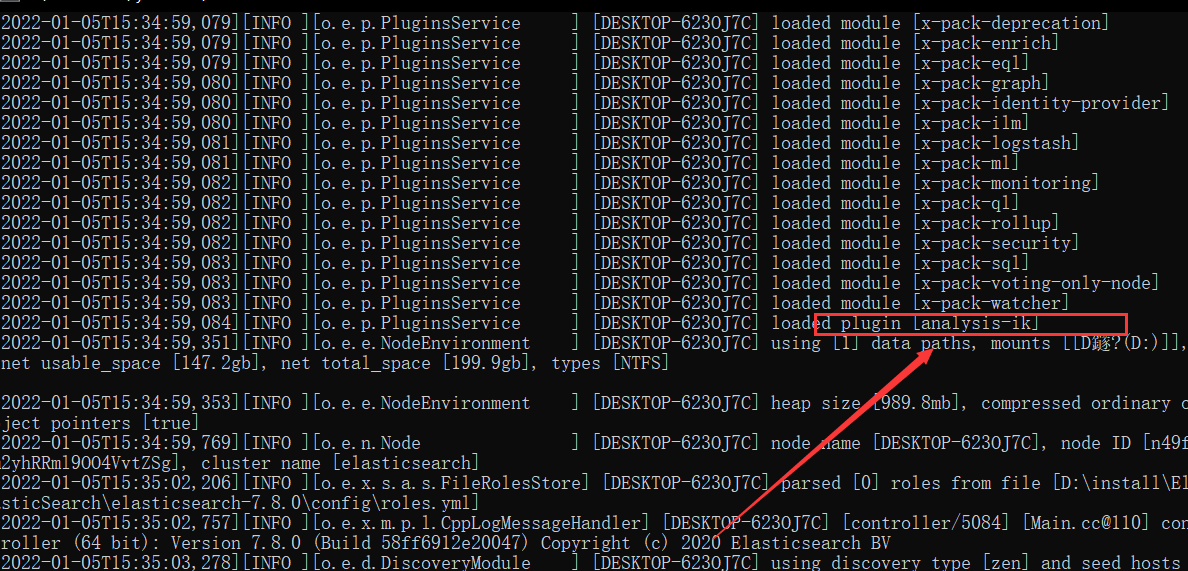
经过如上的操作之后,IK中文分词器就配置成功了,接下来就来体验一下( 启动ES和kibana ),主要是为了了解IK中的另外两种分词方式:ik_max_word和ik_smart
ik_max_word是细粒度的分词,就是:穷尽词汇的各种组成
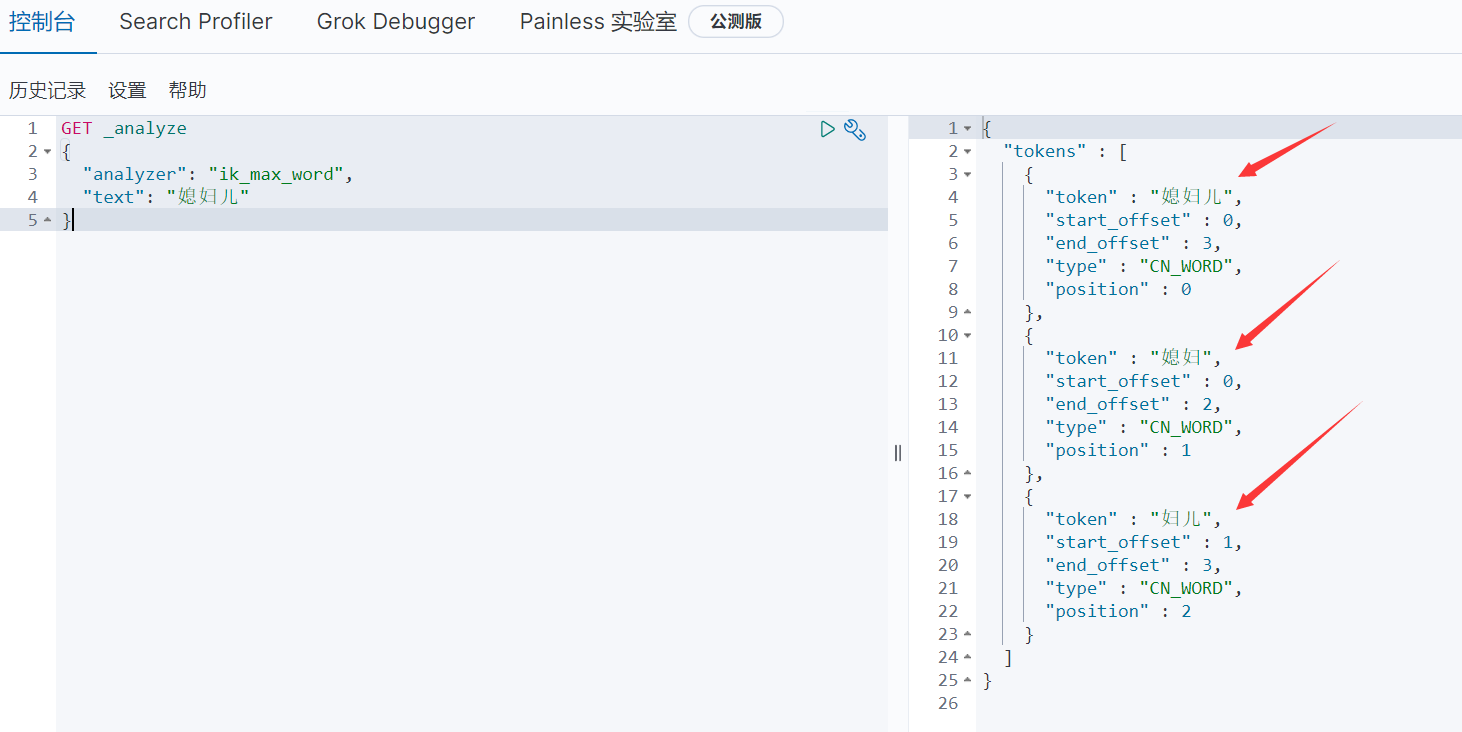
ik_smart是粗粒度的分词
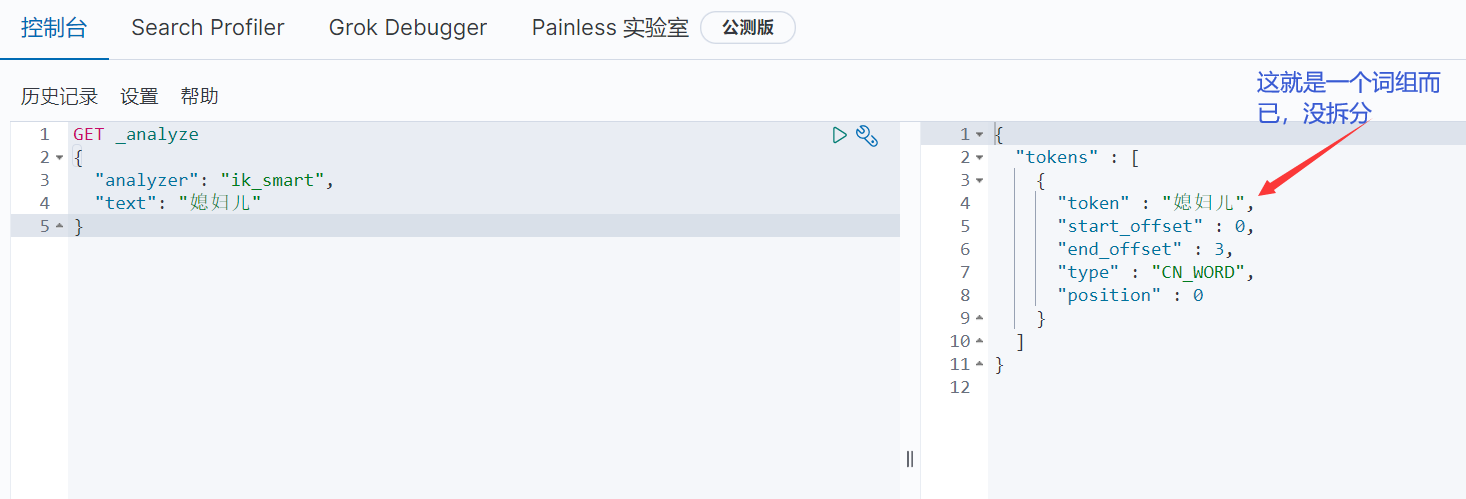
回到前面的问题,“紫邪情”是名字,我不想让它分词,怎么做?上面哪些分词都是在一个“词典”中,所以我们自己搞一个词典即可
1、创建一个.dic文件 dic就是dictionary词典的简写
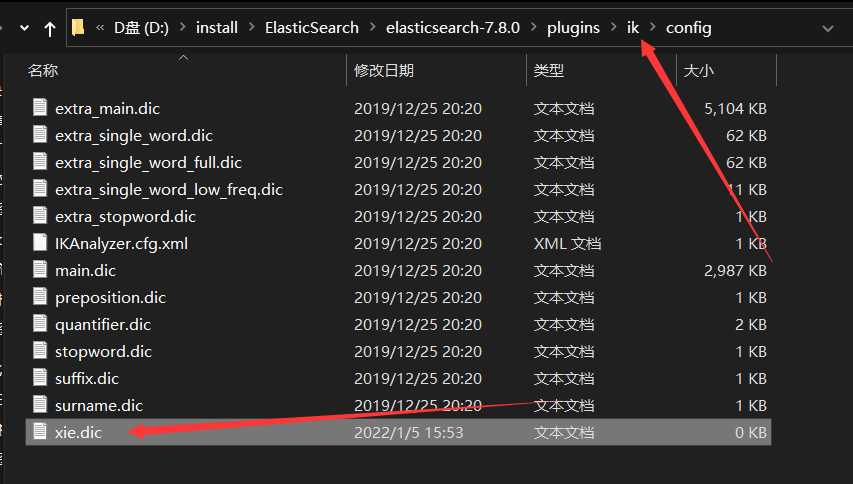
2、在创建的dic文件中添加不分词的词组,保存
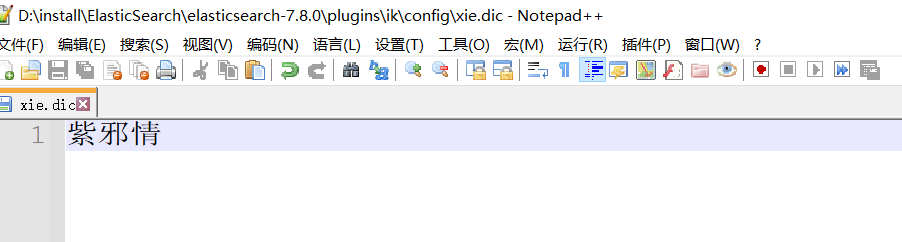
3、把自定义的词典放到ik中去,保存
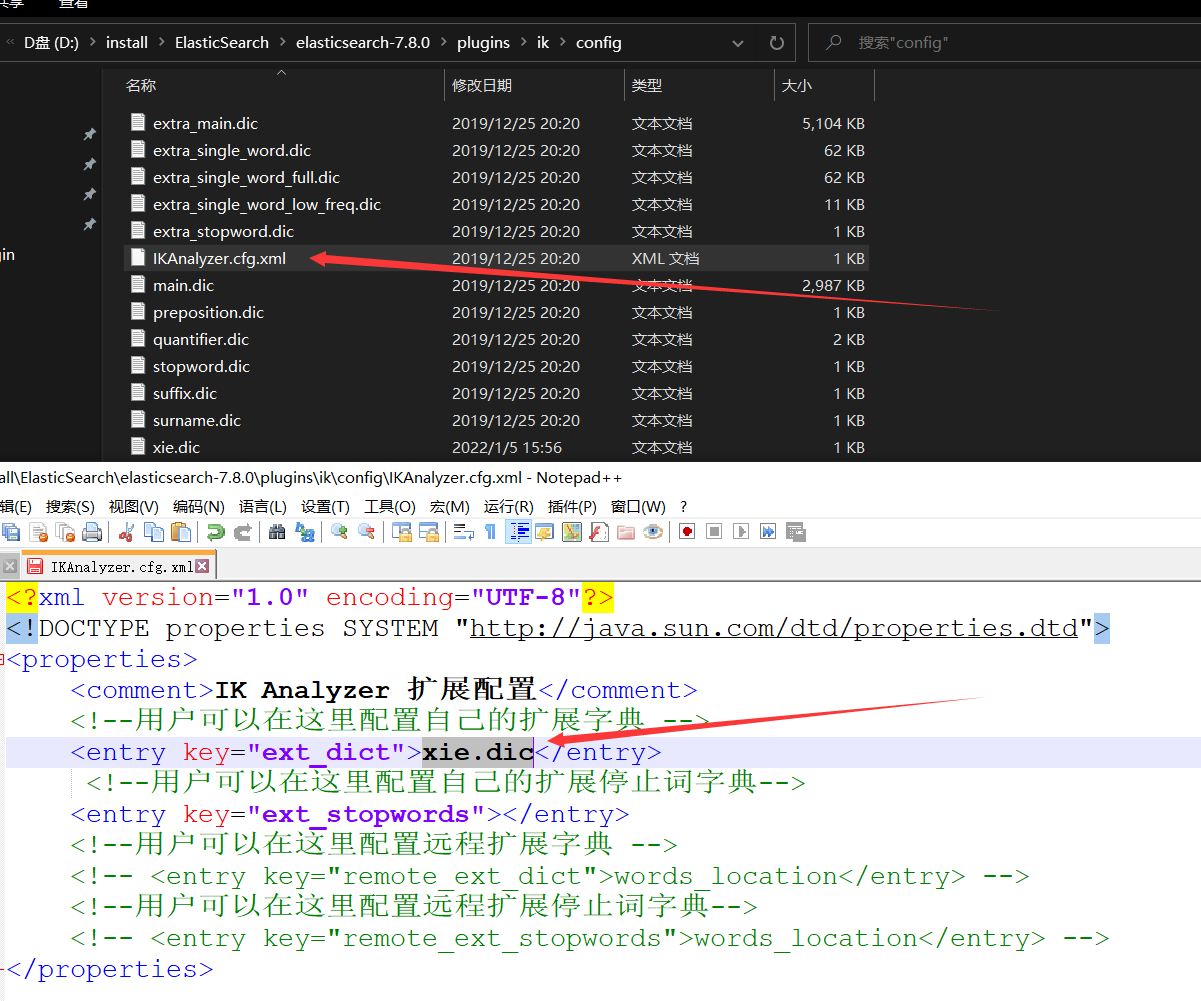
4、重启ES和kibana
5、测试

可见,现在就把“紫邪情”组成词组不拆分了,前面玩的kibana汉化是怎么做的?和这个的原理差不多
4.14.4、自定义分析器
- 这里还有一个自定义分析器的知识点,这个不了解也罢,有兴趣的自行百度百科了解一下
4.14.5、多玩几次kibana
在第一篇高级篇中我边说过:kibana重要,只是经过前面这些介绍了使用之后,并不算熟悉,因此:多玩几次吧
另外:就是前面说的kibana遵循rest风格,在ES中是怎么玩的?总结下来其实就下面这些,要上手简单得很,但理论却是一直弄到现在
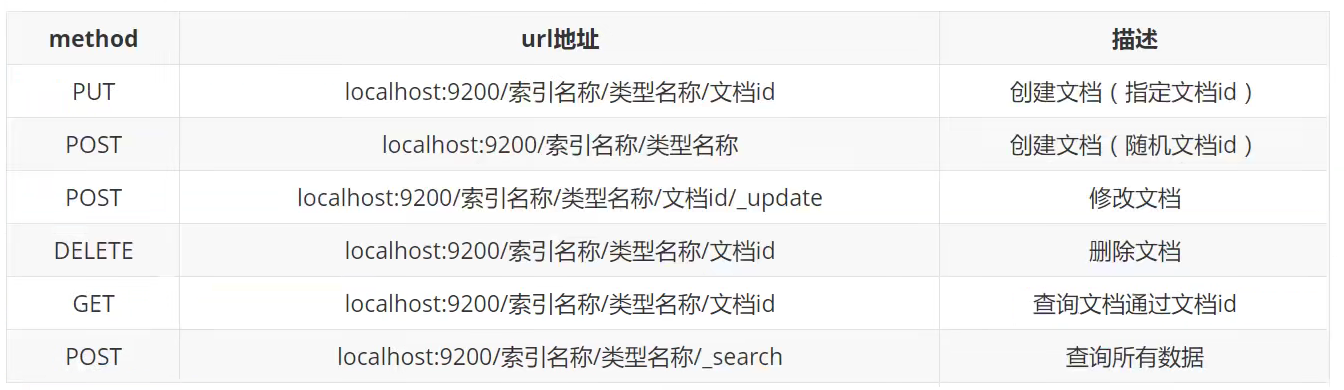
现在用kibana来演示几个,其他在postman中怎么弄,换一下即可( 其实不建议用postman测试,专业的人做专业的事,kibana才是我们后端玩的 )
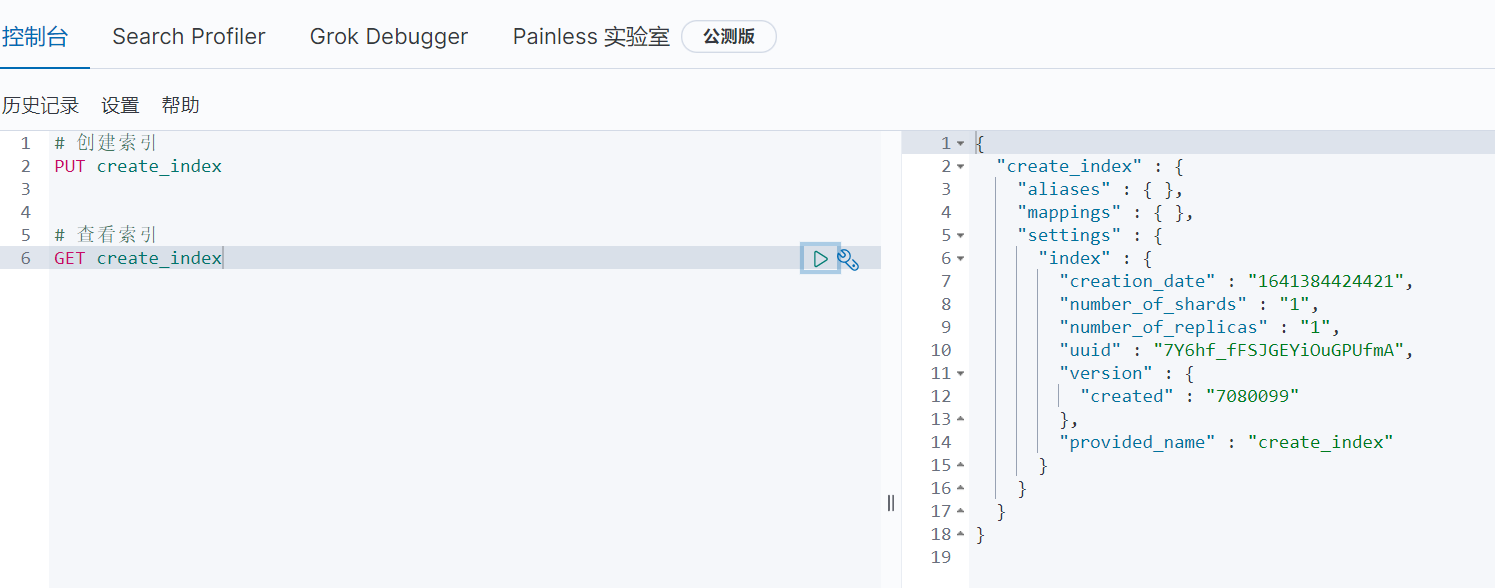
1、创建索引

2、查看索引
3、创建文档( 随机id值,想要自定义id值,在后面加上即可 )
4、删除索引
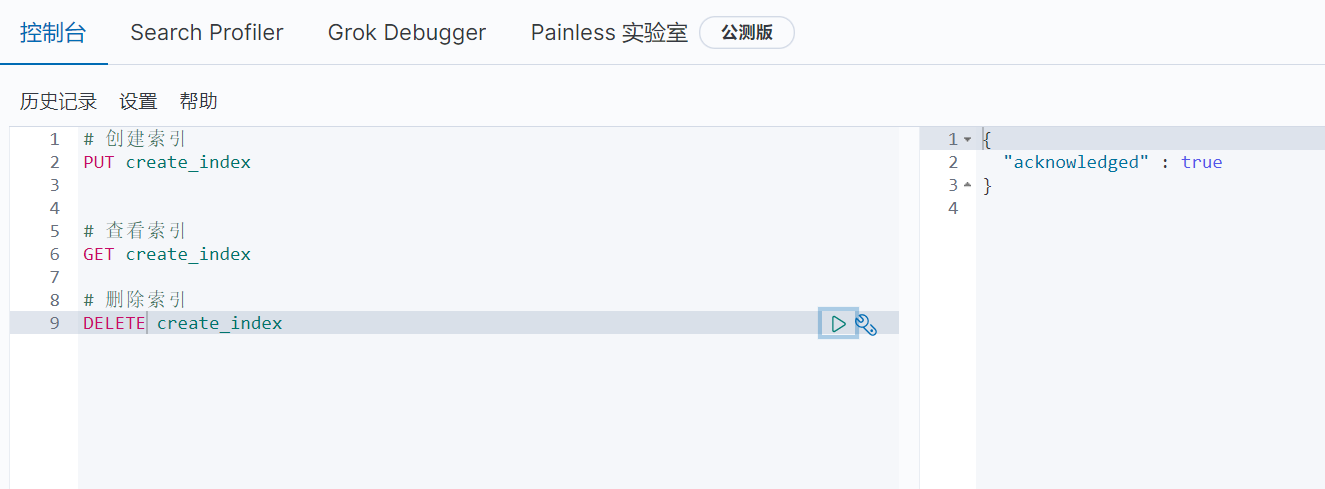
5、创建文档( 自定义id )

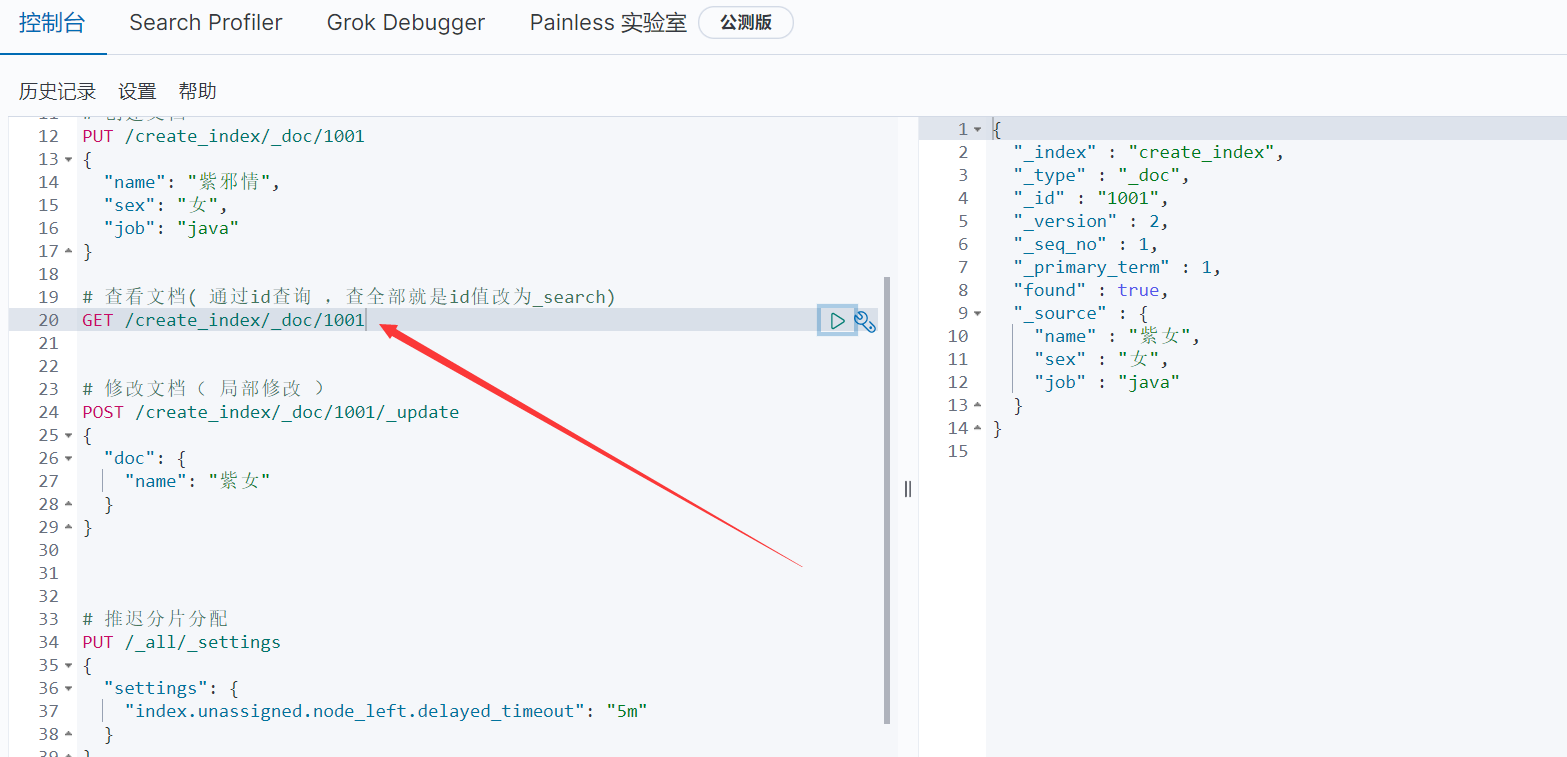
6、查看文档( 通过id查询 )
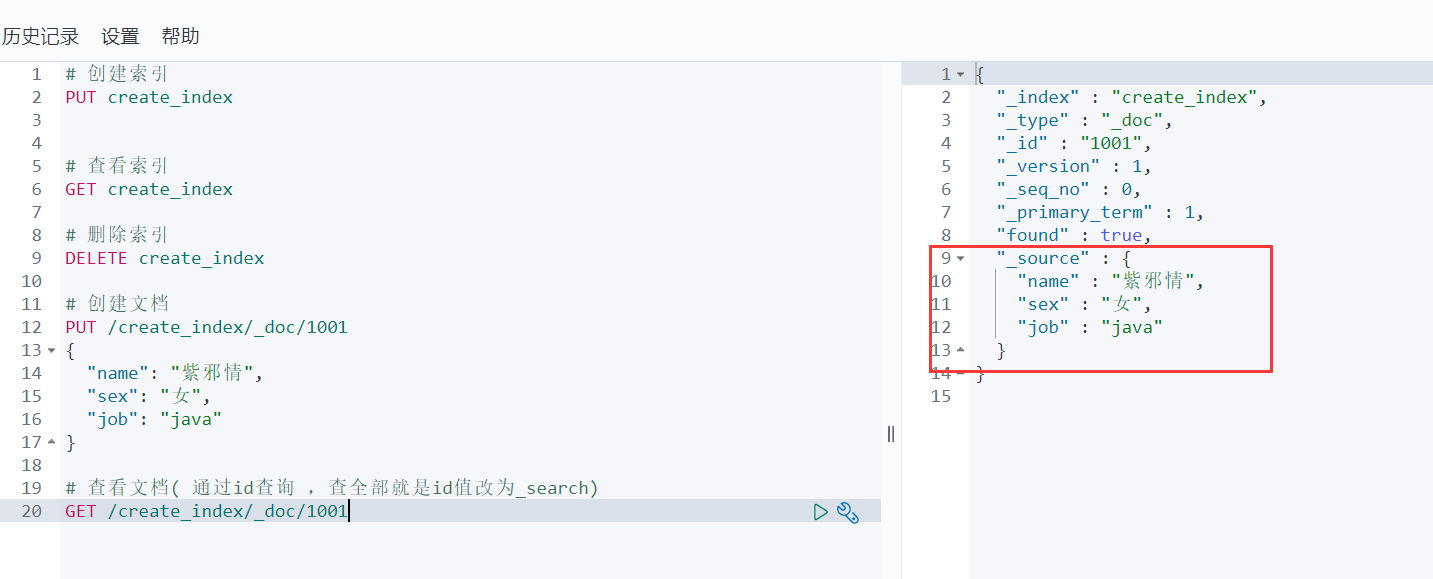
7、修改文档( 局部修改 )
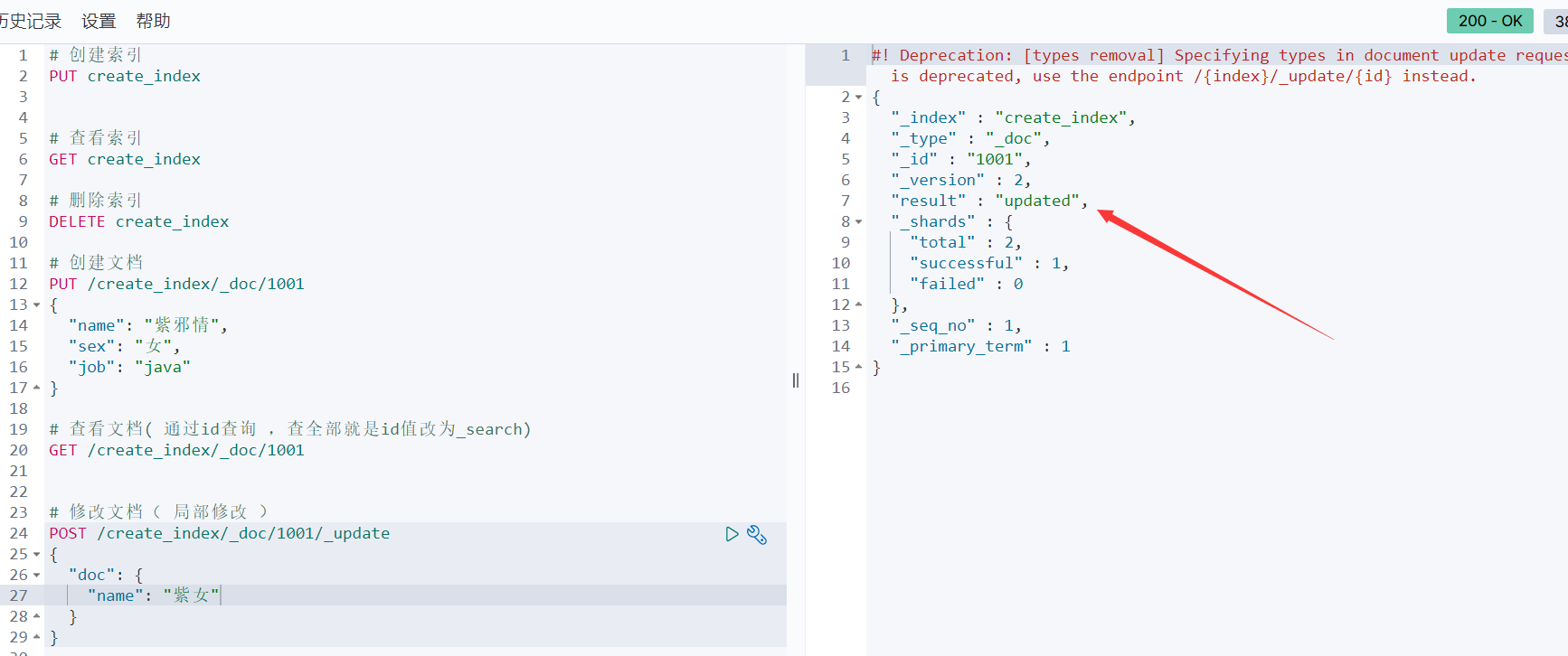
- 验证一下:
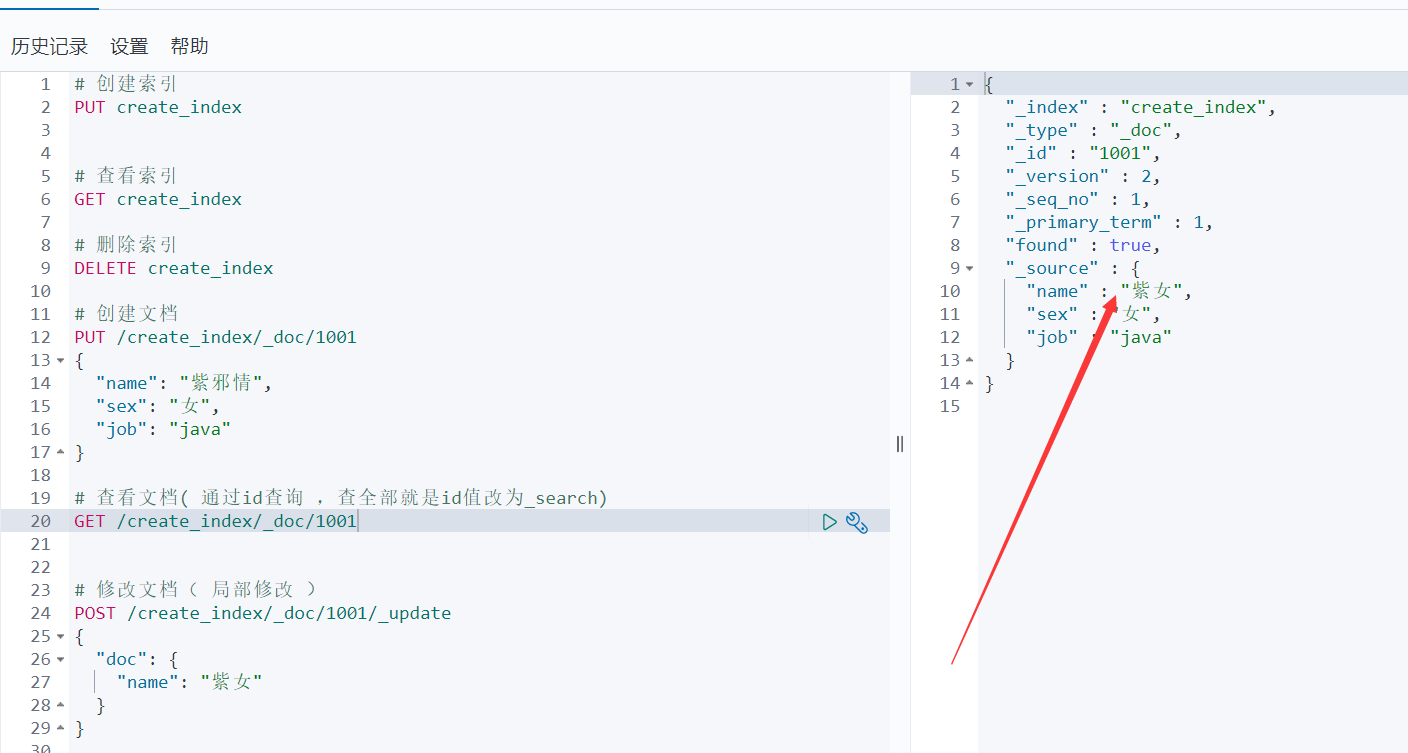
- 验证一下:
8、建字段类型
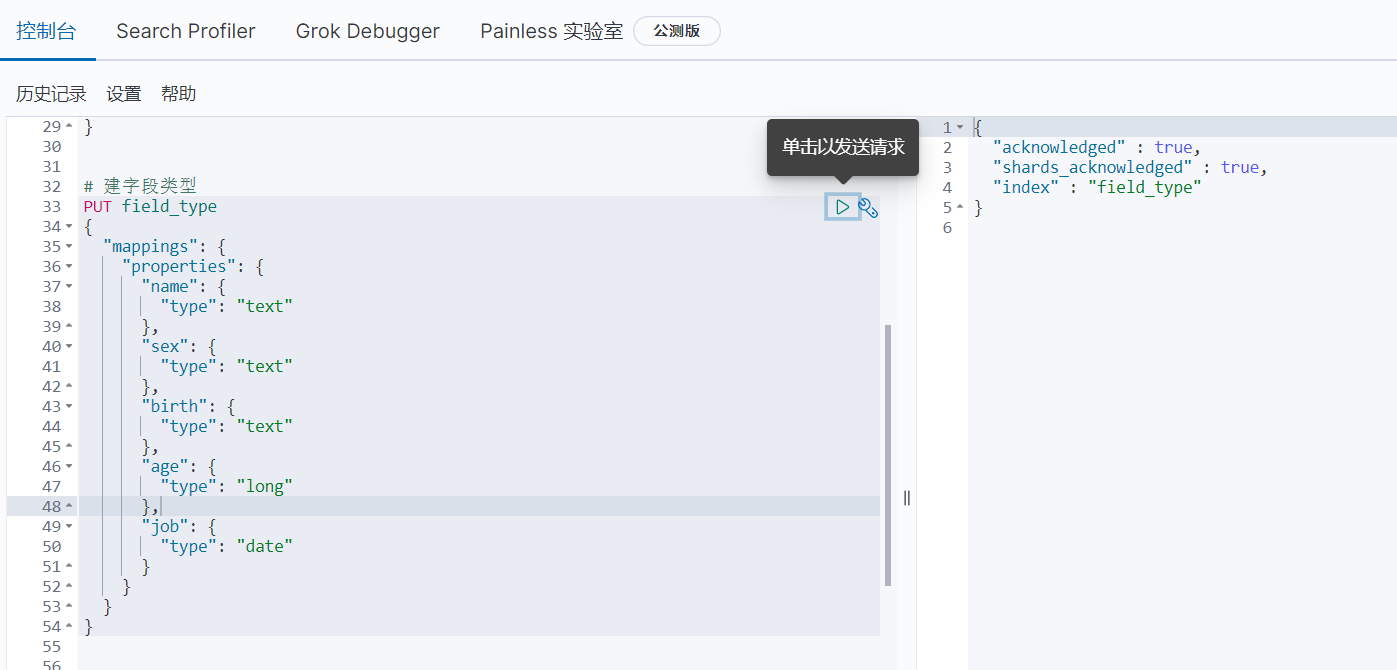
其他的也是差不多的玩法,在基础篇中怎么玩,稍微变一下就是kibana的玩法了
4.15、文档控制( 了解即可 )
所谓的文档控制就是:不断更新的情况,试想:多进程不断去更新文档,会造成什么情况?会把其他人更新过的文档进行覆盖更新了,而ES是怎么解决这个问题的?
就是弄了一个锁来实现的,和Redis一样,也是用的乐观锁来实现的,这个其实没什么好说的,只需要看一下就知道了
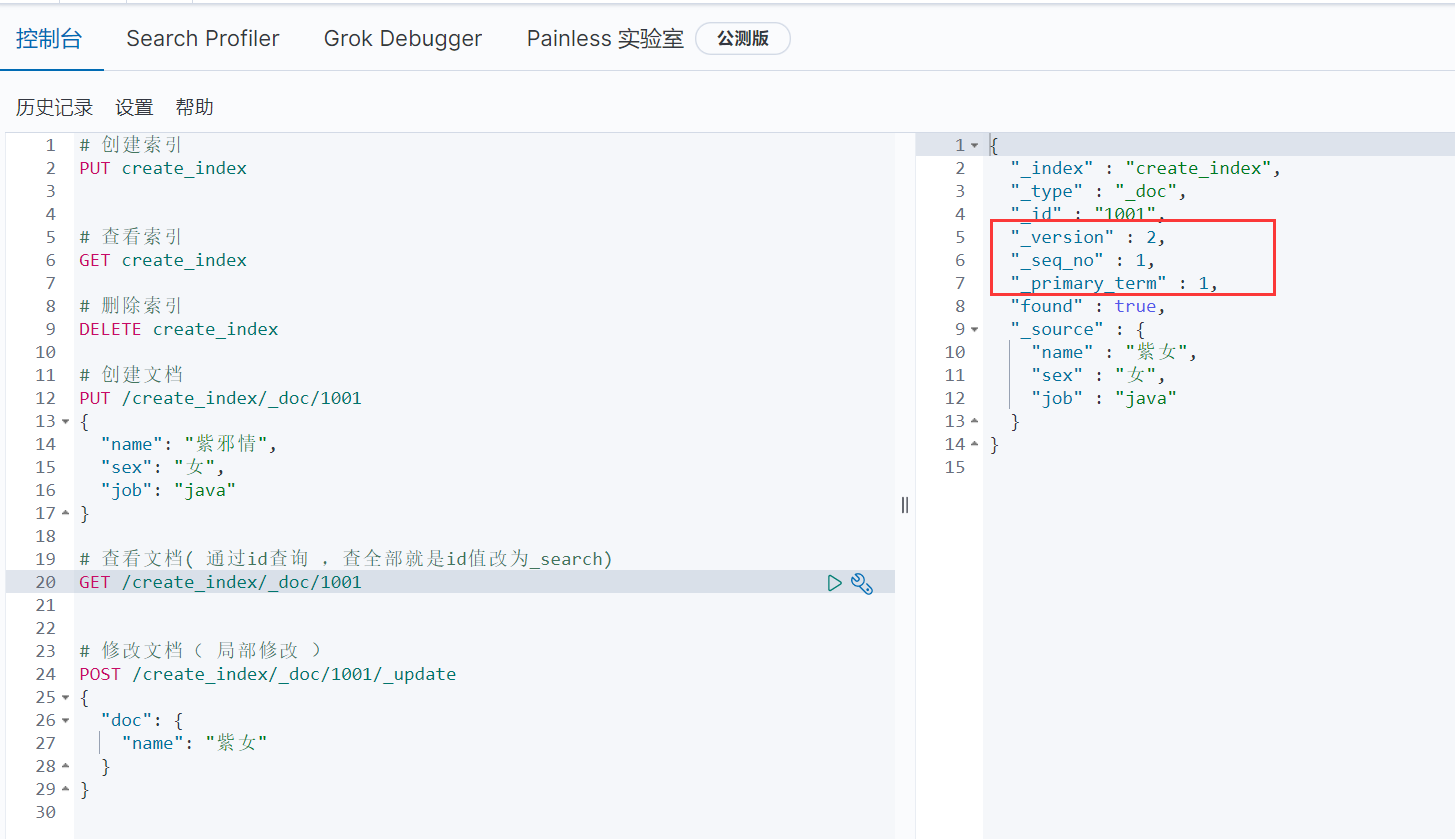
上图中·的三个字段就和锁挂钩的,version,版本号嘛,每次更新都会有一个版本号,这样就解决了多进程修改从而造成的文档冲突了( 必须等到一个进程更新完了,另一个进程才可以更新 ),当然:需要注意旧版本的ES在请求中加上version即可,但是新版本的ES需要使用 if"_seq_no" 和"if_primary_term" 来达到version的效果
4.16、ES的优化
ES的所有索引和文档数据都是存储在本地的磁盘中的,所以:磁盘能处理的吞吐量越大,节点就越稳定
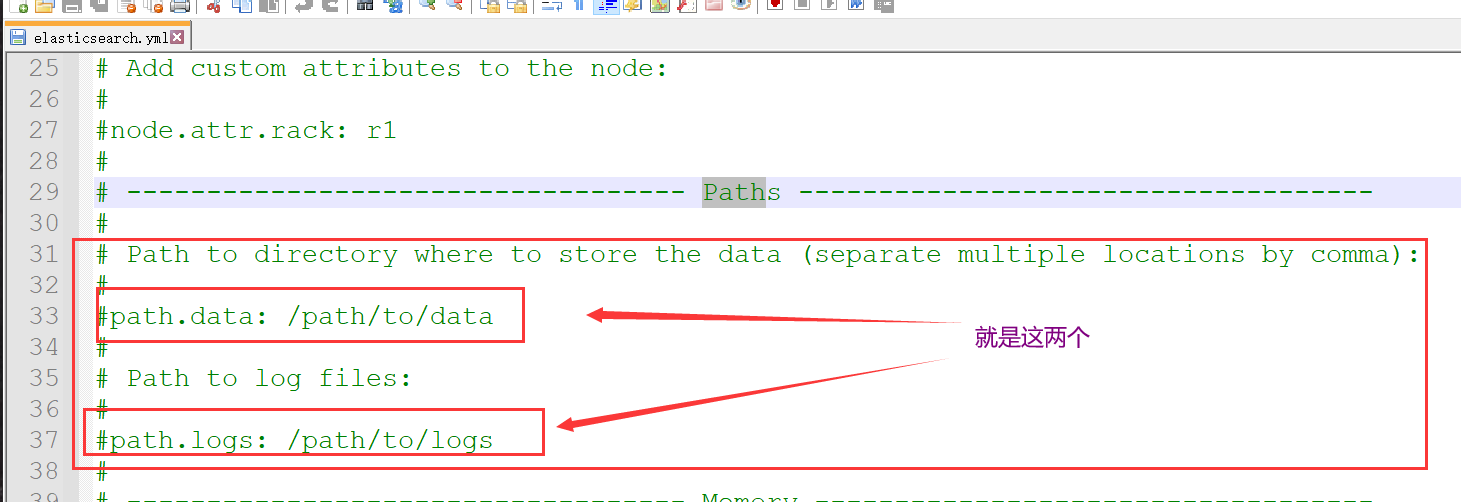
要修改的话,是在config/elasticsearch.yml中改动
4.16.1、硬件方面
1、选用固态硬盘( 即:SSD ),它比机械硬盘的好是因为:机械硬盘是通过旋转马达的驱动来进行的,所以这就会造成发热、磨损,就会影响ES的效率,而SSD是使用芯片式的闪存来存储数据的,性能比机械硬盘好得多
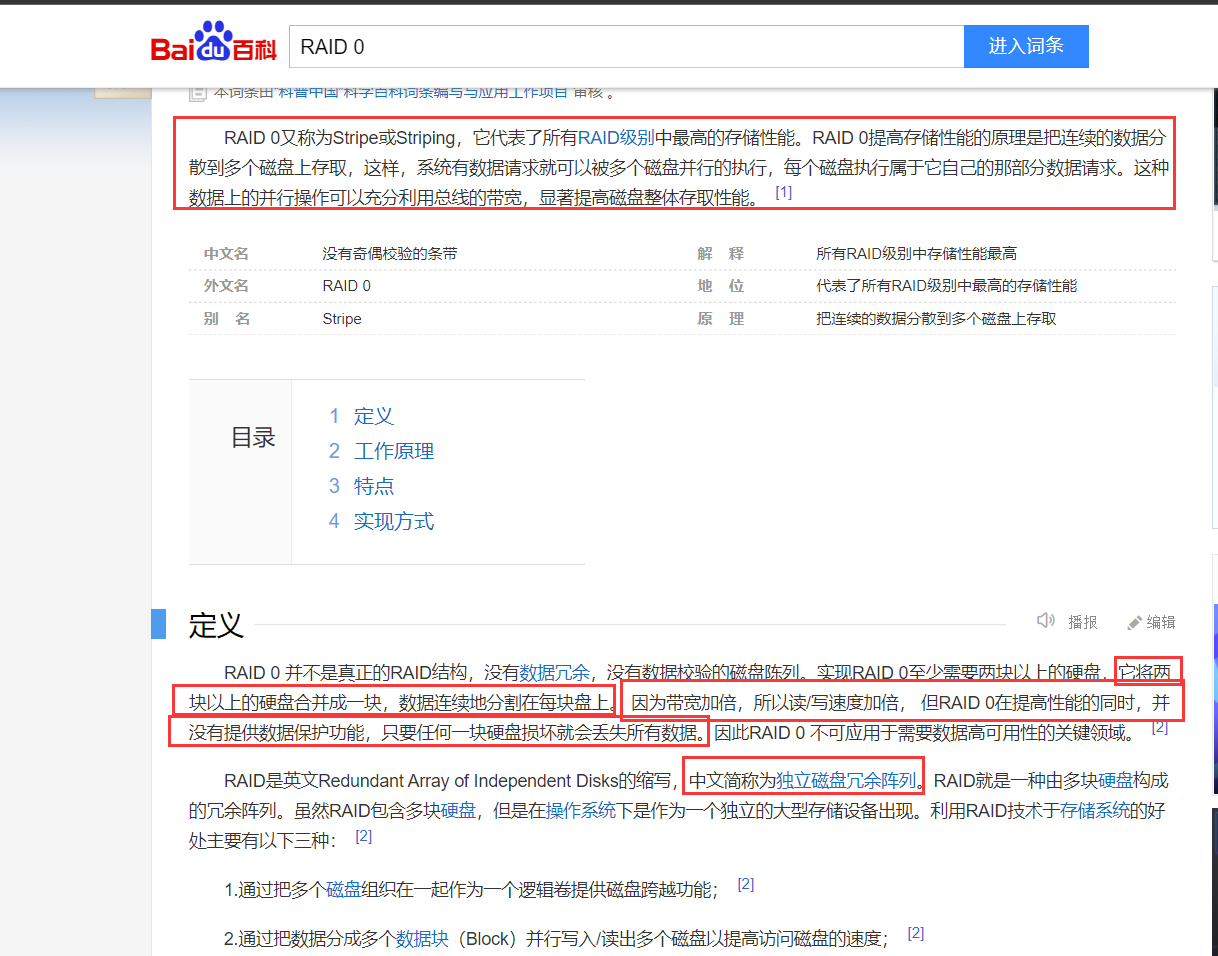
2、使用RAID 0 ( 独立磁盘冗余阵列 ),它是把连续的数据分散到多个磁盘上存取,这样,系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于它自己的那部分数据请求。这种数据上的并行操作可以充分利用总线的带宽,显著提高磁盘整体存取性能
3、由上面的RAID 0可以联想到另外一个解决方式:使用多块硬盘,也就可以达到同样的效果了( 有钱就行 ),是通过path data目录配置把数据条分配到这些磁盘上面
4、不要把ES挂载到远程上去存储
4.16.2、分片策略
- 分片和副本不是乱分配的!分片处在不同节点还可以( 前提是节点中存的数据多 ),这样就类似于关系型中分表,确实可以算得到优化,但是:如果一个节点中有多个分片了,那么就会分片之间的资源竞争,这就会导致性能降低
所以分片和副本遵循下面的原则就可以了
1、每个分片占用的磁盘容量不得超过ES的JVM的堆空间设置( 一般最大为32G ),假如:索引容量为1024G,那么节点数量为:1024 / 32 = 32左右
2、分片数不超过节点数的3倍,就是为了预防一个节点上有多个分片的情况,万一当前节点死了,那么就算做了副本,也很容易导致集群丢失数据
3、节点数 <= 主节点数 * ( 副本数 + 1 )
4、推迟分片分配
有可能一个节点宕掉了,但是后面它又恢复了,而这个节点原有数据是还在的,所以:推迟分片分配,从而减少ES的开销,具体做法如下:
PUT /_all/_settings
{
"settings": {
"index.unassigned.node_left.delayed_timeout": "5m"
}
}
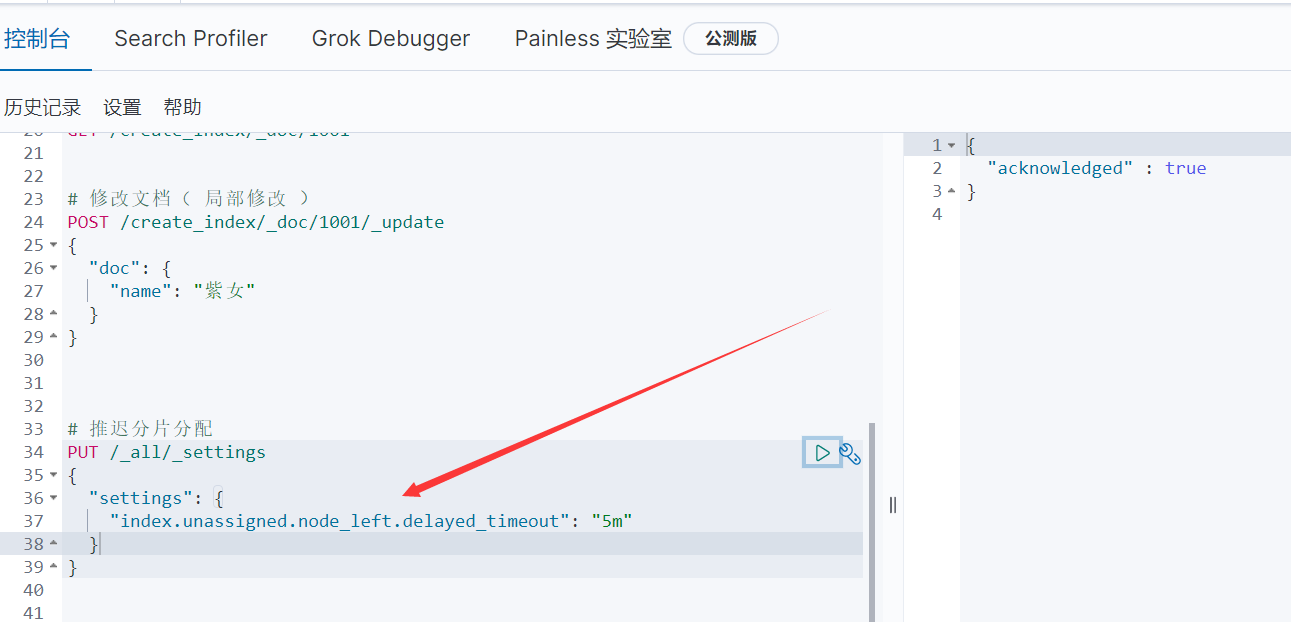
- 可以全局修改,也可以在建索引时修改
4.16.3、带路由查询
前面说过:路由计算公式
shard = hash( routing ) % number_of_primary_shards而routing默认值就是文档id,所以查询时把文档id带上,如:前面玩kibana做的操作
不带路由就会把分片和副本都查出来,然后进行轮询,这效率想都想得到会慢一点嘛
4.16.4、内存优化
修改es的config/jvm.options
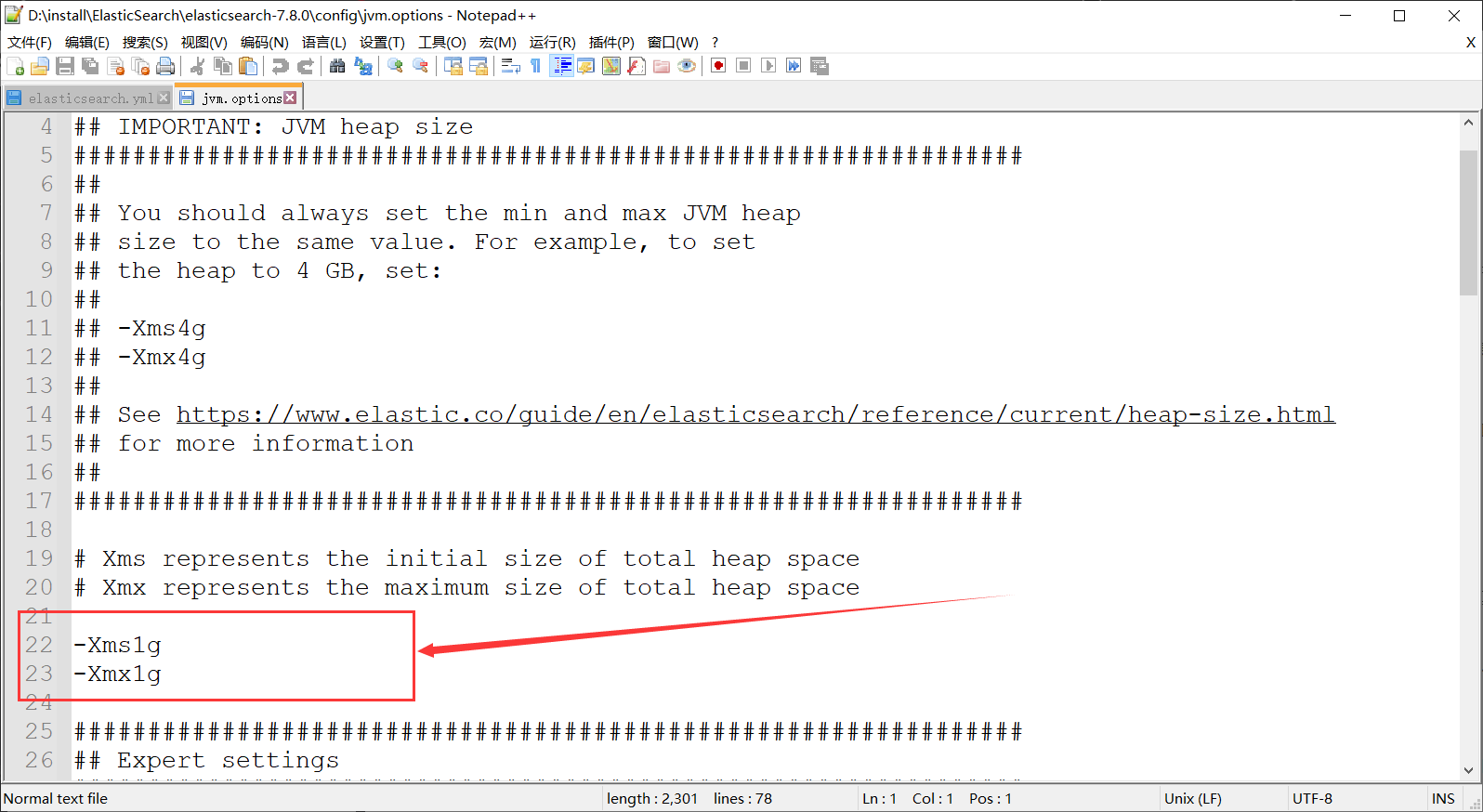
把上面的数字改了,Xms 表示堆的初始大小, Xmx 表示可分配的最大内存,ES默认是1G,这个数字在现实中是远远不够了,改它的目的是:为了能够在 Java 垃圾回收机制清理完堆内存后不需要重新分隔计算堆内存的大小而浪费资源,可以减轻伸缩堆大小带来的压力,但是也需要注意:改这两个数值,需要确保 Xmx 和 Xms 的大小是相同的,另外就是:这两个数值别操作32G啊,前面已经讲过了
4.17、附上一些配置说明
| 参数名 | 参数值 | 说明 |
|---|---|---|
| cluster.name | elasticsearch | 配置 ES 的集群名称,默认值是 ES,建议改成与所存数据相关的名称, ES 会自动发现在同一网段下的 集群名称相同的节点 |
| node.name | node-1001 | 集群中的节点名,在同一个集群中不能重复。节点 的名称一旦设置,就不能再改变了。当然,也可以 设 置 成 服 务 器 的 主 机 名 称 , 例 如 node.name: ${hostname} |
| node.master | true | 指定该节点是否有资格被选举成为 Master 节点,默 认是 True,如果被设置为 True,则只是有资格成为 Master 节点,具体能否成为 Master 节点,需要通过选举产生 |
| node.data | true | 指定该节点是否存储索引数据,默认为 True。数据的增、删、改、查都是在 Data 节点完成的 |
| index.number_of_shards | 1 | 设置索引分片个数,默认是 1 片。也可以在创建索引时设置该值,具体设置为多大值要根据数据量的大小来定。如果数据量不大,则设置成 1 时效率最高 |
| index.number_of_replicas | 1 | 设置默认的索引副本个数,默认为 1 个。副本数越多,集群的可用性越好,但是写索引时需要同步的数据越多 |
| transport.tcp.compress | true | 设置在节点间传输数据时是否压缩,默认为 False |
| discovery.zen.minimum_master_nodes | 1 | 设置在选举 Master 节点时需要参与的最少的候选主节点数,默认为 1。如果使用默认值,则当网络不稳定时有可能会出现脑裂。 合理的 数 值 为 ( master_eligible_nodes / 2 )+1 , 其 中 master_eligible_nodes 表示集群中的候选主节点数 |
| discovery.zen.ping.timeout | 3s | 设置在集群中自动发现其他节点时 Ping 连接的超时时间,同时也是选主节点的延迟时间,默认为 3 秒。 在较差的网络环境下需要设置得大一点,防止因误判该节点的存活状态而导致分片的转移 |
4.18、SpringBoot集成ES
- ES官方学习文档中有,链接是:https://www.elastic.co/guide/index.html

- 然后点击other version,选择对应的版本,如:我的是7.8
- 这里面样都有,点击:getting started看一下
- 选择maven
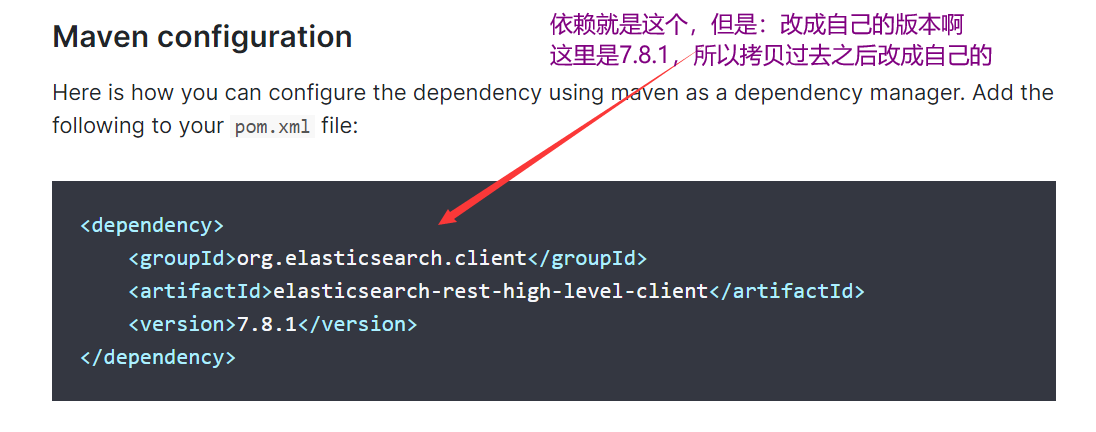
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
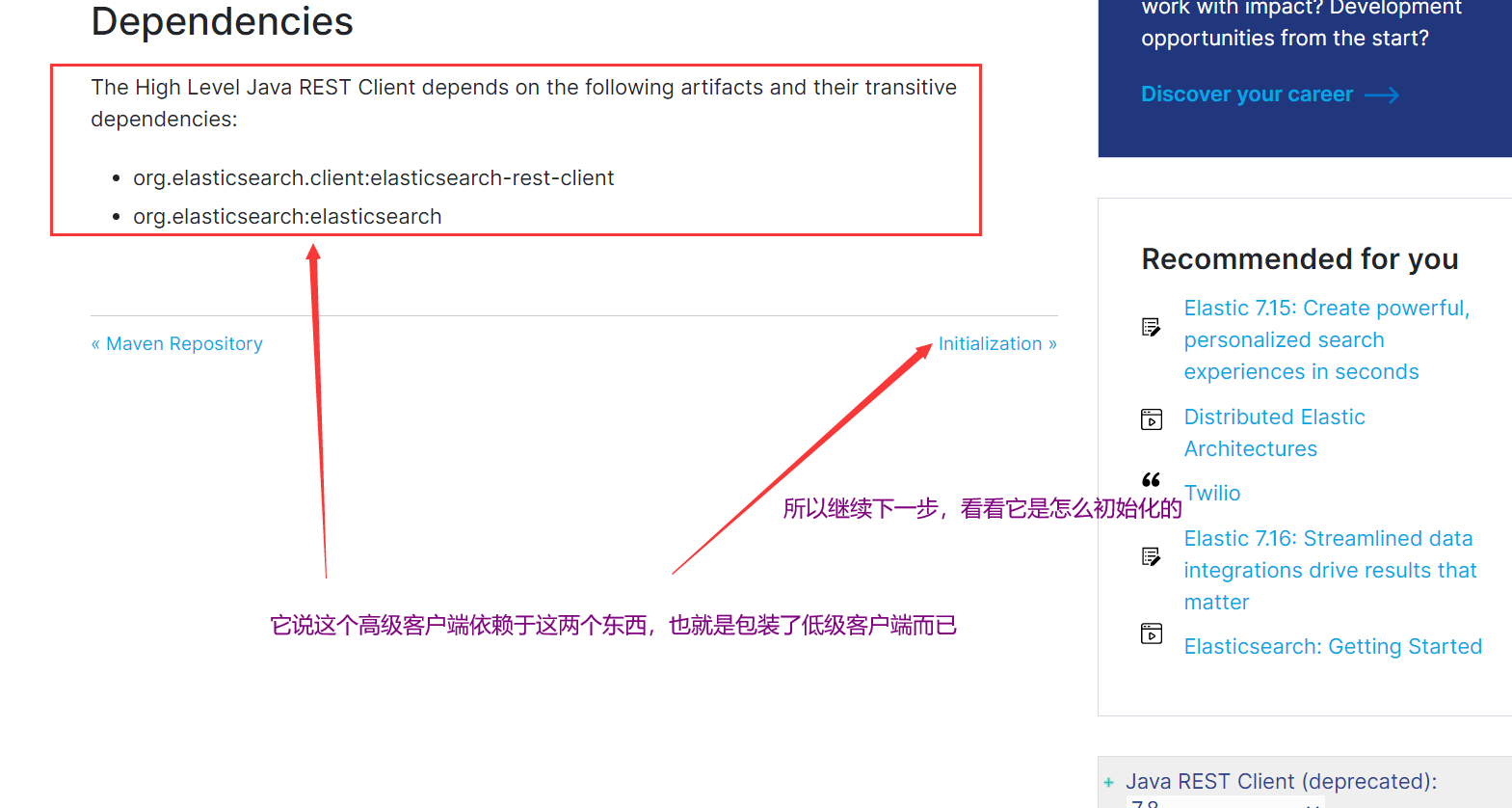
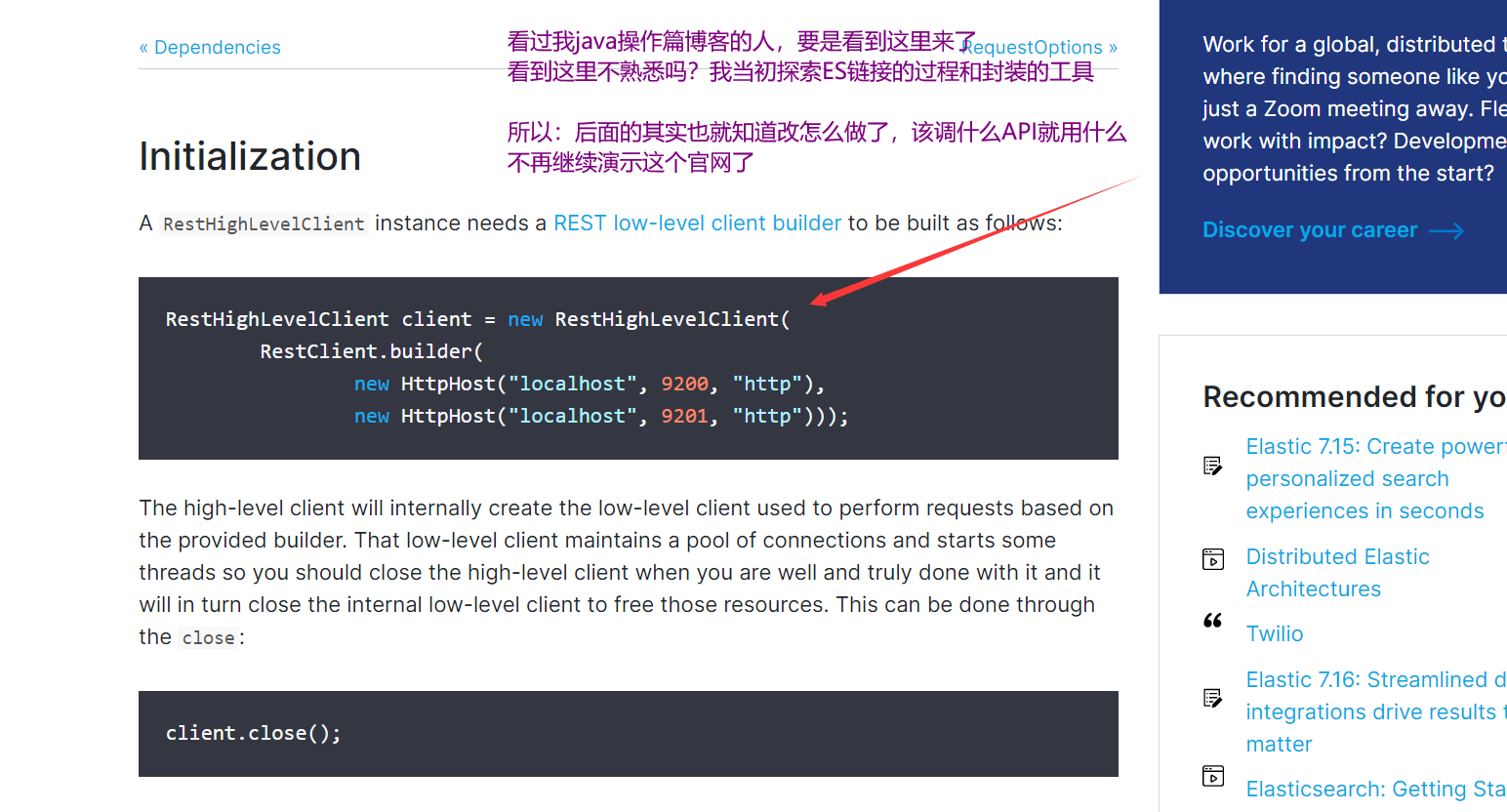
建议:有时间去研究一下官网
4.19、说一些另外的理论吧
4.19.1、ES的master主节点选举流程
1、首先选主是由ZenDiscovery来完成的( 它做了两件事:一个是Ping过程 ———— 发现节点嘛 、二是Unicast过程 ———— 控制哪些节点需要Ping通 )
2、对所有可以成为master的节点( 文件中设置的node.master: true )根据nodeId字典排序,每次“选举节点( 即:参与投票选举主节点的那个节点 )”都把自己知道的节点排一次序,就是把排好序的第一个节点( 第0位 )认为是主节点( 投一票 )
3、当某个节点的投票数达到一个值时( ( 可以成为master节点数n / 2 ) + 1 ),而该节点也投自己,那么这个节点就是master节点,否则重新开始,直到选出master
另外注意:master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理;data节点可以关闭http功能
4.19.2、ES的集群脑裂问题
导致的原因:
- 网络问题:集群间的网络延迟导致一些节点访问不到master, 认为master 挂掉了从而选举出新的master,并对master上的分片和副本标红,分配新的主分片
- 节点负载:主节点的角色既为master又为data,访问量较大时可能会导致ES停止响应造成大面积延迟,此时其他节点得不到主节点的响应认为主节点挂掉了,会重新选取主节点
- 内存回收:data 节点上的ES进程占用的内存较大,引发JVM的大规模内存回收,造成ES进程失去响应
脑裂问题解决方案:
减少误判:discovery.zen ping_ timeout 节点状态的响应时间,默认为3s,可以适当调大,如果master在该响应时间的范围内没有做出响应应答,判断该节点已经挂掉了。调大参数( 如6s,discovery.zen.ping_timeout:6 ),可适当减少误判
选举触发:discovery.zen.minimum. master nodes:1,该参數是用于控制选举行为发生的最小集群主节点数量。当备选主节点的个數大于等于该参数的值,且备选主节点中有该参数个节点认为主节点挂了,进行选举。官方建议为(n / 2) +1, n为主节点个数(即有资格成为主节点的节点个数)
角色分离:即master节点与data节点分离,限制角色
- 主节点配置为:node master: true,node data: false
- 从节点置为:node master: false,node data: true
4 - 基于ELK的ElasticSearch 7.8.x技术整理 - 高级篇( 续 ) - 更新完毕的更多相关文章
- 3 - 基于ELK的ElasticSearch 7.8.x技术整理 - 高级篇( 偏理论 )
4.ES高级篇 4.1.集群部署 集群的意思:就是将多个节点归为一体罢了( 这个整体就有一个指定的名字了 ) 4.1.1.window中部署集群 - 了解即可 把下载好的window版的ES中的dat ...
- 1 - 基于ELK的ElasticSearch 7.8.x 技术整理 - 基础语法篇 - 更新完毕
准备工作 0.什么是ElasticSearch?它和Lucene以及solr的关系是什么? 这些是自己的知识获取能力,自行百度百科 1.下载ElasticSearch的window版,linux版后续 ...
- 2 - 基于ELK的ElasticSearch 7.8.x技术整理 - java操作篇 - 更新完毕
3.java操作ES篇 3.1.摸索java链接ES的流程 自行创建一个maven项目 3.1.1.依赖管理 点击查看代码 <properties> <ES-version>7 ...
- 基于ELK5.1(ElasticSearch, Logstash, Kibana)的一次整合测试
前言开源实时日志分析ELK平台(ElasticSearch, Logstash, Kibana组成),能很方便的帮我们收集日志,进行集中化的管理,并且能很方便的进行日志的统计和检索,下面基于ELK的最 ...
- 基于ELK5.1(ElasticSearch, Logstash, Kibana)的一次整合
前言开源实时日志分析ELK平台(ElasticSearch, Logstash, Kibana组成),能很方便的帮我们收集日志,进行集中化的管理,并且能很方便的进行日志的统计和检索,下面基于ELK的最 ...
- 基于ELK的简单数据分析
原文链接: http://www.open-open.com/lib/view/open1455673846058.html 环境 CentOS 6.5 64位 JDK 1.8.0_20 Elasti ...
- 基于ELK进行邮箱访问日志的分析
公司希望能够搭建自己的日志分析系统.现在基于ELK的技术分析日志的公司越来越多,在此也记录一下我利用ELK搭建的日志分析系统. 系统搭建 系统主要是基于elasticsearch+logstash+f ...
- 从0搭建一个基于 ELK 的日志、指标收集与监控系统
为了使得私有化部署的系统能更健壮,同时不增加额外的部署运维工作量,本文提出了一种基于 ELK 的开箱即用的日志和指标收集方案. 在当前的项目中,我们已经使用了 Elasticsearch 作为业务的数 ...
- ELK stack elasticsearch/logstash/kibana 关系和介绍
ELK stack elasticsearch 后续简称ES logstack 简称LS kibana 简称K 日志分析利器 elasticsearch 是索引集群系统 logstash 是日志归集集 ...
随机推荐
- Linux学习 - 文件系统属性chattr权限
change file attributes on 啊linux file system 1 功能 可以防止误操作 2 chattr命令格式 chattr [+-=] [选项] 文件或目录名 + 增加 ...
- navigationItem的leftBarButtonItem和rightBarButtonItem隐藏
- (void)showEdit { if (不符合显示条件) { self.navigationItem.rightBarButtonItem.customView.hidden = YES; // ...
- Zookeeper客户端链接
一.zkCli.sh ./zkCli.sh -server 39.97.176.160:2182 39.97.176.160 : zookeeper服务器Ip 2182:zookeeper端口 二.Z ...
- 【Linux】【Services】【SaaS】Docker+kubernetes(8. 安装和配置Kubernetes)
1. 概念 1.1. 比较主流的任务编排系统有mesos+marathon,swarm,openshift(红帽内部叫atom服务器)和最著名的kubernetes,居然说yarn也行,不过没见过谁用 ...
- 【Linux】【Shell】【Basic】数组
1. 数组: 变量:存储单个元素的内存空间: 数组:存储多个元素的连续的内存空间: 数组名:整个数组只有一个名字: 数组 ...
- 常用 HTTP 状态码
下面是列举的我在项目中用到过的一些 HTTP 状态码,当然,在具体的使用中并不是用到的状态码越多越好,需要结合自己项目情况来选用适合自己的 HTTP 状态码. HTTP 状态码 含义说明 200 ...
- java使用在线api实例
字符串 strUrl为访问地址和参数 public String loadAddrsApi() { StringBuffer sb; String strUrl = "https://api ...
- python的随机森林模型调参
一.一般的模型调参原则 1.调参前提:模型调参其实是没有定论,需要根据不同的数据集和不同的模型去调.但是有一些调参的思想是有规律可循的,首先我们可以知道,模型不准确只有两种情况:一是过拟合,而是欠拟合 ...
- Iphone开源项目汇总
扫描wifi信息: http://code.google.com/p/uwecaugmentedrealityproject/ http://code.google.com/p/iphone-wire ...
- 我在这里的处女篇(Word技巧集团)
传说这里的文章可以在Word上打好了发布,Word嘛,有[听写]功能,不用打字了: 写好的文章还可以[大声朗读],边听边看最容易找"通假字"了. 冲这,我的新阵地就定这里了,哈哈~