大数据-Hadoop 本地运行模式
Grep案例
1. 创建在hadoop-2.7.2文件下面创建一个input文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir input
2. 将Hadoop的xml配置文件复制到input
[atguigu@hadoop101 hadoop-2.7.2]$ cp etc/hadoop/*.xml input

3. 执行share目录下的MapReduce程序(执行)
[atguigu@hadoop101 hadoop-2.7.2]$ bin/hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+'(要正常的运行,必须要保证output删除,没有才能运行)

4. 查看输出结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat output/*

WordCount案例
1. 创建在hadoop-2.7.2文件下面创建一个wcinput文件夹
[atguigu@hadoop101 hadoop-2.7.2]$ mkdir wcinput
2. 在wcinput文件下创建一个wc.input文件
[atguigu@hadoop101 hadoop-2.7.2]$ cd wcinput
[atguigu@hadoop101 wcinput]$ touch wc.input
3. 编辑wc.input文件
[atguigu@hadoop101 wcinput]$ vi wc.input
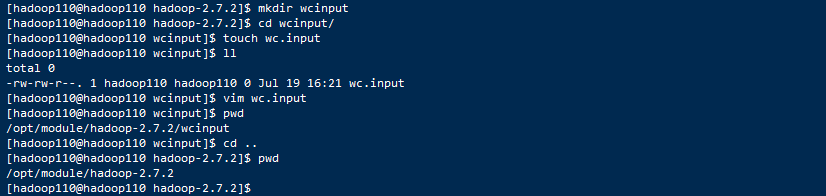
保存退出::wq
4. 回到Hadoop目录/opt/module/hadoop-2.7.2
5. 执行程序
[atguigu@hadoop101 hadoop-2.7.2]$ hadoop jar
share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput wcoutput

6. 查看结果
[atguigu@hadoop101 hadoop-2.7.2]$ cat wcoutput/part-r-00000

大数据-Hadoop 本地运行模式的更多相关文章
- hadoop本地运行模式调试
一:简介 最近学习hadoop本地运行模式,在运行期间遇到一些问题,记录下来备用:以运行hadoop下wordcount为例子. hadoop程序是在集群运行还是在本地运行取决于下面两个参数的设置,第 ...
- 大数据Hadoop入门视频教程:Hadoop的快如入门
最新在学习hadoop .storm大数据相关技术,发现网上hadoop .storm 相关学习视频少之又少,这里整理了传智播客段海涛老师的hadoop学习视频,出来给大家学习交流. 视频下载地址:h ...
- 2 weekend110的mapreduce介绍及wordcount + wordcount的编写和提交集群运行 + mr程序的本地运行模式
把我们的简单运算逻辑,很方便地扩展到海量数据的场景下,分布式运算. Map作一些,数据的局部处理和打散工作. Reduce作一些,数据的汇总工作. 这是之前的,weekend110的hdfs输入流之源 ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- Hadoop大数据学习视频教程 大数据hadoop运维之hadoop快速入门视频课程
Hadoop是一个能够对大量数据进行分布式处理的软件框架. Hadoop 以一种可靠.高效.可伸缩的方式进行数据处理适用人群有一定Java基础的学生或工作者课程简介 Hadoop是一个能够对大量数据进 ...
- Hadoop之运行模式
Hadoop运行模式包括:本地模式.伪分布式以及完全分布式模式. 一.本地运行模式 1.官方Grep案例 1)在hadoop-2.7.2目录下创建一个 input 文件夹 [hadoop@hadoop ...
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- hadoop本地运行与集群运行
开发环境: windows10+伪分布式(虚拟机组成的集群)+IDEA(不需要装插件) 介绍: 本地开发,本地debug,不需要启动集群,不需要在集群启动hdfs yarn 需要准备什么: 1/配置w ...
- 我要进大厂之大数据Hadoop HDFS知识点(1)
01 我们一起学大数据 老刘今天开始了大数据Hadoop知识点的复习,Hadoop包含三个模块,这次先分享出Hadoop中的HDFS模块的基础知识点,也算是对今天复习的内容进行一次总结,希望能够给想学 ...
随机推荐
- shell基础之exit,break,continue
exit代码: 1 #!/bin/bash 2 echo "Is it morning? Please answer yes or no." 3 read YES_OR_NO 4 ...
- python 从2个文件中提取不相同的内容并输出到第三个文件中
#-*- coding: UTF-8 -*- import re import sys import os str1=[] str2=[] str_dump=[] fa=open("A. ...
- Linux下记录登录用户历史操作
前言:众所周知Linux是一个可以同时让多个用户登录的操作系统,每个用户的操作都影响着Linux运行,除了要做好安全工作以外,防止人为恶意损坏也是很关键的,比如有人恶意执行危险命令,要查找就得记录所有 ...
- TensorFlow Keras API用法
TensorFlow Keras API用法 Keras 是与 TensorFlow 一起使用的更高级别的作为后端的 API.添加层就像添加一行代码一样简单.在模型架构之后,使用一行代码,可以编译和拟 ...
- 【Java实现】剑指offer53.1——在排序数组中查找数字(LeetCode34:在排序数组中查找元素的起始位置)
序数组中查找元素的起始位置):思路分享 <剑指offer>题目和LeetCode主站本质是一样的,想要找到target数目,也需要找到左右边界 题目解析: 在一个排序数组中,找到targe ...
- 「题解」300iq Contest 2 B Bitwise Xor
本文将同步发布于: 洛谷博客: csdn: 博客园: 简书. 题目 题目链接:gym102331B. 题意概述 给你一个长度为 \(n\) 的序列 \(a_i\),求一个最长的子序列满足所有子序列中的 ...
- .h5图像文件(数据集)的读取并存储 工具贴(二)
概述 H5文件是层次数据格式第5代的版本(Hierarchical Data Format,HDF5),它是用于存储科学数据的一种文件格式和库文件.由美国超级计算中心与应用中心研发的文件格式,用以存储 ...
- Redisson 分布式锁实现之前置篇 → Redis 的发布/订阅 与 Lua
开心一刻 我找了个女朋友,挺丑的那一种,她也知道自己丑,平常都不好意思和我一块出门 昨晚,我带她逛超市,听到有两个人在我们背后小声嘀咕:"看咱前面,想不到这么丑都有人要." 女朋友 ...
- ElGamal算法
简介 ElGamal算法可以用于加密和签名,其安全性依赖于计算有限域上离散对数的难度. ElGamal密钥 生成密钥对时,首先选择素数p,两个随机数g和x,g和x都小于p,然后计算: y = g ^ ...
- Spring Boot WebFlux-10——WebFlux 实战图书管理系统
前言 本篇内容我们会实现如下图所示的城市管理系统,因为上面案例都用的是 City,所以这里直接使用城市作为对象,写一个简单的城市管理系统,如图所示: 结构 类似上面讲的工程搭建,新建一个工程编写此案例 ...