多元统计之因子分析模型及Python分析示例
1. 简介
- 因子分析是一种研究观测变量变动的共同原因和特殊原因, 从而达到简化变量结构目的的多元统计方法.
- 因子分析模型是主成分分析的推广, 也是利用降维的思想, 将复杂的原始变量归结为少数几个综合因子的一种多变量统计分析方法.
1.1 应用
- 寻求变量的基本结构, 简化变量系统.
- 用于分类, 根据因子得分值, 在因子轴所构成的空间中将变量或者样本进行分类 (能够分析样品间差异的原因).
1.2 类型
- R型因子分析: 研究变量之间的相关关系.
- Q型因子分析: 研究样本之间的相关关系.
2. 因子分析模型
- 因子分析模型主要涉及矩阵的相关运算.
- 在日常分析中使用最多的就是 R 型因子分析, 下面也将主要介绍 R 型因子的分析模型, 可以对比 Q 型因子分析模型加强对模型的理解.
2.1 因子分析的数学模型
2.1.1 R 型因子分析模型
- 概述:
- R型因子分析是将每一个变量都表示成公共因子的线性函数与特殊因子之和, 即
\[X_i = a_{i1}F_1 + a_{i2}F_2 + \cdots + a_{im}F_m + \epsilon_i, \quad (i=1,2,\cdots, p) \tag{2.1.1-1}
\]上式中的\(F_1,F_2,\cdots,F_m\)称为公共因子, \(\epsilon_i\)称为\(X_i\)的特殊因子。该模型可用矩阵表示为:
\[X = AF + \epsilon
\]\[\begin{bmatrix}
X_1 \\
X_2 \\
\vdots \\
X_p
\end{bmatrix} =
\begin{bmatrix}
\epsilon_1 \\
\epsilon_2 \\
\vdots \\
\epsilon_p
\end{bmatrix} + A_{p \times m}\begin{bmatrix}
F_1 \\
F_2 \\
\vdots \\
F_m
\end{bmatrix} \tag{2.1.1-2}
\]- 构造模型满足:
- \(m \le p\)
- \(Cov(F, \epsilon) = 0\), 即公共因子与特殊因子是不相关的
- \(D_F = D(F) = I_m\), 即各个公共因子不相关且方差为1
- 各个特殊因子不相关, 方差不要求相等
\[D_{\epsilon} = D(\epsilon) = \begin{bmatrix}
\sigma_1^2 & & & 0 \\
& \sigma_2^2 & & \\
& & \ddots & \\
0 & & & \sigma_p^2
\end{bmatrix}\]\[D_{\epsilon} = D(\epsilon) = \begin{bmatrix}
\sigma_1^2 & & & 0 \\
& \sigma_2^2 & & \\
& & \ddots & \\
0 & & & \sigma_p^2
\end{bmatrix}\] - 公共因子(潜在因子)是不可观测变量且只存在于某种理论意义之中, 可理解为在高维空间中的互相垂直的m个坐标轴。虽然潜在变量不能直接测得, 但它一定与某些可测变量有着某种程度的关联。
2.1.2 Q 型因子分析 (因子得分)
- 概述:
- 类似地, Q 型因子分析数学模型可表示为:
\[X_i = a_{i1}F_1 + a_{i2}F_2 + \cdots + a_{im}F_m + \epsilon_i, \quad (i=1,2,\cdots, n) \tag{2.1.1-3}
\]- Q型因子分析与R型因子分析模型的差体现在\(X_1, X_2, \cdots, X_n\)表示的是n个样品。
2.2 主成分分析与因子分析的异同
- 相同点:
- R 型或 Q 型因子分析都用公因子 F 代替 X, 一般要求\(m<p, m<n\), 因此因子分析与主成分分析一样, 也是一种降低变量维度数的方法.
- 因子分析求解过程同主成分分析类似, 也是从一个协方差阵出发的.
- 区别:
- 主成分分析的数学模型本质上是一种线性变化, 将原始坐标变换到变异程度大的方向, 突出数据变异的方向, 归纳重要信息。
- 因子分析从本质上看是从显在变量去 "提炼" 潜在因子的过程。并且因子的形式也不是唯一确定的。一般来说, 作为 "自变量" 的因子\(F_1,F_2,\cdots,F_m\)是不可直接观测的.
2.3 因子载荷阵
2.3.1 因子载荷阵不唯一的原因
- 变量X的协差阵\(\Sigma\)的分解式为
D(X) & = D(AF + \epsilon) = E[(AF + \epsilon)(AF + \epsilon)'] \\
& = AE(FF')A' + AE(F\epsilon') + E(\epsilon F')A' + E(\epsilon\epsilon') \\
& = AD(F)A' + D(\epsilon) \\
& = AA' + D(\epsilon)
\end{aligned}
\]
如果X为标准化的随机向量, 则\(\Sigma\)就是相关矩阵\(R = (\rho_{ij}), 即R = AA' + D_{\epsilon}\)
- 对于\(m \times m\)的正交矩阵T, 令\(A^* = AT, F^* = T'F\), 模型可表示为: \(X = A^*F^* + \epsilon\)
由于\[Cov(F^*, \epsilon) = E(F^*\epsilon') = T'E(F\epsilon') = 0 \\
D(F^*) = T'D(F)T = T'T = I_{m \times m}\]所以仍满足模型的条件
同样\(\Sigma\)也可以分解为\(\Sigma = A^*A^{*'} + D_{\epsilon}\)
2.3.2 因子载荷阵的统计意义
- 因子载荷\(a_{ij}\)的统计意义
- 对于因子模型
\[X_i = a_{i1}F_1 + a_{i2}F_2 + \cdots + a_{ij}F_j + \cdots + a_{im}F_m + \epsilon_i \quad (i=1,2,\cdots,p)
\]- 可得\(X_i与F_j\)的协方差为:
\[\begin{aligned}
Cov(X_i,F_j) & = Cov(\sum_{k=1}^ma_{ik}F_k + \epsilon, F_j) \\
& = Cov(\sum_{k=1}^ma_{ik}F_k, F_j) + Cov(\epsilon_i, F_j) \\
& = a_{ij}
\end{aligned}\]- 若对\(X_i\)做了标准化处理, \(X_i\)的标准差为1, 且\(F_j\)的标准差为1, 有
\[r_{X_i,F_j} = \frac{Cov(X_i,F_j)}{\sqrt{D(X_i)}\sqrt{D(F_j)}} = Cov(X_i,F_j) = a_{ij}
\]- 那么, 对于标准化后的\(X_i\), \(a_{ij}\)是\(X_i\)与\(F_j\)的相关系数, 表示\(X_i\)依赖\(F_j\)的分量(比重)。因此统计学上也称其为权。
- 历史原因, 心理学家将它叫做载荷, 表示第i个变量在第j个公共因子上的载荷, 反应了第i个变量在第j个公共因子上的相对重要性.
- 变量共同度的统计意义
- 由因子模型, 知
\[\begin{aligned}
D(X_i) & = a_{i1}^2D(F_1) + a_{i2}^2D(F_2) + \cdots + a_{im}^2D(F_m) + D(\epsilon_i) \\
& = a_{i1}^2 + a_{i2}^2 + \cdots + a_{im}^2 + D(\epsilon_i) \\
& = h_i^2 + \sigma_i^2
\end{aligned}\]- 变量\(X_i\)的共同度为: \(h_i^2 = \sum_{j=1}^ma_{ij}^2 \quad i=1,2,\cdots,p\)
- 如果对\(X_i\)作了标准化处理, 有
\]
- 公因子\(F_i\)的方差贡献率\(g_j^2\)的统计意义
- 设因子载荷矩阵为\(A\), 称第j列元素的平方和, 即:
\[g_j^2 = \sum_{i=1}^pa_{ij}^2 \quad j=1,2,\cdots,m
\]为公共因子\(F_j\)对X的贡献, 即\(g_j^2\)表示同一个公共因子\(F_j\)对各变量所提供的方差贡献之总和, 反映该因子对全部变量的总影响
- 它是衡量每一个公共因子相对重要性的一个尺度。公共因子\(F_j\)的相对重要性可用\(g_j^2/h\)来衡量, 它称为公共因子\(F_j\)对X的贡献率.
- 因子分析的目的就是要由原始随机向量的协差阵\(\Sigma\)或相关阵\(R\)求出因子分析模型的解, 即求出载荷阵\(A\)和特性方差阵\(D_\epsilon\), 并给公因子赋予有实际背景的解释.
3. 因子载荷矩阵求解
3.1 主成分法
- 概述:
- 在进行因子分析之前先对数据进行一次主成分分析, 然后把前几个主成分作为未旋转的公共因子。
- 该方法所得的特殊因子\(\epsilon_1,\epsilon_2,\cdots,\epsilon_p\)之间并不相互独立, 不完全符合因子模型的假设前提。
- 当共同度较大时, 特殊因子所起的作用较小, 特殊因子之间的相关性所带来的影响几乎可以忽略。
3.1.1 求解方法
- 假定从相关阵出发求解主成分, 设有p个变量, 则可以找出p个主成分\(Y_1,Y_2,\cdots,Y_p\)(按由大到小顺序排列), 则主成分与原始变量之间存在如下关系式:
\[\begin{cases}
Y_1 = \gamma_{11}X_1 + \gamma_{12}X_2 + \cdots + \gamma_{1p}X_p \\
Y_2 = \gamma_{21}X_1 + \gamma_{22}X_2 + \cdots + \gamma_{2p}X_p \\
\cdots\cdots \\
Y_p = \gamma_{p1}X_1 + \gamma_{p2}X_2 + \cdots + \gamma_{pp}X_p \\
\end{cases} \tag{3.1.1-1}
\]式中, \(\gamma_ij\)为随机变量X的相关矩阵的特征根所对应的特征向量的分量, 因为特征向量之间彼此正交, 从X到Y的转换关系式可逆的, 则可得出由Y到X的转换关系为:
\[ \begin{cases}
X_1 = \gamma_{11}Y_1 + \gamma_{21}Y_2 + \cdots + \gamma_{p1}Y_p \\
X_2 = \gamma_{12}Y_1 + \gamma_{22}Y_2 + \cdots + \gamma_{p2}Y_p \\
\cdots\cdots \\
X_p = \gamma_{1p}Y_1 + \gamma_{2p}Y_2 + \cdots + \gamma_{pp}Y_p \\
\end{cases} \tag{3.1.1-2}
\]对上面每一等式只保留前m个主成分而把后面的部分用\(\epsilon_i\)代替, 则式(3.1.1-2)转化为:
\[\begin{cases}
X_1 = \gamma_{11}Y_1 + \gamma_{21}Y_2 + \cdots + \gamma_{m1}Y_m + \epsilon_1 \\
X_2 = \gamma_{12}Y_1 + \gamma_{22}Y_2 + \cdots + \gamma_{m2}Y_m + \epsilon_2 \\
\cdots\cdots \\
X_p = \gamma_{1p}Y_1 + \gamma_{2p}Y_2 + \cdots + \gamma_{mp}Y_m + \epsilon_p \\
\end{cases} \tag{3.1.1-3}
\]该式与因子模型(2.1.1-2)相一致, 并且\(Y_i=(i=1,2,\cdots,m)\)之间相互独立。将\(Y_i\)转化成合适的公共因子, 只需将主成分\(Y_i\)变成方差为1的变量, 即除以其标准差(特征根的平方根), 则可令\(F_i = Y_i/\sqrt{\lambda_i}, \quad a_{ij} = \gamma_{ji}\), 式(3.1.1-3)变为:
\[\begin{cases}
X_1 = a_{11}F_1 + a_{12}F_2 + \cdots + a_{1m}F_m + \epsilon_1 \\
X_2 = a_{21}F_1 + a_{22}F_2 + \cdots + a_{2m}F_m + \epsilon_2 \\
\cdots\cdots \\
X_p = a_{p1}F_1 + a_{p2}F_2 + \cdots + a_{pm}F_m + \epsilon_p
\end{cases} \tag{3.1.1-4}
\]这与因子模型完全一致, 这样就得到了载荷矩阵\(A\)和一组初始公共因子(未旋转)。
- 一般设\(\lambda_1,\lambda_2,\cdots,\lambda_p \quad (\lambda_1 \ge \lambda_2 \ge \cdots \ge \lambda_p)\)为样本相关矩阵R的特征根, \(\gamma_1,\gamma_2,\cdots,\gamma_p\)为对应的标准化正交化特征向量。设\(m < p\), 则因子载荷矩阵A的一个解为:
\[\widehat{A} = (\sqrt{\lambda_1}\gamma_1, \sqrt{\lambda_2}\gamma_2,\cdots,\sqrt{\lambda_m}\gamma_m) \tag{3.1.1-5}
\]共同度的估计为:
\[\widehat{h}_i^2 = \widehat{a}_{i1}^2 + \widehat{a}_{i2}^2 + \cdots + \widehat{a}_{im}^2 \tag{3.1.1-6}
\] - 公因子的数目m, 当用主成分进行因子分析时, 可以借鉴确定主成分个数的准则。一般具体问题具体分析, 总之要使所选取的公共因子能够合理地描述原始变量相关阵的结构, 同时要有利于因子模型的解释。
3.2 主轴因子法
- 概述:
- 求解思路与主成分发类似, 均从分析矩阵的结构入手, 不同的地方在于, 主成分发是在所有的p个主成分能解释标准化原始变量所有方差的基础上进行分析的, 而主轴因子法中, 假定m个公共因子只能解释原始变量的部分方差, 利用公共因子方差(或共同度)来代替相关矩阵主对角线上的元素1, 并以新得到的这个矩阵(称为调整相关矩阵)为出发点, 对其分别求解特征根与特征向量并得到因子解。
3.2.1 求解方法
- 在因子模型(2.1.1-1)中, 不难得到如下关于X的相关矩阵R的关系式:
\[R = AA' + \Sigma_\epsilon
\]式中A为因子载荷矩阵, \(\Sigma_\epsilon\)为一对角阵, 其对角元素为相应特殊因子的方差。则称\(R^* = R -\Sigma_\epsilon = AA'\)为调整相关矩阵, 显然\(R^*\)的主对角元素不再是1, 而是共同度\(h_i^2\)。分别求解\(R^*\)的特征值与标准正交特征向量, 进而求出因子载荷矩阵A。此时, \(R^*\)有m个正的特征值。设\(\lambda_1^* \ge \lambda_2^* \ge \cdots \ge \lambda_m^*\)为\(R^*\)的特征根, \(\gamma_1^*, \gamma_2^*, \cdots, \gamma_m^*\)为对应的标准正交话特征向量。m < p, 则因子载荷矩阵A的一个主轴因子解为:
\[\widehat{A} = (\sqrt{\lambda_1^*}\gamma_1^*, \sqrt{\lambda_2^*}\gamma_2^*,\cdots,\sqrt{\lambda_m^*}\gamma_m^*) \tag{3.1.1.7}
\] - 注意到, 上面的分析是以首先得到调整相关矩阵\(R^*\)为基础的, 而实际上, \(R^*\)与共同度(或相对的剩余方差)都是未知的, 需要先进行估计。一般先给出一个初始估计, 然后估计出载荷矩阵A后再给出较好的共同度或剩余方差的估计。初始估计的方法有很多, 可尝试对原始变量先进行一次主成分分析, 给出初始估计值。
3.3 极大似然法
- 如果假定公共因子F和特殊因子\(\epsilon\)服从正态分布, 则能够得到因子载荷和特殊因子方差的极大似然估计。设\(X_1,X_2,\cdots,X_p\)为来自正态总体\(N(\mu,\Sigma)\)的随机样本, 其中\(\Sigma = AA' + \Sigma_\epsilon\)。从似然函数的理论知
\[L(\mu, \Sigma) = \frac{1}{(2\pi)^{np/2}|\Sigma|^{n/2}}e^{-1/2tr\{\Sigma^{-1}[\sum_{j=1}^n(X_j - \bar{X})(X_j - \bar{X})' + n(\bar{X} - \mu)(\bar{X} - \mu)']\}} \tag{3.3.1-1}
\]它通过\(\Sigma\)依赖于A和\(\Sigma_\epsilon\), 但式(3.3.1)不能唯一确定A, 为此, 添加如下条件:
\[A'\Sigma_\epsilon^{-1}A = \Lambda \tag{3.3.1-2}
\]其中\(\Lambda\)是一个对角阵, 用数值极大化的方法可以得到极大似然估计\(\widehat{A}\)和\(\widehat{\Sigma_\epsilon}\)。极大似然估计\(\widehat{A}, \widehat{\Sigma_\epsilon}和\widehat{\mu} = \bar{X}\), 将使\(\widehat{A}'\widehat{\Sigma}_\epsilon^{-1}\widehat{A}\)为对角阵, 使公式(3.3.1-2)达到最大。
4. 公因子重要性的分析
4.1 因子旋转
- 概述
- 不管用何种方法确定初始因子载荷矩阵A, 它们都不是唯一的。
- 因所得的初始因子解,各主因子的典型代表变量不是很突出,容易使因子的意义含糊不清,不便于对实际问题进行分析,出于这种考虑,可以对初始公共因进行线性组合,即进行因子旋转。
- 分类:
- 正交旋转: 由初始载荷矩阵A右乘一正交阵得到, 经过正交旋转得到的新公共因子仍然保持彼此独立的性质
- 斜交旋转: 放弃了因子之间彼此独立的限制, 形式更简洁, 其实际意义更容易理解。
- 说明:
- 对于一个具体问题做因子旋转,有时需要多次才能得到满意效果。每一次旋转后,矩阵各列平方的相对方差之和总会比上一次有所增加。如此继续下去,当总方差的改变不大时,就可以停止旋转,这样就得到新的一组公共因子及相应的因子载荷矩阵,使得其各列元素的相对方差之和最大。
4.2 因子得分概述
- 因子得分就是公共因子\(F_1,F_2,\cdots,F_m\)在每一个样品点上的得分。
4.2.1 计算公式
- 因子模型中,公共因子的个数少于原始变量的个数,且是不可观测的隐变量,载荷矩阵A不可逆, 因而不能直接求得公共因子用原始变量表示的精确线性组合。可采用回归的思想求出线性组合系数的估计值,即建立如下以公共因子为因变量,原始变量为自变量的回归方程:
\[F_j = \beta_{j1}X_1 + \beta_{j2}X_2 + \cdots + \beta_{jp}X_p, \quad j=1,2,\cdots,m \tag{4.2.1-1}
\]此处因为原始变量与公共因子变量均为标准化变量, 所以回归模型中不存在常数项。在最小二乘意义下, 可以得到F的估计值:
\[\widehat{F} = A'R^{-1}X \tag{4.2.1-2}
\]式中, A为因子载荷矩阵, R为原始变量的相关阵, X为原始变量向量。
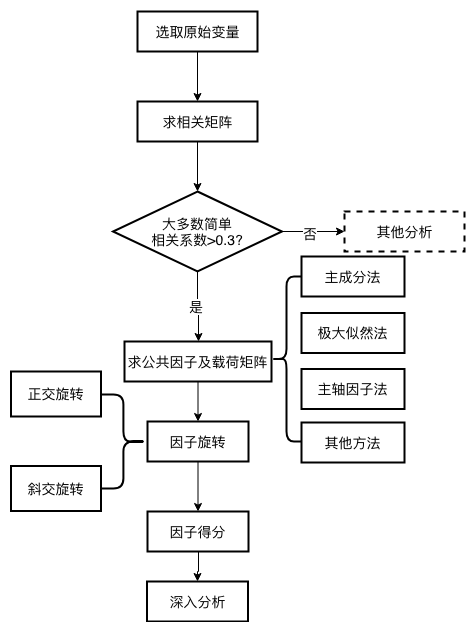
5. 因子分析步骤与逻辑框图
- 了解完因子分析的数学模型及因子载荷矩阵的求解方法后, 下面归纳一下因子分析的一般步骤.
5.1 步骤
5.1.1 选取原始变量进行标准化
- 根据研究的问题选取合适的原始变量, 并对变量做无量纲化, 通常有区间缩放, 标准化和归一化等方法.
5.1.2 适用性验证
- 并非所有的数据都是适合因子分析的, 因此在因子分析之前需要做适用性检验, 即分析变量之间的相关性.
- 共有三种检验方法:
- 计算相关系数矩阵:
- 满足大多数简单相关系数大于 0.3 即适合做因子分析.
- Bartlett 球度检验
- 用于检验相关阵中各变量间的相关性,是否为单位阵,即检验各个变量是否各自独立.
- KMO Kaiser-Meyer-Olkin) 检验统计量: 用于比较变量间简单相关系数和偏相关系数的指标
- 取值在0和1之间, 0.9以上表示非常适合; 0.8表示适合; 0.7表示一般; 0.6 表示不太适合; 0.5 以下表示极不适合.
- 计算相关系数矩阵:
5.1.3 求解初始公共因子及因子载荷矩阵
- 计算特征值和特征向量
- 计算累计贡献率大于 80% 的公共因子个数
5.1.4 因子旋转
- 包括正交旋转和斜交旋转, 一般使用较多的是正交旋转方法以获得相互独立的因子.
5.1.5 计算因子得分
5.1.6 根据因子得分值进行进一步分析
5.2 逻辑框图
6. python示例
6.1 factor_analyzer 包
- API:
- FactorAnalyzer(rotation=None, n_factors=n, method='principal')
- 参数:
rotation: 旋转的方式 (包括 None: 不旋转, 'varimax': 最大方差法,'promax': 最优斜交旋转 )n_factors: 公因子的数量;method: 因子分析的方法 ( 包括 'minres' : 最小残差因子法,'principal' : 主成分分析法 )
6.2 示例
- 导包
import pandas as pd
import numpy as np
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity, calculate_kmo
from factor_analyzer import FactorAnalyzer
import seaborn as sns
import matplotlib.pyplot as plt
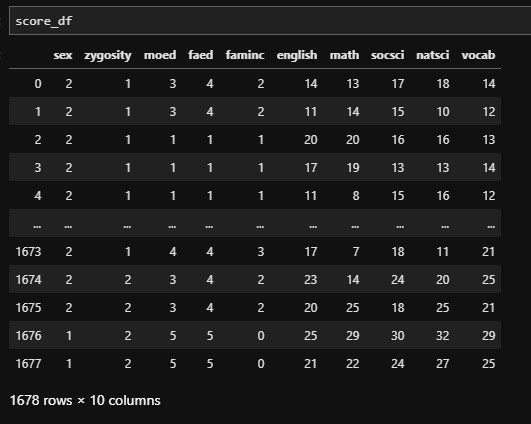
- 读取样本数据
plt.style.use({'figure.figsize':(20, 8)})
score_df = pd.read_csv('src_data/factor/test02.csv')
- 对数据进行标准化, 并进行适用性验证
std_score_df = (score_df - score_df.mean()) / score_df.std()
# 计算皮尔森相关系数
corr_score_df = std_score_df.corr()
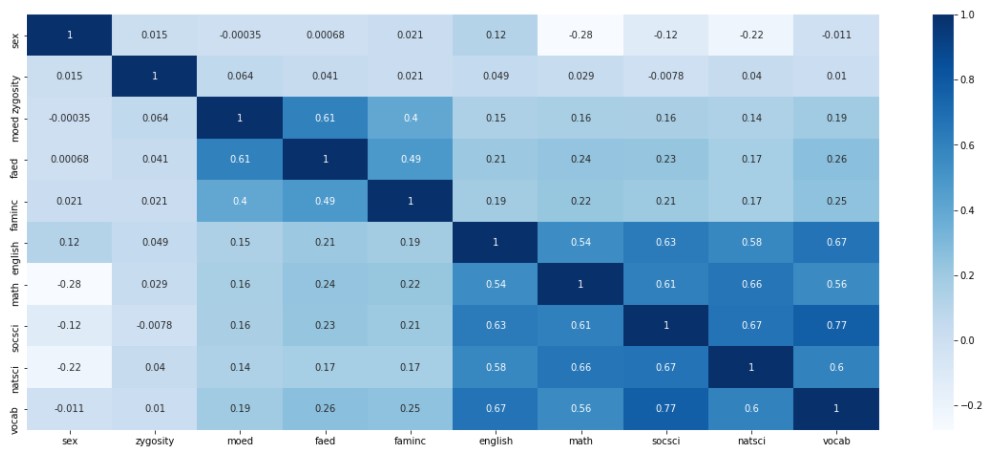
- 绘制热图, 查看变量之间的相关性
# 从热图明细看出变量间具有相关性
sns.heatmap(corr_score_df, cmap='Blues', annot=True)
- KMO Kaiser-Meyer-Olkin) 检验统计量
# KMO Kaiser-Meyer-Olkin) 检验统计量
kmo_per_variable, kmo_total = calculate_kmo(std_score_df)
# kmo_total = 0.8148048571126616 适合因子分析
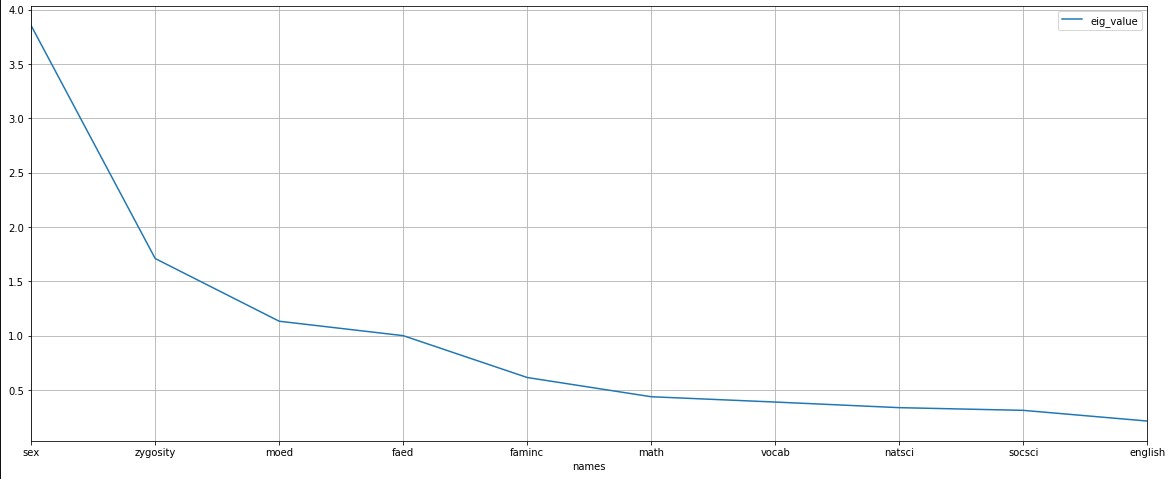
- 计算特征值和特征向量
eig_value, eig_vector = nlg.eig(corr_score_df)
#利用变量名和特征值建立一个 DataFrame
eig_df = pd.DataFrame()
eig_df['names'] = std_score_df.columns
eig_df['eig_value'] = eig_value
eig_df.sort_values(by='eig_value', ascending=False, inplace=True)
eig_df.set_index('names').plot(grid=True)
- 绘图确定初始公共因子个数
cum_eig_df = pd.DataFrame()
cum_eig_df['factors'] = pd.Series(range(1, 11))
cum_eig_df['cum_eig_value_ratio'] = np.cumsum(eig_df['eig_value'].values) / np.sum(eig_df['eig_value'].values)
# 从累计折线图中可看出当因子个数 5 时, 累计贡献率大于 0.8
cum_eig_df.set_index('factors').plot(grid=True)
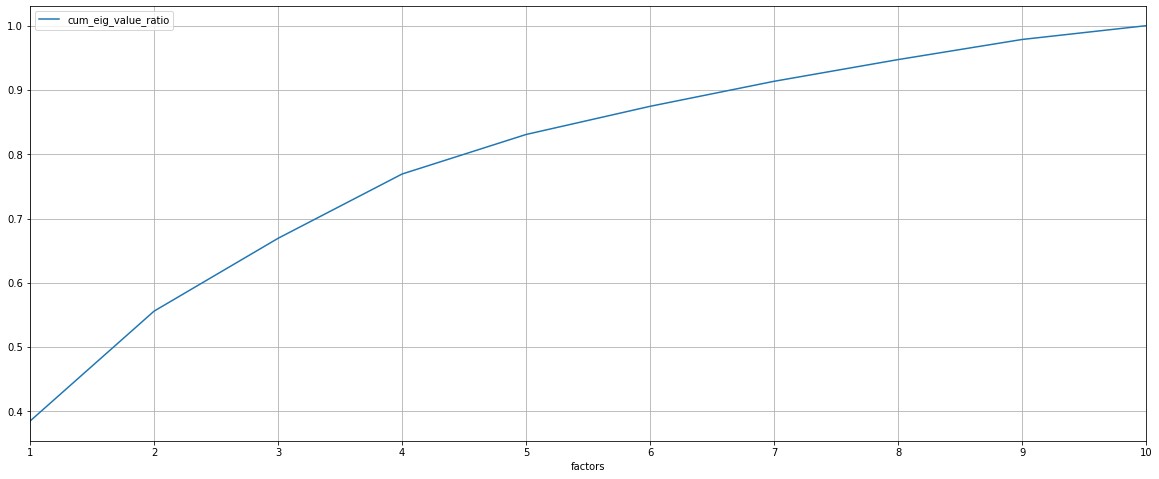
- 因子分析
# 因子旋转使用正交旋转最大方差法, 因子载荷矩阵使用主成分分析法
rotation_fa = FactorAnalyzer(5, method='principal', rotation='varimax')
# 求解载荷矩阵
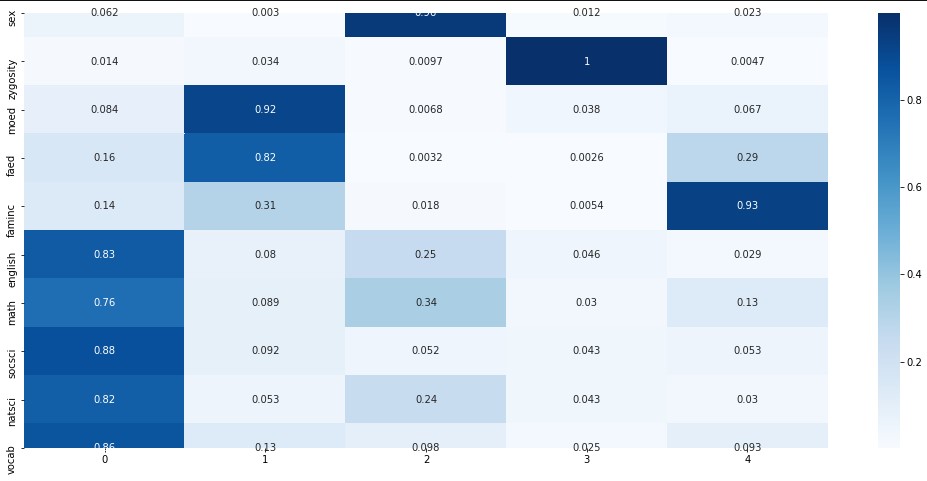
rota_factor_df = pd.DataFrame(np.abs(rotation_fa.loadings_), index=std_score_df.columns)
# 绘制载荷矩阵热图
sns.heatmap(rota_factor_df, annot=True, cmap='Blues')
# 至此该样本中提取出 5 个综合因子
7. 参考
- 多元统计分析-何晓群编著.中国人民大学出版社
- factor_analyzer 包
福提克
多元统计之因子分析模型及Python分析示例的更多相关文章
- pandas应用之分组因子暴露和分位数分析
pandas应用之分组因子暴露和分位数分析 首先感谢原书作者Mes McKinney和batteryhp网友的博文, 俺在此基础上继续探索python的神奇功能. 用A股的实际数据, 以书里的代码为蓝 ...
- 用Python分析国庆旅游景点,告诉你哪些地方好玩、便宜、人又少
注:本人参考“裸睡的猪”公众号同名文章,学习使用. 一.目标 使用Python分析出国庆哪些旅游景点:好玩.便宜.人还少的地方,不然拍照都要抢着拍! 二.获取数据 爬取出行网站的旅游景点售票数据,反映 ...
- 【Coursera】因子分析模型
一.协方差矩阵 协方差矩阵为对称矩阵. 在高斯分布中,方差越大,数据分布越分散,方差越小发,数据分布越集中. 在协方差矩阵中,假设矩阵为二维,若第二维的方差大于第一维的方差,则在图像上的体现就是:高斯 ...
- python 分析慢查询日志生成报告
python分析Mysql慢查询.通过Python调用开源分析工具pt-query-digest生成json结果,Python脚本解析json生成html报告. #!/usr/bin/env pyth ...
- Python分析盘点2019全球流行音乐:是哪些歌曲榜单占领了我们?
写在前面:圣诞刚过,弥留者节日气息的大家是否还在继续学习呐~在匆忙之际也不忘给自己找几首好听的歌曲放松一下,缠绕着音乐一起来看看关于2019年流行音乐趋势是如何用Python分析的吧! 昨天下午没事儿 ...
- Python分析数据难吗?某科技大学教授说,很难但有方法就简单
用python分析数据难吗?某科技大学的教授这样说,很难,但要讲方法,主要是因为并不是掌握了基础,就能用python来做数据分析的. 所谓python的基础,也就是刚入门的python学习者,学习的基 ...
- 五月天的线上演唱会你看了吗?用Python分析网友对这场线上演唱会的看法
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:CDA数据分析师 豆瓣9.4分!这场线上演唱会到底多好看? 首先让我 ...
- Python分析离散心率信号(下)
Python分析离散心率信号(下) 如何使用动态阈值,信号过滤和离群值检测来改善峰值检测. 一些理论和背景 到目前为止,一直在研究如何分析心率信号并从中提取最广泛使用的时域和频域度量.但是,使用的信号 ...
- Python分析离散心率信号(中)
Python分析离散心率信号(中) 一些理论和背景 心率信号不仅包含有关心脏的信息,还包含有关呼吸,短期血压调节,体温调节和荷尔蒙血压调节(长期)的信息.也(尽管不总是始终如一)与精神努力相关联,这并 ...
随机推荐
- mysql默认值
1.创建表时添加默认值 语法: <字段名><类型><默认值> 实例: MySQL [wordpress]> create table ly_content( ...
- pre -regulator 前端稳压器
regulator
- 8.4 parted:磁盘分区工具
parted 对于小于2TB的磁盘可以用fdisk和parted命令进行分区,这种情况一般采用flisk命令,但对于大于2TB的磁盘则只能用parted分区,且需要将磁盘转换为GPT格式. p ...
- 10.2-3 ifup&ifdown:激活与禁用网络接口
ifup:激活网络接口 ifup 和 ifdown 命令用于激活指定的网络接口.ifup命令其实是一个Shel脚本,有Shel基础的读者可以使用which命令来找到这个脚本并读一读.命令可读取 ...
- osi七层模型与tcp/ip四层模型的差别
OSI 七层协议 应用层 表示层 会话层 运输层 网络层 数据链路层 物理层 TCP/IP 四层协议 应用层 运输层 网际层 网络接口层 五层协议: 应用层 为用户的应用进程提供服务 HTTP SMT ...
- 鸿蒙 Android iOS 应用开发对比02
个人理解,不抬杠 转载请注明原著:博客园老钟 https://www.cnblogs.com/littlecarry/ IOS 把界面抽象成 "控制" Controller:And ...
- SSM框架的配置整合(包含配置文件代码)
由于SSM框架学习都要去网上或者以前的项目拷贝相同的代码,所以我在此把自己用到的配置文件全放在这里,帮助自己,帮助别人 首先开始前导入依赖和处理静态资源导出问题 <dependencies> ...
- GO语言常用标准库02---os包
package main import ( "fmt" "os" ) func main() { //获得当前工作路径(当前工程根目录) dir, err := ...
- 聊聊 apt sources.list 文件格式
前言 之前玩 ubuntu 需要切换国内源地址时,都是网上复制别人提供好的,也不知道是什么意思,拿来就用. 这次花点时间来看一下 apt sources.list 的格式,以及其表示的含义. 格式 s ...
- 实时实例分割的Deep Snake:CVPR2020论文点评
实时实例分割的Deep Snake:CVPR2020论文点评 Deep Snake for Real-Time Instance Segmentation 论文链接:https://arxiv.org ...